JSNet: Joint Instance and Semantic Segmentation of 3D Point Clouds
Abstract
在本文中,我们提出了一种新的联合实例和语义分割方法,称为 JSNet,以同时解决 3D 点云的实例和语义分割。首先,我们建立了一个有效的骨干网络来从原始点云中提取鲁棒的特征。其次,为了获得更多的判别特征,提出了一种点云特征融合模块来融合骨干网络的不同层特征。此外,开发了一个联合实例语义分割模块,将语义特征转换为实例嵌入空间,然后将转换后的特征与实例特征进一步融合,以方便实例分割。同时,该模块还将实例特征聚合到语义特征空间中,以促进语义分割。最后,通过对实例嵌入应用简单的均值偏移聚类来生成实例预测。因此,我们在大规模 3D 室内点云数据集 S3DIS 和部分数据集 ShapeNet 上评估提出的 JSNet,并将其与现有方法进行比较。实验结果表明,我们的方法在 3D 实例分割中优于 state-of-theart 方法,显着改善了 3D 语义预测,并且我们的方法也有利于部分分割。这项工作的源代码可在 https://github.com/dlinzhao/JSNet 获得。
Introduction
语义分割是用于分割场景中所有信息区域并将每个区域分类为特定类别的任务。实例分割不同于语义分割,因为同一类的不同对象会有不同的标签。这两项任务在现实世界的场景中都有广泛的应用,例如自动驾驶和基于移动的导航。在二维图像中,这两项任务取得了显着的成果(Chen et al 2018; He et al 2017; Li et al 2019)。然而,3D语义和实例分割的研究仍然面临着巨大的挑战,例如,大规模的噪声数据处理、高计算量以及内存消耗。
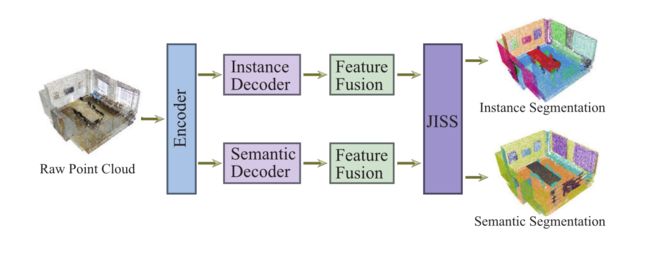
图 1:我们的网络 JSNet 将原始点云作为输入,并为每个点获取输出实例和语义分割结果。 JISS 代表联合实例和语义分割。
文献研究表明,3D 场景数据具有不同的表示形式,例如体积网格 (Wu et al 2015; Thanh Nguyen et al 2016; Maturana and Scherer 2015) 和 3D 点云 (Qi et al 2017b; Li et al 2018; Wang et al 2018b;Yu 等人 2018)。与其他表示相比,点云是一种更紧凑、更直观的 3D 场景数据表示。最近,已经提出了更高效、更强大的深度学习网络架构(Qi et al 2017b; Wu, Qi, and Fuxin 2019; Li, Chen, and Hee Lee 2018)直接处理点云,并在点云分类和部分分割。这些方法通常在其他任务中用作特征提取网络,例如实例分割和语义分割。
在以前的工作中,实例分割和语义分割经常被分别处理或实例分割被视为语义分割的后处理任务(Wang et al 2018a; Pham et al 2019a)。然而,这两个问题是相关的,因为不同类别的点属于不同的实例,而同一实例的点属于同一类。最近,(Pham et al 2019b)处理了多任务逐点网络和多值这两个问题条件随机场(CRF)。然而,CRF 是卷积神经网络(CNN)背后的一个单独部分,很难探索它们组合的性能。此外,该方法没有研究语义分割和实例分割是否可以相互促进。同时,提出了 ASIS (Wang et al 2019b) 来同时解决这两个任务,通过全连接层将语义特征适应实例特征空间,并通过 K K K最近邻 (kNN) 将实例特征聚合到语义特征空间.然而,这种方法的性能是有限的,因为很难为 kNN 选择正确的 K K K值和距离度量。此外,它具有昂贵的计算和内存消耗,因为它会在训练过程中产生高阶稀疏张量。
