seed+transformer+finetune+图文融合+VLP+Prompt Learning整合
1.Seed
在神经网络中,参数默认是进行随机初始化的。不同的初始化参数往往会导致不同的结果,如果不设置的话每次训练时的初始化都是随机的,导致结果不确定。当得到比较好的结果时我们通常希望这个结果是可以复现的,如果设置初始化,则每次初始化都是固定的,在pytorch中,通过设置随机数种子也可以达到这么目的。
#固定随机种子 args.seed=SEED(SEED之前已经设置初值,如31)
在设置随机数种子时需在最前面加上
np.random.seed(args.seed) #给numpy也设置随机数种子(没有使用GPU的时候设置的固定生成的随机数)
torch.manual_seed(args.seed) #为CPU设置种子用于生成随机数,以使得结果是确定的
torch.cuda.manual_seed(args.seed) #为当前GPU设置随机种子;
torch.cuda.manual_seed_all()为所有的GPU设置种子。
从每堆种子里选出来的数都是不会变的,从不同的堆里选随机种子每次都不一样,若想每次都能得到相同的随机数,每次产生随机数之前,都需要调用一次seed()。
个人小结:
直接三连即可
np.random.seed(config["general"]["seed"])
torch.manual_seed(config["general"]["seed"])
torch.cuda.manual_seed_all(config["general"]["seed"])
参考
https://www.zhihu.com/question/288350769/answer/1344058217
https://blog.csdn.net/qq_30129009/article/details/102730646
2.Transfomer
注意力机制考虑随意线索
-随意线索被称之为查询(query) 有意识
-每个输入是一个值(value)和不随意线索(key)的对
-通过注意力池化(汇聚)层来有偏向性的选择某些输入
Transformer是一个纯使用注意力的编码-解码器,类似Seq2Seq
Encoder和Decoder都有n个transformer块
每个块里使用多头(自)注意力,基于位置的前馈网络,和层归一化
而Bert是一个双向12层block的Transfomer,且只有Encoder(同时输入两句话,采用,分开)
多了个segment编码,和位置嵌入是可学习的
任务则是完形填空和预测下一句子,所以只能用来预训练。
图像做Transfomer可以吗?->图像标注与监督问题
一般认为,图像级的标注是弱标注(例如图像分类的类别标注),像素级的标注是强标注(例如分割标注的mask标注),对于普通的分割任务来说:数据是图像,标注是mask,这属于完全监督问题Supervised;如果标注是annotations或者图像级标注,这属于弱监督问题Weakly-supervised;如果标注只有少部分是mask,剩余是annotations或者图像级标注,这属于半监督问题Semi-supervised。
图片转token
(1)首先是ViT简单粗暴的patch划分,以及MLP映射,变成了一个个的image token。这是目前的主流方案,包括各种多模态算法,如CLIP等只要用到ViT结构都是原样照搬;
(2)后续BEiT使用离散VAE来生成image token;
(3)11月中旬 中科大和MSRA提出的PeCo,引入感知相似性的思想,通过VQ-VAE进行token生成。性能上也略微超过MAE。
PS:VAE即Variational Autoencoders,是一种去压缩数据抽取核心特征的技巧,可以将复杂高维度的数据简化。
Autoencoders通常由编码器和解码器两部分组成。Encoder一般就是几层神经网络(可以是全连接或者是卷积)组成的,它负责压缩输入数据,获得输入数据紧凑低维度的表达形式,我们一般把它的结果称为bottleneck;
