redisson简单使用,分布式锁实现原理和源码分析 和 可能出现的问题,redis红锁
https://www.jianshu.com/p/7afacd0f5ccb
https://www.jianshu.com/p/bb6d69720c5c
Redisson分布式锁
引入 和 初始化
<dependency>
<groupId>org.redissongroupId>
<artifactId>redissonartifactId>
<version>3.6.5version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
redis 和 redisson配置
@Bean
public RedissonClient redisson(){
// 单机模式
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.3.170:6379").setDatabase(0);
return Redisson.create(config);
}
redis集群
/*config.useClusterServers()
.setScanInterval(2000)
//.addNodeAddress("redis://10.0.29.30:6379", "redis://10.0.29.95:6379")*/
spring:
redis:
host: 192.168.44.146
用分布式锁 扣减库存
@RestController
public class IndexController {
@Autowired
private RedissonClient redisson;
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* 模拟下单减库存的场景
* @return
*/
@RequestMapping(value = "/duduct_stock")
public String deductStock(){
//定义锁对象
String lockKey = "product_001";
// 1.获取锁对象。使用redisson
RLock redissonLock = redisson.getLock(lockKey);
try{
// 2.加锁。使用redisson
redissonLock.lock(); // 等价于 setIfAbsent(lockKey,"wangcp",10,TimeUnit.SECONDS);
// stringRedisTemplate 中拿当前库存的值
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
//只有一个线程过来了,自减1
int realStock = stock - 1;
//重新设置进去
stringRedisTemplate.opsForValue().set("stock",realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
}else{
System.out.println("扣减失败,库存不足");
}
}finally {
// 3.释放锁
redissonLock.unlock();
}
return "end";
}
}
Redisson 分布式锁实现原理图
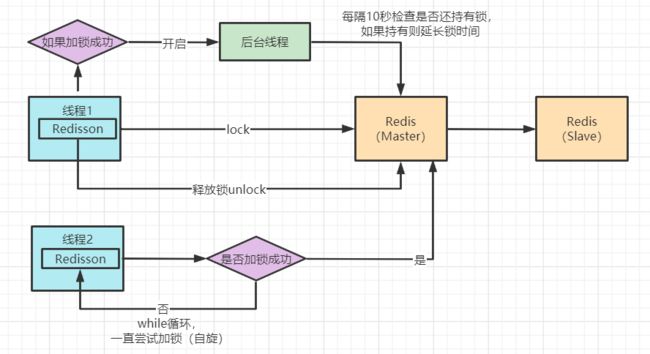
Redisson 底层源码分析
我们点击 lock() 方法,查看源码,最终看到以下代码
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
internalLockLeaseTime = unit.toMillis(leaseTime);
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}
没错,加锁最终执行的就是这段 lua 脚本语言。
if (redis.call('exists', KEYS[1]) == 0) then
redis.call('hset', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
脚本的主要逻辑为:
- exists 判断 key 是否存在
- 当判断不存在则设置 key
- 然后给设置的key追加过期时间
这段lua脚本命令在Redis中执行时,会被当成一条命令来执行,能够保证原子性,故要不都成功,要不都失败。
我们在源码中看到Redssion的许多方法实现中很多都用到了lua脚本,这样能够极大的保证命令执行的原子性。
Redisson锁自动“续命”源码
private void scheduleExpirationRenewal(final long threadId) {
if (expirationRenewalMap.containsKey(getEntryName())) {
return;
}
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
RFuture<Boolean> future = commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
future.addListener(new FutureListener<Boolean>() {
@Override
public void operationComplete(Future<Boolean> future) throws Exception {
expirationRenewalMap.remove(getEntryName());
if (!future.isSuccess()) {
log.error("Can't update lock " + getName() + " expiration", future.cause());
return;
}
if (future.getNow()) {
// reschedule itself
scheduleExpirationRenewal(threadId);
}
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
if (expirationRenewalMap.putIfAbsent(getEntryName(), task) != null) {
task.cancel();
}
}
这段代码是在加锁后开启一个守护线程进行监听。
- Redisson超时时间默认设置30s,线程每10s调用一次判断锁还是否存在,如果存在则延长锁的超时时间。
现在,我们再回过头来看看案例5中的加锁代码与原理图,其实完善到这种程度已经可以满足很多公司的使用了,并且很多公司也确实是这样用的。但我们再思考下是否还存在问题呢?例如以下场景:
- 众所周知 Redis 在实际部署使用时都是集群部署的,那在高并发场景下我们加锁,
- 当把key写入到master节点后,master还未同步到slave节点时master宕机了,
- 原有的slave节点经过选举变为了新的master节点,此时可能就会出现锁失效问题。
- 通过分布式锁的实现机制我们知道,高并发场景下只有加锁成功的请求可以继续处理业务逻辑。
- 那就出现了大伙都来加锁,但有且仅有一个加锁成功了,剩余的都在等待。
- 其实分布式锁与高并发在语义上就是相违背的,我们的请求虽然都是并发,但Redis帮我们把请求进行了排队执行,也就是把我们的并行转为了串行。
- 串行执行的代码肯定不存在并发问题了,但是程序的性能肯定也会因此受到影响。
针对这些问题,我们再次思考解决方案
“CAP原则又称CAP定理,指的是在一个分布式系统中,
- 一致性(Consistency)、
- 可用性(Availability)、
- 分区容错性(Partition tolerance)。
CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。”
在思考解决方案时我们首先想到CAP原则(一致性、可用性、分区容错性),那么现在的Redis就是满足AP(可用性、分区容错性),
如果想要解决该问题我们就需要寻找满足**CP(一致性、分区容错性)**的分布式系统。
首先想到的就是zookeeper,
zookeeper的集群间数据同步机制是
- 当主节点接收数据后不会立即返回给客户端成功的反馈,它会先与子节点进行数据同步,
- 半数以上的节点都完成同步后才会通知客户端接收成功。并且如果主节点宕机后,
- 根据zookeeper的Zab协议(Zookeeper原子广播)重新选举的主节点一定是已经同步成功的。
那么问题来了,Redisson与zookeeper分布式锁我们如何选择呢?
