【论文不精读】Reinforced Path Reasoning for Counterfactual Explainable Recommendation
Reinforced Path Reasoning for Counterfactual Explainable Recommendation
1 Introduction
现代推荐系统在对复杂的用户或者商品上下文进行建模时变得十分复杂并且不透明。例如社会关系([1]Be causal: De-biasing social network confounding in recommendation)和商品标签([2]Leveraging meta-path based
context for top-n recommendation with a neural co-attention model,最近很火的“用户画像”的英文是什么?有哪些方法?有哪些参考论文? - NPSMeter的回答 - 知乎
)
因此,迫切需要一种可信的解释,来解释用户的偏好同时也要保证模型的透明性。
可解释推荐系统(Explainable Recommendation Systems (XRS))旨在提供个性化的推荐,但是也要有能够回答为何特定商品会被推荐的解释([3])。众所周知,高质量的解释可以提升用户的满意度以及推荐的可信度([4], [5])。解释也可以方便系统的设计者在debugg时追踪推荐系统的决策过程([6])。
现存的推荐的可解释推荐系统方法可以分类成两种,一种是模型可知方法(model-intrinsic methods[7],[8]),一种是模型不可知方法(model-agnostic[9]~[12])。
模型可知方法寻找内在可解释的模型,例如决策树([7])和关联规则(association rules[8]),thus are limited in their applications to prominent deep learning models.[3]。最近,模型不可知方法吸引了越来越多的注意力([13]),这种方式允许推荐模型成为一种黑盒模型,例如神经网络([10])。模型不可知方法识别输入的用户商品交互并且从黑盒模型中输出推荐结果([13]),帮助用户理解他们的行为([10])或者哪种商品特征([11],[14])会对他们的推荐产生效果。然而现存的模型不可知方法受到以下的比较大的局限:
- 必须首先识别能够造成正向用户交互的影响因子(例如商品特征),然后再构建解释。然而他们很少考虑到如果直接将解释替换成其他因子,推荐结果会变成什么样子。(while they seldom consider what recommendations would be if we directly intervene on explanations to alternative ones.)
- 这些系统没有考虑到使用固定数量的影响因子来构建的解释的复杂度([9]),完全忽略了去探寻最小的影响因子的集合,集合内的影响因子可以很好地解释推荐。
最近,反事实解释([15])的出现成为解决上述问题的一个可行的机会。通常,反事实解释被定义为一个影响因子的最小集合,该集合中的因子如果被应用的话,将会改变推荐决定。反事实解释通过探索在商品或者用户上的最小变动如何影响推荐决定来解释推荐机制。为了构建反事实解释,我们需要从根本上解决:如果一个最小化的因子(用户行为/商品特征)集发生改变,推荐结果将会发生怎样的变化?。通过反事实解释,用户可以理解最少的改变如何影响推荐,并且在"What-if"场景下,实现反事实思维([17])。
现存的基于可解释的推荐系统的反事实解释可以分成两类:
- 基于搜索的方法([18],[19]),通过干扰用户交互或者商品特征获得反事实实例,对这些实例进行贪心搜索。
使用启发式质量指标衡量,获得最高得分的反事实实例被认为是反事实解释。
例如,Kaffes等人([18])通过从用户的交互中移除商品来构建反事实实例。利用归一化的长度和候选无力度衡量的反事实来指导解释的查询。
Xiong等人([19])在商品特征上使用受限制的特征干扰,并且查找受到干扰的特征作为反事实解释。
