跨模态预训练
- 1.ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks[NeurIPS2019]。code
- 2.LXMERT,LXMERT: Learning Cross-Modality Encoder Representations from Transformers[EMNLP2019]。code
- 3.UNITER,UNITER: UNiversal Image-TExt Representation Learning[ECCV2020]。code
- 4.VisualBERT ,VisualBERT A Simple and Performant Baseline for Vision and Language[ACL2020]。code
- 5.VL-BERT,VL-BERT: Pre-training of Generic Visual-Linguistic Representations[ICLR2020]。code
- 6.Oscar,Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks[ECCV2020]。code
- 7.ERNIE-ViL,ERNIE-ViL: Knowledge Enhanced Vision-Language Representations through Scene Graphs[AAAI2020]。code
- 8.Unicoder-VL,Unicoder-VL: A Universal Encoder for Vision and Language by Cross-Modal Pre-Training。[AAAI2020]
- 9.ViLT,ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision[ICML2021]code
- 10.UNIMO,UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning[ACL2021]code
- 11.LightningDOT,LightningDOT: Pre-training Visual-Semantic Embeddings for
Real-Time Image-Text Retrieval[NAACL2021]code - 12.TFS,Thinking Fast and Slow: Efficient Text-to-Visual Retrieval with Transformers[CVPR2021]
- 13.SOHO,Seeing Out of tHe bOx:End-to-End Pre-training for Vision-Language Representation Learning[CVPR2021]code
- 14.VinVL,VinVL: Revisiting Visual Representations in Vision-Language Models[CVPR2021]code
- 15.UC2,UC2: Universal Cross-lingual Cross-modal Vision-and-Language Pre-training[CVPR2021]code
巨模型
- 1.CLIP,Learning Transferable Visual Models From Natural Language Supervision
- 2.WenLan,WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training code
