android设计模式之享元模式
享元模式是对象池的一种实现,它的英文名是Flyweight,代表轻量级的意思。享元模式用来尽可能减少内存使用量,它适合用于可能存在大量重复对象的场景,来缓存可共享的对象。从而达到对象共享、避免创建过多对象的效果,这样一来就可以提升性能、内存溢出等问题。
享元对象中的部分状态是可以共享的,可以共享的状态称为内部状态,内部状态不会随着环境的变化而变化;不可共享的状态称为外部状态,它们会随着环境的改变而改变。
经典的享元模式中,会建立一个对象容器,该容器为Map,它的键是享元对象的内部状态,它的值是就是享元对象本身。
客户端通过内部状态从享元工厂中获取享元对象,如果有缓存则使用缓存对象,否则创建一个享元对象并存入容器,从而避免创建过多对象的问题。
享元模式的定义
使用享元对象可有效地支持大量细粒度的对象。
享元模式的使用场景
1.系统中存在大量的相似对象。
2.细粒度的对象都具备较接近的外部状态,而且内部状态与环境无关,也就是说对象没有特定身份。
3.需要缓冲池的场景。
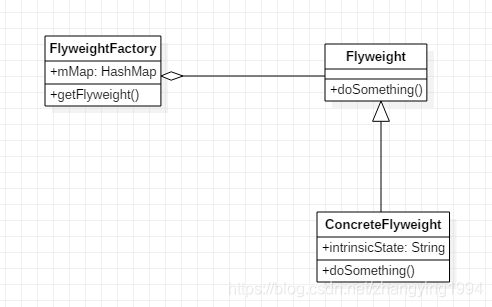
角色介绍
Flyweight:享元对象抽象基类或者接口。
ConcreteFlyweight:具体的享元对象。
FlyweightFactory:享元工厂,负责管理享元对象池和创建享元对象。
享元模式简单Demo
D:\Users\user\ProjectThree\FlyWeightDemo\app\src\main\java\flyweightdemo\gome\com\flyweightdemo\Ticket.java
//创建一个Ticket接口,该接口定义展示车票信息的函数
public interface Ticket {
public void showTicketInfo(String bunk);
}
D:\Users\user\ProjectThree\FlyWeightDemo\app\src\main\java\flyweightdemo\gome\com\flyweightdemo\TranTicket.java
//火车票,Ticket的具体实现类
public class TranTicket implements Ticket {
public String from;//始发地
public String to;//目的地
public String bunk;//铺位
public int price;//
public TranTicket(String from, String to) {
this.from = from;
this.to = to;
}
@Override
public void showTicketInfo(String bunk) {
price = new Random().nextInt(300);
Log.v(TAG, "购买 从 " + from + " 到 " + to + "的 " + bunk + "火车票, 价格:" + price);
}
}
D:\Users\user\ProjectThree\FlyWeightDemo\app\src\main\java\flyweightdemo\gome\com\flyweightdemo\TicketFactory.java
/**
* Created by ying.zhang on 2018/9/3.