但是基于搜索的方法在大规模的搜索空间中会产生大量的计算负担([16])。 - 基于优化的方法([15],[20]~[22])将反事实解释公式化为一种优化问题,籍此来减轻计算压力。
一般情况下,优化目标是寻找到简单但是重要的能够直接导致用户偏好改变的用户动作或者商品的方面。
Ghazimatin等人[21]在用户-商品交互图上使用随机游走(random walks)方法,并且在从图中移除了用户动作边之后计算PageRank分数。改变PageRank的用户动作被视为反事实解释。
Tan等人([15])基于预定义的用户-商品方面偏好矩阵,通过改变商品方面的分数来观察用户偏好的改变。
总的来说,现存的基于优化的方法要么集中关注于用户的动作([20]~[22]),要么集中于商品方面的解释([15]),而基于项目属性的反事实解释在很大程度上没有被探索过。
我们认为,基于商品属性的反事实解释既有利于增强用户的信任感,也有利于提升推荐的表现效果。
一方面,基于商品属性的反事实解释一般更加符合直觉而且在寻求用户的信任时更加具有说服力。这很大程度上是因为用户倾向于去知道细节信息,例如到底是哪个属性导致了电影《阿凡达》不再推荐给我了?是因为导演吗?除此之外,寻找最小的能够改变推荐的属性集合也是很重要的。

如图1所示,用户 u 1 u_1 u1对属性为 { p 1 , p 2 , p 3 , p 4 } \{p_1,p_2,p_3,p_4\} {p1,p2,p3,p4}的商品 i 2 i_2 i2产生了负反馈,我们推测属性 { p 1 , p 2 , p 3 , p 4 } \{p_1,p_2,p_3,p_4\} {p1,p2,p3,p4}揭示了用户 u 1 u_1 u1的负偏好。然而,用户 u 1 u_1 u1却喜欢附带属性 { p 1 , p 2 } \{p_1,p_2\} {p1,p2}的商品 i 1 i_1 i1,某些程度上,这反映了该用户对属性 { p 1 , p 2 } \{p_1,p_2\} {p1,p2}的正向偏好。因此,将“少使用属性 { p 1 , p 2 , p 3 , p 4 } \{p_1,p_2,p_3,p_4\} {p1,p2,p3,p4}”作为用户 u 1 u_1 u1的推荐解释将会产生与用户真实的喜好之间的矛盾且,对用户偏好产生了错误的理解。
事实上,商品 i 1 i_1 i1和商品 i 2 i_2 i2属性的微小变动,例如 { p 3 , p 4 } \{p_3,p_4\} {p3,p4},可能是解释用户 u 1 u_1 u1不喜欢的真实决定性因素。
另一方面,反事实解释可以增强推荐的效果,因为他们提供了高质量的用户偏好的负信号。特别地,如果我们知道对于属性 { p 3 , p 4 } \{p_3,p_4\} {p3,p4}微小变动可以解释用户 u 1 u_1 u1的不喜欢,我们可以推测只有属性 { p 3 , p 4 } \{p_3,p_4\} {p3,p4}的商品 i 3 i_3 i3可能也不会被该用户喜欢。最后,反事实解释通过过滤掉负商品来帮助我们产生更多的精确的推荐。
本论文中,我们利用知识图谱(Knowledge graphs, KGs)来推测基于属性的反事实解释,同时增强推效果。我们提出了一种新的反事实可解释推荐(Counterfactual Explainable Recommendation, CERec),来将反事实优化问题构建为强化学习(Reinforcement Learning)任务。RL的智能体agent在统一搜索候选反事实时优化一种解释策略。为了减少搜索空间,我们提出了一种具有两步注意力机制的KG自适应路径采样器,并且选择反事实的商品属性作为可解释的候选项。使用候选解释,RL的agent优化了寻找最优反事实属性解释的策略。我们也将解释策略应用到了一个推荐模型中来强化推荐效果。本工作的具体贡献如下:
- 据我们所知,我们是首先在知识图谱中利用丰富的属性信息,并且为推荐提供基于属性的反事实解释;
- 我们提出了一种基于强化学习的框架来寻找最优的反事实解释,该框架由自适应的路径采样器和反事实奖励函数驱动;
- 我们设计了一种具有两步注意力机制的自适应路径采样器来减少反事实解释的搜索空间;
- 我们将推荐模型和反事实解释统一地进行训练,旨在增强推荐效果;