Decoder以Encoder输出的bottleneck作为输入,它也由几层全连接或卷积网络组成,它负责重构输入数据。
这个网络的最后步骤就是比较重构后的输入与原始输入的区别,计算reconstruction loss用于训练。
事实上,训练一个编解码器结构的过程就是一种寻找数据压缩方式的过程。
VAE 与 autoencoder 的区别在于,autoencoder 的重构目标是固定的结果向量本身,而 VAE的目标则是输入的分布状况。
在实现过程中,两者之间的唯一差别在于autoencoder 中的 bottelneck 向量,在VAE 中会拆成两个———均值向量和标准差向量。然后使用均值方差参数进行采样,将采样的结果再送入到解码器中。
VAE 的loss通常由两部分组成:

VAE 结构中值得注意的一点是bottleneck之后的采样方式如何选取。有一个问题是普通的采样过程不可以通过backpropogation回传梯度。我们在这里需要用到reparameterization 技巧,我们把结果看成 如下表达,
z = μ + σ ⊙ ε, ε ~ Normal(0,1)
这样就可以计算μ和σ的梯度,epsilon的值我们不需要在意, 把它固定看成正态分布就可以了。
3.Finetune
微调指导事项
1.通常的做法是截断预先训练好的网络的最后一-层( softmax层) , 并用与我们自己的问题相关的新的softmax层替换它。例如, ImageNet上预先训练好的网络带有1000个类别的softmax图层。如果我们的任务是对10个类别的分类,则网络的新softmax层将由10个类别组成,而不是1000个类别。然后,我们在网络上运行预先训练的权重。确保执行交叉验证,以便网络能够很好地推广。
2.使用较小的学习率来训练网络。由于我们预计预先训练的权重相对于随机初始化的权重已经相当不错,我们不想过快地扭曲它们太多。通常的做法是使初始学习率比用于从头开始训练(Training from scratch )的初始学习率小10倍。
3.如果数据集数量过少,我们进来只训练最后一-层 ,如果数据集数量中等,冻结预训练网络的前几层的权重也是一种常见做法。这是因为前几个图层捕捉了与我们的新问题相关的通用特征,如曲线和边。我们希望保持这些权重不变。相反,我们会让网络专注于学习后续深层中特定于数据集的特征。
不同数据集下使用微调
数据集1 - 数据量少,但数据相似度非常高-在这种情况下, 我们所做的只是修改最后几层或最终的softmax图层的输出类别。
数据集2 -数据量少,数据相似度低.在这种情况下,我们可以冻结预训练模型的初始层(比如k层),并再次训练剩余的( n-k )层。由于新数据集的相似度较低,因此根据新数据集对较高层进行重新训练具有重要意义。
数据集3 -数据量大,数据相似度低-在这种情况下,由于我们有一个大的数据集 ,我们的神经网络训练将会很有效。但是,由于我们的数据与用于训练我们的预训练模型的数据相比有很大不同。使用预训练模型进行的预测不会有效。因此,最好根据你的数据从头开始训练神经网络( Training from scatch )。
数据集4 -数据量大,数据相似度高-这是理想情况。在这种情况下,预训练模型应该是最有效的。使用模型的最好方法是保留模型的体系结构和模型的初始权重。然后,我们可以使用在预先训练的模型中的权重来重新训练该模型
4.如何评价FAIR最新研究ViT-based Mask R-CNN? 建议想了解的可以去知乎看下
5.图文融合的趋势,来自知乎 王宁的回复
(1)多模态任务主要分为Align和Fuse两大派系。也有称为light fusion和heavy fusion
前者的fusion方式通常十分简单,如向量内积,代表是CLIP和ALIGN,他们是一种双塔结构,重点在于多模态的对齐,以便于图文匹配、检索等下游任务。
