SLQA论文笔记
Multi-Granularity Hierarchical Attention Fusion Networks for Reading Comprehension and Question Answering 论文笔记
这是阿里2018年发表在ACL上的一篇文章,创新性的使用了层级attention结构,并加入了fusion模块,在SQuAD数据集上取得了优异的表现。
Overview
作者的motivation来源于人类对阅读理解题目的处理:先浏览一遍文章和问题,然后把问题和文章进行联系,接着把答案的大体区间确定下来(这个在雅思阅读里叫定位),最终再次回顾文章和问题(这个在雅思阅读里叫精读)选取出最优答案。从这样的一种模式中作者捕捉到了一种分层理解结构,即文章与问题之间的联系和对文章、问题分别进行深度理解。因此本文核心的部分就是Hierarchical Attention Fusion Network:
- a basic co-attention layer with shallow semantic fusion
- a self-attention layer with deep semantic fusion
- a memory-wise bilinear alignment function
作者也称这种attention机制所学习到的特征是多细粒度的(multi-granularity),通过这种一层一层的attention机制逐渐定位答案。同时,作者对attention function和fusion kernel的改进也对模型效果的提升做出了很大贡献。
Model Architecture
模型大致分为四个部分:
- Embedding & Encoder
- Co-Attention & Fusion
- Self-Attention & Fusion
- Model & Output(the third layer of attention)
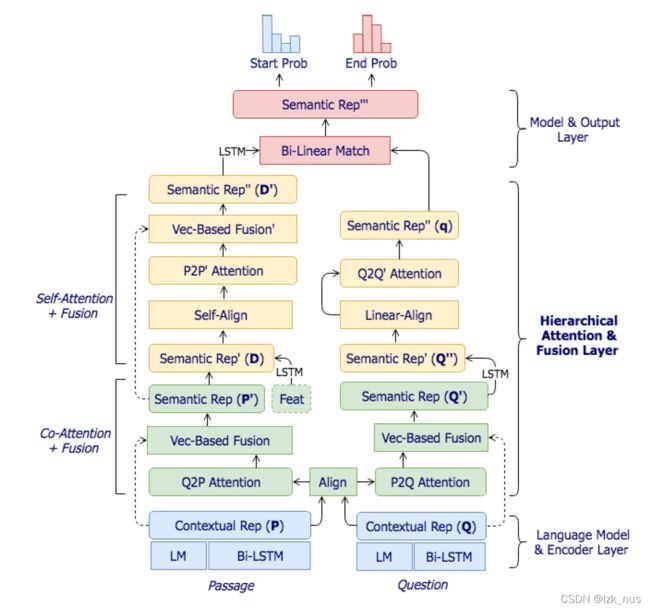
其中,第二、第三和第四中的Model部分共同组成了本文的hierarchical结构。上图就是模型的总体架构,应该来说,这个模型是相对比较复杂的。
Embedding & Encoder
本文一大亮点在于embedding部分,作者依然是word+character embedding,word是Glove,但是character采用的是ELMo,后面的消融实验也证明了ELMo的效果的确是好。得到word embedding e e e和 char embedding c c c后,将它们concatenate起来输入到一个Bi-LSTM中,最终,我们把Bi-LSTM的输出与char embedding拼接起来作为Encoder的输出。
u t P = [ B i L S T M ( [ e t P ; c t P ] ) ; c t P ] u t Q = [ B i L S T M ( [ e t Q ; c t Q ] ) ; c t Q ] P = { u t P } t = 1 n Q = { u t Q } t = 1 m u^{P}_{t}\ =\ [BiLSTM([e^{P}_{t};c^{P}_{t}]);c^{P}_{t}]\\ u^{Q}_{t}\ =\ [BiLSTM([e^{Q}_{t};c^{Q}_{t}]);c^{Q}_{t}] \\ P=\{u^{P}_{t}\}_{t=1}^{n} \ \ \ \ \ Q=\{u^{Q}_{t}\}_{t=1}^{m} utP = [BiLSTM([etP;ctP]);ctP]utQ = [BiLSTM([etQ;ctQ]);ctQ]P={utP}t=1n Q={utQ}t=1m
Co-Attention & Fusion
这一部分计算的是passage与query之间的关系,简单来说就是P2Q和Q2P的双向attention外加一个fusion,这里的fusion是一个创新点。similarity score的计算方式作者也进行了一些改进:
S i j = A t t n ( u i P , u j Q ) = R e L u ( W T u i P ) ⋅ R e L u ( W T u j Q ) S_{ij} = Attn(u^{P}_{i},u^{Q}_{j})=ReLu(W^{T}u^{P}_{i})\cdot ReLu(W^{T}u^{Q}_{j}) Sij=Attn(uiP,ujQ)=ReLu(WTuiP)⋅ReLu(WTujQ)
改进的原因我引用作者原话:This decomposition avoids the quadratic complexity that is trivially parallelizable.
