Flink中的Time和Window
文末附下载地址
1. Flink中Time语义与Watermark
1.1 Flink中的时间语义
Flink中的时间语义分为两种,分别是处理时间(Process Time)和事件时间(Event Time)。
处理时间是指执行处理操作的机器的系统时间,在流式数据计算中,处理时间是最简单的时间语义,不需要各个节点之间进行协调同步,也不需要考虑数据在流中的位置。
事件时间是指每个事件在对应的设备上发生的时间,也就是数据生成时间,数据一旦生成,这个时间就确定了,这个时间作为一个属性嵌入到数据中,其实也就是这叫数据记录的时间戳。由于在事件时间语义下,先产生的数据先处理,这就要求我们要保证数据到达的顺序,但真实情况下由于分布式系统中网络传输延迟的不确定性,实际面对的数据往往是乱序的。所以,这种情况下,我们不能单单的使用数据自带的时间戳作为时钟,而是需要另外一个标志来表示事件时间的进展,在Flink中把它叫做事件时间的“水位线”(watermark)。
在Flink1.12版本之前默认的时间语义是处理时间,1.12之后将事件时间作为了默认的时间语义。
1.2 水位线(Watermark)
1.2.1 什么是水位线
在事件时间语义下,不依赖于系统时间,而是用数据自身的时间戳定义了一个时钟,用来表示当前时间的进展。于是每个并行子任务都有一个自己的逻辑时钟,它的前进靠数据的时间戳来驱动。但是这种驱动本身存在问题,因为数据本身在处理转换的过程中会变化,如果遇到窗口聚合等操作,其实要攒一批数据才会有一个结果,那么下游的数据就会变少,时间进度的控制就不够精细了。而且,数据向下游传递的过程中,一般只能发送给一个子任务,这样其他并行子任务的时钟就无法推进了。
所以把时钟以数据的形式传递出去,告诉下游任务当前时间的进展,而且这个时钟的传递不会因为窗口聚合之类的操作而停滞。一种简单的想法是在数据流中加入一个时钟标记,记录当前的事件时间。这个标记可以直接广播到下游,当下游任务收到这个标记,就可以更新自己的时钟了。由于类似水流中用来做标志的记号,在Flink中,这种用来衡量事件时间EventTime进展的标记,就被称作为水位线(watermark)。
-
有序流中的水位线
在理想状态下,数据应该按照生成的先后顺序进入流中,我们只需要从每个数据中提取时间戳,就可以保证是从小到大增长的,而从插入的水位线也会不断增长、事件时钟也会不断向前推进。但是在实际场景下,由于数据量比较大,可能会有很多的数据时间戳屎一样的,这个时候每来一条数据就生成提取时间戳作为watermark,就会做了大量的无用功。即使时间戳不一样,同时涌来的数据时间戳的时间差也会非常小,对处理计算没有什么影响。所以为了提高效率,每隔一段时间会生成一个水位线,这个水位线的时间戳就是当前最新的数据的时间戳。
需要注意的是,水位线插入的周期,本身也是一个时间概念。在当前事件时间语义下,假设每隔100ms生成一个watermark,那就要等事件时间推进100ms才能插入,但是事件时间本身的进展,就是需要watermark来表示的。所以对于水位线的生成,周期时间指的是处理时间(系统时间)而不是事件时间。
关于watarmark的间隔是事件时间还是处理时间,在源码
TimestampsAndWatermarksOperator类中有所体现。
-
乱序流中的水位线
有序流中的处理非常简单,看起来也没有起到太大的作用。但这种情况只存在于理想状态下。在分布式系统中,由于数据在节点之间传输,会因为网络问题传输延迟的不确定性,导致数据顺序发生改变,这就是所谓的“乱序数据”。