后者的fusion方式便是Transformer,代表有VLP、OSCAR、UNITER、VINVL等,他们可看做是一种单塔结构,重点在于利用attention机制融合多模态信息,可以做更多的任务,可实现VQA、caption等需要信息融合和理解的下游任务,这一点是Align类算法做不到的。但话说回来,这类方法在检索的效率上又不如CLIP,毕竟每一对img-text pair都要经过BERT融合,再用CLS embedding做分类。而CLIP等算法可以预先存储好img和text的特征,再逐一比对即可。
归结而来,用什么算法要看任务而定。而目前也隐隐出现了两类方法一统的趋势:双塔模型作为底座,单塔模型在上层融合,先做好align再做好fusion。
Transformer中的attention,具备着不同特征空间(multi-head)以及全局范围(non-local)的特征聚合能力,确实适合多模特征表达的对齐和融合。
(2)先给结论,王宁个人推荐ALBEF和BLIP,原因两点:端到端模型,单塔和双塔统一。
优秀的"图像+文本"的多模态论文有很多,比如早期的VILBERT [1], LXMERT [2], VLP [3], UNITER [4], Oscar [5]等。这些方法大都借鉴BERT的思想进行masked language modeling对齐多模态,有时加入或干脆使用其它约束,比如Oscar利用目标检测器得到的图片tag作为anchor辅助多模态的对齐,UNIMO主要使用contrastive loss进行多模态对齐。这些方法很优秀,但是主要不足在于,这些框架的图片特征大多都源于目标检测算法,例如Faster RCNN得到的RoI特征,整个框架不是端到端的训练。
趋势是端到端训练(比如CVPR 2021的oral论文SOHO [7]),另外便是单塔和双塔模型的统一。在上一个回答中王宁感觉先做好双塔模型的对齐,再做好单塔的特征融合可能是一种趋势。不久后,王宁就看到这篇"align before fuse" [10],不禁感慨大佬做得真早。论文的主要思想就是利用双塔结构,visual encoder+text encoder(BERT前6层)使用contrastive loss进行对齐,然后再利用BERT的后6层初始化一个单塔模型,进行多模态信息融合,因此该算法可以以双塔形式快速地img-text检索,上面的单塔模型可以做各种VL任务如captioning和VQA。最近这位大佬继续发力,扩展出了BLIP算法 [11]。贴上流程图:
视觉部分是ViT模型, 可以端到端训练。text encoder部分是一个BERT模型,作者巧妙地设计了一个局部模块共享和非共享的策略。当不插入cross-attention模块时,这个BERT模型就充当纯粹的text encoder,因而可以和ViT分支组合成双塔模型,也就是说,上图的前两个分支可组合成一个CLIP的结构。当插入cross-attention模块后,BERT模型就可以以一种相对heavy fusion的方式融合图像和文本特征,可以实现生成等任务,比如image captioning。作者多种任务联合训练,并使用不同的special token来区分不同任务。
[7] Seeing out of the box: End-to-end pre-training for vision-language representation learning. In CVPR, 2021.
[10] Align before fuse: Vision and language representation learning with momentum distillation. In NeurIPS, 2021.
[11] BLIP: Bootstrapping language-image pretraining for unified vision-language understanding and generation. arXiv preprint arXiv:2201.12086, 2022.