- 3.ALIGN,Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision [ICML2021]
- 4.Florence,Florence: A New Foundation Model for Computer Vision
- 5.M6,M6: A Chinese Multimodal Pretrainer
| 模型 | 参数 | 数据集 |
|---|---|---|
| CLIP | 63 million | 400 million |
| WenLan | 30 million | 1 billion |
| ALIGN | 1.8 billion | |
| Florence | 893 million | 900 million |
| M6 | 100 billion | 60.5 million |
1.ViLBERT

方法
主要思想是输入文本和Faster RCNN region proposal得到的目标类别和标签,首先分别mask文本中的词和图像中的目标,然后预测mask的词以及mask的目标特征和类别,最后是跨模态的匹配。
- Masked Multi-modal Modelling,mask 15%的单词和区域块,masked区域块中有90%的值是0,其他保持不变。回归图像块的特征以及语义标签(求分布)和文本的特征。
- Multi-modal Alignment Prediction,判断文本和图像是否是一对。
实验
- 预训练,数据集是Conceptual Captions。
- Finetune,数据集VQA, VCR, RefCOCO+, and Flickr30k。
2.LXMERT
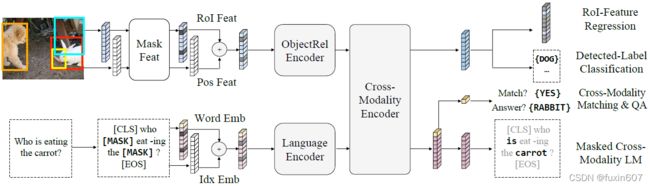
方法
主要思想与ViLBERT相似,输入文本和Faster RCNN region proposal得到的目标类别和标签,首先分别mask文本中的词和图像中的目标,然后预测mask的词以及mask的目标特征和类别,最后是跨模态的匹配和视觉问答。
- Masked Cross-Modality Language Model,
- Masked Object Prediction,
- Cross-Modality Tasks,
实验
- 预训练,数据集是MS COCO, Visual Genome, VQA v2.0, GQA balanced version, and VG-QA这五个数据集的合并。
- Finetune,数据集VQA, GQA, and NLVR2。
3.UNITER
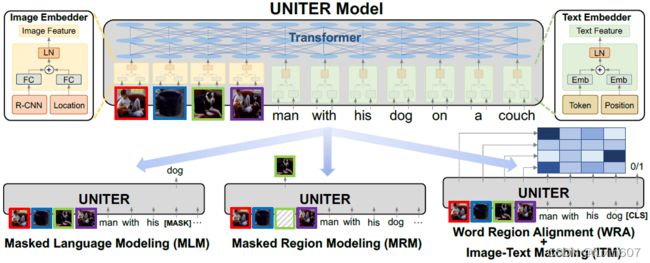
方法
主要思想与ViLBERT相似,输入文本和Faster RCNN region proposal得到的目标类别和标签,首先分别mask文本中的词和图像中的目标,然后预测mask的词以及mask的目标特征和类别,最后是文本与图像以及词与目标的匹配(单路网络)。
- Masked Language Modeling,
- Masked Region Modeling,
- ImageText Matching,
- Word-Region Alignment, 最优传输方法。
实验
- 预训练,数据集是COCO, Visual Genome, Conceptual Captions, and SBU Captions这四个数据集的合并。
- Finetune,数据集VQA, Flickr30K, NLVR2, and RefCOCO+。
