迁移学习(Transfer Learning)概述及代码实现
基于PaddlePaddle的李宏毅机器学习——迁移学习
大噶好,我是黄波波,希望能和大家共进步,错误之处恳请指出!
百度AI Studio个人主页, 我在AI Studio上获得白银等级,点亮2个徽章,来互关呀~
本项目是在飞桨深度学习学院提供的李宏毅-机器学习特训营课程。
Abstract
本文共分为两大部分:第一部分介绍迁移学习的主要概念以及类型,第二部分是实现迁移学习布置的作业——领域对抗性训练(Domain Adversarial Training)并进行了三次不同epoch的训练。
第一部分:迁移学习介绍
1 迁移学习:Transfer Learning
1.1 什么是迁移学习呢?
假设现在要做猫和狗的分类器,我们需要一样标签数据告诉机器哪些是猫,哪些是狗。
同时,假设现在有一些与猫和狗没有直接关系的数据,这里说是没有直接关系,并不是说是完全没有关系。就是说有一些关系,但又不是直接相关的。

假设现在有自然界真实存在的老虎和大象的图片,那老虎和大象对分辨猫和狗会有帮助吗。

或者说我们有一些卡通动画中的猫和狗图像,但不是真实存在的,有没有帮助呢。

迁移学习把任务A开发的模型作为初始点,重新使用在为任务B开发模型的过程中。迁移学习是通过从已学习的相关任务中转移知识来改进学习的新任务。
1.2 为什么用迁移学习
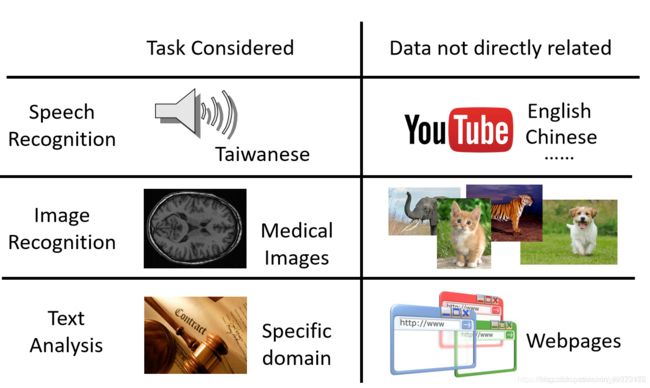
这三个说的是,第一个是做闽南语(台湾腔)的语音识别,但是没有太多的训练数据,只有很多无直接关系的英文、普通话数据;第二是做医疗方面的图像识别,同样样本不多,但有很多其他真实动物的图像;第三个说的是在特定领域,这里是法律方面的文本分析,缺少数据,但是可以找到很多不相关的网页数据。
这时候迁移学习就会很有用,因为可能实际情况就是这样,我们无法收集太多想要的数据,但是存在很多不直接相关的其他数据。
其实在现实生活中我们会做迁移学习(有点像类比的思想)。
这里用漫画家的生活对应到研究生的生活。漫画家要画漫画,研究生要跑实验等。

1.3 迁移学习的概述
我们主要把迁移学习分为四大类。
在迁移学习中,有一些arget data,就是和你的任务由直接关系的数据;
还有很多source data,是和你现在的任务没有直接关系的数据。
根据它们是否有标签,可以分成四类。

1.3.1 第一类迁移学习
我们先看下target data和source data都是有标签的情况。
这种情况下我们可以做什么事情呢,一件事情是模型的微调(Fine-tuning),另一件事情是多任务学习(Multitask Learning)。
-
1) 模型微调
设你有一组大量的source data,和一组少量的target data。它们都是有标签的。

你可能听过单样本学习(one-shot learning):说现在的样本很少,只有几个或一个样本。
在语音识别中,我们有大量的source data,我们有几万个人说的不同的句子,并且知道这些句子是什么。target data是某个具体的使用者他说的话,和说的话对应的文字。
因为每个人发音都是不一样的,你拿一大堆人语音的数据训练出来的模型,对某个特定的使用者,可能并不是一定好的。所以我们期望说,假设特定的使用者可以对我们的语音识别系统说5句话,我们知道这5句话对应的文字。
有了这些少量的target data后,就可以拿这些数据让某个特定使用者的语音识别做得更好。这让我想到了"Hey,siri"初次启用时需要说几句话。
这里面的问题是target data数据量很少,所以我们需要特殊的处理方法。一个比较常见的方法叫保守训练(conservative training)。由于篇幅有限这里不将展开,具体详见李宏毅机器学习课件。
接下来我们介绍下多任务学习(Multitask Learning)
-
2) 多任务学习
我们现在有多个不同的任务,我们希望机器能同时学会做好这几个不同的任务。
比如说你要训练某个人打篮球,同时要训练他唱、跳、Rap。

我们希望NN也能做到这件事情。
在这种神经网络的架构设计上可以是像上面这种。这里假设任务A和任务B可以共用同一组输入特征。就是这两个NN,它们前面几层是共用的,但是在某个隐藏层会产生两个分支,一条产生的是任务A的分支,另一条是任务B的。
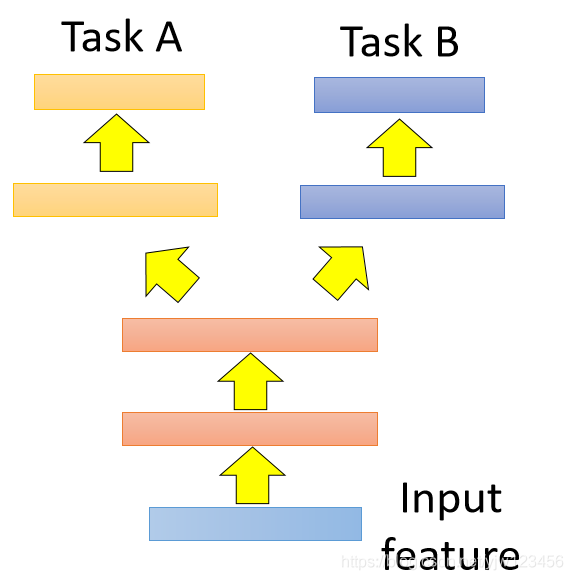
那如果这两个任务的输入特征都不能共用呢,我们就可以采用上面的设计,在这两个NN中对不同的输入特征做一些转换,然后丢到共用的网络层中去,再从共用的层中分两个分支出来。