然后P2Q和Q2P的attention就是分别对row和col进行softmax
α i = s o f t m a x ( S i : ) Q ^ = ∑ i = 1 m α i Q i \alpha_{i} \ = \ softmax(S_{i:})\\ \hat{Q} \ =\ \sum_{i=1}^{m} \alpha_{i}Q_{i} αi = softmax(Si:)Q^ = i=1∑mαiQi
β j = s o f t m a x ( S : j ) P ^ = ∑ j = 1 n β j P j \beta_{j} \ = \ softmax(S_{:j})\\ \hat{P} \ =\ \sum_{j=1}^{n}\beta_{j}P_{j} βj = softmax(S:j)P^ = j=1∑nβjPj
接下来是fusion,作者分别将 P P P与 Q ^ \hat{Q} Q^融合, Q Q Q与 P ^ \hat{P} P^融合
P ′ = F u s e ( P , Q ^ ) Q ′ = F u s e ( Q , P ^ ) P' \ =\ Fuse(P,\hat{Q})\\ Q' \ =\ Fuse(Q, \hat{P}) P′ = Fuse(P,Q^)Q′ = Fuse(Q,P^)
融合的kernel选择有很多,比如简单的concat,文中采用的是带有difference和element-wise product的融合
m ( p , q ) = t a n h ( W f [ p ; q ; p ∘ q ; p − q ] ) m(p, q)\ =\ tanh(W_{f}[p;q;p \circ q; p - q]) m(p,q) = tanh(Wf[p;q;p∘q;p−q])
接下来,作者又认为Encoder得到的original的contextual embedding学习了passage与query的全局信息,因此又通过gate将original embedding与fusion feature进行拼接,类似于highway,最终得到的passage、query表示分别为:
P ′ = g ( P , Q ^ ) ⋅ m ( P , Q ^ ) + ( 1 − g ( P , Q ^ ) ) ⋅ P Q ′ = g ( Q , P ^ ) ⋅ m ( Q , P ^ ) + ( 1 − g ( Q , P ^ ) ) ⋅ Q P' \ =\ g(P, \hat{Q}) \cdot m(P,\hat{Q}) + (1-g(P,\hat{Q})) \cdot P\\ Q' \ =\ g(Q, \hat{P}) \cdot m(Q,\hat{P}) + (1-g(Q,\hat{P})) \cdot Q P′ = g(P,Q^)⋅m(P,Q^)+(1−g(P,Q^))⋅PQ′ = g(Q,P^)⋅m(Q,P^)+(1−g(Q,P^))⋅Q
P ′ P' P′可以看作是query-aware的passage representation, Q ′ Q' Q′可以看作是passage-aware的query representation。后面实验部分作者还对比了不同fusion kernel带来的效果差异
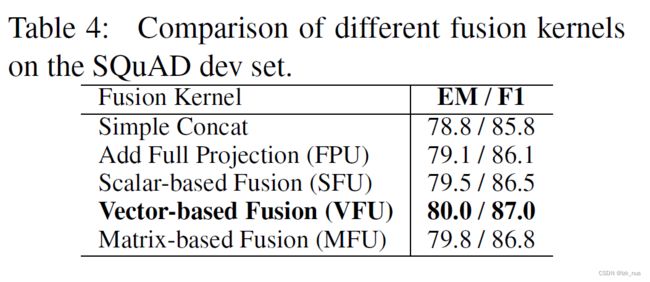

Self-Attention & Fusion
接下来是self-attention的部分,和R-Net的想法一样,作者希望通过self-matching的方法将passage、query对的representation分别进一步增强,学习到一些内在联系。
Passage part
一开始,作者先采用了一个小trick,他把人工特征加入到passage的表示中,也就是现在的passage representation变成了 [ P ′ ; f e a t m a n ] [P';feat_{man}] [P′;featman],然后在把它传到一个Bi-LSTM中得到 D D D
D = B i L S T M ( [ P ′ ; f e a t m a n ] ) D \ =\ BiLSTM([P';feat_{man}]) D = BiLSTM([P′;featman])
虽然叫做self-attention,但作者采用的attention计算方式不是attention is all you need,而是一种bilinear的self-alignment,其实也就是我理解的multiplicative