这里的“乱序数据”是指数据的先后顺序不一致,主要就是基于数据生成的时间戳而言的。有可能一个5秒产生的数据,生成时间肯定比7秒产生的数据要早,但是由于网络问题导致5秒产生的数据在7秒产生的数据之后才到达处理节点。所以这个时候,我们希望用水位线来表示当前事件时间的进展。和之前的想法一样,靠数据驱动,来一个数据就提取它的时间戳作为watermark,不过由于现在的数据是乱序,就可能出现watermark回退了,watermark回退代表着时钟回退了,所以水位线的时间戳不能减小。
所以我们需要在插入新的水位线时,先判断当前时间戳是否比之前的大,否则就不会生成新的水位线。也就是说,只有数据的时间戳比当前的时钟大,才能推动时钟前进,这个时候才会插入新的watermark。
因为考虑到大数据下的处理效率,同样也可以使用周期性生成水位线的策略。周期性的情况下,只需要将之前所有的数据中的最大时间戳保存下来,需要插入水位线时,就直接以它作为新的watermark插入即可。
但是由于数据乱序,这种情况下我们没法处理迟到的数据,所以为了处理迟到的数据,我们可以让watermark延迟2秒,也就是说生成的watermark是在最大的时间戳的基础上减去延迟的2秒。如果2秒内迟到的数据还是没到,我们可以稍微调整的大一点,比如5秒,最终的目的就是让所有属于该窗口的数据进入到窗口中。
-
水位线的特性
- 水位线时插入到数据流中的一个标记,可以认为是一条特殊的数据
- 水位线的主要内容是一个时间戳,用来表示当前事件时间的进展
- 水位线是基于数据的时间戳生成的
- 水位线的时间戳必须是递增的,以确保任务的事件时钟一直向前推进
- 水位线可以设置延迟,来保证正确处理延迟数据
- 一个水位线t,表示在t之前的所有数据都到齐了
1.2.2 如何生成水位线
-
水位线生成策略
在Flink的DataStreamAPI中,有一个单独用于生成水位线的方法
.assignTimestampsAndWatermarks(),它为流中的数据分配时间戳,并生成水位线来指示事件时间:
该方法需要一个
WatermarkStrategy作为参数,这个其实就是所谓的水位线生成策略。WatermarkStrategy中包含了一个时间戳分配器TimestampAssigner和一个水位线生成器WatermarkGenerator。
-
Flink内置的水位线生成器
Flink提供了内置水位线生成器(WatermarkGenerator),不仅开箱即用简化了编程,同时也为自定义水位线策略提供了模板。内置的生成器可以通过
WatermarkStrategy的静态方法来创建。它们都是周期性生成水位线的,分别对应着有序流forMonotonousTimestamps和乱序流forBoundedOutOfOrderness。周期性的时间是多少呢?我们可以在源码中看到,在WatermarkGenerator类中,onEvent和onPeriodicEmit分别对应着断点式和周期性的生成watermark的方式。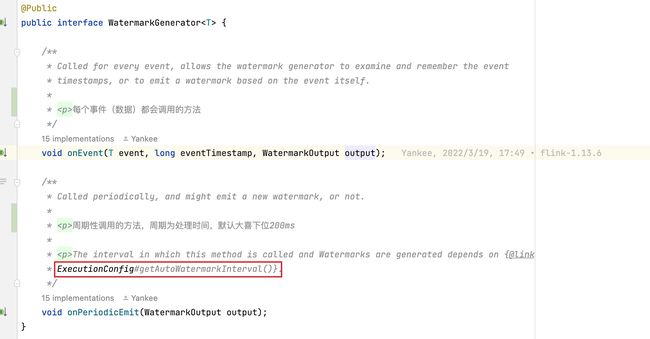
需要注意的是针对有序流和无序流中,生成的watermark略有不同,无论在有序流还是无序流中,最终生成的水位线都是
当前最大时间戳 - 1,不同点是使用forBoundedOutOfOrderness生成无序流的时间戳是有一个参数maxOutOfOrderness,表示允许最大的乱序时间,所以最后生成的watermark还需要减去maxOutOfOrderness。但其实无论是forMonotonousTimestamp还是forBoundedOutOfOrderness最后都调用的是BoundedOutOfOrdernessWatermarks,只是forMonotonousTimestamp在调用时maxOutOfOrderness=0。
1.2.3 自定义水位线策略
