理解ES的refresh、flush、merge
一、refresh
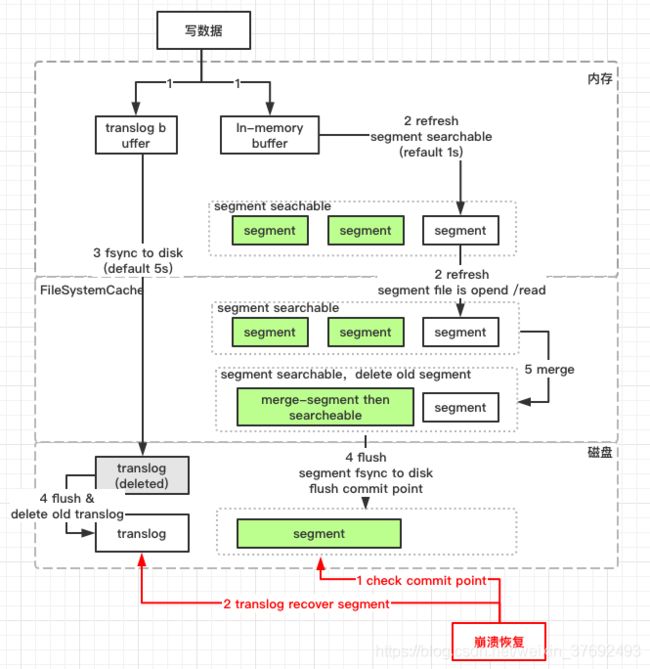
对于任何数据库的写入来讲fsync刷盘虽然保证的数据的安全但是如果每次操作都必须fsync一次,那fsync操作将是一个巨大的操作代价,在衡量对数据安全与操作代价下,ES引入了一个较轻量的操作refresh操作来避免频繁的fsync操作。
1.1 什么是refresh
在ES中,当写入一个新文档时,首先被写入到内存缓存中,默认每1秒将in-memory index buffer中的文档生成一个新的段并清空原有in-memory index buffer,新写入的段变为可读状态,但是还没有被完全提交。该新的段首先被写入文件系统缓存,保证段文件可以正常被正常打开和读取,后续再进行刷盘操作。由此可以看到,ES并不是写入文档后马上就可以搜索到,而是一个近实时的搜索(默认1s后)。
如图,文档被写入一个新的段后处于searchable状态,但是仍是未提交状态
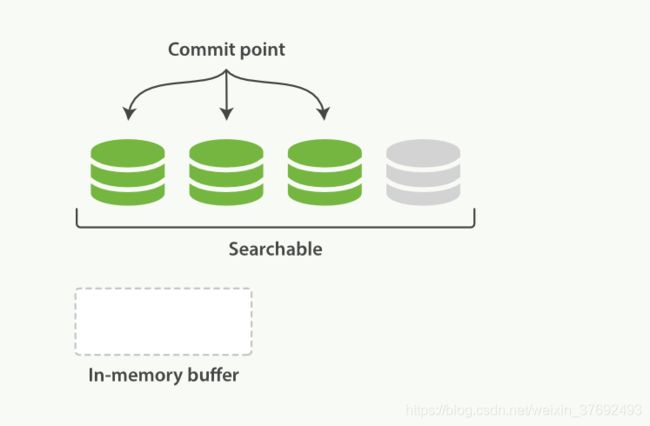
文档写入内存缓存区中,默认每1s生成一个新的段,这个写入并打开一个新段的轻量的过程叫做 refresh。
虽然refresh是一个较轻量的操作,但也是有一定的资源消耗的,必要时刻可以手动执行refresh api保证文档可立即被读到。生产环境建议正确使用refresh api,接受ES本身1s后可读的近实时特性。
1.2 refresh api的使用
-
-- refresh全局索引 -
POST /_refresh -
-- refresh指定索引 -
POST /blogs/_refresh
1.3 refresh相关参数设置
- refresh_interval 控制索引refresh频率
默认为1s,可根据实际业务场景设置为n u m {num}num{时间单位},表示索引每${num}s进行一次refresh;若设置为-1表示关闭refresh。
refresh_interval参数设置时是填写具体的一个持续时间值,若该参数设置为1则表示每1毫秒进行一次refresh,若设置不当会导致整个ES集群处于瘫痪状态
-
PUT /my_logs -
{ -
"settings": { -
"refresh_interval": "30s" //设置每30s进行一次refresh -
} -
}
合理设置refresh_interval参数,在生产环境中,若我们需要创建一个大索引,可设置该参数为-1,开始使用时再开启参数,减少创建索引时refresh的消耗
1.4 refresh特点
不完整提交(因为没有刷盘)
refresh资源消耗相对较小,避免每次文档写入fsync导致资源上的瓶颈
默认每1s进行一次refresh,refresh后的段可以被打开,实现近实时搜索
二、flush
即使通过每秒refresh实现了近实时搜索,但refresh无法保障数据安全,我们仍然需要经常进行完整提交来确保能从失败中恢复。flush就是一次完全提交的过程,一次完整的提交会将段刷到磁盘,并写入一个包含所有段列表的提交点。Elasticsearch 在启动或重新打开一个索引的过程中使用这个提交点来判断哪些段隶属于当前分片,保证数据的安全。
为此ES增加了一个 translog ,或者叫事务日志,在每一次对 ES的变更操作除写入内存缓存外还会写入到translog中,translog周期性刷盘,保证变更的持久性。
