目标检测(七)一篇文章5分钟搞懂卷积神经网络——基于tensorflow2.0训练Alexnet网络实践
一、什么是卷积神经网络
1、定义
卷积神经网络(Convolutional Neural Networks)是一种深度学习模型或类似于人工神经网络的多层感知器,常用来分析视觉图像。卷积神经网络的创始人是着名的计算机科学家Yann LeCun,目前在Facebook工作,他是第一个通过卷积神经网络在MNIST数据集上解决手写数字问题的人。

上图所示,卷积神经网络架构与常规人工神经网络架构非常相似,特别是在网络的最后一层,即全连接。此外,还注意到卷积神经网络能够接受多个特征图作为输入,而不是向量。
2、卷积网络的层次结构
一个卷积神经网络主要由以下5层组成:
- 数据输入层/ Input layer
- 卷积计算层/ CONV layer
- ReLU激励层 / ReLU layer
- 池化层 / Pooling layer
- 全连接层 / FC layer
2.1 数据输入层
该层要做的处理主要是对原始图像数据进行预处理,其中包括:
去均值:把输入数据各个维度都中心化为0,如下图所示,其目的就是把样本的中心拉回到坐标系原点上。
归一化:幅度归一化到同样的范围,如下所示,即减少各维度数据取值范围的差异而带来的干扰,比如,我们有两个维度的特征A和B,A范围是0到10,而B范围是0到10000,如果直接使用这两个特征是有问题的,好的做法就是归一化,即A和B的数据都变为0到1的范围。
PCA/ 白化:用PCA降维;白化是对数据各个特征轴上的幅度归一化
对二维数据去均值与归一化效果图如下图:

对二维数据去相关与白化效果如下图:

2.2 卷积计算层
这一层就是卷积神经网络最重要的一个层次,也是卷积神经网络的名字来源。 在这个卷积层,有两个关键操作:
局部关联:每个神经元看做一个滤波器(filter)
窗口(receptive field)滑动:filter对局部数据计算
先介绍卷积层遇到的几个名词:

如上图2有两个主要参数是我们可以调整的。选择了过滤器的尺寸以后,我们还需要选择步幅(stride)和填充(padding)。步幅控制着过滤器围绕输入内容进行卷积计算的方式。过滤器通过每次移动一个单元的方式对输入内容进行卷积。过滤器移动的距离就是步幅。步幅的设置通常要确保输出内容是一个整数而非分数。
填充值是什么呢?当你把5 x 5 x 3的过滤器用在32 x 32 x 3的输入上时,输出的大小会是28 x 28 x 3。这里空间维度减小了。如果我们继续用卷积层,尺寸减小的速度就会超过我们的期望。在网络的早期层中,我们想要尽可能多地保留原始输入内容的信息,这样我们就能提取出那些低层的特征。比如说我们想要应用同样的卷积层,但又想让输出量维持为32 x 32 x 3。为做到这点,我们可以对这个层应用大小为2的零填充(zero padding)。零填充在输入内容的边界周围补充零。
同时在这里我要提及一下我在学习卷积神经网络的时候一直长期犯的一个误区就是,我一直以为卷积核都长下面这样,以3x3大小卷积核为例,我错误认为卷积核里的元素都得1与0的组合,所以3*3的卷积核最多只有2的9次方,512个不同的卷积核。这样的认知是错误的。

但是在真实的网络训练过程中,正确的认识是卷积核的元素都是1,但是卷积核的每个元素都有一个权重值,这个权重值就是训练过程中要训练的参数。所以不管是1x1、3x3、5x5大小的卷积核,不同的权重值可以使得有无数不同的卷积核,最后训练过程不断调整权重值的过程,也是不断训练找出可以提取出有效特征的卷积核的过程。
2.3 非线性层(激活层)
非线性层主要是对卷积层输出结果做非线性映射,CNN采用的激活函数一般为ReLU(The Rectified Linear Unit/修正线性单元),它的特点是收敛快,求梯度简单,但较脆弱,如下图。

除了上述的激活函数,还有sigmiod激活函数、softmax激活函数、ReLU的变种Leaky-relu激活函数等,详细的了解可以参考https://blog.csdn.net/Dby_freedom/article/details/88946229
2.4 池化层
池化层夹在连续的卷积层中间,用于压缩数据和参数的量,减小过拟合。简而言之,如果输入是图像的话,那么池化层的最主要作用就是压缩图像。
池化层用的方法有最大池化(Max pooling)和平均池化(average pooling),而实际用的较多的是Max pooling。Max pooling的原理如下图:

对于每个2 * 2的窗口选出最大的数作为输出矩阵的相应元素的值,比如输入矩阵第一个2 * 2窗口中最大的数是6,那么输出矩阵的第一个元素就是6,如此类推。
这里再展开叙述池化层的具体作用:
特征不变性:也就是我们在图像处理中经常提到的特征的尺度不变性,池化操作就是图像的resize,平时一张狗的图像被缩小了一倍我们还能认出这是一张狗的照片,这说明这张图像中仍保留着狗最重要的特征,我们一看就能判断图像中画的是一只狗,图像压缩时去掉的信息只是一些无关紧要的信息,而留下的信息则是具有尺度不变性的特征,是最能表达图像的特征。
**特征降维:**我们知道一幅图像含有的信息是很大的,特征也很多,但是有些信息对于我们做图像任务时没有太多用途或者有重复,我们可以把这类冗余去除,把最重要的特征抽取出来,这也是池化操作的一大作用。
过拟合约束:在一定程度上防止过拟合,更方便优化。
2.5 全连接层
两层之间所有神经元都有权重连接,通常全连接层在卷积神经网络尾部。也就是跟传统的神经网络神经元的连接方式是一样的:

卷积神经网络在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。通过不断调整映射能力,用来提取图像中的特征。卷积神经网络自动学习图像的分类特征,并通过训练自动提取特征,相比传统目标检测算法,例如Haar-like、Hog等传统算法手动设计图像的特征表示具有十分大的优势。
二、了解一点点它的发展历程
LeNet模型( LeCun等,1998) 是最早提出的卷积神经网络模型,主要用于MNIST(modified NIST) 数据集中手写数字识别,模型结构如图2-8所示。 其包含3个卷积层、2个池化层和2个全连接层,每个卷积层和全连接层均有可训练的参数,为深度卷积神经网络的发展奠定了基础。

尽管 LeNet在小规模MNIST数据集上取得了不错的效果,但复杂的图像分类任务则需要大规模数据集以及学习能力更强的网络模型。2012 年, Krizhevsky 等人(2012)提出了AlexNet网络结构如图2-9所示,该网络包含5个卷积层和3个全连接层,输入图像经过卷积操作和全连接层的操作,最后输入具有1000个节点的Softmax分类器完成图像分类。该网络通过使用线性整流函数(ReLU)作为激活函数,引入局部响应归一化(LRN)缓解梯度消失问题;使用数据增强和 Dropout技术大大缓解了过拟合问题;并采用两个GPU并行计算的方式训练,提高了训练速度。 AlexNet在2012年ImageNet比赛中以远超当时亚军的优势获得分类任务冠军。

AlexNet 初始几层用较大尺寸核进行卷积导致参数量较大,Simonyan 和Zisserman(2015) 提出了VGGNet (Visual Geometry Group), 继承了AlexNet和LeNet的框架,主要贡献在于通过堆叠采用3 × 3小卷积核的卷积层,增加了网络深度,提升了网络性能。 VGGNet 包含5种结构,其中最常用的是 VGGNet-19和VGGNet-16。
一般来说,提升网络性能最直接的方法是增加网络深度,但随着网络深度的增加,参数量加大,网络易产生过拟合,同时计算资源需求也显著增加。Szegedy等人(2015) 提出的 GoogLeNet 采用了Inception-v1模块,该模块采用稀疏连接降低模型参数量的同时,保证了计算资源的使用效率,在深度达到22层的情况下提升了网络的性能。
对于不同的卷积神经网络的结构层出不群,这里先挖个坑,到时候再发表一个所有常用卷积神经网络结构的综述贴!!!最近再搞嵌入式驱动的入门,不知道后面还有没有机会玩AI算法了,哈哈哈哈。
三、实战篇-AlexNet网络结构实现图像分类
1、数据集介绍
CIFAR-10是由Hinton的学生Alex Krizhevsky和Ilya Sutskever整理的一个用于识别普适物体的小型数据集。一共包含10个类别的RGB彩色图片:飞机、车、鸟类、猫、鹿、狗、蛙类、马、船和卡车。图片的尺寸为32×32 ,数据集中一共有50000张训练图片和10000 张测试图片。 CIFAR-10的图片样例如图所示。