- 对模型的可解释性以及推荐效果采用大量的实验来验证CERec的有效性。
2 Related Work
可解释推荐
可解释推荐被证明能够提升用户的满意度([23])以及系统的透明度([24])。可解释推荐系统的研究可以被分成两个主要的类别([3],[25])。
第一类是模型固有方法(model-intrinsic)([7],[8]),
模型的可解释性分为intrinsic和posthoc。intrinsic表示模型自身就存在可解释性,例如决策树、线性模型、注意力机制;posthoc表示模型需要另一个独立的解释模型或技术来为目标模型提供解释,其本身是不可解释的,例如神经网络、热图(heat map)
知乎:人工智能的可解释性(一)
[26]~[29]设计了可解释的推荐模型以方便进行解释。模型固有方法训练可解释模型来识别对用户偏好有影响的因子,然后依此构建解释。
Shulman等人([7])提出了一种干扰决策树模型来预测用户对商品的评分。每一个决策树都是以单个用户为根,商品为叶而构建起来的,同时应用线性回归方法来学习叶子节点的值,然后构建决策规则。该决策是沿着决策树形成的一系列决策。
Lin等人([8])提出了一种针对特定用户的个性化联系规则挖掘方法。通过识别用户和商品之间的联系规则来产生解释。
其他的工作([26]~[31])尝试探索基于内容的方法([26])以及基于近邻的协同过滤([27],[28])来产生基于用户近邻([27],[30],[31])、商品相似度([28])以及用户/商品相似度([26])或者他们的某些组合的一种解释。
当现代推荐系统已经逐渐变得复杂并且成为黑盒模型,例如基于嵌入向量的模型([32]~[34])和深度神经网络([35],[30],[31]),发展模型固有方法([3])已经没有现实意义。因此另外一种类别的模型不可知方法(([10],[14],[37]))旨在利用事后比较(post-hoc)的方法来解释黑盒模型。例如Ghazimatin等人([10])对联合了用户的社会关系和历史交互数据的异质信息网络使用了图学习方法。习得的图嵌入向量被用来训练一种可解释的学习-排序模型,以此来输出解释路径。Singh等人([14])训练了一种学习-排序隐因子模型来生成排序标签。这些排序标签之后被用来训练一种基于树结构的可解释模型,来为排序列表生成可解释的商品特征。
反事实可解释推荐
反事实解释在哲学、心理学和社会科学等方面有很长的应用历史([16],[38],[39])。它们被认为是令人满意的解释([40]~[42]),并且可以引出像人类一样的因果推理。反事实解释最近在推荐系统中是一个热门话题。
目前成功的工作可以分为基于搜索和基于优化的两种方法。
第一类基于搜索的方法([18],[19])在反事实解释上使用贪心搜索算法。比如Kaffes等人([18])通过删除用户交互序列中的商品来干扰用户-商品交互,以此来生成受扰的用户交互,作为反事实解释。然后使用广度优先搜索来寻找实现了最大的归一化长度以及候选无力分数的反事实解释。Xiong等人([19])提出了对候选项目特征的约束特征扰动,并将受扰动的项目特征视为反事实解释。
第二类基于优化的的方法([15],[20],[21],[22])优化解释模型以找到变化最小的反事实解释。例如Ghazimatin等人[21]在异构信息网络上执行随机游走,并在从图中删除用户动作边后计算 PageRank 分数。这些改变PageRank分数的最小化的用户行为集合就是反事实解释。Tran等人[22]识别更新神经模型参数的最小用户操作集。Tran等人[15]基于用户方面偏好矩阵修改商品的方面得分,观察用户偏好变化。
现有的基于优化的方法要么关注用户行为[20],[21],[22],要么关注商品方面的解释[15],相比之下,我们的反事实解释是基于现实世界中的商品人口统计特征,定义在商品的属性侧的。此外,我们在强化学习的环境下,通过搜索候选的反事实来优化解释策略,从而将基于搜索和基于优化的方法融合进同一个机制中。
3 初步处理
A. Collaborative Knowledge Graph 协同知识图谱