2.1 什么是translog
translog就是ES的一个事务日志,当发生一个文档变更操作时,文档不仅会写入到内存缓存区也会同样记录到事务日志中,事务日志保证还没有被刷到磁盘的操作的进行持久化。translog持久化后保证即使意外断电或者ES程序重启,ES首先通过磁盘中最后一次提交点恢复已经落盘的段,然后将该提交点之后的变更操作通过translog进行重放,重构内存中的segment。
translog也可以被用来实时CRUD搜索,当我们通过_id进行查询/更新/删除文档时,ES在检索该文档对应的segment时会优先检查translog中最近一次的变更操作,以便获取到最新版本的文档记录。
2.2 translog基本流程
- 一个文档被索引之后,就会被添加到内存缓冲区,并且追加到了translog
- 默认每秒refresh一次,refresh会清空内存缓存,但是不会清空translog
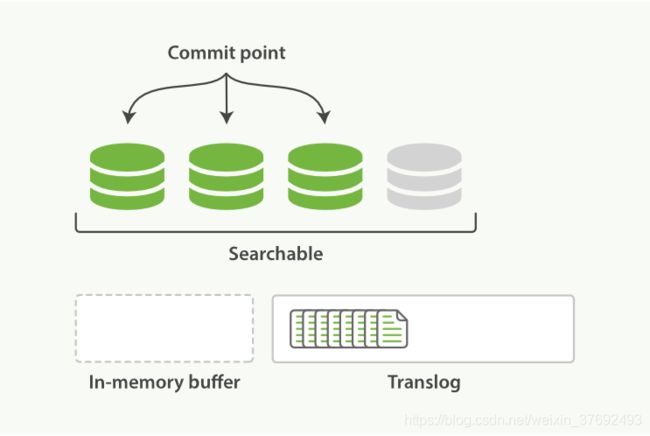
- refresh操作不断发生,更多的文档被添加到内存缓冲区和追加到translog
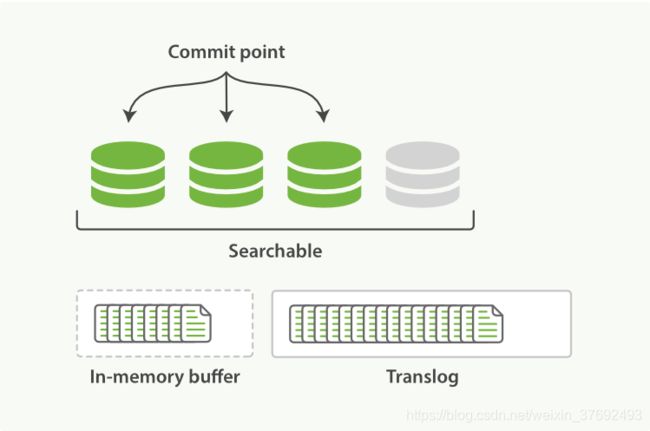
- translog周期性通过fsync进行刷盘,默认5s,可通过参数index.translog.sync_interval、index.translog.durability控制,保证应用重启后先确认最后记录的commit point,commit point之后的变更操作通过落盘的translog进行重构恢复段
- 默认当translog太大(512MB)时,进行flush操作
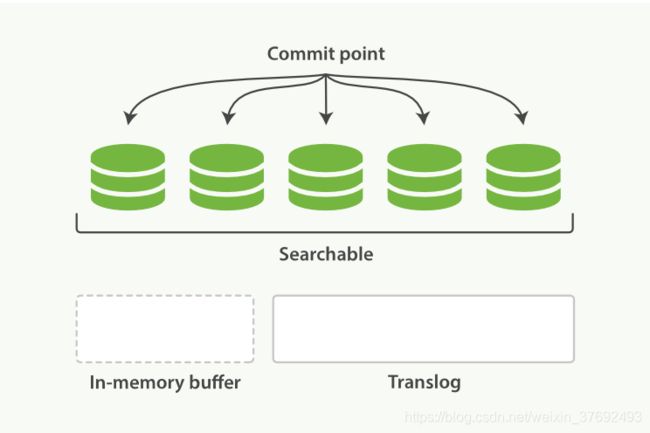
2.3 什么是flush
将translog中所有的段进行全量提交并对translog进行截断的操作叫做flush,flush操作期间会做的事项主要有:
- 强制refresh,将内存缓冲区所有文档写入一个新的段,写入到文件系统缓存并将旧的内存缓冲区被清空(refresh)
- 将最新的commit point写入磁盘
- 将文件系统缓存中的段通过fsync进行刷盘
- 删除老的translog,启动新translog
2.4 flush api的使用
一般来讲自动刷新就足够了,很少需要自己手动执行 flush 操作。
-
POST /blogs/_flush -
POST /_flush?wait_for_ongoing
2.5 flush 相关参数设置
-
index.translog.sync_interval -
translog通过fsync刷盘的的频率,默认5s,不允许设置100ms以内 -
index.translog.durability -
request(default):默认每次请求(index, delete, update, or bulk request)后都进行fsync和commit -
async:每间隔sync_interval进行一次fsync和commit -
index.translog.flush_threshold_size -
translog最大达到512MB的时候强制进行flush操作,flush后将commit point进行刷盘,保证数据安全
2.6 flush的特点