4.VisualBERT

方法
这篇文章主要是解释预训练模型学到了什么(实际上就是可视化特征图),输入文本和Faster RCNN region proposal得到的目标类别和标签,mask文本的词并结合文本与视觉特征进行预测,匹配文本与图像特征(单路网络)。
- Masked language modeling with the image,
- Sentence-image prediction,
实验
- 预训练,数据集是COCO
- Finetune,数据集VQA, VCR, NLVR2, and Flickr30K。
5.VL-BERT
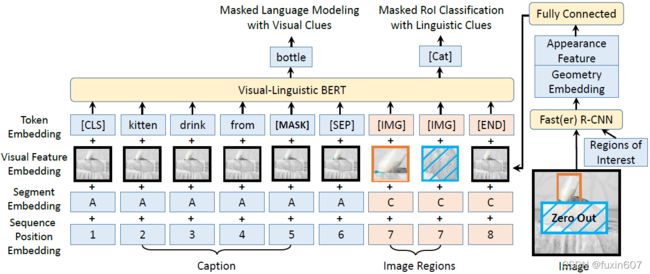
方法
主要思想是将文本的embedding特征和图像faster RCNN的特征中间用特殊字符分开,形成一个整体的输入(类似BERT完整的一句话),然后再进行Masked词预测和Masked目标语义预测(单路)。
- Masked Language Modeling with Visual Clues ,
- Masked RoI Classification with Linguistic Clues ,
实验
- 预训练,数据集是Conceptual Captions and BooksCorpus。
- Finetune,数据集VCR, VQA and RefCOCO+。
6.Oscar
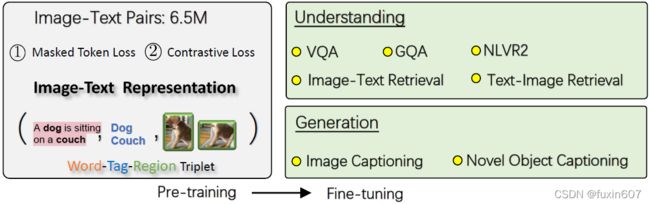
主要思想与ViLBERT相似,输入文本和Faster RCNN region proposal得到的目标类别和标签,首先分别mask文本中的词和图像目标框的语义类别,然后预测mask的词或者类别,最后是文本与图像以及词与目标的匹配(单路)。
- Masked Token Loss,随机mask 15%的词或者目标的语义类别进行预测。
- Contrastive Loss,随机替换50%的语义类别作为负例样本。
实验
- 预训练,数据集是COCO, Conceptual Captions, SBU captions, flicker30k, and GQA这五个数据集的合并。
- Finetune,数据集COCO, NoCaps, VQA, GQA, and NLVR2。
7.ERNIE-ViL
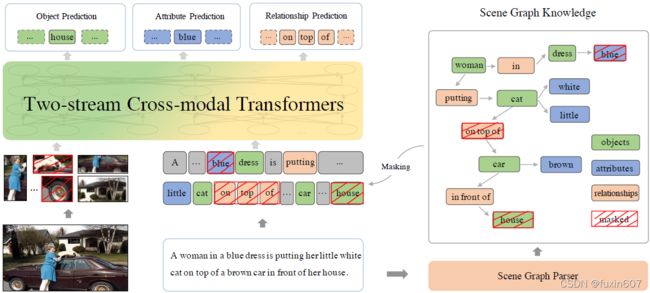
方法
这篇文章尝试从场景图生成的角度预训练模型,首先利用文本生成场景图,然后分别mask Object,Prediction和Relationship,最后对masked的词进行预测,主要分为Object Prediction,Attribute Prediction和Relationship Prediction三部分。
- Object Prediction ,
- Attribute Prediction ,
- Relationship Prediction ,
实验
- 预训练,数据集是Conceptual Captions and SBU Captions。
- Finetune,数据集VCR,VQA,RefCOCO+ and Flickr30K。
8.Unicoder-VL
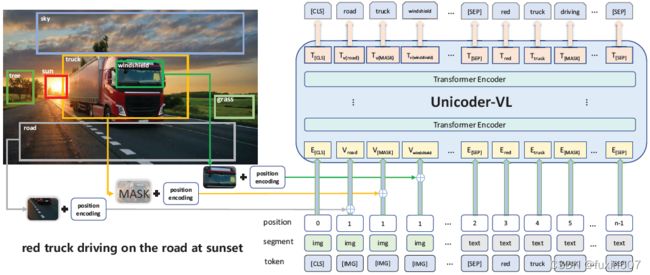
方法
这篇文章思路和之前的方法很像,主要分为三部分Masked Language Modeling (MLM), Masked Object Classifation (MOC)和Visual-linguistic Matching (VLM)。