一般来说,Flink内置的水位线生成器就可以满足我们的大部分需求了,有时候可能有一些比较复杂的业务需求,可能就要我们自定义实现水位线策略WatermarkStrategy。在WatermarkStrategy中,时间戳分配器都差不多,主要区别在WatermarkGenerator的实现。整体来说,Flink有两种不同的水位线生成方式,分别是是周期性的(Periodic)和断点式的(Punctuated)。这两种的区别就在于在那个方法中发出水位线,如果是在onPeriodicEmit中发出水位线,则是周期性的,如果在onEvent中发出水位线,那就是断点式。
-
周期性
/** * 被周期性调用 * * @param output */ @Override public void onPeriodicEmit(WatermarkOutput output) { long watermark = maxTs - maxDelay; LOG.info("生成的watermark:{}", watermark); output.emitWatermark(new Watermark(watermark)); } -
断点式
/** * 当数据来的时候调用 * * @param event 事件 * @param eventTimestamp 事件中的时间 * @param output */ @Override public void onEvent(WaterSensor_Java event, long eventTimestamp, WatermarkOutput output) { long maxTimeStamp = Math.max(eventTimestamp, maxTs); LOG.info("获取数据中最大的时间戳:{}", maxTimeStamp); maxTs = maxTimeStamp; long watermark = maxTs - maxDelay; LOG.info("生成的watermark:{}", watermark); output.emitWatermark(new Watermark(watermark)); }
1.2.4 在自定义数据源中发送水位线
@Override
public void run(SourceContext<Event> ctx) throws Exception {
Random random = new Random();
String[] users = {"Mary", "Bob", "Alice"};
String[] urls = {"./home", "./cart", "./prod?id=1"};
while (running) {
long timeInMillis = Calendar.getInstance().getTimeInMillis();
String user = users[random.nextInt(users.length)];
String url = urls[random.nextInt(urls.length)];
Event event = new Event(user, url, timeInMillis);
// 使用collectWithTimestamp方法将数据发送出去,并指明数据中的时间戳字段
ctx.collectWithTimestamp(event, event.getTimestamp());
// 发送水位线
ctx.emitWatermark(new Watermark(event.getTimestamp() - 1L));
Thread.sleep(1000L);
}
}
需要注意的是,在自定义数据源中发送了水位线后,就不能在程序中用assignTimestampsAndWatermarks方法来生成水位线了,二者只用其一。
1.3 水位线的传递