在这项工作中,我们引入了一个名为 JSNet 的 3D 点云联合实例语义分割神经网络来解决两个基本问题:语义分割和实例分割。所提出的网络 JSNet 包括四个部分:一个共享特征编码器、两个并行分支解码器、每个解码器的特征融合模块、一个联合分割模块。特征编码器和解码器基于 PointNet++ (Qi et al 2017b) 和 PointConv (Wu, Qi, and Fuxin 2019) 构建,以学习更有效的高级语义特征。为了获得更多的判别特征,我们提出了一个点云特征融合模块来融合高层和低层信息来细化输出特征。为了使这两个任务相互促进,提出了一种新颖的联合实例和语义分割模块来同时处理实例和语义分割。具体来说,该模块通过一维卷积将语义特征转换为实例嵌入空间,然后将转换后的特征与实例特征进一步融合,以方便实例分割。同时,该模块还通过隐式学习将实例特征聚合到语义特征空间中,以促进语义分割。因此,我们的方法可用于学习实例感知语义融合特征和语义感知实例嵌入特征,这可以使这些点的预测更加准确。
总而言之,我们工作的主要贡献如下:
-
我们设计了一个更高效的点云特征融合(PCFF)模块来生成更多的判别特征并提高点预测的准确性。
-
我们提出了一种新颖的联合实例和语义分割(JISS)模块,使实例分割和语义分割相互促进。该模块进一步提高了训练过程中可接受的 GPU 内存消耗的准确性。
-
我们在 S3DIS 数据集 (Armeni et al 2016) 上取得了令人印象深刻的结果,同时在 3D 实例分割任务上取得了显着改进。此外,我们在 ShapeNet 数据集 (Yi et al 2016) 上的实验表明,JSNet 也可以在零件分割任务中取得令人满意的性能。
Related Work
在本节中,我们简要回顾了一些点云特征提取工作,以及一些现有的 3D 场景中的语义和实例分割方法。特别是,我们专注于应用于 3D 点云的基于深度神经网络的方法,因为它们已在该领域证明了稳健性和效率。
Deep learning for 3D Point Clouds
虽然深度学习已经成功用于 2D 图像,但对于具有不规则数据结构的 3D 点云的特征学习能力仍然存在许多挑战。最近,PointNet (Qi et al 2017a) 是最早将神经网络直接应用于点云的方法之一。它使用共享的多层感知器 (MLP) 和最大池从无序点集中学习深度特征。然而,PointNet 难以捕捉局部区域特征。 PointNet++ (Qi et al 2017b) 使用分层神经网络解决了这个缺点。最大池操作是从 PointNet 和 PointNet++ 的点中提取特征的关键结构。但它只在特征图的局部或全局区域上保持最强的激活,这可能会导致语义和实例分割任务丢失一些有用的详细信息。
后来的一些作品(Simonovsky 和 Komodakis 2017;Hermosilla 等人 2018;Xu 等人 2018)通过学习用于卷积计算的连续滤波器来提取点云的特征。这项工作(Simonovsky 和 Komodakis 2017)首先提出了将具有边缘条件的连续滤波器学习到 3D 图的想法。此外,动态图 CNN (Wang et al 2018b) 引入了一种动态更新图的方法。以下工作 PointConv (Wu, Qi, and Fuxin 2019) 提出了一种逆密度尺度来重新加权 MLP 学习到的连续函数并补偿非均匀采样,同时它在训练过程中也需要较高的 GPU 内存。
Semantic&Instance Segmentation on Point Clouds
对于语义分割,基于全卷积网络(Long、Shelhamer 和 Darrell 2015)的方法(Zhao et al 2017; Chen et al 2018)在二维领域取得了巨大的进步。至于 3D 语义分割,由 (Huang and Y ou 2016) 引入的 3D-FCNN 使用 3D 全卷积神经网络预测粗体素标签。 SEGCloud (Tchapmi et al 2017) 使用三线性插值和完全连接的条件随机场扩展了 3DFCNN。 RSNet(Huang、Wang 和 Neumann 2018)使用切片池化层、循环神经网络 (RNN) 层和切片去池化层对点云的局部依赖关系进行建模。 P-RNN (Ye et al 2018) 通过使用逐点金字塔池化模块对语义分割的固有上下文特征进行建模,并使用双向分层 RNN 探索远程空间依赖关系。最近,提出了一种图注意力卷积 GAC (Wang et al 2019a),以利用动态内核捕获点云的结构化特征,以适应对象的结构。然而,以前很少有工作利用实例嵌入的优势来关注语义分割。