协同知识图谱(CKG)将用户-商品交互以及商品知识编码成统一的相关图。 U ∈ R M , I ∈ R N \mathcal{U}\in \mathbb{R}^M, \mathcal{I}\in\mathbb{R}^N U∈RM,I∈RN分别代表用户和商品集。历史用户-商品交互矩阵 Y = { y u i ∣ u ∈ U , i ∈ I } \mathcal{Y}=\{y_{ui}|u\in\mathcal{U},i\in\mathcal{I}\} Y={yui∣u∈U,i∈I}通过用户的精确反馈来构建, y u i = 1 y_{ui}=1 yui=1表示在 u u u和 i i i之间有交互。除此之外,我们还使用了拓展的知识图谱来描述商品知识,这包含着现实世界的商品和属性实体以及他们之间的联系。受到[46]的启发,我们将丰富的商品知识和交互数据融合进协同知识图谱中。 ε \varepsilon ε和 R \mathcal{R} R表示拓展的知识图谱中实体和联系的集合。我们首先建立一种商品-实体对齐方法, ψ : I → ε \psi: \mathcal{I}\to\varepsilon ψ:I→ε,来将交互数据中的商品映射到KG的实体中。协同知识图谱CKG可以被规则化为: G = { ( h , r , t ) ∣ h , t ∈ ε ′ , r ∈ R ′ } \mathcal{G}=\{(h,r,t)|h,t\in\varepsilon',r\in \mathcal{R}'\} G={(h,r,t)∣h,t∈ε′,r∈R′},这里的 ε ′ = ε ∪ U \varepsilon'=\varepsilon\cup\mathcal{U} ε′=ε∪U, R ′ = R ∪ { I ( y u i ) } \mathcal{R}'=\mathcal{R}\cup\{\mathbb{I}(y_{ui})\} R′=R∪{I(yui)}。 I ( ⋅ ) \mathbb{I}(\cdot) I(⋅)是代表用户 u u u和商品 i i i之间是否存在交互,也就是在图中是否存在边的一种指标。每一个三元组 ( h , r , t ) (h,r,t) (h,r,t)用来形容头节点 h h h到尾节点 t t t之间是否存在连接 r r r。例如(Michael Jackson, SingerOf, Beat it)。
B. Counterfactual Explanation for Recommendation
反事实解释被定义为原始样本的最小扰动集合,如果施加了这种扰动,将会导致对该样本的相反的预测[47]。
本文中,我们主要集中于找到基于商品属性的反事实解释,最小扰动集合被定义为一种属性的集合。更准确地说,假设 f R f_R fR是一种Top-K推荐模型,该模型可以向用户 u u u提供一个长度为 K K K的推荐列表 Q u Q_u Qu,我们说 i ∈ Q u i\in Q_u i∈Qu被推荐了。对于一个用户-商品对 ( u , i ) (u,i) (u,i),我们的目标是寻找一种最小的商品属性集合 Δ u i = { a u i 1 , ⋯ , a u i r } \Delta_{ui}=\{a_{ui}^1,\cdots,a_{ui}^r\} Δui={aui1,⋯,auir}。在集合中的每个属性都是对应着图谱中的属性实体,属性包含着现实世界的描述商品的语义信息。
在有了推荐模型 f R f_R fR以及属性集合 Δ u i \Delta_{ui} Δui的情况下,我们的优化目标是衡量将 Δ u i \Delta_{ui} Δui应用到被推荐的商品 i i i上之后,是否会导致对用户推荐的商品 i i i被替换成商品 j j j。如果优化目标达到了,那么这个属性集合 Δ u i \Delta_{ui} Δui被定义为颠覆推荐结果的反事实解释,而商品 j j j则成为了原始商品 i i i的反事实商品。同时,反事实解释 Δ u i \Delta_{ui} Δui的模长也应该是最小的。
利用优化后的 Δ u i \Delta_{ui} Δui,我们可以生成将商品 i i i推荐给用户 u u u的反事实解释,形式如下:
如果商品 i i i的一个最小属性集合 [ Δ u i ( S ) ] [\Delta_{ui}(S)] [Δui(S)]发生了改变,推荐商品将会变成 j j j。