试玩地址
https://huggingface.co/spaces/Salesforce/BLIP/tree/main
6.VLP
VLP模型的预训练任务可以分为两类:图像-文本对比学习任务和基于语言建模任务
E2E-VLP【目标检测和图像字幕生成,自然语言视觉推理、跨模态检索】
Before:主要采用两步训练过程,即首先使用预训练的目标检测器提取基于区域的视觉特征,然后将图像表示和文本嵌入串联起来作为Transformer的输入进行训练 。
Disadvantage:视觉表示泛化能力弱【目标检测知识受限,限制模型性能 】、以及二阶段pipeline计算效率低下【目标检测提取区域特征非常耗时额外约束模型】
本文提出了第一个用于V+L理解和生成的端到端视觉语言预训练模型(E2E-VLP),在该模型中,作者建立了一个统一的Transformer[Encoder,Decoder]框架,直接从图像像素级学习视觉区域特征和跨模态表示,用于联合学习视觉表示和图像与文本之间的语义对齐。
E2E-VLP可以灵活地应用于基于编码器模块的视觉语言理解任务 和基于编码器-解码器模块的视觉语言生成任务 。
图像表示
(像素级)CNN主干网络来从图片中提取低分辨率的特征图。然后在使用一个1x1的卷积将通道维度降低,得到新的特征图。由于Transformer编码器需要输入一个一维的序列,因此还需要把特征图在空间维度上进行flatten得到。并加入了位置信息,得到最终的图像表示。(Transformer对位置不敏感)
跨模态的编码器预训练
Transformer学习图像grid特征和语言token之间的跨模态注意。为实现细粒度的特征级语义融合,将图像特征和文本嵌入concat构成输入序列(Pretrain task:MLM,ITM)
MLM设的15%,除了context还借助图特征进行预测,以解决歧义
ITM随机采样50%不匹配的图文对和50%匹配的对,并基于encoder最后一层的[CLS] token,来训练分类器进行预测图像和句子是否相互匹配。
视觉增强解码器
CNN特征图没有对象级语义,很难将其与语言嵌入之间的跨模态语义直接对齐。而Transformer解码器能来帮助捕捉视觉特征的细粒度语义。目标检测和图像字幕共享相同的解码器注意参数,但使用不同的head。
Joint Training:用所有编码器和解码器的预训练任务(即掩蔽语言建模、图文匹配、目标检测、图像字幕)联合对E2E-VLP进行预训练,最小化以下四个损失函数。
优点:
1.端到端联合学习图像和文本之间的视觉表示和语义对齐,去除目标检测器的依赖,因为它不仅降低了模型的预测速度 ,目标检测任务中预定义的类别也会成为各种多模态任务的瓶颈 ,此外,区域特征中对于区域外的上下文特征捕获能力也较差 。
2.提出使用了可扩展性更强和更有效的grid特征来进行视觉语言预训练。但其不能获取图像的对象级信息了,所以作者又提出了两个任务来克服这个缺点,即目标检测和图像字幕。目标检测用于捕获对象级的视觉特征,图像字幕用于将不同的对象与文本对齐,以增强跨模态表示。
异议的点:
- 细粒度特征融合就只是I和T的feature concat?
- 如果多借助图特征预测mask value,是不是应该多mask
3.匹配和不匹配的图文对如何确定,这里大概率是数据内提前预定义好,或者自己制造的不匹配(如拿数据中不同对的caption和image) - 不用目标检测和图像字幕,只借助MLM和ITM任务是否行得通
FILIP【细粒度交互式语言-图像预训练】
Before:要不然是通过每个模态全局相似度(ROI感兴趣区域)对跨模态交互建模,but缺乏充足信息;或者使用基于视觉和文本token的交叉/自注意力对跨模态(细粒度)交互建模。然而,交叉/自注意力在训练和推理过程中效率低下。
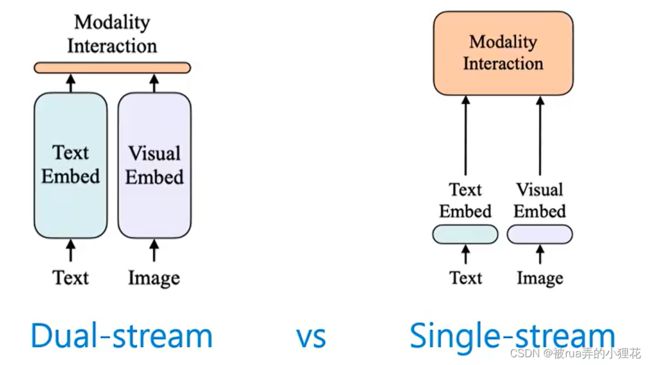
也就是单双塔模型,双塔交互程度低,模型参数集中在各模态编码器中,Efficent,灵活部署在下游任务上,不过是全局特征(整句话和图)对齐。单塔细粒度对齐带来笨重低效。
在本文中,引入一种大规模细粒度交互语言-图像预训练,灵活且高效,通过一种跨模态后交互机制实现更加细粒度的对齐,该机制使用图像patch和文本token之间token最大相似度指导对比目标->来自ColBert。(类似CLIP相似度矩阵,十个文本promt,zeroshot predict)
较为典型的单塔模型有阿里提出的M6,拼接后提交到Transformer中,使得视觉语言模块在前向传播中得到深度交互,并通过4种掩码策略丰富预训练任务,LM