如果可以选择适当的不同的任务合在一起的话,是可以有帮助的。
什么样的任务可能有帮助呢,举例来说,现在在做语音识别的时候,我们不仅让机器学会某国语言的语音识别,我们让机器学会多国语言的。

此时,多任务学习就会有帮助。
这多国语言前面几层是共用的,因为不同的语音声音讯号是一样的(人类的语言都会有一些同样的特征,比如中文里面的嘿和英语里面的hey发音很像)。从这些共用的层出来后分成多个分支,分别做不同国家语言的语音识别。这整个NN可以同时一起训练,这时候学出来的效果比只用一种语言还要好。
这里是文献上的实验的例子,纵轴是错误率,横轴是中文语言识别训练的数据量。
从实验结果看到,如果仅让机器学中文的话,就是蓝色的线,它达到红线交点处的错误率需要的中文数据量会超过同时与欧洲语言一起学习的数据量。并且可以看到橙色的曲线是在蓝色曲线的下方,说明效果更加好。

还有另外一个任务学习方法叫渐进式网络(Progressive Neural Networks),这里不将展开。
1.3.2 第二类迁移学习
上面介绍的都是source data和target data有标签的情况,那如果只是source data有标签,target data无标签呢。这种类型也有两种情况,第一种是领域对抗性训练(Domain Adversarial Training),第二种是零次学习(Zero-shot Learning)。第二种情况是第二部分代码实现的内容。
-
1)领域对抗性训练(Domain Adversarial Training)
这种情况的前提是他们有相同的任务,在概念上你可以把有标签的source data当成训练数据,把无标签的target data当成测试数据,但是这样的效果肯定是很差的,因为它们的分布不同。

假设今天要做手写数字识别,你有有标签的MNIST的数据,但是你要识别的对象是无标签的来自MNIST-M的数据,在MNIST-M中的数字甚至是彩色的,它的数据样本分布和原来的MNIST分布不一样。

所以需要特别的处理。Domain-adversarial training就是干这件事的。Domain-adversarial training可以看成GAN的一种。它想要把source data和target data转换到同样的领域上,让它们有同样的分布。

如果我们没有对数据做任何处理,单纯的拿source data来训练一个分类器,它输入是一个图像,输出是该图形的类别。那今天得到的特征分布可能是下面这样子。

MNIST的数据它是蓝色的点,确实可以看到它们分成一群一群的,把几群数据的点拿出来看的话,得到的结果可能是左边的样子,能区分出4,0和1。 但是把和MNIST分布不同的MNIST-M手写数字的图片丢到这个分类器中去,这些不一样的图片,它们的特征分布可能像红点一样。可以看到,红点和蓝点根本没有交集。
如果今天这个NN无法用同样的特征表示这两种数据,那么就会无法得到好的分类结果。
怎么办呢
我们希望在一个NN中,前面几个网络层做的事是特征抽取,如图1所示,也就是说,希望这个特征抽取器能把不同领域的source data和target data都转成同样的特征。
图1 Feature Extractor:特征提取器

也就是我们希望说,红点和蓝点的分布不是上面这样,而是像下面混合在一起。

那怎么让我们这个特征抽取器做到这件事情呢。
这里需要引入一个领域的分类器(domain classifier),如图2所示,就像我们做GAN的时候引入的鉴别器。它也是一个神经网络。

图2 Domain Classifier领域的分类器
Domain-adversarial training可以看成GAN的一种。它想要把source data和target data转换到同样的领域上,让它们有同样的分布。
这个领域分类器的作用是,要侦测出现在特征抽取器输出的特征是属于哪个领域的(来自哪个分布的)。现在特征抽取器要做的事情是尽量骗过这个领域分类器,而后者是尽量防止被骗。
特征抽取器要做的是去除source 领域和target 领域不一样的地方,让提取出来的特征分布是很接近的,可以骗过领域分类器。
但是如果只有这两个神经网络是不够的。因为绿色的特征抽取器可以轻易的骗过红色的分类器,只要它不管输入是什么,只把所有的输出都变成0就可以了。
所以需要引入另外一个东西叫标签预测器(Label predictor)的东西。

图3 Label predictor:标签预测器
现在特征抽取器不仅要骗过分类器,还要让预测器尽量有准确的预测结果。这是一个很大的神经网络,但是这三个不同的部分有不同的目标。
预测器想要正确的分类输入的图片,分类器想要正确分别输入是来自哪个分布。它们都只能看到特征抽取器抽取后的特征。
抽取器一方面希望可以促使预测器做的好,另一方面要防止分类器做的好。
那么要怎么做呢?
一样用梯度下降来训练,红色的分类器部分要调整参数,去让分辨领域的结果越正确越好;蓝色的预测器需要调参数,让标签的预测正确率越高越好;如图4所示梯度反向传播过程。
这两者不一样的地方在于,当分类器要求绿色的抽取器去调整参数以满足以及的目标时,绿色的抽取器会尽量满足它的要求;还当红色的神经网络要求绿色的神经网络调整参数的时候,红色的网络会故意乘以− 1 -1−1,以防止分类器做的好。
最后红色的神经网路会无法做好分类,但是它必须要努力挣扎,它需要从绿色的NN给的不好的特征里面尽量去区分它们的领域。这样才能迫使绿色的NN产生红色的NN无法分辨的特征。难点就在于让红色的NN努力挣扎而不是很快放弃。