* 享元模式通过消息池的形式有效减少了重复对象的存在。它通过内部状态标识
* 某个种类的对象,外部程序根据这个不会变化的内部状态从消息池中取出对象。
* 使得同一类对象可以重复被使用,避免大量重复对象。
*/
//使用享元模式很简单,只需要简单地改造一下TicketFactory
//车票工厂,以出发地和目的地为key缓存车票
//我们在TicketFactory中添加了一个map容器,并以出发地+"-"+目的地为键,
//以车票对象作为值存储车票对象。这个map的键就是我们所说的内部状态,在这里就是出发地、横杠、目的地拼接起来的字符串,
//如果没有缓存则创建一个对象,并且将这个对象存到map中,下次再有类似请求则从缓存中取出。从而有效避免了大量的内存占用以及频繁的GC操作。
public class TicketFactory {
static Map sTicketMap = new ConcurrentHashMap();
public static Ticket getTicket(String from, String to) {
String key = from + "-" + to;
if (sTicketMap.containsKey(key)) {
Log.v(TAG,"使用缓存==>" + key);
return sTicketMap.get(key);
} else {
Log.v(TAG, "创建对象==>" + key);
Ticket ticket = new TranTicket(from, to);
sTicketMap.put(key, ticket);
return ticket;
}
}
}
D:\Users\user\ProjectThree\FlyWeightDemo\app\src\main\java\flyweightdemo\gome\com\flyweightdemo\MainActivity.java
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
Ticket ticket01 = TicketFactory.getTicket("苏州", "上海");
ticket01.showTicketInfo("上铺");
Ticket ticket02 = TicketFactory.getTicket("苏州", "上海");
ticket02.showTicketInfo("下铺");
Ticket ticket03 = TicketFactory.getTicket("苏州", "上海");
ticket03.showTicketInfo("坐票");
}
Log分析:
V/FLY_WEIGHT: 创建对象==>苏州-上海
V/FLY_WEIGHT: 购买 从 苏州 到 上海的 上铺火车票, 价格:290
V/FLY_WEIGHT: 使用缓存==>苏州-上海
V/FLY_WEIGHT: 购买 从 苏州 到 上海的 下铺火车票, 价格:20
V/FLY_WEIGHT: 使用缓存==>苏州-上海
V/FLY_WEIGHT: 购买 从 苏州 到 上海的 坐票火车票, 价格:157
Android源码中的享元模式
一个基本知识点:
UI不能够在子线程中更新。这原本就是一个伪命题,因为并不是UI不可以在子线程中更新,而是UI不可以在不是它的创建线程中进行更新。只是绝大多数情况下UI都是从UI线程中创建的,因此,在其他更新时会抛出异常。在这种情况下,当我们在子线程完成了耗时操作之后,通常会通过一个Handler将结果传递给UI线程,然后在UI线程中更新相关视图。
在主线程中创建的一个Handler对象,它的Looper就是UI线程的Looper。在子线程执行完耗时操作后,则通过Handler向UI线程传递一个Runnable,即这个Runnable执行在UI线程中,然后在这个Runnbale中更新UI。
那么Handler和Looper的工作原理是什么呢?它们之间是如何协作的?
在此之前需要了解两个概念,即Message和MessageQueue。
其实Android应用是事件驱动的,每个事件都会转化为一个系统消息,即Message。
消息中包含了事件的相关信息以及这个消息的处理人——Handler。
每个进程都有一个默认的消息队列,也就是我们的MessageQueue,
这个消息队列维护了一个待处理的消息列表,有一个消息循环不断从这个列表中取出消息、处理消息,这样就使得应用动态地运作起来。它们的运作原理就像工厂的生产线一样,待加工的产品就是Message,“传送带”就是MessageQueue,工人们就对应处理事件的Handler。这么一来,Message必然产生很多对象,因为整个应用都是由事件,也就是Message来驱动的,系统需要不断产生Message、处理Message、销毁Message,难道Android没有IOS流畅是因为这个原因吗?重复构建大量的Message也不是Android的实现方式。
通过Handler传递了一个Runnable给UI线程。实际上Runnable会被包装到一个Message对象中,然后再投递到UI线程的消息队列中。我们看看Handler的post(Runnable run)函数。
/**
* Causes the Runnable r to be added to the message queue.
* The runnable will be run on the thread to which this handler is
* attached.
*(导致Runnable r添加到消息队列中。runnable将在连接此Handler的线程上运行。)
* @param r The Runnable that will be executed.(将要执行的Runnable)
*
* @return Returns true if the Runnable was successfully placed in to the
* message queue. Returns false on failure, usually because the
* looper processing the message queue is exiting.
*(如果Runnable已成功放入消息队列,则返回true。
*失败时返回false,通常是因为处理消息队列的looper正在退出。)
*/
public final boolean post(Runnable r)
{
return sendMessageDelayed(getPostMessage(r), 0);
}
private static Message getPostMessage(Runnable r) {
Message m = Message.obtain();
m.callback = r;
return m;
}
* Enqueue a message into the message queue after all pending messages
* before (current time + delayMillis). You will receive it in
* {@link #handleMessage}, in the thread attached to this handler.