SOHO和SimVLM,试图通过视觉字典或PrefixLM消除这目标检测器可扩展性较低这一负担。
遵循双流方案保证灵活且高效推理的同时,进一步提出了一种新的多模态交互机制用于捕捉细粒度表示。
ImageEncoder:ViT;TextEncoder:根据CLIP使用49408大小的小写Byte Pair Encoding,BPE,序列以[BOS]开始,以[EOS]结束。和GPT2相同,在word embedding层之后,token嵌入被送到仅解码器的Transformer模型中。在图像和文本编码器之上,文本token和视觉token的表示线性投影到多模态公共(语义)空间,并分别进行L2归一化。
细粒度对比学习:效果比预测表征学习好,图文对正样本,其余负样本
跨模态后期交互:比较每个视觉token和所有文本token相似度,选最大,随后使用所有图像(文本)非填充(padding)token的平均token-wise最大相似度作为图像到文本(文本到图像)的相似度,当然I2T和T2I不一定相等.
notice:计算相似度时,排除padding文本token,因为损害性能,且用均值而非sum,因为非padding tokens num不一;并用对比损失而非成对损失
Efficient Trick
- embedding from 768/512 to 256(效果提升)
- Use fp16半精度计算和分布式通信
- 两个模态select 25%最相似的tokens用于分布式通信(保证足够的性能)
prompt template<-由于预训练过程中的多义性和不一致的问题
[prefix]{label},[category description].[suffix]
[prefix]”是一个上下文描述,“a photo of a”;“label”是数据集的类标签;“[category description]”描述的是对一些细粒度图像分类数据集有帮助的类别,“a type of pet”
图像和文本增强,预训练数据集,预训练细节:自动混合精度和梯度检查点
未来工作
其架构和训练过程仍还有进一步优化的空间。在未来,可以使用更加先进的图像编码器和精心设计的交互层来提高性能。此外,可以进一步增加更多的Masked语言/图像Loss以支持更多的生成任务。
近年来,由于基于Transformer的视觉-语言模型的发展,联合文本-图像嵌入得到了显著的改善。尽管有这些进步,我们仍然需要更好地理解这些模型产生的表示。在本文中,我们在视觉、语言和多模态水平上比较了预训练和微调的表征。为此,我们使用了一组探测任务来评估最先进的视觉语言模型的性能,并引入了专门用于多模态探测的新数据集。这些数据集经过精心设计,以处理一系列多模态功能,同时最大限度地减少模型依赖偏差的可能性。虽然结果证实了视觉语言模型在多模态水平上理解颜色的能力,但模型似乎更倾向于依赖文本数据中物体的位置和大小的偏差。在语义对抗的例子中,我们发现这些模型能够精确地指出细粒度的多模态差异。最后,我们还注意到,在多模态任务上对视觉-语言模型进行微调并不一定能提高其多模态能力。我们提供所有的数据集和代码来复制实验。
7.Prompt Learning
1.Prompt-tuning,Prefix-tuning,P-tuning
也许Prompting Tuning会成为Feature Engineering问题,设计合理的Prompts将会很有意思
可以让GPT-3处理各种类型的任务,甚至拥有直接处理零样本和小样本学习能力。
prompting 更加依赖先验,而 fine-tuning 更加依赖后验。
Fine-tuning中:是预训练语言模型“迁就“各种下游任务。具体体现就是通过引入各种辅助任务loss,将其添加到预训练模型中,然后继续pre-training,以便让其更加适配下游任务,这个过程中,预训练语言模型做出了更多的牺牲。
Prompting中,是各种下游任务“迁就“预训练语言模型。具体体现将人为的规则给到预训练模型,使模型可以更好地理解人的指令的一项技术,我们需要对不同任务进行重构,使得它达到适配预训练语言模型的效果,这个过程中,是下游任务做出了更多的牺牲。
Fine-tune(110亿)需要为每个下游任务都存下整个预训练模型的副本,并且推理必须在单独的批次中执行。
参数量要小很多(5个数量级,20K),只需要为每个任务存储一个特定于下游任务的小单元,并使用原始的预先训练过的模型启用混合任务推理即可。
thinking: 多任务可能更适合,但如果做单个特定的下游任务的话,