水位线是数据流中插入的一个标记,用来表示事件时间的进展,它会随着数据一起在任务间传递。如果是forward的传输,数据和水位线都是按照本身的顺序依次传输、依次处理的。但在实际的应用中,上下游往往都有多个并行子任务,为了推进事件时间的统一进展,我们要求在上游处理完成水位线、时钟改变后,广播给下游子任务,这样,后续任务就不需要依赖于原始数据中的时间戳,也可以知道当前的事件时间了。同时也有一个问题,在redistributing的传输模式下,一个任务有可能会收到来自不同分区上游子任务的数据,而不同分区的子任务时钟并不同步,所以同一时刻发给下游任务的水位线可能并不相同,也就是说,此时该任务会收到来自多个分区的水位线,这个时候由于水位线的本质是说”当前时间之前的数据,都已经到齐了“。也就是说对于下游来说,只要收到水位线,就表示之前的数据都到了,我不会给你下发比水位线时间更早的数据了,所以在实际处理中,当收到多个水位线时,根据木桶原理,用最小的值作为当前任务的水位线。
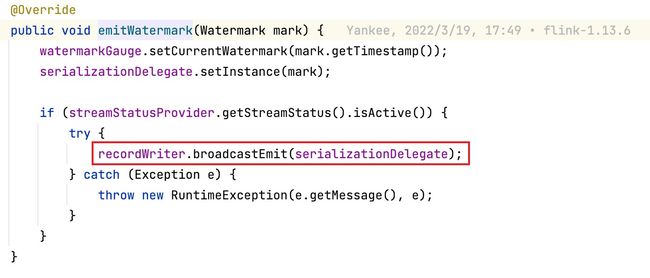
在BoundedOutOfOrdernessWatermarks中周期性调用方法下可以看到通过emitWatermark将水位线向下游传递,通过该方法继续深入查看,就能看到在底层通过调用WatermarkOutput.emitWatermark进而调用Output.emitWatermark将水位线以broadcast的形式继续向下游传递。
2. Flink中的Window窗口
Flink中的窗口大致分为两类,分别是Keyed Windows和Non-Keyed Windows,接下来我们从其简单应用方面看看Window都包含哪些内容,基本的用法等。
2.1 窗口分类
2.1.1 按照使用场景分类
-
Keyed Windows:跟在KeyedStream后使用stream .keyBy(...) <- keyed versus non-keyed windows .window(...) <- required: "assigner" [.trigger(...)] <- optional: "trigger" (else default trigger) [.evictor(...)] <- optional: "evictor" (else no evictor) [.allowedLateness(...)] <- optional: "lateness" (else zero) [.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data) .reduce/aggregate/apply() <- required: "function" [.getSideOutput(...)] <- optional: "output tag" -
Non-Keyed Windows:直接使用WindowAllstream .windowAll(...) <- required: "assigner" [.trigger(...)] <- optional: "trigger" (else default trigger) [.evictor(...)] <- optional: "evictor" (else no evictor) [.allowedLateness(...)] <- optional: "lateness" (else zero) [.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data) .reduce/aggregate/apply() <- required: "function" [.getSideOutput(...)] <- optional: "output tag"