* (在之前的所有待处理消息(当前时间+ delayMillis)之后将消息排入消息队列。
* 您将在附加到此Hanlder的线程中的{@link #handleMessage}中收到它。)
* @return Returns true if the message was successfully placed in to the
* message queue. Returns false on failure, usually because the
* looper processing the message queue is exiting. Note that a
* result of true does not mean the message will be processed -- if
* the looper is quit before the delivery time of the message
* occurs then the message will be dropped.
*(请注意,结果为true并不意味着将处理消息 - 如果在消息传递时间之前退出looper,则消息将被丢弃。)
*/
public final boolean sendMessageDelayed(Message msg, long delayMillis)
{
if (delayMillis < 0) {
delayMillis = 0;
}
return sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis);
}
在post函数中会调用sendMessageDelayed函数,但在此之前调用了getPostMessage将Runnable 包装到一个Message对象中。然后再将这个Message对象传递给sendMessageDelayed函数,具体代码如下:
public final boolean sendMessageDelayed(Message msg, long delayMillis)
{
if (delayMillis < 0) {
delayMillis = 0;
}
return sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis);
}
/**
* Enqueue a message into the message queue after all pending messages
* before the absolute time (in milliseconds) uptimeMillis.
* The time-base is {@link android.os.SystemClock#uptimeMillis}.
* Time spent in deep sleep will add an additional delay to execution.
* You will receive it in {@link #handleMessage}, in the thread attached
* to this handler.
* (在绝对时间(以毫秒为单位) uptimeMillis 之前的所有待处理消息之后将消息排入消息队列。 时基是{@link android.os.SystemClock#uptimeMillis}。深度睡眠所花费的时间会给执行带来额外的延迟。 您将在附加到此Handler的线程中的{@link #handleMessage}中收到它。)
* @param uptimeMillis The absolute time at which the message should be
* delivered, using the
* {@link android.os.SystemClock#uptimeMillis} time-base.
* (使用{@link android.os.SystemClock#uptimeMillis}时基传递消息的绝对时间。)
* @return Returns true if the message was successfully placed in to the
* message queue. Returns false on failure, usually because the
* looper processing the message queue is exiting. Note that a
* result of true does not mean the message will be processed -- if
* the looper is quit before the delivery time of the message
* occurs then the message will be dropped.
*/
public boolean sendMessageAtTime(Message msg, long uptimeMillis) {
//获取当前handler所在的消息队列
MessageQueue queue = mQueue;
if (queue == null) {
RuntimeException e = new RuntimeException(
this + " sendMessageAtTime() called with no mQueue");
Log.w("Looper", e.getMessage(), e);
//消息队列为空,直接返回
return false;
}
//将消息 添加到消息队列
return enqueueMessage(queue, msg, uptimeMillis);
}
sendMessageDelayed函数最终又调用了sendMessageAtTime函数,我们知道。post消息时可以延时发布,因此,有一个delay的时间参数。在sendMessageAtTime函数中会判断当前Handler的消息队列是否为空,如果不为空那么就会将消息追加到消息队列中。又因为我们的Handler在创建时关联了UI线程的Looper(如果不是手动传递的Looper,那么Handler持有的Looper就是当前线程的Looper,也就是说在哪个线程创建的Handler,就是哪个线程的Looper),Handler从这个Looper中获取消息队列,这样一来Runnbale就会被放到UI线程的消息队列中了,因此,我们的Runnbale在后续的某个时刻就会被执行在UI线程中。
这里我们不深究Handler、Looper等角色的运作细节,我们这里关注的是享元模式的运用。在上面的getPostMessage中会将Runnbale 包装成一个Message,在前文没有过,系统并不会构建大量的Message对象,那么它会如何处理呢?
private static Message getPostMessage(Runnable r) {
Message m = Message.obtain();
m.callback = r;
return m;
}
我们看到在getPostMessage中的Message对象是从一个Message.obtain()函数中返回的,并不是通过new来实现的,如果使用new那么就是我们起初猜测的会构建大量的Message对象,所以看一下Message.obtain()的实现:
#Message
/**
* Return a new Message instance from the global pool. Allows us to
* avoid allocating new objects in many cases.