例如分割,基于 Mask R-CNN (He et al 2017) 的方法 (Li et al 2019; Huang et al ) 在 2D 图像上占主导地位。然而,很少有关于 3D 实例分割的研究。 SGPN (Wang et al 2018a) 通过学习具有双铰链损失的点特征的相似性矩阵来生成实例建议。 GSPN (Yi et al 2019) 通过重构形状生成提案并输出基于 PointNet++ 的最终分割结果。3D-BoNet (Yang et al 2019) 直接回归 3D 边界框并同时预测所有实例的点级掩码。同样,很少有作品利用语义融合的优势来分割实例。
但是,以前的大多数作品都分别处理这两个任务。最近,(Pham et al 2019b) 提出了一种多任务逐点网络 (MT-PNet),用于预测语义类别和实例嵌入向量,然后使用多值条件随机场 (MV-CRF) 作为后处理。然而,CRF 是 CNN 背后的独立部分,很难探索它们组合的性能。此外,该方法没有研究语义分割和实例分割是否可以相互促进。因此,性能提升并不明显。同时,提出了 ASIS (Wang et al 2019b) 来一次分割 3D 点云的实例和语义,它使用 PointNet 或 PointNet++ 作为骨干网络,然后连接一个提议的模块 ASIS。 ASIS 通过全连接层将语义特征适配到实例特征空间,并通过 kNN 将实例特征聚合到语义特征空间。虽然该方法 (Wang et al 2019b) 难以为 kNN 选择正确的 K K K 值和距离度量,并且由于在训练过程中会产生高阶稀疏矩阵,因此内存成本也很高。
Proposed Method
在本节中,首先,我们描述了我们提出的 JSNet 的整个网络架构以及 3D 点云的语义分割。然后,我们详细阐述了我们提出的网络的两个主要组件,分别包括点云特征融合 (PCFF) 模块和联合实例和语义分割 (JISS) 模块。
Network Architecture
图 2(a) 所示的整个网络由四个主要组件组成,包括一个共享编码器、两个并行解码器、每个解码器的点云特征融合模块、作为最后一部分的联合分割模块。对于两个并行分支,一个旨在为每个点提取语义特征,而另一个是实例分割任务。特别是对于特征编码器和两个解码器,我们可以通过复制一个解码器直接使用PointNet++或PointConv作为我们的骨干网络,因为这两个解码器具有相同的结构。然而,如上所述,对于实例或语义分割,PointNet++ 可能会因为最大池化操作而丢失详细信息,并且 PointConv 在训练过程中具有昂贵的 GPU 内存消耗。在这项工作中,我们将 PointNet++ 和 PointConv 结合起来,以构建一个更有效的骨干网络,同时具有可接受的内存成本。主干的编码器是通过连接一个PointNet++的集合抽象模块和PointConv的三个特征编码层来构建的。类似地,解码器由 PointConv 的三个深度特征解码层和 PointNet++ 的特征传播模块组成。
对于整个管道,我们的网络将大小为 N a N_{a} Na的点云作为输入,然后通过共享特征编码器将其编码为 N e × 512 N_e \times 512 Ne×512形状的矩阵。接下来,特征编码器的输出被输入到两个并行解码器中,并分别由它们的后续组件进行处理。语义分支对共享特征进行解码,将不同层的特征融合成一个形状为 N a × 128 N_a \times 128 Na×128的语义特征矩阵 F S S F_{S S} FSS。同理,实例分支在PCFF模块之后输出一个实例特征矩阵 F I S F_{I S} FIS。实例特征由 JISS 模块提取和处理,然后输出两个特征矩阵。矩阵 P S S I P_{S S I} PSSI的形状为 N a × C N_a \times C Na×C的矩阵之一,用于预测语义类别,其中 C C C是语义类别的数量。另一个用 N a × K N_a \times K Na×K整形的 E I S S E_{I S S} EISS是实例特征矩阵,用于预测每个点的实例标签,其中 K K K是嵌入向量的维数。在嵌入空间中,嵌入表示点的实例关系:属于同一实例对象的点相近,不同实例的点彼此远离。