cloze prompt([z]在句中)。适合使用掩码 (Mask) LM 解决的任务。
prefix prompt([z]在句末)。适合有关生成的任务或使用标准自回归 LM 解决的任务,因为它们与模型从左到右的性质刚好吻合。
suffix prompt (),前缀是CLIP, prompt 模板则必须包含至少两个输入的空间
如方面级情感分析是Text-span CLS类型,Template为[X]What about service?[Z],人工设计模板或者自动化搜索模板
answer 工程的目的是搜索一个 answer 空间 Z 和一个到原始输出 Y 的映射,从而得到更细粒度的预测模型。
有效性:prompt 可以看做是对预训练语言模型中已经记忆的知识的一种检索方式,其任务形式就是预训练任务,因此predicate时得到“提示,所需使用的信息量更多,所以样本的类别分布在prompt视角下都是稀疏的->few shot效果显著
Prefix-Tuning:提出任务特定的trainable前缀prefix,这样直接为不同任务保存不同的前缀即可。因此实现上只需要存储一个大型transformer模型和多个学习的任务特定的prefix参数。
对于自回归模型,加入前缀后的模型输入表示:z = [ P R E F I X ; x ; y ] z=[PREFIX;x;y]z=[PREFIX;x;y]
或者为编码器和编码器都添加prefix:z = [ P R E F I X ; x ; P R E F I X ′ ; y ] z=[PREFIX;x;PREFIX’;y]z=[PREFIX;x;PREFIX′;y]。
“GPT Understands, Too“ P-tuning V1首次提出了用连续空间搜索的 embedding 做 prompt。
不关心模版长什么样, 只需要知道模版由哪些 token 组成,该插入到哪里,插入后能不能完成我们的下游任务,输出的候选空间是什么就可以了。即不关心模版的“自然语言”要求,它只是为了更好地实现“一致性”但不是必须的。
连续的Prefix-Tuning和P-tuning 放弃了“模版由自然语言构成”这一要求,从而将其变成了可以简单梯度下降求解的连续参数问题,效果还更好。
P-tuning在一些复杂的自然语言理解NLU任务上效果很差(任务不通用)+预训练的参数量不能小(规模不通用)。因此V2版本主要是基于P-tuning和Prefix-tuning,引入Deep Prompt Encoding和Multi-task Learning等策略进行优化的。
多模态预训练中的Prompt(MAnTiS,ActionCLIP,CPT,CoOp,ALPRO,Frozen)
Multimodal Conditionality for Natural Language Generation
Prompt用于Natural Language Generation多模态NLG任务。
先从NLG任务过渡到Vision-language的应用吧,这篇文章主要是利用图片信息来增强文本的生成。
ActionCLIP: A New Paradigm for Video Action Recognition
Prompt用于Action Recognition动作识别问题。
在输入端就纳入label信息,将其与对应的视频特征进行关联。这样做不仅可以增强视频表征的语义性,同时能够具备很强的zero-shot的迁移能力。另一个优势是,这种多模态输入完全可以利用现在已经做了大量工作的多模态预训练模型。
“pre-train, prompt, and fine-tune”,模型图如下。pre-train指利用现有的多模态预训练模型,然后改装我们的任务适应模型,最后再在自己的数据集上进行fine-tune。这样的做法,通过prompt保持住pre-trained模型的强大表征性能,又节省了很多的计算资源。
CPT:Colorful Prompt Tuning for Pre-Training Vision-Language Models
Prompt用于Visual Grounding视觉定位问题。在图像和文本中使用共同的颜色来标识,以将视觉定位问题变成填空问题来解决跨模态差异。
Learning to Prompt for Vision-Language Models
CLIP中用到Prompt的地方也是它处理句子-图像对的方式,CoOp实际是在CLIP(图文匹配的双流分支)的基础上进一步进行的改进。不过它受到了AutoPrompt的启发会更多一些,是一个learnable context