C. Task Formulation 任务形式化
给定协同知识图谱 G \mathcal{G} G,我们想要构建一种反事实解释模型来探索 G \mathcal{G} G之间的丰富联系,进而产生原始推荐商品的反事实商品。我们形式化反事实解释模型如下:
j ∼ π E ( u , i , f R , G ∣ Θ E ) , (1) j\sim\pi_E(u,i,f_R,\mathcal{G}|\Theta_E),\tag{1} j∼πE(u,i,fR,G∣ΘE),(1)
这里的 π E ( ⋅ ) \pi_E(\cdot) πE(⋅)是反事实解释模型,参数为 Θ E \Theta_E ΘE, f R f_R fR是Top-K推荐模型。反事实解释模型产生 G \mathcal{G} G中商品的经验分布,来对推荐商品 i i i生成反事实商品 j j j,期望可以获得最小属性集合的反事实目标,来逆转推荐结果。
我们也期望使用 π E \pi_E πE生成的反事实商品来改进推荐模型 f R f_R fR。最终一个反事实商品可以提供高质量的消极信号,因为该商品拥有可以使得积极商品不再匹配用户偏好的属性。受到成对排序学习[48]的启发,我们将一个积极的商品-用户交互与反事实商品进行配对,来增强推荐模型 f R f_R fR中的反事实信号,

这里的 f R ( ⋅ ) f_R(\cdot) fR(⋅)就是伴有参数 Θ R \Theta_R ΘR的推荐模型, σ ( ⋅ ) \sigma(\cdot) σ(⋅)是sigmoid函数。 ( u , i ) (u,i) (u,i)是满足 ∃ r ∈ R ′ , s . t . ( u , r , i ) ∈ G \exists r\in \mathcal{R}',s.t.(u,r,i)\in \mathcal{G} ∃r∈R′,s.t.(u,r,i)∈G。该公式鼓励积极商品从目标用户上接收到比反事实商品更高的预测分数。这样,推荐模型不仅仅是为反事实解释模型训练提供推荐结果,同时通过交互式地增强反事实信号来强化推荐,进而将推荐模型和反事实解释模型共同训练。
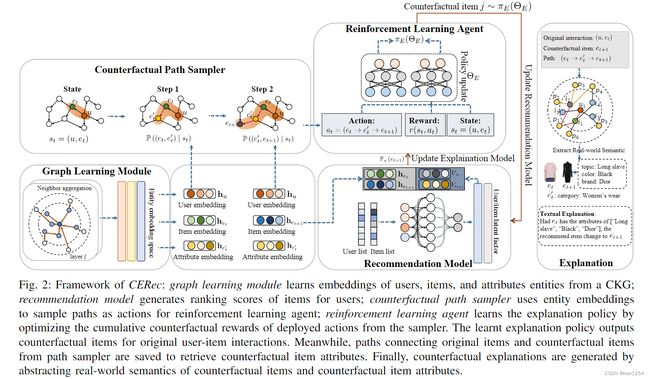
4 模型框架
反事实解释推荐框架(counterfactual explainable recommendation, CERec)利用协同知识图谱中的富联系信息来产生基于属性的反事实解释,同时对推荐模型提供改进。
本模型包含三个模块:
- 推荐模型
产生排序分数,以及和解释模型共同训练
- 图学习模块
对给定的CKG中的用户商品以及属性实体进行嵌入,获得嵌入向量。
- 反事实解释模型
基于实体嵌入向量以及排序分数构造有效路径采样方法,发掘高质量的反事实商品。主要包含两个部分:
- 反事实路径采样器,使用实体嵌入来采样路径,作为强化学习智能体的的行为actions。
- 强化学习的智能体agent,使用采样器获得的路径作为行动actions,优化累积奖励。
A. 推荐模型
现在我们将要展示使用用户和商品的隐因子来进行Top-K推荐的推荐模型 f R f_R fR。我们采用成对学习排名模型CliMF[49]作为推荐模型。CliMF初始化用户和商品的IDs作为隐因子,并且通过直接优化平均倒数排序(Mean Reciprocal Rank, MRR)来预测商品对用户的预测排序分数。值得注意的是, f R f_R fR可以是任何将用户和商品的嵌入作为输出并且输出商品排序结果的模型。
f R ( u , i ) = U u T V i (3) f_R(u,i)=U_u^TV_i\tag{3} fR(u,i)=UuTVi(3)
这里 U u U_u Uu代表d维的用户 u u u隐因子, V i V_i Vi表示d维的商品 i i i隐因子。我们使用MRR损失来定义我们的目标函数,来优化参数 Θ R \Theta_R ΘR,形式如下:
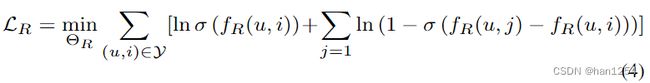