在训练时,我们网络的损失函数 L \mathcal{L} L由语义分割损失 L sem \mathcal{L}_{\text {sem }} Lsem 和实例嵌入损失 L i n s \mathcal{L}_{i n s} Lins组成:
L = L sem + L ins (1) \mathcal{L}=\mathcal{L}_{\text {sem }}+\mathcal{L}_{\text {ins }} \tag{1} L=Lsem +Lins (1)
其中 L sem \mathcal{L}_{\text {sem }} Lsem 是用经典的交叉熵损失定义的。对于实例嵌入损失,我们利用判别函数来表达嵌入损失 Lins,其灵感来自 (De Brabandere, Neven, and Van Gool 2017) 中的工作。具体来说,实例嵌入损失函数公式如下:
L ins = L pull + L push , (2) \mathcal{L}_{\text {ins }}=\mathcal{L}_{\text {pull }}+\mathcal{L}_{\text {push }}, \tag{2} Lins =Lpull +Lpush ,(2)
其中 L pull \mathcal{L}_{\text {pull }} Lpull 使嵌入接近实例的平均嵌入,而 L push \mathcal{L}_{\text {push }} Lpush 使不同实例的平均嵌入彼此分离。给定实例数 M M M、第 m m m 个实例中的元素数 N m N_m Nm、点的嵌入 e n e_n en以及第 m m m个实例中嵌入的平均值 μ m \mu_m μm。每个术语重写如下:
L pull = 1 M ∑ m = 1 M 1 N m ∑ n = 1 N m [ ∥ μ m − e n ∥ 1 − δ v ] + 2 (3) \mathcal{L}_{\text {pull }}=\frac{1}{M} \sum_{m=1}^M \frac{1}{N_m} \sum_{n=1}^{N_m}\left[\left\|\mu_m-e_n\right\|_1-\delta_v\right]_{+}^2 \tag{3} Lpull =M1m=1∑MNm1n=1∑Nm[∥μm−en∥1−δv]+2(3)

其中 [ x ] + = max ( 0 , x ) [x]_{+}=\max (0, x) [x]+=max(0,x); ∥ ⋅ ∥ 1 \|\cdot\|_1 ∥⋅∥1为 L 1 L_{1} L1距离; δ v \delta_v δv 和 δ d \delta_d δd分别是 L pull \mathcal{L}_{\text {pull }} Lpull 和 L push \mathcal{L}_{\text {push }} Lpush 的边距(margins)。
在测试时,通过对嵌入使用简单的均值偏移聚类(Comaniciu 和 Meer 2002)生成最终的实例标签,并通过使用 argmax 操作获得最终的语义类别。
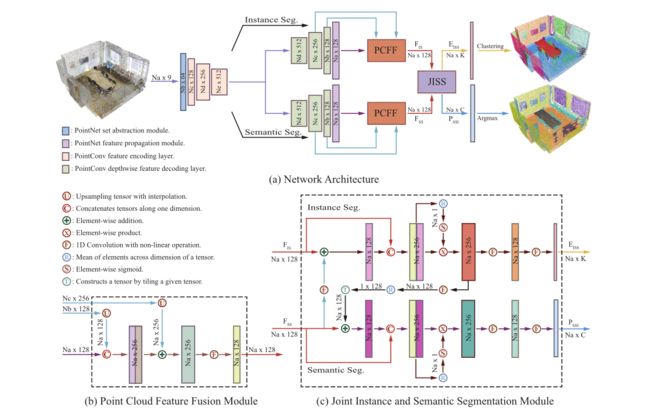
图 2:3D 点云 (JSNet) 的联合实例语义分割神经网络概述。 (a) 网络架构示意图。 (b) 点云特征融合 (PCFF) 模块的组件。 © 联合实例和语义分割 (JISS) 模块的组件。不同颜色的块代表(a)中的不同模块,而这些块代表(b)和(c)中的不同特征。
Point Cloud Feature Fusion Module
在二维图像的分割和检测任务中,之前的工作只使用最后一层的特征进行预测,而在后续的方法中融合了不同的层特征(Lin et al 2017; He et al 2017; Chen et al 2018),因为高层具有更丰富的语义信息,而低层具有更详细的信息。这些工作表明融合特征有利于更好的预测。