图4 Domain Adversarial Training梯度反向传播过程
-
2)零次学习(Zero-shot Learning)
零次学习(Zero-shot Learning)说的是source data和target data它们的任务都不相同。

比如source data可能是要做猫和狗的分类;但是target data要做的是做草泥马和羊的分类。

target data中需要正确找出草泥马,但是source data中都没出现过草泥马,那要怎么做这件事情呢
我们先看下语音识别里面是怎么做的,语音识别一直都有训练数据(source data)和测试数据(target data)是不同任务的问题。 很有可能在测试数据中出现的词汇,在训练数据中从来没有出现过。语音识别在处理这个问题的时候,做法是找出比词汇更小的单位。通常语音识别都是拿音位(phoneme,可以理解为音标)做为单位。
如果把词汇都转成音位,在识别的时候只去识别音位,然后再把音位转换为词汇的话就可以解决训练数据和测试数据不一样的问题。
其实在图像上的处理方法也很类似,这里不展开。
1.3.3 第三类迁移学习
-
自我学习
自我学习(Self-taught learning)其实和半监督学习很像,都是有少量的有标签数据,和非常多的无标签数据。但是与半监督学习有个很大的不同是,有标签数据可能和无标签数据是没有关系的。
1.3.4 第四类迁移学习
-
自学成簇
如果target data和source data都是无标签的话,可以用Self-taught Clustering来做。
可以用无标签的source data,可以学出一个较好的特征表示,再用这个较好的特征表示用在聚类上,就可以得到较好的结果。
第二部分:领域对抗性训练(Domain Adversarial Training)代码实现
2.1 项目描述
本作业的任务是迁移学习中的领域对抗性训练(Domain Adversarial Training)。
也就是左下角的那一块。

Domain Adaptation是让模型可以在训练时只需要 A dataset label,不需要 B dataset label 的情况下提高 B dataset 的准确率。 (A dataset & task 接近 B dataset & task)也就是给定真实图片 & 标签以及大量的手绘图片,请设计一种方法使得模型可以预测出手绘图片的标签是什么。


2.2 数据集介绍
这次的任务是源数据: 真实照片,目标数据: 手画涂鸦。
我们必须让model看过真实照片以及标签,尝试去预测手画涂鸦的标签为何。
资料位于’data/data58171/real_or_drawing.zip’
- Training : 5000 张真实图片 + label, 32 x 32 RGB
- Testing : 100000 张手绘图片,28 x 28 Gray Scale
- Label: 总共需要预测 10 个 class。
- 资料下载下来是以 0 ~ 9 作为label
特别注意一点: 这次的源数据和目标数据的图片都是平衡的,你们可以使用这个资料做其他事情。
项目要求
- 禁止手动标记label或在网上寻找label
- 禁止使用pre-trained model
数据准备
项目传送门
3 代码实现
3.1 数据集查看
# 导入相关库
import os
import cv2
import paddle
import numpy as np
from PIL import Image
import paddle.nn as nn
import matplotlib.pyplot as plt
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable, Mapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sized
2021-04-14 17:30:09,287 - INFO - font search path ['/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf', '/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/afm', '/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/pdfcorefonts']
2021-04-14 17:30:09,624 - INFO - generated new fontManager
展示一下训练集
def no_axis_show(img, title='', cmap=None):
# imshow, 縮放模式為nearest。
fig = plt.imshow(img, interpolation='nearest', cmap=cmap)
# 不要显示axis
fig.axes.get_xaxis().set_visible(False)
fig.axes.get_yaxis().set_visible(False)
plt.title(title)
#标签映射
titles = ['horse', 'bed', 'clock', 'apple', 'cat', 'plane', 'television', 'dog', 'dolphin', 'spider']
plt.figure(figsize=(18, 18))
for i in range(10):
plt.subplot(1, 10, i+1)
fig = no_axis_show(plt.imread(f'work/real_or_drawing/train_data/{i}/{500*i}.bmp'), title=titles[i])
# work/real_or_drawing/train_data/1/566.bmp

展示一下测试集
plt.figure(figsize=(18, 18))
for i in range(10):
plt.subplot(1, 10, i + 1)
fig = no_axis_show(plt.imread(f'work/real_or_drawing/test_data/0/0000{i}.bmp'), title='none')

3.2 Special Domain Knowledge
预处理source data
因为大家涂鸦的时候通常只会画轮廓,我们可以根据这点将source data做点边缘侦测处理,让source data更像target data一点。
Canny Edge Detection
算法这边不赘述,只教大家怎么用。若有兴趣欢迎参考wiki或这里。
cv2.Canny使用非常方便,只需要两个参数: low_threshold, high_threshold。
cv2.Canny(image, low_threshold, high_threshold)
简单来说就是当边缘值超过high_threshold,我们就确定它是edge。如果只有超过low_threshold,那就先判断一下再决定是不是edge。
以下我们直接拿source data做做看。
titles = ['horse', 'bed', 'clock', 'apple', 'cat', 'plane', 'television', 'dog', 'dolphin', 'spider']
plt.figure(figsize=(18, 18))
original_img = plt.imread(f'work/real_or_drawing/train_data/0/464.bmp')
plt.subplot(1, 5, 1)
no_axis_show(original_img, title='original')
gray_img = cv2.cvtColor(original_img, cv2.COLOR_RGB2GRAY)
plt.subplot(1, 5, 2)
no_axis_show(gray_img, title='gray scale', cmap='gray')
canny_50100 = cv2.Canny(gray_img, 50, 100)
plt.subplot(1, 5, 3)
no_axis_show(canny_50100, title='Canny(50, 100)', cmap='gray')
canny_150200 = cv2.Canny(gray_img, 150, 200)
plt.subplot(1, 5, 4)
no_axis_show(canny_150200, title='Canny(150, 200)', cmap='gray')
canny_250300 = cv2.Canny(gray_img, 250, 300)
plt.subplot(1, 5, 5)
no_axis_show(canny_250300, title='Canny(250, 300)', cmap='gray')

