训练NeRF模型的几个建议
原文instant-ngp/nerf_dataset_tips
我们实现所需的初始相机参数在transforms.json里提供,格式和NeRF: Neural Radiance Fields是兼容的。为此我们提供了脚本scripts/colmap2nerf.py来方便这些工作,它可以用来处理视频或者序列图片,基于开源的COLMAP运动获取信息法来获取必要的数据。
训练过程对数据非常挑剔,为了获得好的结果,不能包含错误标注的数据,不能含有模糊的帧(运动模糊和失焦模糊都不行),本文试图给出一些建议,一个好的准则是如果在20秒之内你的模型还没收敛,那么即使训更长的时间也不会有更好的结果。因此我们建议在开始的时候调整数据获取满意的结果。大多数的收敛发生在最开始的几秒之内。
数据集最常见的问题是相机位置的比例或偏移不正确。更多详细信息,请参见下文。另一个常见的问题是图像太少,或者图像的相机参数不准确(例如,如果COLMAP失败)。在这种情况下,您可能需要获取更多图像,或调整相机位置的计算过程,这(colmap失败)超出了本文的范围。
现有数据集
默认情况下,instant-ngp 的 NeRF 实现仅通过从[0,0,0]到[1,1,1]的单位包围框行进光线步进。默认情况下,数据加载程序在输入 JSON 文件中读取摄像机变换矩阵,并缩放位置0.33和偏移[0.5,0.5,0.5],以便将输入数据的来源映射到此立方体的中心。选择比例因子是为了适应原始NerF论文中的合成数据集,以及我们的script/ colmap2nerf.py脚本的输出。
通过在 UI 的"调试可视化"汇总中同时选中"可视化相机"和"可视化单位立方体",检查相机与此边界框的对齐情况是很有必要的,如下所示:
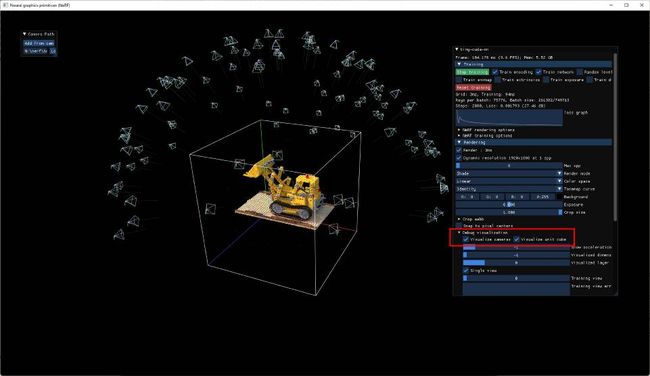
对于在单位立方体外部可见背景的自然场景,有必要在最外层的作用域(与现有参数相同的嵌套)将文件中的参数aabb_scale设置为 2 的幂到 128(即 1、2、4、8 ...128)。有关示例请参阅data/nerf/fox/transforms.json。
效果可以在下图中看到:
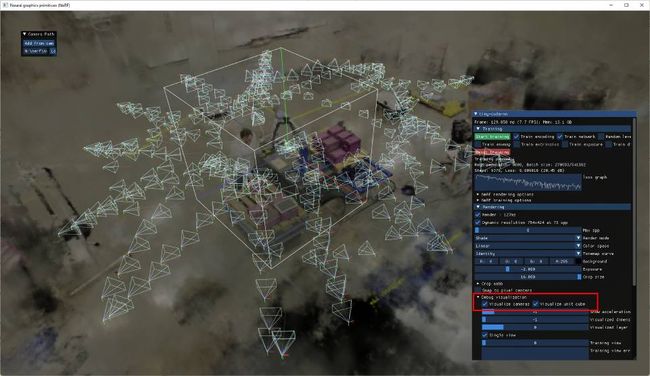
相机仍然在某种程度上集中在单位立方体内的"感兴趣对象"上;但是,aabb_scale参数(此处设置为 16)会导致 NeRF 实现将光线追踪到一个更大的边界框(边长为 16),其中包含以 为中心的背景元素。
扩充现有数据集
如果你已经有一个transforms.json的数据集,则应将其居中,并且其比例应与原始 NeRF 合成数据集相似。当您将其加载到NGP中时,如果您发现它没有收敛,首先要检查的是相机相对于单元立方体的位置,使用上述调试功能。如果数据集没有主要落在单位立方体中,则值得将其移动到该单位立方体。您可以通过调整转换本身来执行此操作,也可以将全局参数添加到 json 的外部范围。
您可以设置以下任何参数,其中列出的值是默认值。
{
"aabb_scale": 16,
"scale": 0.33,
"offset": [0.5, 0.5, 0.5],
...