这里的 Y ∈ R M × N \mathcal{Y}\in \mathbb{R}^{M\times N} Y∈RM×N代表历史用户-商品交互矩阵, σ ( ⋅ ) \sigma(\cdot) σ(⋅)是sigmoid函数, j ∼ π E ( Θ E ) j\sim \pi_E(\Theta_E) j∼πE(ΘE)是我们反事实解释模型中产生的反事实商品。通过优化损失函数,我们可以基于 U U U和 V V V来获得每个商品 i i i对用户 u u u的排序分数,

这里的K是用户 u u u的推荐列表 Q u Q_u Qu的长度, P u ( i ) \mathbb{P}_u(i) Pu(i)指的是用户 u u u的推荐列表中商品 i i i的排序分数。
B. 图学习模块
图学习模块GLM从给定的协同知识图谱 G \mathcal{G} G中学习用户、商品以及特征的表示。习得的embedding被应用进我们的推荐模型中:
- 计算用户、商品以及属性实体的重要性分数,形成采样路径,作为反事实路径采样的动作actions。
- 计算商品实体之间的相似度,为强化学习的智能体定义采取actions之后的反事实奖励。
我们使用了GraphSage[32]来学习用户、商品以及属性实体的表示。对于一个实体 e ∈ G e\in \mathcal{G} e∈G,GraphSage强化了从它的近邻 N e \mathcal{N}_e Ne传递来的信息,进而习得 e e e的表示。因为用户实体会和类别为商品的实体相连接,也就是说 N e ∈ I \mathcal{N}_e\in \mathcal{I} Ne∈I,那么习得的用户嵌入表示捕捉了来自历史用户-商品交互数据的影响。相同地,商品实体会和商品属性实体相连,习得的商品embedding吸收了来自它们的属性的上下文信息。
而且我们首先使用多独热码(Multi-OneHot),实体IDs被映射到embeddings,初始化在GraphSage的0层的实体表示,该层的实体 e e e被表示为 h e 0 h_e^0 he0。在第 l l l个图卷积层,实体 e e e接收到从其近邻传递的信息来更新自己的表示:
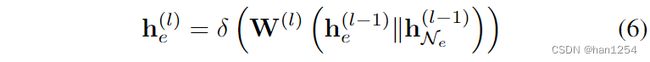
这里的 h e ( l ) ∈ R d l \textbf{h}_e^{(l)}\in \mathbb{R}^{d_l} he(l)∈Rdl是实体 e e e在 l l l层的embedding表示, d l d_l dl是embedding的维度大小; W ( l ) ∈ R d l × 2 d l − 1 \textbf{W}^{(l)}\in \mathbb{R}^{d_l\times 2d_{l-1}} W(l)∈Rdl×2dl−1是权重矩阵, ∣ ∣ \vert\vert ∣∣是连接操作, δ ( ⋅ ) \delta(\cdot) δ(⋅)是非线性激活函数LeakyReLU, h N e ( l − 1 ) \textbf{h}_{\mathcal{N}_e}^{(l-1)} hNe(l−1)是从 e e e的近邻集合 N e \mathcal{N}_e Ne中传递的信息,

在已经获得了每个图卷积层 l ∈ { 1 , ⋯ , L } l\in \{1,\cdots,L\} l∈{1,⋯,L}的表示 h e ( l ) h_e^{(l)} he(l)之后,我们采用层叠加机制(layer-aggregation mechanism)[52]来将所有层的embeddings连接至一个单独的向量中,表示如下:

通过使用层叠加,we can capture higher-order
propagation of entity pairs across different graph convolutional
layers.(没搞懂)。在堆叠了L层之后,我们获得了在协同知识图谱CKG中每个实体的最终的表示。接下来我们使用 h u \textbf{h}_u hu来代表用户实体 u u u的embedding, h e t h_{e_t} het是商品实体 e t e_t et的embedding表示, h e t ′ h_{e_t'} het′是商品属性实体 e t ′ e_t' et′的embedding表示。
C. 反事实解释模型