模型是不一定需要符合自然语言的连贯性的。learnable context将和不同类别的word embedding拼接之后再进行后面的过程。然后其他地方,image encoder和text encoder和CLIP都比较类似,优化的目标也是使得和图片对应的prompt预测分数最大。
另外还有两种有意思的变体:
1.在class的前后都插入learnable context,以增加prompt的灵活性。
2.设计class-specific context(CSC),让所有类别的prompt参数独立(目前是所有参数都是共享的),实验结果证明这种做法在一些细粒度分类任务中效果更好。
Align and Prompt: Video-and-Language Pre-training with Entity Prompts
ALPRO模型(Align and Prompt),即对齐模态同时给细粒度提示,结合Prompt和对比学习来实施目标软标签。新增视频文本对比损失VTC,和提示实体建模PEM。其中,VTC强调捕获视频文本对的实例级对齐,PEM鼓励模型将局部视频区域与文本实体对齐。
Multimodal Few-Shot Learning with Frozen Language Models
连续的图片prompts,训练时完全固定Language Model,因此反向传播只更新vision encoder的参数,目的是将visual特征拉到文本特征的空间中,实现两个模态的对齐。
Prompting as Multimodal Fusing
在上一篇的基础上解耦提取特征和对齐空间,即把visual encoder也固定,和Language Model一样只理解图像特征,而对齐空间则由prompt向量来做。
只有prompt参数可训练,可以使架构更模块化,并可以灵活调整和加入其他模态。
总结
单模型主要改进BERT的输入,双模型主要做co/cross的BERT。
全图片只能预测特征,masked的精髓在于图片的局部区域,可特征可label。
预训练任务的单模态以mask为主,视频可以打乱帧时序,细化可以到object关系。多模态以语义对齐为主,一直做到caption的细粒度对齐。
大规模,多任务的训练,多显卡高算力。可以看一下OpenAI发布的必看论文 CLIP,DALL-E,论文解读传送门。
下游任务丰富。
个人偏向于单流模型,参数较少较轻便且端到端,性能不差。
异议的点
prompt你到底行不行
prompt从最开始的人工设计模板,到自动prompt再到连续prompt,逐渐变的畸形。
最开始的人工设计模板就是为了利用好BERT的pretrain阶段学习到的MLM能力然后用在下游,但是人工设计模型存在不稳定的问题,自动prompt效果又很差。
于是连续prompt开始表演,连续prompt已经没有prompt的味道了,把prompt弄成向量,通过训练希望模型能自己得到好的prompt向量,其实就是在finetune。
说句实话,到目前为止,我还是「有些失望的」,和我想象的并不一样。在工业落地方面,我们总是希望模型具有解决小样本、快速训练、快速推理的能力。那么prompt解决了吗?其实并没有。
所以prompt行不行,目前来看不如finetune。但是他具有一定的few shot能力,特别是离散prompt。在一些简单的任务是可以直接用离散prompt的方式做到few shot,这其实是利用BERT在pretrain阶段学习到的能力,但是一旦任务过难,那few shot效果会很差,远不如标几条数据finetune一下。这里就是涉及到泛化和精准,你想要一定的泛化性,那就一定牺牲了精准。
最后zeroprompt和T5,基本是把prompt的东西都玩完了,其实就是pretrain阶段和下游阶段是否一致的问题。
- 现在说的解决few-shot甚至zero-shot,基本上都是基于超大参数的模型,推理速度可想而知,以机器问答场景举例,让用户等个几秒钟,是完全不可以接受的。
- 很多论文都是自动模板、自动答案空间映射,并且还是全量参数在训练,训练时长不减反增,真的是心累。有哪些时间,你说我标点数据香不香。
- 反正模型都很大,不是large就是xxlarge,或者一切软模版也是增加了部分参数,或多或少,反正推理时间是没变短。
- 在真实情况下,NER任务中每个类别标个50-100条数据,分类任务中每个类别标个200-300条,都可以达到一个不错的效果,对于公司来说,标这点数据还是可以接受的,那么在这种数据规模下,prompt又能提高多少呢?