}
有关实现详细信息和其他选项请参阅nerf_loader.cu。
准备新的 NeRF 数据集
请确保您已安装 COLMAP,并且它在 PATH 中可用。如果您使用视频文件作为输入,请确保安装 FFmpeg 并确保它在 PATH 中可用。要检查是否属于这种情况,从终端窗口中,您应该能够运行并查看每个窗口的一些帮助文本。colmapffmpeg -?
如果从视频文件进行训练,请使用以下建议参数从包含视频的文件夹中运行 scripts/colmap2nerf.py 脚本:
data-folder$ python [path-to-instant-ngp]/scripts/colmap2nerf.py --video_in --video_fps 2 --run_colmap --aabb_scale 16 上述假设单个视频文件作为输入,然后以指定的帧速率(2)提取帧。建议选择可生成约 50-150 张图像的帧速率。所以对于一分钟的视频,--video_fps 2是可以的。
对于从图像进行训练,请将它们放在名为images的文件夹中,然后使用合适的选项,如下所示:
data-folder$ python [path-to-instant-ngp]/scripts/colmap2nerf.py --colmap_matcher exhaustive --run_colmap --aabb_scale 16该脚本将根据需要运行 FFmpeg 和/或 COLMAP,然后执行到transforms.json所需格式的转换步骤,该步骤将写入当前目录。
默认情况下,该脚本使用"顺序匹配器"调用 colmap,该匹配器适用于从平滑变化的相机路径拍摄的图像,如在视频中。如果图像没有特定顺序,则穷举匹配器更合适,如上面的图像示例所示。有关更多选项,可以使用 运行脚本。有关COLMAP的更高级用途或具有挑战性的场景,请参阅COLMAP文档;您可能需要修改script/colmap2nerf.py脚本本身。
aabb_scale参数是instant-ngp最重要的特定参数。它指定场景的范围,默认为1;也就是说,对场景进行缩放,使摄像机位置与原点的平均距离为 1 个单位。对于小型合成场景(如原始 NeRF 数据集),aabb_scale默认值 1 是理想的,可以实现最快的训练。NeRF 模型假设训练图像完全可以由此边界框中包含的场景来解释。但是,对于背景超出此边界框的自然场景,NeRF模型将挣扎,并可能在框的边界处产生幻觉"漂浮物"。通过设置aabb_scale为更大的 2 次幂(最多 16 次方),NeRF 模型会将光线扩展到更大的边界框。请注意,这可能会略微影响训练速度。如果有疑问,对于自然场景,请从16开始,然后尽可能减少它。该值可以直接在输出文件transforms.json中编辑,而无需重新运行 scripts/colmap2nerf.py 脚本。
假设成功,您现在可以按如下方式训练 NeRF 模型,从文件夹开始:
instant-ngp$ ./build/testbed --mode nerf --scene [path to training data folder containing transforms.json]NeRF 训练数据提示
NeRF模型最适合50-150张图像,这些图像表现出最小的场景运动,运动模糊或其他模糊伪影。重建的质量取决于COLMAP能够从图像中提取准确的相机参数。有关如何验证这一点的信息,请查看前面的部分。
该脚本colmap2nerf.py假定训练图像都近似地指向一个共享的兴趣点,该兴趣点位于原点。该点是通过对所有训练图像对的中心像素采取光线之间最接近的接近点的加权平均值来发现的。在实践中,这意味着当训练图像被捕获指向感兴趣对象的训练图像时,脚本效果最佳,尽管它们不需要完成完整的360度视图。如上所述,如果设置aabb_scale为大于 1 的数字,则感兴趣对象后面的任何可见背景仍将被重建。