本文的反事实解释模型包括两个主要部分:
- 反事实路径采样器
在用户、商品和属性embeddings上施加两步注意力机制,寻找高质量的路径作为每个状态 s t s_t st下施加的动作 a t a_t at。之后状态和动作被送入强化学习智能体去学习解释策略。
- 强化学习智能体agent
基于推荐模型生成的排序分数以及商品embeddings,强化学习agent学习在状态 s t s_t st下的奖励 r ( s t , a t ) r(s_t,a_t) r(st,at),并且依此更新解释策略 π ( Θ E ) \pi(\Theta_E) π(ΘE)。最终基于习得的解释策略 π E \pi_E πE以及路径历史,我们的反事实解释推荐系统CERec为推荐生成基于反事实解释的属性。
使用强化学习构建反事实解释模型
反事实路径采样,counterfactual path sampler(CPS)
A. 反事实路径采样
基本的思想是:在已知目标用户的情况下,从推荐的商品出发,学习如何导航到它的商品属性,沿着采样路径生成潜在的反事实商品。在实际操作中,为了构建这样的高阶路径采样,我们需要构建大规模的协同知识图谱,因为这种图谱包含着丰富的用户、商品以及商品属性信息。最终,反事实商品被从目标用户-商品交互对的更高跳数的近邻中采样,来形成候选行动action空间。然而,从候选行动空间中学习反事实解释是不可行的,因为这种空间将潜在地覆盖了大量的路径。因此,我们CPS反事实路径采样器被设计出来,通过过滤不相干的路径以及选择重要路径,减少候选行动空间。
这里,我们使用注意力机制来计算访问的实体对源实体的重要性,从而生成采样路径。我们引入 P ( a t ∣ s t ) \mathbb{P}(a_t|s_t) P(at∣st),利用注意力机制来在每个状态 s t s_t st下采样路径作为action。
每个状态 s t s_t st下, a t ∼ P ( a t ∣ s t ) = ( e t → e t ′ → e t + 1 ) a_t\sim \mathbb{P}(a_t|s_t)=(e_t\to e_t'\to e_{t+1}) at∼P(at∣st)=(et→et′→et+1)就是从商品 e t e_t et到商品 e t + 1 e_{t+1} et+1的路径,它们之间通过商品属性 e t ′ e_t' et′连接,动作 a t a_t at通过两步路径采样生成:
- 选择一条 e t e_t et的出边,该边指向商品属性实体 e t ′ e_t' et′;
- 通过 e t e_t et选择第三个实体 e t + 1 e_{t+1} et+1。
我们分别将每一步的置信度建模成两个注意力机制,即 P ( ( e t , e t ′ ) ∣ s t ) \mathbb{P}((e_t, e_t')|s_t) P((et,et′)∣st)以及 P ( ( e t ′ , e t + 1 ) ∣ s t ) \mathbb{P}((e_t',e_{t+1})|s_t) P((et′,et+1)∣st)
第一个注意力机制 P ( ( e t , e t ′ ) ∣ s t ) \mathbb{P}((e_t,e_t')|s_t) P((et,et′)∣st)明确了 e t e_t et的各个属性对其的重要性,这个重要性是可以感知到当前的状态 s t = ( u , e t ) s_t=(u,e_t) st=(u,et)的,即用户 u u u和商品 e t e_t et。对于商品 e t e_t et的每一条指向其属性 e t ′ ∈ N e t e_t'\in \mathcal{N}_{e_t} et′∈Net的出边,首先获得商品 e t e_t et、属性 e t ′ e_t' et′以及用户 u u u的embeddings,表示为 h e t \textbf{h}_{e_t} het、 h e t ′ \textbf{h}_{e_t'} het′和 h u \textbf{h}_u hu。之后商品属性 e t ′ e_t' et′的重要性分数被计算为:

δ ( ⋅ ) \delta(\cdot) δ(⋅)是LeakyReLU。因此我们施加softmax函数来标准化 e t e_t et所有近邻的注意力分数:

