tensorRT(二)| MNIST例子解读
本文来自公众号“AI大道理”。
这里既有AI,又有生活大道理,无数渺小的思考填满了一生。
本文使用TensorRT MNIST的例子介绍TensorRT的基本流程。
MNIST的例子将训练好的神经网络模型转换为TensorRT的形式,并用TensorRT Optimizer进行优化。
![]()
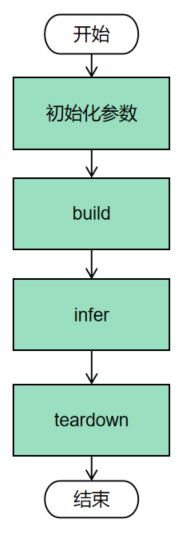
1、全流程
TensorRT获取模型结构与权重、进行模型优化、生成engine。
这一步被称为 build phase,耗时较长(特别在嵌入式设备上),所以需要保存为一个本地文件。
生成的文件不能在不同设备、不同TensorRT版本下使用。
基本流程:
-
-
执行基本的安装,用Caffe parser初始化tensorRT。
-
用Caffe parser导入训练过的Caffe model。
-
对输入进行预处理并存储在缓冲区内。
-
建立引擎。
-
序列化和反序列化引擎。
-
利用引擎推理一张图片。
-
TensortRT构造 SampleMNIST 对象,调用相关方法实现Caffe模型转换、TensorRT Engine推理。
![]()
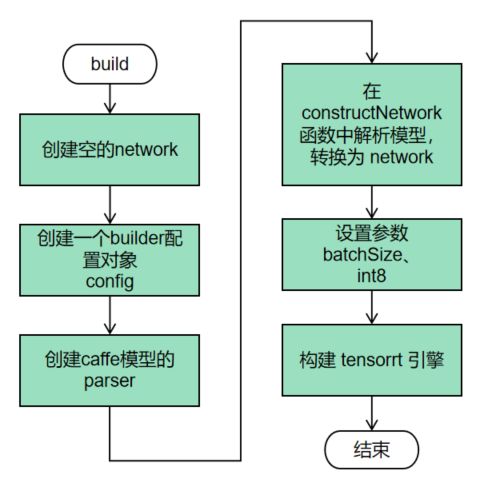
2、build(建立引擎)
构建器。
搜索cuda内核目录以获得最快的可用实现,必须使用和运行时的GPU相同的GPU来构建优化引擎。
在构建引擎时,TensorRT会复制权重,创建 config、network、engine 等其它对象的核心类。
首先要创建一个空的network,将训练好的网络解析出来,转化为network,然后构建tensorRT引擎。
build将Caffe model 使用tensorRT优化器进行优化转换为 TensorRT object,因此需要指定 网络模型文件(如caffe的deploy.prototxt)、训练好的权值文件(如caffe的net.caffemodel)以及均值文件(如caffe的mean.binaryproto)。
此外,还需要指定 batch size,并标记输入输出层。

build流程:
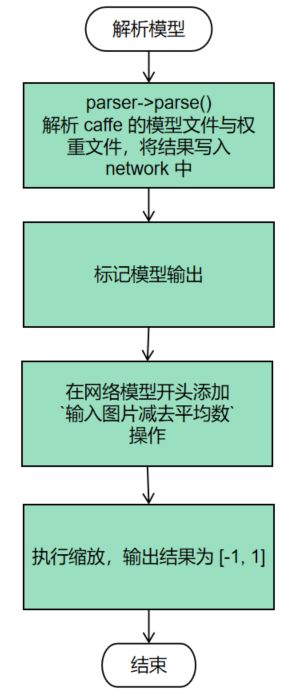
模型解析就是将caffe的模型文件和权重文件进行解析,保存结果到network中。其实就是模型的一种保存形式转化为另外一种形式。
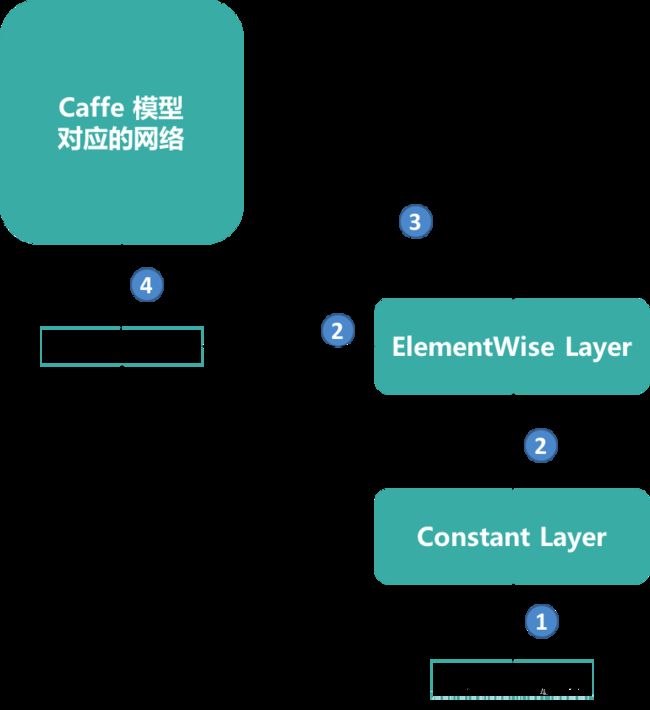
网络的Input做一个范围限制处理,包括通过network->addConstant方法创建一个IConstant Layer,该Layer的input是个3维Dims3对象。
通过network->addElementWise方法创建一个IElementWise Layer,将原网络的Input和IConstant Layer的output作为Input求相减。
最后通过network->getLayer(0)->setInput替换原网络的Input为IElementWise Layer的output,完成对原网络Input的范围限制处理。
小结一下build作用就是加载和设定参数细节,解析网络文件,然后搭建网络,最后按照一定的configuration构建了一个engine,engine就是引擎,它是推动TensorRT推理的真正实体。
![]()
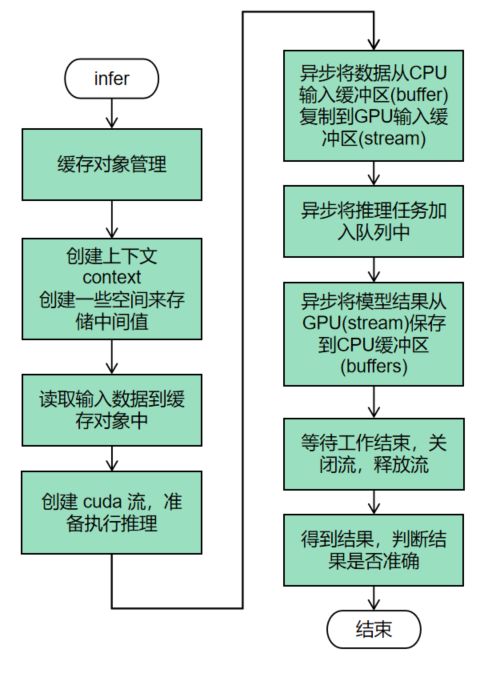
3、infer(执行推理)
infer将转换好的模型在tensorRT engine上跑一遍。
由于数据输入是在cpu,模型推理是在GPU,因此这里需要对数据进行搬运。
从cpu搬到gpu进行异步计算,得到结果后又需要从gpu搬到cpu进行显示。