基于上述观察,我们提出了一个点云特征融合(PCFF)模块,用于点云中的语义和实例分割。图 2(b) 显示了结构的细节。考虑到精度、计算和 GPU 内存消耗,我们只融合解码器的最后三层。我们使用 F a , F b F_a, F_b Fa,Fb和 F c F_c Fc来表示解码器的特征矩阵,形状分别为 N a × 128 N_a \times 128 Na×128、 N b × 128 N_b \times 128 Nb×128和 N c × 256 N_c \times 256 Nc×256。首先,我们连接 F a F_a Fa 和 F b ′ F_b^{\prime} Fb′使用来自 F b F_{b} Fb的插值进行上采样。然后将前一个输出添加到 F c ′ F_c^{\prime} Fc′从 F c F_c Fc上采样)元素和卷积应用于先前的结果。继 (Qi et al 2017b) 之后,通过使用基于三个最近邻的反平方距离加权平均值来实现插值。最后,PCFF 生成一个形状为 N a × 128 N_a \times 128 Na×128的融合特征矩阵。该模块可以以可接受的计算和内存消耗细化解码器的输出特征。
Joint Instance and Semantic Segmentation
事实上,语义分割和实例分割都将初始点云特征分别映射到不同的新高级特征空间。在语义特征空间中,相同语义类别的点聚集在一起,而不同类别的点被分开。在实例特征空间中,同一实例对象的点紧密组合,而不同实例的点相互分离。这表明我们可以从语义特征空间中提取语义感知信息,将信息整合到实例特征中并生成语义感知的实例嵌入特征,反之亦然。
基于这一观察,我们提出了一个联合实例语义分割 (JISS) 模块来同时获取语义标签和分割实例对象,如图 2© 所示。 JISS 模块将语义特征转换为实例嵌入空间,然后将转换后的特征与实例特征进一步融合,以方便实例分割。同时,该模块还将实例特征聚合到语义特征空间中,以促进语义分割。具体来说,语义特征矩阵 F S S F_{S S} FSS通过一维卷积 (Conv1D) 转换为实例特征空间作为 F S S T F_{S S T} FSST,并将 F S S T F_{S S T} FSST作为 F I S S F_{I S S} FISS逐元素添加到实例特征矩阵 F I S F_{I S} FIS。然后,我们通过将特征 F I S F_{I S} FIS和 F I S S F_{I S S} FISS连接到 F I S S C F_{I S S C} FISSC中来对点特征的空间相关性进行建模以增强重要特征,然后将 F I S S C F_{I S S C} FISSC应用于跨维度的元素平均值(Mean)和逐元素的 sigmoid(Sigmoid)生成权重矩阵 F I S R F_{I S R} FISR。最后,将特征矩阵 F I S S C F_{I S S C} FISSC与 F I S R F_{I S R} FISR相乘生成特征矩阵 F I S S R F_{I S S R} FISSR,然后进行两次 1D 卷积,生成 N a × K N_a \times K Na×K形状的实例嵌入特征 E I S S E_{I S S} EISS。过程可表述为:
F I S S C = Concat ( F I S , F I S + Conv 1 D ( F S S ) ) (5) F_{I S S C}=\operatorname{Concat}\left(F_{I S}, F_{I S}+\operatorname{Conv} 1 D\left(F_{S S}\right)\right) \tag{5} FISSC=Concat(FIS,FIS+Conv1D(FSS))(5)
F I S S R = F I S S C ⋅ Sigmoid ( Mean ( F I S S C ) ) (6) F_{I S S R}=F_{I S S C} \cdot \operatorname{Sigmoid}\left(\operatorname{Mean}\left(F_{I S S C}\right)\right) \tag{6} FISSR=FISSC⋅Sigmoid(Mean(FISSC))(6)