- 答案是如果并发量没有那么高,可以用zookeeper来做分布式锁,但是它的并发能力远远不如Redis。
- 如果你对并发要求比较高的话,那就用Redis,偶尔出现的主从 架构锁失效的问题其实是可以容忍的。
关于第二个提升性能的问题,我们可以参考ConcurrentHashMap的锁分段技术的思想,
- 例如我们代码的库存量当前为1000,那我们可以分为10段,每段100,然后对每段分别加锁,
- 这样就可以同时执行10个请求的加锁与处理,当然有要求的同学还可以继续细分。但其实Redis的Qps已经达到10W+了,没有特别高并发量的场景下也是完全够用的。
分布式锁 原理
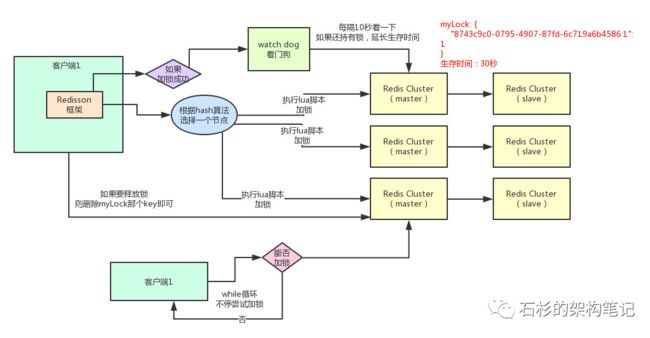
如图所示啊,石杉大佬画的redisson分布式锁原理。
大概总结下,保证我们的key落到一个集群里,并且加锁操作是基于lua脚本的原子性操作,对于锁延迟由watch dog控制。
具体可以看https://www.cnblogs.com/AnXinliang/p/10019389.html
二 Redis分布式锁可能出现多个系统加锁成功的现象
如果你对某个redis master实例,写入了myLock这种锁key的value,
-
此时会异步复制给对应的master slave实例。
-
但是这个过程中一旦发生redis master宕机,主备切换,redis slave变为了redis master。
-
接着就会导致,客户端2来尝试加锁的时候,在新的redis master上完成了加锁,而客户端1也以为自己成功加了锁。
此时就会导致多个客户端对一个分布式锁完成了加锁。
这时系统在业务语义上一定会出现问题,导致各种脏数据的产生。
所以这个就是redis cluster,或者是redis master-slave架构的主从异步复制导致的redis分布式锁的最大缺陷:在redis master实例宕机的时候,可能导致多个客户端同时完成加锁。
如果我们想保证完全一致,必须重写Redisson加锁的逻辑了,保证必须mater和slave同时加锁成功,我们整个加锁才是成功的。
三 .redis的红锁
上面的2是对于单个主从结构我们可以这样干,如果假设我们有多个相对独立的master,无slave呢?我们在其中一个master上加了,然后它挂了岂不是我们的数据会在剩下的结点会重新加锁成功?
redis引入了红锁的概念:用Redis中的多个master实例,来获取锁,
- 只有**
大多数实例获取到了锁,才算是获取成功**。
具体的红锁算法分为以下五步:
- 1.获取当前的时间(单位是毫秒)。
- 2.使用相同的key和 随机值 在N个节点上请求锁。
- 这里获取锁的尝试时间要远远 小于锁的超时时间,
- 防止某个masterDown了,我们还在不断的获取锁,而被阻塞过长的时间。
- 3.只有在**
大多数节点上**获取到了锁,- 而且总的获取时间小于锁的超时时间的情况下,认为锁获取成功了。
- 如果锁获取成功了,锁的超时时间就是
- 最初的锁超时时间 进去 获取锁的总耗时时间。(加上吧)
- 如果锁获取失败了,
- 不管是因为获取成功的节点的数目没有过半,
- 还是因为获取锁的耗时超过了锁的释放时间,
- 都会将已经设置了key的master上的key删除。