与 MNIST 数据集中目比, CIFAR-10 具有以下不同点:
- CIFAR-10是3通道的彩色RGB图像,而MNIST是灰度图像。
- CIFAR-10的图片尺寸为32×32, 而MNIST的图片尺寸为28×28,比MNIST稍大。
- 相比于手写字符,CIFAR-10含有的是现实世界中真实的物体,不仅噪声很大,而且物体的比例、特征都不尽相同,这为识别带来很大困难。直接的线性模型如Softmax在 CIFAR-10上表现得很差。
2、AlexNet网络结构详解
AlexNet网络包括了6000万个参数和65000万个神经元,5个卷积层,在一些卷积层后面还有池化层,3个全连接层,输出为 的softmax层。AlexNet的作者提出了使用Dropout的方式在网络正向传播过程中随机失活一部分神经元,左图是一个正常的全连接的正向传播过程,每个结点都与下层节点进行全连接,如果使用了Dropout之后,就会每一层中随机的失活一部分神经元,可以变向的认为Dropout操作减少了网络中的训练参数,从而达到解决过拟合。

下面就开始对AlexNet的网络结构进行详解:
原文中的网络有上下两层,其原因是当时作者是用两块GPU进行并行运算,为了方便理解只用看其中一部分。
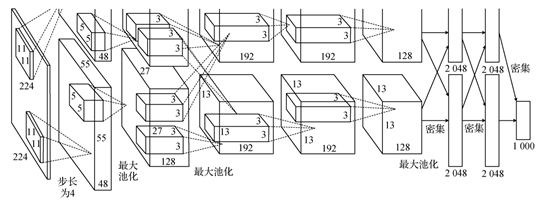
- 第一个卷积层的卷积核大小为[11,11],stride=4,卷积核个数为48,由于上下两层都有48个,所以一共有96个卷积核,当然这个图并没有标注padding的个数,能够得到的只有卷积后的特征层的大小为[55,55,96],用公式可以推算出,在输入的左边加一列0,右边加两列0,上面加上一列0,下面加上两列0;
- 第二个层是最大池化下采样,图中并没有给出池化核的大小和stride,但可以通过查一些其他资料得出,其kernel_size=3,padding=0,stride=2,注意,池化操作只会改变特征的宽高,不会改变特征矩阵的深度;
- 再下一次又是一个卷积层,根据图中的标注可以得出卷积核的个数为128×2=256个,卷积核的大小为5,同时根据查阅的资料和一些源码,可以得出padding=[2,2],stride=1,最后通过公式得到输出为[27,27,256];
- 在跟一个最大池化下采样,其卷积核的大小也是等于3,padding=1,stride=2,输出为[13,13,256];
- 第三个卷积层:从图中信息可以得出卷积核的个数为192×2=384,卷积核大小为3,查阅资料得出,padding=[1,1],stride=1,代入公式得到输出[13,13,384];
- 第四个卷积层:和第三个卷积层的配置一模一样,所以输入和输出的维度都是[13,13,384]
- 第五个卷积层:卷积核的个数为158×2=256,卷积核大小=3,padding=[1,1],stride=1,输出为[13,13,256]
- 最后一个最大池化下采样层,图中并没有给出这个层的任何信息,通过参考一些资料和源码,得到kernel_size=3,padding=0,stride=2,所以最终输出是[6,6,256]
- 最后接了三个全连接层,就不需要对其进行分析了,只需要对下采样后的输出进行展平进行全连接就可以了,这里有必要提一下最后一个层,图中是1000个结点,因为论文的数据集有一千个类别,所以有一千个结点,如果要将网络运用到我们自己的数据集,则有几个分类改成几就okay了。
3、代码分析
3.1 环境配置
本次实验代码运行的环境配置如下:
Python=3.7.1
Tensorflow-gpu=2.3.1
Numpy=1.18.5
Matplotlib=3.5.1
本次实验的源码已经上传到了Github,有兴趣的小伙伴可以下载下来查看。
链接:https://github.com/ilovecooker/cifar-10
3.2 代码展示
(1) 数据预处理
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import cifar10
class get_data():
def get_cifar10_data(self):
# x_train_original和y_train_original代表训练集的图像与标签
, x_test_original与y_test_original代表测试集的图像与标签
(x_train_original, y_train_original), (x_test_original, y_test_original) = cifar10.load_data()
# 验证集分配(从测试集中抽取,因为训练集数据量不够)
x_val = x_test_original[:5000]
y_val = y_test_original[:5000]
x_test = x_test_original[5000:]
y_test = y_test_original[5000:]
x_train = x_train_original
y_train = y_train_original
# 这里把数据从unint类型转化为float32类型, 提高训练精度。
x_train = x_train.astype('float32')
x_val = x_val.astype('float32')
x_test = x_test.astype('float32')
# 原始图像的像素灰度值为0-255,为了提高模型的训练精度,
通常将数值归一化映射到0-1。
x_train = x_train / 255
x_val = x_val / 255
x_test = x_test / 255
# 图像标签一共有10个类别即0-9,这里将其转化为独热编码(One-hot)向量
y_train = to_categorical(y_train)
y_val = to_categorical(y_val)
y_test = to_categorical(y_test)
return x_train, y_train, x_val, y_val, x_test, y_test
(2) 构建AlexNet网络结构
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten,
Dense, Dropout, BatchNormalization,UpSampling2D
"""
定义alexnet网络模型
"""
class model_set():
def alexnet(self):
model = Sequential()
model.add(UpSampling2D(input_shape=(32, 32, 3),size=(7,7)))
model.add(Conv2D(96, (11, 11), strides=(4, 4), padding='same',
activation='relu', kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(BatchNormalization())
model.add(Conv2D(256, (5, 5), strides=(1, 1), padding='same',
activation='relu', kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(BatchNormalization())
model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same',
activation='relu', kernel_initializer='uniform'))
model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same',
activation='relu', kernel_initializer='uniform'))
model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same',
activation='relu', kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
print(model.summary())
return model
(3) 模型训练
import tensorflow as tf
from model import model_set
from data_get import get_data
import matplotlib.pyplot as plt
"""
编译网络并训练
"""
data=get_data()
x_train, y_train, x_val, y_val, x_test, y_test = data.get_cifar10_data()
model_fun=model_set()
model = model_fun.alexnet()
# 编译网络(定义损失函数、优化器、评估指标)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
#设置终止条件
early_stopping=tf.keras.callbacks.EarlyStopping(monitor='val_accuracy', min_delta=0.005,
patience=7, verbose=0, mode='auto',
baseline=None, restore_best_weights=False)
# 开始网络训练(定义训练数据与验证数据、定义训练代数,定义训练批大小)
train_history = model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=100, batch_size=100, verbose=1,callbacks = [early_stopping])
# 模型保存
model.save('alexnet_cifar10.h5')
# 定义训练过程可视化函数(训练集损失、验证集损失、训练集精度、验证集精度)
def show_train_history(train_history, train, validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train', 'validation'], loc='best')
plt.show()
show_train_history(train_history, 'accuracy', 'val_accuracy')
show_train_history(train_history, 'loss', 'val_loss')
训练过程中的运行截图如图所示。