3.4 Data Process
在这里因为train_data的格式已经标注好每种图片,可以直接使用paddle.vision.datasets.DatasetFolder。所以只要使用这个API便可以做出一个datasets。在这里要是说明的是用DataFolder读取的时候有两个存放位置,这两个位置分别存放图片和标签。
此外还有数据预处理部分见下面代码:
3.4.1 数据预处理
import paddle.vision.transforms as T
from paddle.vision.datasets import DatasetFolder,ImageFolder
# 训练集预处理
def source_transform(imge):
# 转灰色: Canny 不吃 RGB。
img = T.to_grayscale(imge)
# cv2 不吃 skimage.Image,因此转成np.array后再做cv2.Canny
img = cv2.Canny(np.array(img), 170, 300)
# 重新np.array 转回 skimage.Image
img = Image.fromarray(np.array(img))
# 随机水平翻转 (Augmentation)
RHF= T.RandomHorizontalFlip(0.5)
img = RHF(img)
# 旋转15度内 (Augmentation),旋转后空的地方补0
RR = T.RandomRotation(15, fill=(0,))
img = RR(img)
# 最后Tensor供model使用。
tensor = T.ToTensor()
return tensor(img)
# 测试集预处理
target_transform = T.Compose([
# 转灰阶:
T.Grayscale(),
# 缩放: 因为source data是32x32,我们把target data的28x28放大成32x32。
T.Resize((32, 32)),
# 随机水平翻转(Augmentation)
T.RandomHorizontalFlip(0.5),
# 旋转15度内 (Augmentation),旋转后空的地方补0
T.RandomRotation(15, fill=(0,)),
# 最后Tensor供model使用。
T.ToTensor(),
])
#下面调用一下数据预处理函数
original_img = Image.open(f'work/real_or_drawing/train_data/0/464.bmp')
print('原来的照片形状:',np.array(original_img).shape)
process = source_transform(original_img)
print('预处理后的照片形状:',process .shape)
print(process)
plt.subplot(1,2,1)
no_axis_show(process .numpy().squeeze(), title='process image',cmap='gray')
plt.subplot(1,2,2)
no_axis_show(original_img, title='origimal image', cmap='gray')
原来的照片形状: (32, 32, 3)
预处理后的照片形状: [1, 32, 32]
Tensor(shape=[1, 32, 32], dtype=float32, place=CUDAPlace(0), stop_gradient=True,
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]])

3.4.2 数据加载器定义
# 生成数据集
source_dataset = DatasetFolder('work/real_or_drawing/train_data', transform=source_transform) # DatasetFolder 用于读取训练集,读取的时候图片和标签
target_dataset = DatasetFolder('work/real_or_drawing/test_data', transform=target_transform) # ImageFolder 用于读取测试集,读取的时候只有图片
# 数据加载器定义
source_dataloader = paddle.io.DataLoader(source_dataset, batch_size=50, shuffle=True)
target_dataloader = paddle.io.DataLoader(target_dataset, batch_size=50, shuffle=True)
test_dataloader = paddle.io.DataLoader(target_dataset, batch_size=100, shuffle=False)
%matplotlib inline
# 展示生成并经过预处理的的source_dataset和source_loader
print('=============source_dataset=============')
#由于使用了DatasetFolder,训练集这里有图片和标签两个参数image,label
for image, label in source_dataset:
print('image shape: {}, label: {}'.format(image.shape,label))
print('训练集数量:',len(source_dataset))
print('图片:',image)
print('标签:',label)
plt.imshow(image.numpy().squeeze(),cmap='gray')
break
=============source_dataset=============
image shape: [1, 32, 32], label: 0
训练集数量: 5000
图片: Tensor(shape=[1, 32, 32], dtype=float32, place=CUDAPlace(0), stop_gradient=True,
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]])
标签: 0

#source_loader的信息
print('=============source_dataloader=============')
for batch_id, (data,label) in enumerate(source_dataloader):
print('一个batch的图片:',data.shape) # 索引[0]存放图片
print('一个batch的标签个数:',label.shape) #索引[1]存放标签
print('图片:',data[0].shape)
break
# no_axis_show(x_data.numpy().squeeze(),title='process image', cmap='gray')
=============source_dataloader=============
一个batch的图片: [50, 1, 32, 32]
一个batch的标签个数: [50]
图片: [1, 32, 32]
# 展示生成并经过预处理的target_dataset和target_dataloader
print('=============target_dataset=============')
for image_,_ in target_dataset:
print('image shape: {}'.format(image_.shape))
print('测试集数量:',len(target_dataset))
plt.imshow(image_.numpy().squeeze(),cmap='gray')
print('图片:',image_)
break
=============target_dataset=============
image shape: [1, 32, 32]
测试集数量: 100000
图片: Tensor(shape=[1, 32, 32], dtype=float32, place=CUDAPlace(0), stop_gradient=True,
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]])

