机器学习的分类
1、一般分类
机器学习的一般分类为:监督学习、无监督学习、强化学习、半监督学习、主动学习。
1.监督学习
监督学习是从
a.输入空间、特征空间、输出空间、假设空间
输入、输出所有可能的取值的集合分别称为输入空间、输出空间。
一个具体的输入是一个实例,通常由特征向量表示,特征向量组成的空间为特征空间。特征空间与输入空间可以为同一空间,也可以为不同空间。
输入输出的随机变量一般用大写X、Y表示,具体实例使用小写表示。
输入实例x的特征向量表示为:
其中上标表示第几个特征,一般下标表示第几个实例。
而用于学习的训练集格式如下:
测试所用的格式也如上一样,输入输出对又称为样本或样本点。
假设空间即是所有可能的模型的集合。
监督学习中假设训练数据与测试数据是依联合分布P(X,Y)独立同分布产生的,步骤如下图所示:
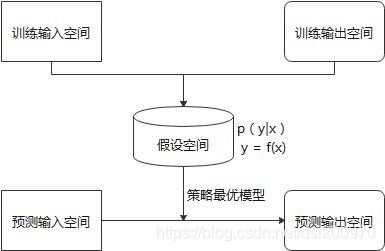
b.一些重要的监督学习算法
- K-近邻(KNN)
- 线性回归
- 逻辑回归
- 支持向量机
- 决策树和随机森林
- 神经网络
2.无监督学习
无监督学习相比监督学习没有标注数据,也就是Y。无监督学习是从一堆数据中学习其内在统计规律或内在结构,学习到的模型可以是类别、转换或概率。这些模型可以实现对数据的聚类、降维、可视化、概率估计和关联规则学习。
假设X为输入空间,Z为隐式结构空间,则模型可以表示为P(x|z),P(z|x), z=g(x)。无监督学习可以用于对已有数据的分析,也可以对未知数据进行预测。前者可以用作概率估计,后两者用来聚类或降维。
具体步骤如图所示:
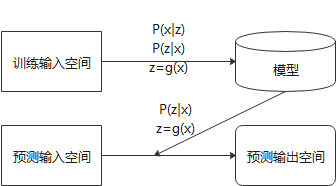
一些重要的无监督学习算法:
a.聚类算法
- k-平均算法(k-means)
- 分层聚类算法
- 最大期望算法(EM)
b.可视化与降维
- 主成分分析(PCA)
- 核主成分分析
- 局部线性嵌入
- t-分布随机近临嵌入
c.关联规则学习
- Apriori
- Eclat
3.强化学习
强化学习是指智能系统在与环境的连续交互中学习最佳行为策略的机器学习问题。例如,机器人学习行走;AlphaGo学习下棋。
强化学习的本质是学习最优的序贯决策。
在每一步t,智能系统从环境中观测到一个状态s和一个奖励r,采取一个动作a。环境根据采取的动作决定下一个时刻t+1的状态和奖励。需要学习的策略表示为给定状态下采取的动作,目标不是短期奖励的最大化,而是长期累积奖励的最大化。

强化学习的马尔科夫决策过程是状态、奖励、动作序列上的随机过程,由五元组
- S是有限状态的集合
- A是有限动作的集合
- P是状态转移概率函数:
- r是奖励函数:
- γ是衰减系数:
马尔可夫决策过程具有马尔可夫性,下一个状态只依赖于前一个动作和状态,由状态转移概率函数表示。下一个奖励依赖前一个状态和动作,由奖励函数表示。
策略π定义为给定状态下的动作的函数a=f(s)或条件概率分布P(a|s)。
价值函数或状态价值函数定义为策略π从某一个状态s开始长期累积奖励的数学期望:
动作价值函数定义为策略π的从某一个状态s和动作a开始长期累积奖励的数学期望:
强化学习的目标是在所有的策略中选择出价值函数最大的策略,而实际中往往从一个具体的策略出发,不断优化现有策略。
| 基于价值 | 基于策略 | |
|---|---|---|
| 有模型的 | 学习过程的模型,包括转移概率函数和奖励函数。 | |
| 无模型 | 求解最优价值函数 | 求解最优策略π |
4.半监督学习
半监督学习包含大量未标注数据和少量标注数据。主要是利用未标注中的信息,辅助标注数据,进行监督学习。
例如说上传的照片都是大量未标注数据,但会有重复的同一个人的照片,可以通过无监督学习进行分类;如果你为其中一份照片标注了信息,则可以为其他未标注的数据标注信息。
大多数半监督学习算法是无监督式和监督式算法的结合,例如深度信念网络(DBN)。它基于一种互相堆叠的无监督式组件,这个组件叫作受限玻尔兹曼机(RBM)。
5.主动学习