E I S S = Conv 1 D ( Conv 1 D ( F I S S R ) ) , (7) E_{I S S}=\operatorname{Conv} 1 D\left(\operatorname{Conv} 1 D\left(F_{I S S R}\right)\right), \tag{7} EISS=Conv1D(Conv1D(FISSR)),(7)
其中实例嵌入特征矩阵 E I S S E_{I S S} EISS用于通过均值偏移聚类生成最终实例标签。
对于语义分割分支,给定实例嵌入 F I S S R F_{I S S R} FISSR,该模块将 F I S S R F_{I S S R} FISSR作为 F I S S T F_{I S S T} FISST集成到语义特征空间中,并带有一维卷积,然后是跨维度的元素平均值和平铺操作。接下来,其他操作类似于实例分支,除了最后一层输出一个实例感知的语义特征矩阵 P S S I P_{S S I} PSSI,形状为 N a × C N_a \times C Na×C。我们还将这个过程制定如下:
F I S S T = Tile ( Mean ( Conv 1 D ( F I S S R ) ) ) (8) F_{I S S T}=\text { Tile }\left(\text { Mean }\left(\operatorname{Conv} 1 D\left(F_{I S S R}\right)\right)\right) \tag{8} FISST= Tile ( Mean (Conv1D(FISSR)))(8)
F S S I = Concat ( F S S , F S S + F I S S T ) (9) F_{S S I}=\operatorname{Concat}\left(F_{S S}, F_{S S}+F_{I S S T}\right) \tag{9} FSSI=Concat(FSS,FSS+FISST)(9)
F S S I R = F S S I ⋅ Sigmoid ( Mean ( F S S I ) ) (10) F_{S S I R}=F_{S S I} \cdot \operatorname{Sigmoid}\left(\operatorname{Mean}\left(F_{S S I}\right)\right) \tag{10} FSSIR=FSSI⋅Sigmoid(Mean(FSSI))(10)
P S S I = Conv 1 D ( Conv 1 D ( F S S I R ) ) (11) P_{S S I}=\operatorname{Conv} 1 D\left(\operatorname{Conv} 1 D\left(F_{S S I R}\right)\right) \tag{11} PSSI=Conv1D(Conv1D(FSSIR))(11)
其中 F S S I F_{S S I} FSSI是实例融合特征矩阵, F S S I R F_{S S I R} FSSIR是用于语义分割的特征融合矩阵。最终的实例感知语义特征被送入最后一个分类器,以预测每个点的类别。
Conclusion
在这项工作中,我们提出了 JSNet,这是一种基于深度学习框架的新型端到端方法,用于点云上的 3D 实例分割和语义分割。该框架由一个共享特征编码器、两个并行特征解码器和一个点云特征融合(PCFF)模块和联合实例语义分割(JISS)模块。一方面,特征编码器、特征解码器和PCFF模块可以学习到更有效、更具判别力的特征。另一方面,JISS模块使实例和语义分割相得益彰。最后,我们的方法在 S3DIS 数据集上的实例和语义分割任务上都取得了显着的改进。未来,可以将点云的空间几何拓扑添加到我们的框架中以获得更好的分割结果。
论文链接:https://ojs.aaai.org/index.php/AAAI/article/view/6994
References