L = s o f t m a x ( D ⋅ W l ⋅ D T ) D ^ = L ⋅ D L \ =\ softmax(D \cdot W_{l} \cdot D^{T})\\ \hat{D}\ =\ L \cdot D L = softmax(D⋅Wl⋅DT)D^ = L⋅D
然后又是fusion, D ′ = F u s e ( D , D ^ ) D'\ =\ Fuse(D,\hat{D}) D′ = Fuse(D,D^),再把fuse后的 D ′ D' D′传到一个Bi-LSTM中得到这一层里passage的最终表示
D ′ ′ = B i L S T M ( D ′ ) D'' \ =\ BiLSTM(D') D′′ = BiLSTM(D′)
Query part
query的self-alignment与passage有些不同,首先还是将 Q ′ Q' Q′传入到一个BiLSTM中得到 Q ′ ′ Q'' Q′′,然后attention的计算不再是bilinear的,而是简单的linear
γ = s o f t m a x ( w q T Q ′ ′ ) q = ∑ i = 1 m γ i Q i ′ ′ \gamma\ =\ softmax(w^{T}_{q}Q'')\\ q\ =\ \sum_{i=1}^{m}\gamma_{i}Q''_{i} γ = softmax(wqTQ′′)q = i=1∑mγiQi′′
这样得到的query的最终表示变成了一个向量
Model & Output
输出层文章说的是采用了Pointer-Net,但是实际上并不是Pointer-Net的形式,作者在输出的部分又做了一次bilinear的alignment,然后得到start和end的概率分布
p s = s o f t m a x ( q ⋅ W s T ⋅ D ′ ′ ) p e = s o f t m a x ( q ⋅ W e T ⋅ D ′ ′ ) p_s \ = \ softmax(q \cdot W^{T}_{s} \cdot D'')\\ p_e \ = \ softmax(q \cdot W^{T}_{e} \cdot D'') ps = softmax(q⋅WsT⋅D′′)pe = softmax(q⋅WeT⋅D′′)
Experiment & Analysis
在SQuAD数据集上的指标

成功成为了新SOTA,然后是鲁棒性测试

也成功超过了其他所有模型。我们重点来看消融实验和对比试验
Ablation
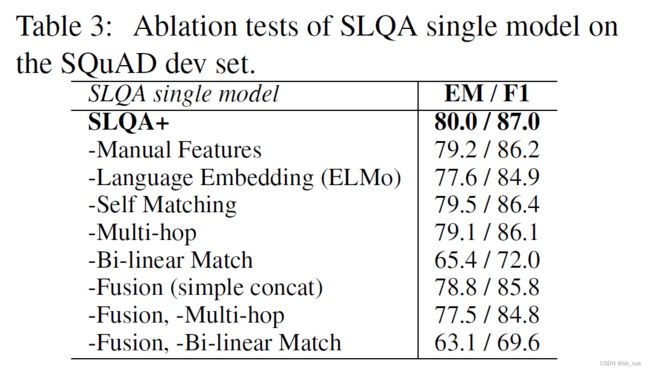
从表格中我们可以看出来,ELMo对模型效果的贡献度相当之高,同时bilinear match也在模型中扮演了非常重要的角色。但我对这个实验有一点异议,我认为对于bilinear match这个部分不应该做消融,毕竟把它消融掉就没有attention了,那效果肯定拉跨。后面的对比试验是正确的
Comparison
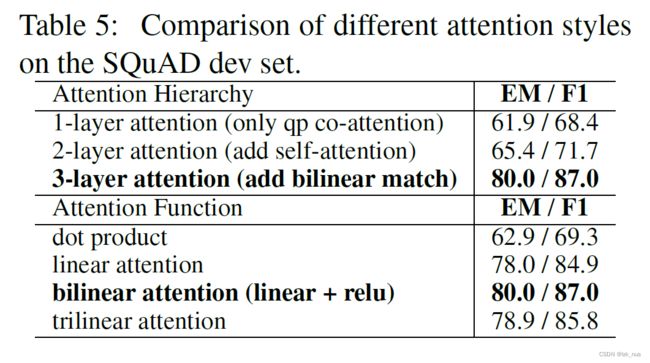
可以看到这里作者做了两个对比:
- 不同层级的attention
- attention function选取
这个对比实验证明了本文的三层hierarchical attention效果是最佳的,并且bilinear attention也是效果最好的。
Reflection
这篇文章我最大的感觉是整体架构与R-Net很像,虽然作者并没有说他们借鉴了R-Net,但是我感觉两者有异曲同工之妙,都采用了这种Embedding - Co-Attention - Self-Matching - Model - Output的架构。实验数据也证明了我的猜想,可以看到R-Net与SLQA之间差距甚微,个人感觉大概率是这个ELMo拉开的差距,当然还有这个fusion加highway也起到了不少作用。本文在最后在输出答案的阶段再对passage和query做了一次alignment是一个创新点,普通的pointer network会直接将两者的向量表示拼接然后传入语言模型,但是这里再通过一个bilinear attention取得了更好的效果。
总的来说这篇文章很系统的总结出了基于MRC的QA模型架构,不同的模型只是在这个架构的某几个部分进行改进。