infer先创建了一个buffer,然后构建上下文环境,接着把输入图像读取到buffer里,再把buffer的输入从主机CPU端拷贝到设备端GPU,调用上下文执行函数,再从设备端GPU把输出拷贝到主机端CPU,最后再验证结果。
推理流程:
-
创建runtime
-
反序列化创建engine
-
创建context
-
获取输入输出索引
-
创建buffers
-
为输入输出开辟GPU显存
-
创建cuda流
-
从CPU到GPU----拷贝input数据
-
异步推理
-
从GPU到CPU----拷贝output数据
-
同步cuda流
-
释放资源
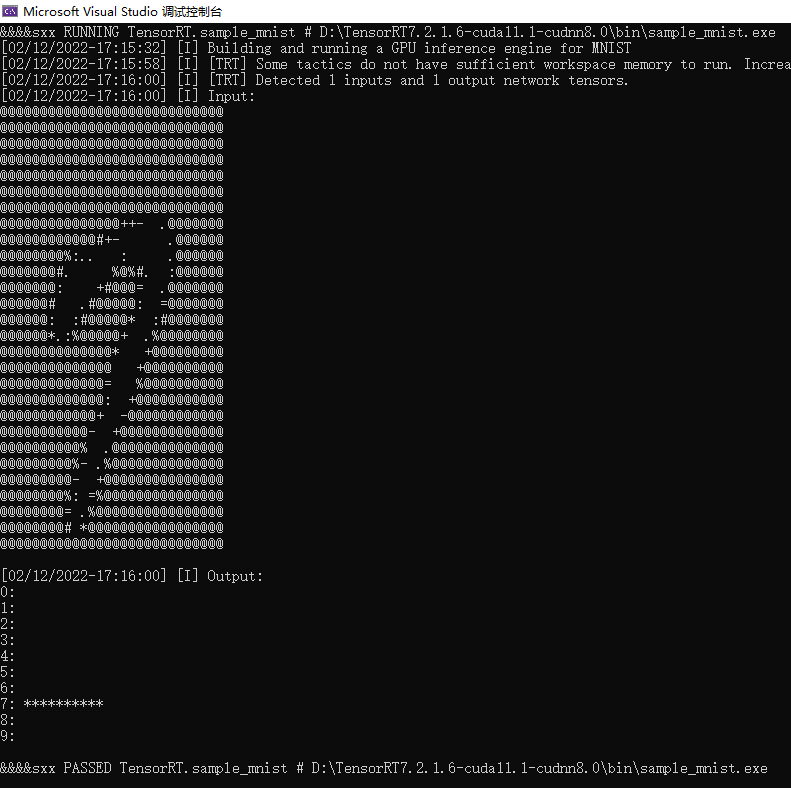
推理结果:
![]()
4、teardown(释放资源)

![]()
5、总结
TensorRT并不开源,看不见底层实现原理,我们仅仅只是使用它提供的API。
TensorRT是一个高性能的深度学习推断(Inference)的优化器和运行的引擎。
TensorRT支持Plugin,对于不支持的层,用户可以通过Plugin来支持自定义创建。
TensorRT使用低精度的技术获得相对于FP32二到三倍的加速,用户只需要通过相应的代码来实现。

——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

—————————————————————
投稿吧 | 留言吧