- Masked Language Modeling (MLM),
- Masked Object Classifation (MOC) ,
- Visual-linguistic Matching (VLM) ,
实验
- 预训练,数据集是Conceptual Captions and SBU Captions。
- Finetune,数据集MSCOCO和Flickr30K。
9.ViLT

方法
这篇文章主要的特点是使用图像patch作为图像的输入,主要分为三部分Image Text Matching,Masked Language Modeling和Word Patch Alignment。
- Image Text Matching,
- Masked Language Modeling,
- Word Patch Alignment,
实验
- 预训练,数据集是Microsoft COCO(MSCOCO),Visual Genome (VG) ,SBU Captions (SBU) 和Google Conceptual Captions (GCC) 。
- Finetune,数据集VQAv2,NLVR2,MSCOCO和Flickr30K。
10.UNIMO
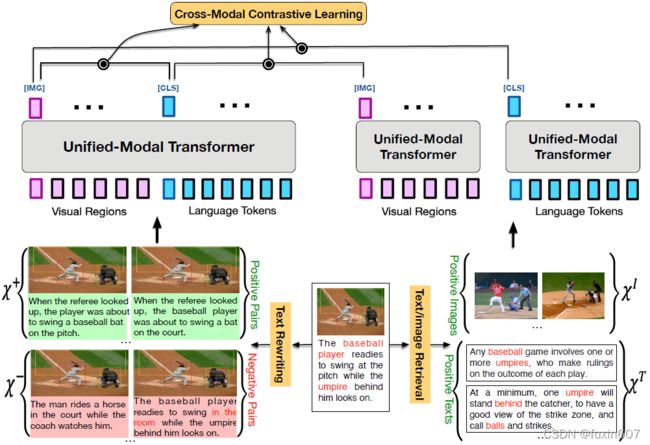
方法
这篇文章任然采用Faster RNN的特征,核心思想是从两个角度对样本进行扩充,分别是引入额外的Image Collections和Text Corpus(基于成对的文本和图像检索单模态的图像和文本,将检索得到的数据作为查询数据的正例样本)以及文本的rewriting技术,方法主要分为三部分Cross-Modal Contrastive Learning,Visual Learning和Language Learning。
- Cross-Modal Contrastive Learning,
- Visual Learning,
- Language Learning,
实验 - 预训练,数据集是BookWiki,OpenWebText,OpenImages,COCO unlabel,COCO,Visual Genome,Conceptual Captions和SBU Captions。
- Finetune,数据集CoQA,SQuAD,CNN/DailyMail (CNNDM) ,Gigaword,SST-2,MNLI,CoLA datase, STS-B,VQAv2.0, Microsoft COCO Captions,SLNI-VE和Flickr30k。
11.LightningDOT

方法
这篇文章从实时性的角度讲故事,核心思想与之前的方法比较相似,主要分为Visual-embedding Fused Masked Language Modeling,Semantic-embedding Fused Masked Region Modeling和Cross-modal Retrieval Objective(finetune时只有这一个loss)。
- Visual-embedding Fused Masked Language Modeling,
- Semantic-embedding Fused Masked Region Modeling,
- Cross-modal Retrieval Objective,
实验
- 预训练,数据集是COCO,VG,Conceptual Captions和SBU captions。
- Finetune,数据集Flickr30k和COCO。
12.TFS
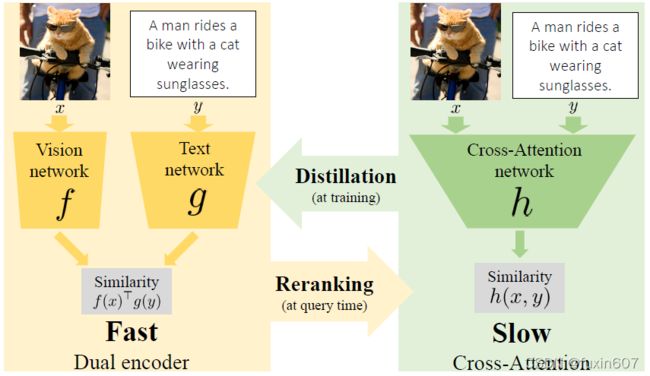