主动学习是机器不断给出实例进行人工标注,然后使用标注数据学习预测模型的机器学习问题。主动学习的目标是对学习最有帮助的实例人工标注,以较小的标注代价,达到最好的学习效果。
2、按模型分类
1.概率模型和非概率模型
| 监督学习 | 无监督学习 | |
| 概率模型 | P(y|x)生成模型 | P(z|x),P(x|z) |
| 非概率模型 | y=f(x) 判别模型 | z=g(x) |
| 概率模型 | 非概率模型 | |
| 具体模型 | 决策树、朴素贝叶斯、隐马尔可夫、条件随机场、概率潜在语义分析、潜在狄利克雷分配、高斯混合模型、逻辑斯蒂回归 | 感知机、支持向量机、KNN、AdaBoost、k-means、潜在语义分析、神经网络、逻辑斯蒂回归 |
条件概率函数与决策函数对应的可以互相转化:

二者区别在于模型的内在结构,概率模型一定可以表示为联合概率分布的形式,而非概率模型不一定存在。
概率模型的代表是概率图模型,是联合概率分布由无向图或有向图表示的概率模型,而联合概率分布可以根据图结构分解为因子乘积的形式。贝叶斯、马尔可夫随机场、条件随机场是概率图模型。无论模型如何复杂,均可以使用最基本的加法规则和乘法规则进行概率推理。
加法规则:
乘法规则:
2.线性模型与非线性模型
特别是非概率函数y=f(x)或z=g(x),如果是线性的则为线性模型,否则为非线性模型。
| 线性模型 | 非线性模型 | |
| 具体模型 | 感知机、线性支持SVM、KNN、 K-means、潜在语义分析 |
核函数SVM、AdaBoost、神经网络 |
3.参数化模型和非参数化模型
参数化模型假设模型参数的维度固定,由有限维参数完全刻画;非参数化模型假设参数维度不固定或者无穷大,随训练数据量的增加而不断增大。
| 参数化模型 | 非参数化模型 | |
| 具体模型 | 感知机、朴素贝叶斯、逻辑斯蒂回归、K-means、高斯混合模型 | 决策树、SVM、AdaBoost、KNN、(概率)潜在语义分析、潜在狄利克雷分配 |
3、按算法分类
按算法分类也是看是否可以从传入的数据流中进行增量学习。按照此种分类分为在线学习与批量学习。
批量学习是把所有可用数据进行训练,这需要大量时间和计算资源,通常都是离线完成的。缺点是不能应对快速变化的数据以及较少的计算资源(CPU、内存空间、磁盘空间、磁盘I/O、网络I/O等)。
在线学习是每次接受一个或者小批量的数据,进行训练,整个过程通常是离线完成的,可以将其当做增量学习。
利用随机梯度下降的感知机学习算法就是在线学习算法。在线学习算法通常比批量学习更难,很难学到预测准确率更高的模型。
4、按技巧分类
1.贝叶斯学习
贝叶斯学习主要想法是在概率模型的学习和推理中,利用贝叶斯定理,计算在给定数据条件下模型的条件概率,即后验概率,并应该这个原理进行模型的估计和对数据进行预测。使用模型的先验分布是贝叶斯学习的特点。
假设随机变量D表示数据,随机变量θ表示模型参数,根据贝叶斯定理,可以用下面公式计算后验概率:
其中P(θ)是先验概率,P(D|θ)是似然函数。
预测时,计算数据对后验概率分布的期望值:
如果先验分布是均匀分布,去后验概率最大,就能从贝叶斯估计得到最大似然估计。
朴素贝叶斯和潜在狄利克雷分配就是贝叶斯学习。
2.核方法
核方法是使用核函数表示和学习非线性模型的一种机器学习方法,可以应用于监督学习与无监督学习。
把线性模型扩展到非线性模型,直接的做法是显式地定义从输入空间(低维)到特征空间(高维)的映射,在特征空间中进行内积计算。
假设x1和x2是输入空间的任意两个实例,其内积是
核支持向量机、核PCA、核K-means都属于核方法。
5、按如何泛化分类
1.基于实例的学习
基于实例的学习是系统先完全记住学习示例,然后通过某种相似度度量方式将其泛化到新的实现。
2.基于模型的学习
基于模型的学习是构建示例的模型,使用模型进行预测。
资料整理来自:
- 《统计学习方法 第二版》 李航
- 《机器学习实战 基于Scikit-Learn和TensorFlow》Aurelien Geron