#target_dataloader的信息
print('=============target_dataloader=============')
for batch_id, (data_1,label_1) in enumerate(target_dataloader):
# print('一个batch的图片:',data[0].shape)
print('一个batch的图片:',data_1.shape)
print('一张图片的形状:',data_1[0].shape)
print(label_1)
break
=============target_dataloader=============
一个batch的图片: [50, 1, 32, 32]
一张图片的形状: [1, 32, 32]
Tensor(shape=[50], dtype=int64, place=CUDAPinnedPlace, stop_gradient=True,
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
3.5 搭建三个模型
这里的原理参考本文的1.3.2 第二类迁移学习的领域对抗性训练(Domain Adversarial Training)。
- Feature Extractor: 典型的VGG-like叠法。
- Label Predictor :MLP到尾
- Domain Classifier: MLP到尾。
特征抽取器不仅要骗过分类器,还要让预测器尽量有准确的预测结果。这是一个很大的神经网络,但是这三个不同的部分有不同的目标。
预测器想要正确的分类输入的图片,分类器想要正确分别输入是来自哪个分布。它们都只能看到特征抽取器抽取后的特征
抽取器一方面希望可以促使预测器做的好,另一方面要防止分类器做的好。
那么要怎么做呢?详见下面的模型训练部分。
3.5.1 搭建模型
class FeatureExtractor(nn.Layer):
'''
从图片中抽取特征
input [batch_size ,1,32,32]
output [batch_size ,512]
'''
def __init__(self):
super(FeatureExtractor, self).__init__()
self.conv = nn.Sequential(
nn.Conv2D(in_channels=1, out_channels=64, kernel_size=3, padding=1, stride=1), # [batch_size ,64,32,32] (32-3+2*1)/1 + 1
nn.BatchNorm2D(64),
nn.ReLU(),
nn.MaxPool2D(kernel_size=2), # [batch_size ,64,16,16]
nn.Conv2D(64, 128, 3, 1, 1), # [batch_size ,128,16,16]
nn.BatchNorm2D(128),
nn.ReLU(),
nn.MaxPool2D(2), # [batch_size ,128,8,8]
nn.Conv2D(128, 256, 3, 1, 1), # [batch_size ,256,8,8]
nn.BatchNorm2D(256),
nn.ReLU(),
nn.MaxPool2D(2), # [batch_size ,256,4,4]
nn.Conv2D(256, 256, 3, 1, 1), # [batch_size ,256,4,4]
nn.BatchNorm2D(256),
nn.ReLU(),
nn.MaxPool2D(2), # [batch_size ,256,2,2]
nn.Conv2D(256, 512, 3, 1, 1), # [batch_size ,512,2,2]
nn.BatchNorm2D(512),
nn.ReLU(),
nn.MaxPool2D(2), # [batch_size ,512,1,1]
nn.Flatten() # [batch_size ,512]
)
def forward(self, x):
x = self.conv(x) # [batch_size ,256]
return x
class LabelPredictor(nn.Layer):
'''
预测图像是什么动物
'''
def __init__(self):
super(LabelPredictor, self).__init__()
self.layer = nn.Sequential(
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512,512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, h):
c = self.layer(h)
return c
class DomainClassifier(nn.Layer):
'''预测时手绘还是真实图片'''
def __init__(self):
super(DomainClassifier, self).__init__()
self.layer = nn.Sequential(
nn.Linear(512, 512),
nn.BatchNorm1D(512),
nn.ReLU(),
nn.Linear(512, 512),
nn.BatchNorm1D(512),
nn.ReLU(),
nn.Linear(512, 512),
nn.BatchNorm1D(512),
nn.ReLU(),
nn.Linear(512, 512),
nn.BatchNorm1D(512),
nn.ReLU(),
nn.Linear(512, 1),
)
def forward(self, h):
y = self.layer(h)
return y
3.5.2 模型配置
import paddle.optimizer as optim
# 模型实例化
feature_extractor = FeatureExtractor()
label_predictor = LabelPredictor()
domain_classifier = DomainClassifier()
class_criterion = nn.CrossEntropyLoss()
domain_criterion = nn.BCEWithLogitsLoss()
# 定义优化器
optimizer_F = optim.Adam(learning_rate=0.0001, parameters=feature_extractor.parameters())
optimizer_C = optim.Adam(learning_rate=0.0001, parameters=label_predictor.parameters())
optimizer_D = optim.Adam(learning_rate=0.0001, parameters=domain_classifier.parameters())
3.5.3 开始训练
用梯度下降来训练,红色的分类器部分要调整参数,去让分辨领域的结果越正确越好;蓝色的预测器需要调参数,让标签的预测正确率越高越好;
这两者不一样的地方在于,当分类器要求绿色的抽取器去调整参数以满足以及的目标时,绿色的抽取器会尽量满足它的要求;还当红色的神经网络要求绿色的神经网络调整参数的时候,红色的网络会故意乘以-1,以防止分类器做的好。
最后红色的神经网路会无法做好分类,但是它必须要努力挣扎,它需要从绿色的NN给的不好的特征里面尽量去区分它们的领域。这样才能迫使绿色的NN产生红色的NN无法分辨的特征。难点就在于让红色的NN努力挣扎而不是很快放弃。