方法
核心思想是分两部进行检索,与LightningDOT类似。
实验
- 预训练,数据集是COCO和Conceptual Captions。
- Finetune,数据集Flickr30k和COCO。
13.SOHO
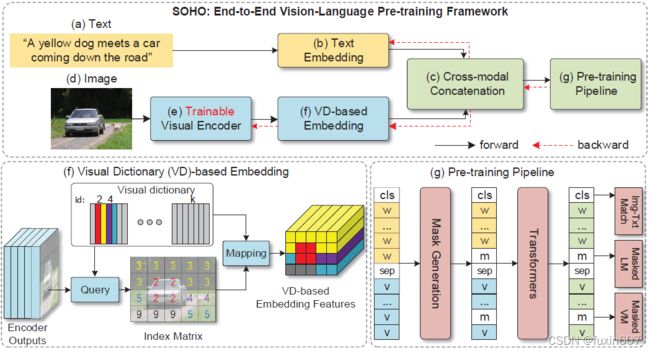
方法
该方法直接提取image-level的视觉特征(非faster RCNN特征),首先提取图像的特征,然后构造视觉字典对图像中的特征进行表示(最近邻搜索),最后再进行跨模态的融合与预训练。方法主要分为Cross-Modal Transformer,Masked Language Modeling和Masked Visual Modeling三部分,
- Cross-Modal Transformer,
- Masked Language Modeling,
- Masked Visual Modeling,
实验
- 预训练,数据集是MSCOCO和VG。
- Finetune,数据集MSCOCO,Flickr30K,VQA2.0,NLVR2和SNLI-VE。
14.VinVL
方法
这篇文章的核心思想是通过提升faster rcnn模型的性能来提升图像的视觉表示,进而提升视觉语言任务。
实验
- 目标检测数据集COCO,OpenImages,Objects365和Visual Genome。
- 预训练,数据集COCO,Conceptual Captions,SBU captions,flicker30k,GQA,VQA,VG-QAs和OpenImages。
- Finetune,数据集VQA,GQA,MS COCO,Novel Object Captioning和NLVR2。
15.UC2
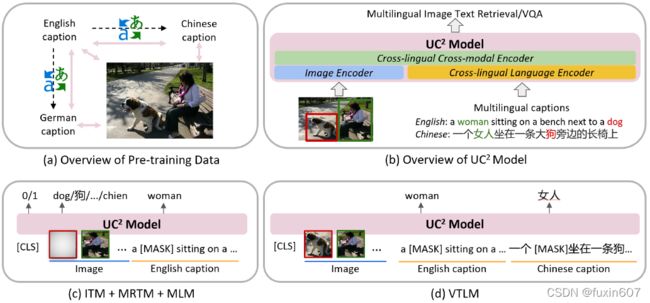
方法
这篇文章的核心思想是将英文的caption翻译成其他语言的caption,然后再进行多语言的学习。
巨模型
1.CLIP

方法
文本分支是ViT(实验中用了5 ResNets和 3 Vision Transformers),图像分支是Transformer,最后通过对比度学习进行训练。
实验
30个不同的视觉数据集。
2.WenLan
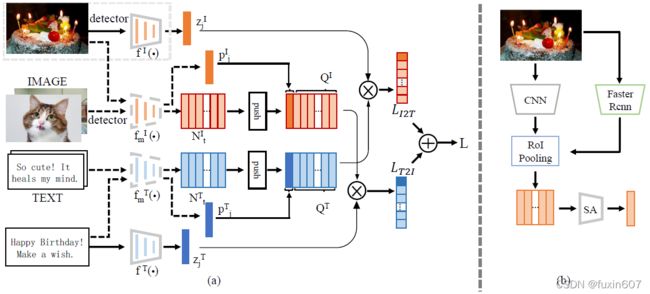
方法
与CLIP比较相似,不同之处在CLIP是在batchsize里面选择负例样本(借鉴MoCo),而wenlan是构造一个额外的字典,专门用于扩充负例样本。
3.ALIGN
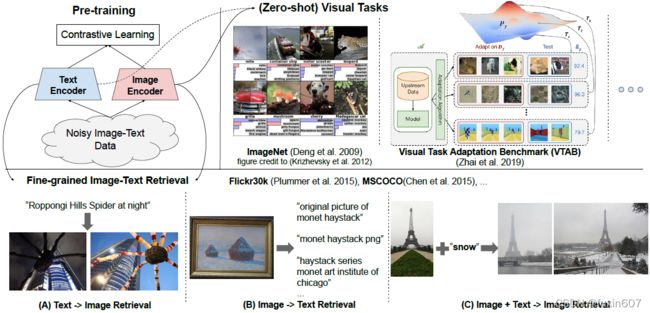
方法
方法上没什么创新,但是证明了语料库规模的巨大提升可以弥补数据内部存在的噪声。
4.Florence
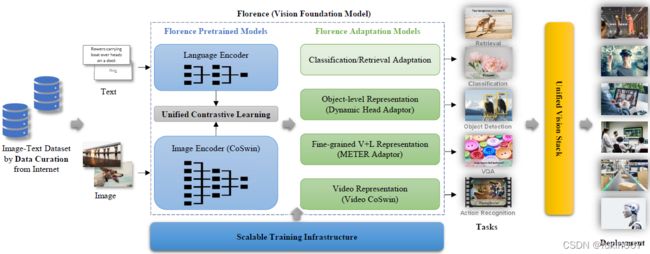
方法
图像主干网络是CoSwin(Swin的修改版),文本的主干网络是Roberta,每一个子注意力块采用协同注意力机制(co-attention),损失函数是掩码语言预测(masked-languag
e modeling )和基于对比度学习的图文匹配( image-text matching)。
5.M6
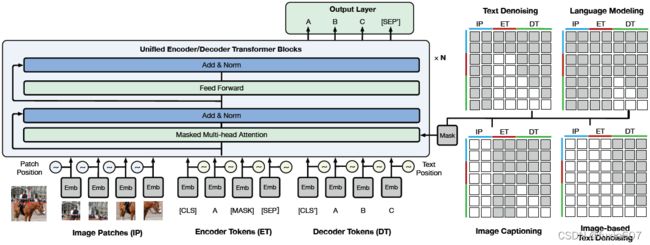
方法
backbone文章中没有明确介绍,图像是patch输入,文本应该是Transformer,训练时采用了4种预训练任务,分别是Text Denoising,Language Modeling,Image Captioning和Image-based Text Denoising。