选择了商品属性 e t ′ e_t' et′之后,我们施加另一种注意力机制 P ( ( e t ′ , e t + 1 ) ∣ s t ) \mathbb{P}((e_t',e_{t+1})|s_t) P((et′,et+1)∣st)来决定从属性的近邻 N e t ′ \mathcal{N}_{e_t'} Net′中选择哪一个商品作为反事实商品。首先基于属性 e t ′ e_t' et′、商品 e t + 1 e_{t+1} et+1以及用户 u u u的embeddings计算 e t + 1 ∈ N e t ′ e_{t+1}\in \mathcal{N}_{e_t'} et+1∈Net′的注意力分数,
![]()
接下来我们通过标准化注意力分数来生成商品 e t + 1 e_{t+1} et+1的选择概率。并且,因为我们关心如何生成合理的反事实商品,我们过滤掉了无法达到反事实目标的无关商品,也就是那些已经在推荐列表 Q u Q_u Qu中被推荐给用户 u u u的商品。

最终的反事实路径采样的计算方法为,
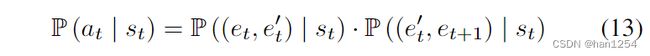
B. 强化学习
我们公式化反事实解释模型为一个基于路径的强化学习agent,来挖掘高质量的反事实商品。每个动作 a t a_t at都是一条指向候选反事实商品的路径。使用反事实奖励 r ( s t , a t ) r(s_t,a_t) r(st,at)来衡量是否动作 a t a_t at在当前环境 s t s_t st下返回一个合理的反事实商品。
- Agent:反事实解释模型被形式化为一个马尔可夫决策过程 M = { S , A , P , R } \mathcal{M}=\{\mathcal{S,A,P,R}\} M={S,A,P,R}
- S \mathcal{S} S:连续状态空间,描述目标用户和当前访问的商品实体。
- A \mathcal{A} A:离散空间,包含策略学习需要的动作 a t a_t at
- P \mathcal{P} P:状态转移,包含当前状态转移到下一个状态的概率。 P ( s t + 1 ∣ s t , a t ) ∈ P = 1 , s t + 1 = ( u , e t + 1 ) , s t = ( u , e t ) \mathbb{P}(s_{t+1}|s_t, a_t)\in \mathcal{P}=1,s_{t+1}=(u,e_{t+1}),s_t=(u,e_t) P(st+1∣st,at)∈P=1,st+1=(u,et+1),st=(u,et)不太明白概率为何为1?
- R \mathcal{R} R: r ( s t , a t ) ∈ R r(s_t, a_t)\in \mathcal{R} r(st,at)∈R,反事实奖励,衡量商品 e t + 1 e_{t+1} et+1是否是一个合理的反事实商品。通过两个标准来进行定义:
- 合理性[16]:与原始商品 e t e_t et相比, e t + 1 e_{t+1} et+1在被移除出当前用户的推荐列表这一事件上具有更高的置信度。
- 相似性:反事实解释需要得到反事实商品和原始商品之间最小的属性变动,商品 e t + 1 e_{t+1} et+1应该尽可能地与原始商品 e t e_t et类似。

这的 ϵ \epsilon ϵ表示推荐阈值。 ϵ = P u ( e t ) − P u ( Q u K ) \epsilon=\mathbb{P}_u(e_t)-\mathbb{P}_u(\textbf{Q}_u^K) ϵ=Pu(et)−Pu(QuK)。
- 目标函数
使用agent的 { S , A , P , R } \mathcal\{S,A,P,R\} {S,A,P,R},我们的反事实解释模型寻找一种反事实解释策略 π E \pi_E πE,这个策略可以在强化深度 T T T上最大化累计奖励 R ( π E ) R(\pi_E) R(πE)
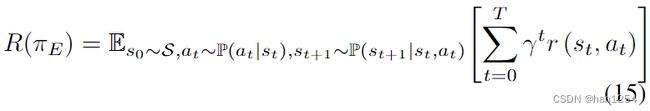
最终的反事实解释是通过提炼反事实项目的属性及其真实世界的语义而形成的。