# 定义训练函数
import paddle
def train_epoch(source_dataloader, target_dataloader, lamb):
'''
Args:
source_dataloader: source data的dataloader
target_dataloader: target data的dataloader
lamb: 调控adversarial的loss系数。
'''
running_D_loss, running_F_loss = 0.0, 0.0
total_hit, total_num = 0.0, 0.0
for i, ((source_data, source_label), (target_data,_)) in enumerate(zip(source_dataloader, target_dataloader)):
mixed_data = paddle.concat([source_data, target_data], axis=0)
domain_label = paddle.zeros([source_data.shape[0] + target_data.shape[0], 1]).cuda()
# 设定source data的label为1
domain_label[:source_data.shape[0]] = 1
# Step 1 : 训练Domain Classifier
feature = feature_extractor(mixed_data)
# 因为我们在Step 1不需要训练Feature Extractor,所以把feature detach
#这样可以把特征抽取过程的函数从当前计算图分离,避免loss backprop传递过去。
domain_logits = domain_classifier(feature.detach())
loss = domain_criterion(domain_logits, domain_label)
running_D_loss += loss.numpy().tolist()[0]
loss.backward()
optimizer_D.step()
# Step 2 : 训练Feature Extractor和Domain Classifier
class_logits = label_predictor(feature[:source_data.shape[0]])
domain_logits = domain_classifier(feature)
# loss为原本的class CE - lamb * domain BCE,相減的原因是我们希望特征能够使得domain_classifier分不出来输入的图片属于哪个领域
loss = class_criterion(class_logits, source_label) - lamb * domain_criterion(domain_logits, domain_label)
running_F_loss += loss.numpy().tolist()[0]
loss.backward()
optimizer_F.step()
optimizer_C.step()
#训练了一轮,清空所有梯度信息
optimizer_D.clear_grad()
optimizer_F.clear_grad()
optimizer_C.clear_grad()
# return class_logits,source_label #测试
bool_eq = paddle.argmax(class_logits, axis=1) == source_label.squeeze()
total_hit += np.sum(bool_eq.numpy()!=0)
total_num += source_data.shape[0]
print(i, end='\r')
return running_D_loss / (i+1), running_F_loss / (i+1), total_hit / total_num
# 训练125 epochs
train_D_loss_history,train_F_loss_history,train_acc_history = [], [], []
for epoch in range(125):
train_D_loss, train_F_loss, train_acc = train_epoch(source_dataloader, target_dataloader, lamb=0.1)
train_D_loss_history.append(train_D_loss)
train_F_loss_history.append(train_F_loss)
train_acc_history.append(train_acc)
epoch = epoch + 1
if epoch % 50 == 0:
paddle.save(feature_extractor.state_dict(), "ckp/{}ckp_feature_extractor.pdparams".format(str(epoch)))
paddle.save(label_predictor.state_dict(), "ckp/{}ckp_label_predictor.pdparams".format(str(epoch)))
print('epoch {:>3d}: train D loss: {:6.4f}, train F loss: {:6.4f}, acc {:6.4f}'.format(epoch, train_D_loss, train_F_loss, train_acc))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:648: UserWarning: When training, we now always track global mean and variance.
"When training, we now always track global mean and variance.")
5
epoch 1: train D loss: 0.0202, train F loss: 0.0416, acc 0.9844
epoch 2: train D loss: 0.0291, train F loss: 0.0400, acc 0.9824
epoch 3: train D loss: 0.0308, train F loss: 0.0378, acc 0.9872
epoch 4: train D loss: 0.0351, train F loss: 0.0576, acc 0.9792
epoch 5: train D loss: 0.0348, train F loss: 0.0456, acc 0.9830
epoch 6: train D loss: 0.0395, train F loss: 0.0360, acc 0.9860
epoch 7: train D loss: 0.0353, train F loss: 0.0508, acc 0.9822
epoch 8: train D loss: 0.0390, train F loss: 0.0348, acc 0.9874
epoch 9: train D loss: 0.0413, train F loss: 0.0503, acc 0.9808
epoch 10: train D loss: 0.0440, train F loss: 0.0480, acc 0.9796
epoch 11: train D loss: 0.0413, train F loss: 0.0428, acc 0.9834
epoch 12: train D loss: 0.0422, train F loss: 0.0402, acc 0.9842
epoch 13: train D loss: 0.0512, train F loss: 0.0506, acc 0.9782
epoch 14: train D loss: 0.0519, train F loss: 0.0549, acc 0.9814
epoch 15: train D loss: 0.0446, train F loss: 0.0309, acc 0.9878
epoch 16: train D loss: 0.0485, train F loss: 0.0395, acc 0.9858
epoch 17: train D loss: 0.0531, train F loss: 0.0445, acc 0.9826
epoch 18: train D loss: 0.0507, train F loss: 0.0370, acc 0.9864
epoch 19: train D loss: 0.0525, train F loss: 0.0516, acc 0.9812
epoch 20: train D loss: 0.0546, train F loss: 0.0422, acc 0.9832
epoch 21: train D loss: 0.0522, train F loss: 0.0407, acc 0.9856
epoch 22: train D loss: 0.0541, train F loss: 0.0248, acc 0.9884
epoch 23: train D loss: 0.0537, train F loss: 0.0352, acc 0.9872
epoch 24: train D loss: 0.0517, train F loss: 0.0291, acc 0.9884
epoch 25: train D loss: 0.0611, train F loss: 0.0304, acc 0.9866
epoch 26: train D loss: 0.0590, train F loss: 0.0407, acc 0.9840
epoch 27: train D loss: 0.0588, train F loss: 0.0312, acc 0.9886
epoch 28: train D loss: 0.0569, train F loss: 0.0347, acc 0.9852
epoch 29: train D loss: 0.0586, train F loss: 0.0501, acc 0.9810
epoch 30: train D loss: 0.0563, train F loss: 0.0530, acc 0.9796
epoch 31: train D loss: 0.0699, train F loss: 0.0683, acc 0.9734
epoch 32: train D loss: 0.0577, train F loss: 0.0367, acc 0.9862
epoch 33: train D loss: 0.0546, train F loss: 0.0385, acc 0.9860
epoch 34: train D loss: 0.0669, train F loss: 0.0304, acc 0.9868
epoch 35: train D loss: 0.0629, train F loss: 0.0350, acc 0.9846
epoch 36: train D loss: 0.0573, train F loss: 0.0194, acc 0.9918
epoch 37: train D loss: 0.0660, train F loss: 0.0222, acc 0.9886
epoch 38: train D loss: 0.0702, train F loss: 0.0388, acc 0.9852
epoch 39: train D loss: 0.0710, train F loss: 0.0333, acc 0.9868
epoch 40: train D loss: 0.0724, train F loss: 0.0372, acc 0.9828
epoch 41: train D loss: 0.0731, train F loss: 0.0312, acc 0.9856
epoch 42: train D loss: 0.0744, train F loss: 0.0263, acc 0.9890
epoch 43: train D loss: 0.0788, train F loss: 0.0238, acc 0.9876
epoch 44: train D loss: 0.0806, train F loss: 0.0312, acc 0.9862
epoch 45: train D loss: 0.0726, train F loss: 0.0442, acc 0.9808
epoch 46: train D loss: 0.0763, train F loss: 0.0461, acc 0.9814
epoch 47: train D loss: 0.0765, train F loss: 0.0501, acc 0.9818
epoch 48: train D loss: 0.0770, train F loss: 0.0327, acc 0.9884
epoch 49: train D loss: 0.0789, train F loss: 0.0294, acc 0.9874
epoch 50: train D loss: 0.0841, train F loss: 0.0306, acc 0.9860
epoch 51: train D loss: 0.0807, train F loss: 0.0439, acc 0.9810
epoch 52: train D loss: 0.0742, train F loss: 0.0327, acc 0.9872
epoch 53: train D loss: 0.0797, train F loss: 0.0293, acc 0.9870
epoch 54: train D loss: 0.0826, train F loss: 0.0342, acc 0.9848
epoch 55: train D loss: 0.0840, train F loss: 0.0353, acc 0.9846
epoch 56: train D loss: 0.0810, train F loss: 0.0187, acc 0.9898
epoch 57: train D loss: 0.0846, train F loss: 0.0278, acc 0.9878
epoch 58: train D loss: 0.0878, train F loss: 0.0430, acc 0.9820
epoch 59: train D loss: 0.0933, train F loss: 0.0413, acc 0.9828
epoch 60: train D loss: 0.0856, train F loss: 0.0380, acc 0.9864
epoch 61: train D loss: 0.0883, train F loss: 0.0312, acc 0.9856
epoch 62: train D loss: 0.0851, train F loss: 0.0281, acc 0.9888
epoch 63: train D loss: 0.0929, train F loss: 0.0244, acc 0.9886
epoch 64: train D loss: 0.0968, train F loss: 0.0327, acc 0.9848
epoch 65: train D loss: 0.0973, train F loss: 0.0300, acc 0.9866
epoch 66: train D loss: 0.1008, train F loss: 0.0298, acc 0.9860
epoch 67: train D loss: 0.0987, train F loss: 0.0480, acc 0.9790
epoch 68: train D loss: 0.1049, train F loss: 0.0304, acc 0.9856
epoch 69: train D loss: 0.1018, train F loss: 0.0231, acc 0.9870
epoch 70: train D loss: 0.0993, train F loss: 0.0237, acc 0.9874
epoch 71: train D loss: 0.1073, train F loss: 0.0213, acc 0.9896
epoch 72: train D loss: 0.1006, train F loss: 0.0291, acc 0.9874
epoch 73: train D loss: 0.1113, train F loss: 0.0322, acc 0.9864
epoch 74: train D loss: 0.1169, train F loss: 0.0280, acc 0.9864
epoch 75: train D loss: 0.0981, train F loss: 0.0250, acc 0.9866
epoch 76: train D loss: 0.1152, train F loss: 0.0200, acc 0.9894
epoch 77: train D loss: 0.1056, train F loss: 0.0209, acc 0.9884
epoch 78: train D loss: 0.1171, train F loss: 0.0323, acc 0.9834
epoch 79: train D loss: 0.1179, train F loss: 0.0358, acc 0.9834
epoch 80: train D loss: 0.1054, train F loss: 0.0220, acc 0.9884
epoch 81: train D loss: 0.1150, train F loss: 0.0454, acc 0.9808
epoch 82: train D loss: 0.1175, train F loss: 0.0211, acc 0.9900
epoch 83: train D loss: 0.1161, train F loss: 0.0178, acc 0.9898
epoch 84: train D loss: 0.1174, train F loss: 0.0285, acc 0.9870
epoch 85: train D loss: 0.1233, train F loss: 0.0360, acc 0.9836
epoch 86: train D loss: 0.1247, train F loss: 0.0277, acc 0.9870
epoch 87: train D loss: 0.1178, train F loss: 0.0126, acc 0.9914
epoch 88: train D loss: 0.1292, train F loss: 0.0260, acc 0.9860
epoch 89: train D loss: 0.1216, train F loss: 0.0266, acc 0.9858
epoch 90: train D loss: 0.1400, train F loss: 0.0245, acc 0.9872
epoch 91: train D loss: 0.1286, train F loss: 0.0178, acc 0.9876
epoch 92: train D loss: 0.1263, train F loss: 0.0142, acc 0.9914
epoch 93: train D loss: 0.1287, train F loss: 0.0249, acc 0.9874
epoch 94: train D loss: 0.1305, train F loss: 0.0230, acc 0.9868
epoch 95: train D loss: 0.1218, train F loss: 0.0244, acc 0.9882
epoch 96: train D loss: 0.1289, train F loss: 0.0261, acc 0.9872
epoch 97: train D loss: 0.1279, train F loss: 0.0220, acc 0.9878
epoch 98: train D loss: 0.1296, train F loss: 0.0240, acc 0.9880
epoch 99: train D loss: 0.1254, train F loss: 0.0158, acc 0.9906
epoch 100: train D loss: 0.1340, train F loss: 0.0096, acc 0.9928
epoch 101: train D loss: 0.1321, train F loss: 0.0208, acc 0.9876
epoch 102: train D loss: 0.1388, train F loss: 0.0338, acc 0.9824
epoch 103: train D loss: 0.1355, train F loss: 0.0224, acc 0.9874
epoch 104: train D loss: 0.1366, train F loss: 0.0405, acc 0.9806
epoch 105: train D loss: 0.1386, train F loss: 0.0367, acc 0.9838
epoch 106: train D loss: 0.1402, train F loss: 0.0294, acc 0.9872
epoch 107: train D loss: 0.1353, train F loss: 0.0310, acc 0.9850
epoch 108: train D loss: 0.1380, train F loss: 0.0107, acc 0.9918
epoch 109: train D loss: 0.1475, train F loss: 0.0178, acc 0.9892
epoch 110: train D loss: 0.1376, train F loss: 0.0189, acc 0.9892
epoch 111: train D loss: 0.1350, train F loss: 0.0119, acc 0.9908
epoch 112: train D loss: 0.1454, train F loss: 0.0132, acc 0.9902
epoch 113: train D loss: 0.1463, train F loss: 0.0373, acc 0.9818
epoch 114: train D loss: 0.1418, train F loss: 0.0376, acc 0.9802
epoch 115: train D loss: 0.1501, train F loss: 0.0323, acc 0.9834
epoch 116: train D loss: 0.1446, train F loss: 0.0132, acc 0.9902
epoch 117: train D loss: 0.1367, train F loss: 0.0181, acc 0.9896
epoch 118: train D loss: 0.1407, train F loss: 0.0171, acc 0.9908
epoch 119: train D loss: 0.1416, train F loss: 0.0169, acc 0.9890
epoch 120: train D loss: 0.1469, train F loss: 0.0152, acc 0.9914
epoch 121: train D loss: 0.1444, train F loss: 0.0141, acc 0.9906
epoch 122: train D loss: 0.1522, train F loss: 0.0237, acc 0.9854
epoch 123: train D loss: 0.1450, train F loss: 0.0274, acc 0.9856
epoch 124: train D loss: 0.1530, train F loss: 0.0134, acc 0.9900
epoch 125: train D loss: 0.1607, train F loss: 0.0277, acc 0.9848
#保存模型
paddle.save(feature_extractor.state_dict(), "model/feature_extractor_final.pdparams")
paddle.save(label_predictor.state_dict(), "model/label_predictor_final.pdparams")
3.5.4 可视化训练过程
#分开绘制三条曲线
epochs = range(epoch)
# 模型训练可视化
def draw_process(title,color,iters,data,label):
plt.title(title, fontsize=20) # 标题
plt.xlabel("epochs", fontsize=15) # x轴
plt.ylabel(label, fontsize=15) # y轴
plt.plot(iters, data,color=color,label=label) # 画图
plt.legend()
plt.grid()
plt.savefig('{}.jpg'.format(title))
plt.show()
# Domain Classifier train loss
draw_process("train D loss","green",epochs,train_D_loss_history,"loss")
# Feature Extrator train loss
draw_process("train F loss","green",epochs,train_F_loss_history,"loss")
# Label Predictor的train accuracy
draw_process("train acc","red",epochs,train_acc_history,"accuracy")