- 在5-shot下,不用prompt是30,用了是40,确实提高了10个点,但是40的精读,模型能上线吗?
但是,我们依然要抱有希望,并且要冷静地看待新的技术。我并没有否定Prompt的价值,只是目前我现在很难在资源有限的情况下把它很好地落地,也许是自己的能力有限。
附录(Prompt相关论文)
[1] *Template-free Prompt Tuning for Few-shot NER
Github: https://github.com/rtmaww/EntLM/
[2]IDPG: An Instance-Dependent Prompt Generation Method
[3]Automatic Multi-Label Prompting: Simple and Interpretable Few-Shot Classification
Github: https://github.com/HanNight/AMuLaP
[4]ProQA: Structural Prompt-based Pre-training for Unified Question Answering
[5]On Transferability of Prompt Tuning for Natural Language Processing
Github: https://github.com/thunlp/Prompt-Transferability
[6]PROMPT WAYWARDNESS: The Curious Case of Discretized Interpretation of Continuous Prompts
Github: https://github.com/Alrope123/prompt-waywardness
[7]Learning to Transfer Prompts for Text Generation
Github: https://github.com/RUCAIBox/Transfer-Prompts-for-Text-Generation
[8]*Learning To Retrieve Prompts for In-Context Learning
Github: https://github.com/OhadRubin/EPR
[9]Do Prompt-Based Models Really Understand the Meaning of Their Prompts?
Github: https://github.com/awebson/prompt_semantics
[10]Go Back in Time: Generating Flashbacks in Stories with Event Plots and Temporal Prompts
Github: https://github.com/PlusLabNLP/flashback_gen
[11]Probing via Prompting and Pruning
[12]Contrastive Learning for Prompt-based Few-shot Language Learners
Github: https://github.com/yiren-jian/LM-SupCon
[13]Using Natural Sentence Prompts for Understanding Biases in Language Models
[14]Zero-Shot Event Detection Based on Ordered Contrastive Learning and Prompt-Based Prediction
[15]LiST: Lite Prompted Self-training Makes Efficient Few-shot Learners
Github: https://github.com/microsoft/LiST
[16]Exploring the Universal Vulnerability of Prompt-based Learning Paradigm
Github: https://github.com/leix28/prompt-universal-vulnerability
[17]Prompt Augmented Generative Replay via Supervised Contrastive Learning for Lifelong Intent Detection
[18]RGL: A Simple yet Effective Relation Graph Augmented Prompt-based Tuning Approach for Few-Shot Learning
[19]On Measuring Social Biases in Prompt-Based Learning
[20]Few-Shot Self-Rationalization with Natural Language Prompts
Github: https://github.com/allenai/feb
[21]SEQZERO: Few-shot Compositional Semantic Parsing with Sequential Prompts and Zero-shot Models
Github: https://github.com/amzn/SeqZero
[22]PromptGen: Automatically Generate Prompts using Generative Models