最终训练完成后的h5模型文件如下图。

(4) 测试模型与结果可视化
from tensorflow.keras import models
from data_get import get_data
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import cifar10
data=get_data()
x_train, y_train, x_val, y_val, x_test, y_test = data.get_cifar10_data()
model=models.load_model("alexnet_cifar10.h5")
# 输出网络在测试集上的损失与精度
score = model.evaluate(x_test, y_test)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
# 输出网络在测试集上的损失与精度
score = model.evaluate(x_test, y_test)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
# 测试集结果预测
predictions = model.predict(x_test)
predictions = np.argmax(predictions, axis=1)
print('前20张图片预测结果:', predictions[:20])
# 预测结果图像可视化
(x_train_original, y_train_original), (x_test_original, y_test_original) = cifar10.load_data()
def cifar10_visualize_multiple_predict(start, end, length, width):
for i in range(start, end):
plt.subplot(length, width, 1 + i)
plt.imshow(x_test_original[5000+i], cmap=plt.get_cmap('gray'))
title_true = 'true=' + str(y_test_original[5000+i]) # 图像真实标签
title_prediction = ',' + 'prediction' + str(predictions[i]) # 预测结果
title = title_true + title_prediction
plt.title(title)
plt.xticks([])
plt.yticks([])
plt.show()
cifar10_visualize_multiple_predict(start=0, end=9, length=3, width=3)
模型测试后的运行结果如图所示。