4 模型预测
在测试集上执行预测
4.1 预测测试集结果
result = []
label_predictor.eval()
feature_extractor.eval()
for i, (test_data, _) in enumerate(test_dataloader):
test_data = test_data.cuda()
class_logits = label_predictor(feature_extractor(test_data))
x = paddle.argmax(class_logits, axis=1).cpu().detach().numpy()
result.append(x)
import pandas as pd
result = np.concatenate(result)
# Generate your submission
df = pd.DataFrame({'id': np.arange(0,len(result)), 'label': result})
df.to_csv('DaNN_submission.csv',index=False)
# 统计预测的标签数量,10种图片的预测数量如下:
print(df.iloc[:,1].value_counts())
5 26514
3 20621
4 10328
7 9979
8 9213
1 9159
6 4518
9 4365
0 3781
2 1522
Name: label, dtype: int64
4.2 展示预测结果
展示前一百幅的结果
labels = iter(df['label'][0:100])
def f_names():
for i in range(100):
yield 'work/real_or_drawing/test_data/0/{:05}.bmp'.format(i)
names = iter(f_names())
for j in range(10):
plt.figure(figsize=(18, 18))
for i in range(10):
plt.subplot(1, 10, i + 1)
name = next(names)
label = next(labels)
fig = no_axis_show(plt.imread(name),title=titles[label])
yield 'work/real_or_drawing/test_data/0/{:05}.bmp'.format(i)
names = iter(f_names())
for j in range(10):
plt.figure(figsize=(18, 18))
for i in range(10):
plt.subplot(1, 10, i + 1)
name = next(names)
label = next(labels)
fig = no_axis_show(plt.imread(name),title=titles[label])