其实在这两种中,Non-Keyed Windows是Keyed Windows的一种特殊实现。在看Flink中的Window都包含哪些之前,我们需要先看看其基本用法:在window中需要一个WindowAssigner将KeyedStream转换成WindowedStream,然后就可以指定窗口的计算逻辑,这块分为全量窗口计算(apply和process)和增量窗口计算(reduce和aggregate),之后就是触发窗口计算的Trigger以及能够修改窗口内元素的Evictor,此时便会通过WindowOperatorBuilder生成一个WindowOperator,窗口的处理逻辑主要就在WindowOperator中。
2.1.2 按照时间语义分类
Window大致分为GlobalWindow和TimeWindow,进一步从时间语义方面看看Flink已经内置的几种WindowAssigner。

-
EventTime:事件时间语义滚动窗口(Tumbling):TumblingEventTimeWindows 滑动窗口(Sliding):SlidingEventTimeWindows 会话窗口(Session):EventTimeSessionWindows -
ProcessTime:处理时间语义滚动窗口(Tumbling):TumblingProcessTimeWindows 滑动窗口(Sliding):SlidingProcessTimeWindows 会话窗口(Session):ProcessTimeSessionWindows
2.1.3 按照窗口类型分类
-
滚动窗口(Tumbling):
EventTime和ProcessTime
-
滑动窗口(Sliding):
EventTime和ProcessTime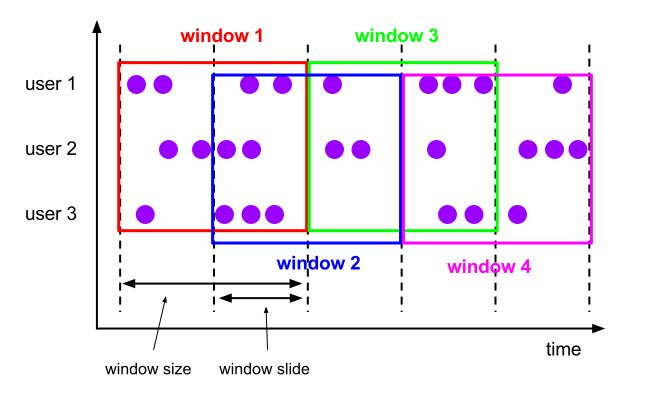
-
会话窗口(Session):
EventTime和ProcessTime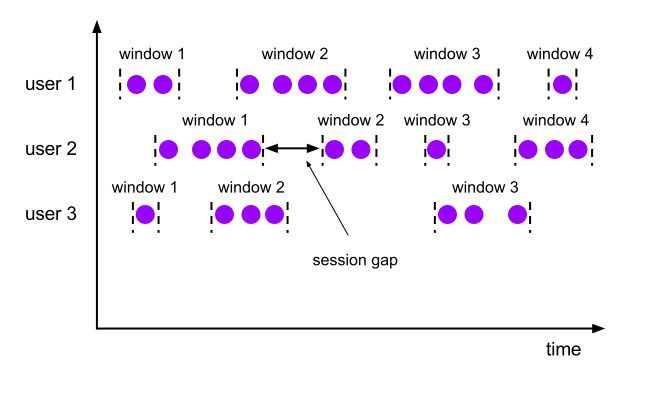
-
计数窗口(Count):分为滚动计数和滑动计数,都是使用
countWindow -
全局窗口(Global):计数窗口
CountWindow是GlobalWindow的一种特殊实现
2.2 窗口分配逻辑
下面我们深入的看看不同的窗口它是如何知道某一条数据是属于那个窗口的,这块我们根据窗口是魂动还是滑动的来分析其窗口分配器WindowAssigner的实现。
2.2.1 滚动窗口分配逻辑(TumblingEventTimeWindows)
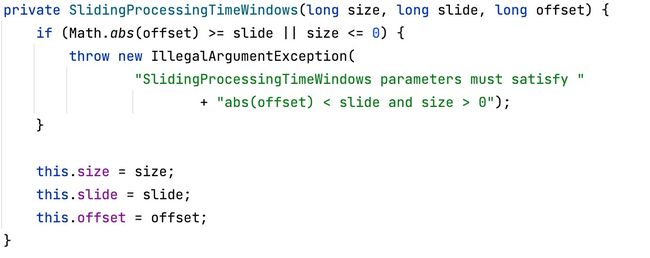
首先会在构造方法中对时间偏移量offset和时间窗口大小size进行判断,如果abs(offset) >= size就会抛出异常。

之后会调用assignWindows方法计算元素所属的窗口集合,最终的计算窗口开始的逻辑是:timestamp - (timestamp - offset + size) % size,对于滚动窗口来说,每个元素只会属于一个窗口,窗口的计算逻辑是:start, start + size,所以最终形成的元素所属的窗口集合也就只有一个。

在TumblingProcessTimeWindows中,也是调用getWindowStartWithOffset方法获取窗口的开始时间,不一样的是,在第一参数位置,EventTime使用的是数据的timestamp,而ProcessTime直接使用now作为参数进行计算。
2.2.2 滑动窗口分配逻辑(SlidingProcessTimeWindows)
和滚动窗口类似,也会在其构造方法中对时间偏移量offset和时间窗口的滑动步长slide进行判断,同时也会对窗口的的大小进行检验,如果abs(offset) >= slide或者size <= 0就会向外抛出异常。