refresh会清空内存缓存,但是不会清空translog
flush操作将文件系统缓存中的segment进行fsync刷盘,并更新commit point
当程序意外重启后,es首先找到commit point,然后通过translog重构commit point之后的segment
三、merge
每次refresh操作都会生成一个新的segment,随着时间的增长segmengt会越来越多,这就出现一个比较严重的问题是每次search操作必须依次扫描所有的segment,导致查询效率变慢,为了避免该问题es会定期多这个segment进行合并操作。
3.1 什么是merge
将refresh产生的多个小segment整合为一个大的segment的操作就叫做merge。同时merge操作会将已经打.del标签的文档从文件系统进行物理删除。merge属于一个后台操作。
在es中每个delete操作其实都是对将要删除的文档打一个.del的标签,同理update操作就是将原文档进行.del打标然后插入新文档,只有merge操作才会将这些已经打标的.del文件真正进行物理删除。
一个大segment的merge操作是很消耗CPU、IO资源的,如果使用不当会影响到本身的serach查询性能。es默认会控制merge进程的资源占用以保证merge期间search具有足够资源。
3.2 merge操作相关流程
- refresh操作会相应的产生很多小的segment文件,并刷入到文件系统缓存(此时文件系统中既有已经完全commit的segment也有不完全提交仅searchable的segment)
- es可以对这些零散的小segment文件进行合并(包含完全提交以及searchalbe的segment)
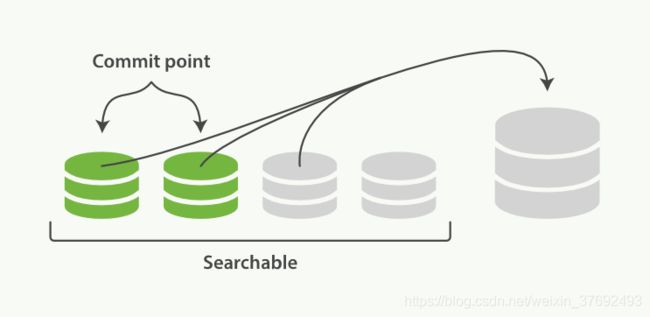
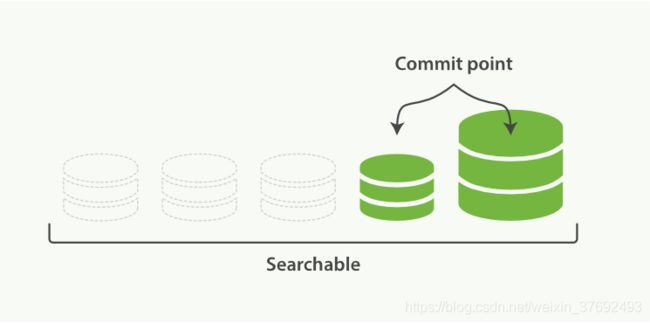
- es会对merge操作后的segment进行一次flush操作,更新磁盘cpmmit point
- 将merge之后的segment打开保证searchalbe,然后删除merge之前的零散的小segment
3.3 相关参数API
optimize API通过对max_num_segments参数对merge操作进行控制,默认该参数为1,控制每次merge仅对1个segment进行合并,保证原有的search操作资源充足。
POST /logstash-2014-10/_optimize?max_num_segments=1 max_bytes_per_sec为限制每次merge操作的带宽限制,默认20MB每秒。若生产环境使用SSD或者es日志中发现“now
throttling indexing”相关INFO等级等信息,可适当调大该参数。
indices.store.throttle.max_bytes_per_sec3.4 merge的特点
对文件系统中零散的小segment进行合并,合并为一个大的segment,减少search期间依次扫描多个segment带来的资源消耗
merge操作会消耗CPU、IO资源,ES对于merge操作相对比较保守,会控制每次merge操作的带宽限制
merge操作不适用于频繁更新的动态索引,相反他更适合只有index的日志型索引,定期将历史索引segment进行合并,加快search效率