*/(从全局池返回一个新的Message实例。 允许我们在许多情况下避免分配新对象。)
public static Message obtain() {
synchronized (sPoolSync) {
if (sPool != null) {
Message m = sPool;
sPool = m.next;
m.next = null;
m.flags = 0; // clear in-use flag (清空in-use flag)
sPoolSize--;
return m;
}
}
return new Message();
}
实现很简单,但是有一个引人注目的关键词——Pool,它的中文意思是池。是共享对象池? 看一下obtain中的sPoolSync、sPool里是什么程序。
/**
*(定义一条消息,其中包含可以发送到{@link Handler}的描述和任意数据对象。)
* Defines a message containing a description and arbitrary data object that can be
* sent to a {@link Handler}. This object contains two extra int fields and an
* extra object field that allow you to not do allocations in many cases.
*(此对象包含两个额外的int字段和一个额外的对象字段,允许您在许多情况下不进行分配。)
*
While the constructor of Message is public, the best way to get
* one of these is to call {@link #obtain Message.obtain()} or one of the
* {@link Handler#obtainMessage Handler.obtainMessage()} methods, which will pull
* them from a pool of recycled objects.
*/(
虽然Message的构造函数是public,但获取其中一个的最佳方法是调用{@link #obtain Message.obtain()}或{@link Handler#obtainMessage Handler之一。 obtainMessage()}方法,它们将它们从循环对象池中拉出来。)
public final class Message implements Parcelable {
... ...
private static final Object sPoolSync = new Object();
private static Message sPool;
private static int sPoolSize = 0;
... ...
}
首先Message文档的第一段的意思是介绍一下这个Message类的字段,以及介绍这个Message对象是被发送到Handler的,对于我们来说作用不大。第二段的意思是建议我们使用Message的obtain方法获取Message对象,而不是通过message的构造函数,因为obtain方法会从被回收的对象池中获取Message对象。然后再看看关键的字段,sPoolSync是一个普通的Object对象,它的作用就是用于在获取Message对象时进行同步锁。再看sPool居然是一个Message对象,居然不是我们上面说的消息池之类的东西,既然它命名为sPool不可能是有名无实吧,再往下看:
// sometimes we store linked lists of these things(以链表形式存储消息)
/*package*/ Message next;(并且这个next是包访问权限)
可以发现,原来Message消息池没有使用map这样的容器,而是使用的是链表。这个next就是指向下一个Message的,Message链如下所示:

每一个Message对象都有一个同类型的next字段,这个Message指向的就是下一个可用的Message,最后一个可用的Message的next为null;这样一来,所有可用的Message对象就通过next串连成一个可用的Mesasage池。
那么这些Message对象是什么时候会被放到链表中呢?我们在obtain函数中只看到了从链表中获取,并没有看到存储。
如果消息链表中没有可用对象的时候,obtian中则是直接返回一个通过new创建的Message对象,而且没有被存储到链表中。
(which will pull them from a pool of recycled objects.)这会将它们从回收池中取出来。其实在创建的时候不会把Message对象放到池中,在回收(这里的回收并不是指虚拟机回收Message对象)该对象时才会将该对象添加到链表中。
发现Message类中有类似Bitmap那样的recycle函数。
/**
* Return a Message instance to the global pool.
* (将Message实例返回到全局池。)
*(调用此函数后,您不能触摸消息,因为它已被有效释放。)
* You MUST NOT touch the Message after calling this function because it has
* effectively been freed. It is an error to recycle a message that is currently
* enqueued or that is in the process of being delivered to a Handler.