5 总结分析
本次项目共进行了三次训练:第一次训练200个epochs,第二次训练125个epoch,第三次250个epoch。
可以通过以下的曲线对比,模型的训练可视化如下,可以发现:
- 1) 三次训练中特征抽取器(Feature Extractor)的train F loss曲线都呈现下降趋势。
- 2) 而epoch=125,和epoch=200时,领域的分类器(Domain Classifier)的train D loss曲线呈现增大的趋势,可能原因是训练不稳定;epoch=250,领域的分类器(Domain Classifier)的train D loss曲线逐渐收敛。
- 3)三次的训练,标签预测器(Label Lredictor)的acc曲线在上升,最终acc都在0.98左右。
特征抽取器就是不断抽取一些领域分类器不一样的特征为了能骗过它。并且他们这样相生相克就是为了模型能有很好的预测能力,这在标签预测器的acc曲线充分地表现了出来。因此,这就是迁移学习——Domain-adversarial training的根本所在!(Domain-adversarial training可以看成GAN的一种。它想要把source data和target data转换到同样的领域上,让它们有同样的分布。)
- epoch=125
训练过程不稳定



- epoch=200



- epoch=250



模型的前100张测试集结果对比:
就前100张预测图片来看,三种预测结果差别还挺大的,因为没有标签,无法得知预测结果好坏。
epoch=125:


epoch=200
epoch=250




6 参考文献&文章&代码
[1] 李宏毅机器学习
[2] https://blog.csdn.net/weixin_44673043/article/details/114858094
[3] https://helloai.blog.csdn.net/article/details/104484924
[4]https://datawhalechina.github.io/leeml-notes/#/chapter30/chapter30
作者介绍
百度AI Studio个人主页, 我在AI Studio上获得白银等级,点亮2个徽章,来互关呀~
CSDN:https://i.csdn.net/#/user-center/profile?spm=1011.2124.3001.5111
交流qq:3207820044