*
(回收当前已加入的消息队列或正在传递给Handler的message是错误的。)
*/
//将Message对象回收到消息池中
public void recycle() {
//判断是否该消息还在使用
if (isInUse()) {
if (gCheckRecycle) {
throw new IllegalStateException("This message cannot be recycled because it "
+ "is still in use.");
}
return;
}
//清空状态,并且将消息添加到消息池中
recycleUnchecked();
}
/**
* Recycles a Message that may be in-use.
* Used internally by the MessageQueue and Looper when disposing of queued Messages.
*/
void recycleUnchecked() {
// Mark the message as in use while it remains in the recycled object pool.
// Clear out all other details.
(将消息保留在循环对象池中时将其标记为正在使用。
清除所有其他细节。)
//清空消息状态,设置该消息in-use flag
flags = FLAG_IN_USE;
what = 0;
arg1 = 0;
arg2 = 0;
obj = null;
replyTo = null;
sendingUid = -1;
when = 0;
target = null;
callback = null;
data = null;
//回收到消息池中
synchronized (sPoolSync) {
if (sPoolSize < MAX_POOL_SIZE) {
next = sPool;
sPool = this;
sPoolSize++;
}
}
}recycle函数会将一个Message对象回收到一个全局的池中,这个池也就是我们上文所说的链表。然后判断是否要将该消息回收到消息池中,如果池的大小小于MAX_POOL_SIZE时,将自身添加到链表的表头。例如,当链表中还没有元素时,将第一个Message对象添加到链表中,此时sPool为null,next指向sPool,因此next也为null,然后sPool又指向了this,因此,sPool就指向了当前这个被回收的对象,并且sPoolSize加1。我们把这个被回收的Message对象命名为m1,此时结构如下图所示。

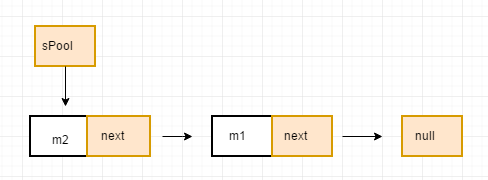
如果此时再插入一个名称为m2的Message对象,那么m2将会被插到表头中,此时sPool指向的就是m2。
这个对象池的大小默认为50,因此,如果池大小在小于50的情况下,被回收的Message就会被插到链表的头部。
此时如果池中有元素,当我们调用obtain函数时,如果池中有元素就会从池中获取,实际上获取的也是表头元素,也就是这里的sPool。然后再将sPool这个指针后移一个元素。
/**
* Return a new Message instance from the global pool. Allows us to
* avoid allocating new objects in many cases.
*/
public static Message obtain() {
synchronized (sPoolSync) {
if (sPool != null) {
Message m = sPool;
sPool = m.next;
m.next = null;
m.flags = 0; // clear in-use flag//清空in-use flag
sPoolSize--;
return m;
}
}
return new Message();
}在obtain函数中,首先会声明一个Message对象m,并且让m指向sPool。sPool实际上指向了m2,因此,m实际上指向了m2,这里相当于保存了m2这个元素。下一步是sPool指向m2的下一个元素,也就是m1.sPool也完成后移之后把m.next置空,也就是将m2.next变成了null。最后就是m指向了m2元素,m2的next为空,sPool从原来的表头m2指向下一个元素m1,最后将对象池的元素减1,这样m2就顺利地脱离了消息队列,返回给了调用obtain函数的客户端程序,如下图所示:


现在已经很明显了,Message通过在内部构建一个链表来维护一个被回收的Message对象的对象池,当用户调用obtain函数时会优先从池中获取,如果池中没有可以复用的对象则创建新的Message对象。这些新创建的Message对象在被使用完之后会被回收到这个对象池中,当下次再次调用obtain函数时,它们就会被复用。这里的Message相当于承担了享元模式中3个元素的职责,即Flyweight抽象,又是ConcreteFlyweight角色,同时又承担着FlyweightFactory管理对象池的职责。因为Android应用是事件驱动的,因此,通过new创建Message就会创建大量重复的Message对象,导致内存占用率较高,频繁GC等问题,通过享元模式创建一个大小为50的消息池,避免了上述问题的产生。
参考《Android源码设计模式》