之后和滚动窗口一样,也会调用assignWindows计算元素所属的窗口集合,由于滑动窗口中,一个元素可能属于多个窗口,所以首先计算元素所属最后一个窗口的开始时间,计算逻辑是:timestamp - (timestamp - offset + size) % size,窗口的计算逻辑是:判断结束的条件是当前窗口开始时间start小于当前数据的第一个窗口的开始时间timestamp - size,循环每次窗口时间减去滑动步长start - slide,最终形成的窗口会保存在List集合中。
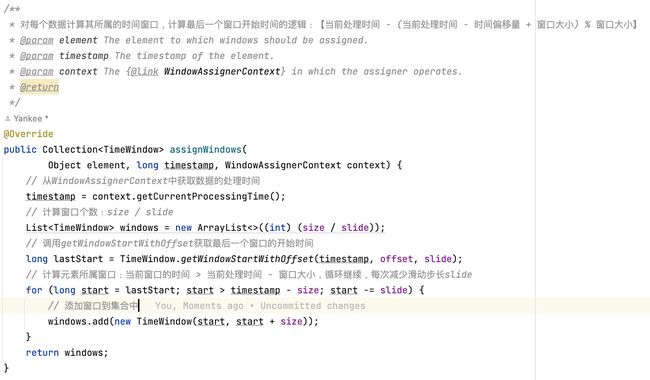
在SlidingEventTimeWindows中,也是调用getWindowStartWithOffset方法获取最后一个窗口的开始时间,不一样的是,在第一位参数位置,EventTime使用的是数据的timestamp,而ProcessTime使用的now,也就是从WindowAssignerContext中获取的currentProcessTime。
从以上两个窗口的计算规则中可以看出,对于EventTime时间语义的处理,当timestamp第一次进入是都是和Long.MIN_VALUE进行对比,也就是说对于EventTime时间语义,时间的最小值不能小于Long.MIN_VALUE,否则就会抛出异常。
2.2.3 会话窗口分配逻辑(EventTimeSessionWindows)
会话窗口的计算逻辑相对来说比较简单,在其构造方法中也会对sessionTimeout进行校验,如果sessionTimeout <= 0则会向外抛出异常。同时其窗口处理逻辑也非常简单,因为对于会话窗口来说某个元素也只能属于一个窗口,所以最终生成的窗口列表也就只有一个值,其窗口的计算逻辑:timestamp, timestamp + sessionTimeout。

2.3 窗口计算函数
有了窗口分配器,我们只是知道了数据是属于哪个窗口,将数据收集起来就是为了对数据进行计算,经过窗口分配器后,数据流被转换成了WindowedStream,这个类型并不是DataStream,并不能直接进行转换,所以还需要调用窗口函数才可以将数据处理计算后转换成DataStream。
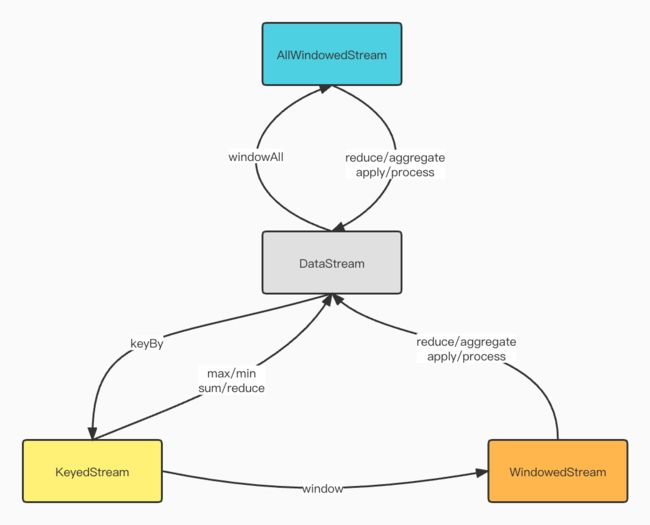
窗口计算函数分为增量和全量函数计算,增量窗口计算函数根据数据来一条计算一条,不会缓存数据,而全量窗口计算函数则会缓存窗口中的函数,相比于增量窗口函数,全量窗口函数包含了窗口的元数据信息等附加信息。所以在平时的使用中,我们可以采用ProcessWindowFunction与ReduceFunction或AggregateFunction结合使用的情况。
2.3.1 增量窗口计算
-
ReduceFunction我们可以按照如下方式使用
ReduceFunction进行增量聚合计算。DataStream<Tuple2<String, Long>> input = ...; input .keyBy(<key selector>) .window(<window assigner>) .reduce(new ReduceFunction<Tuple2<String, Long>>() { public Tuple2<String, Long> reduce(Tuple2<String, Long> v1, Tuple2<String, Long> v2) { return new Tuple2<>(v1.f0, v1.f1 + v2.f1); } }); -
AggregateFunctionReduceFunction是AggregateFunction的一种特殊实现,AggregateFunction包含三个范型,分别是:输入类型IN,累加器类型ACC和输出类型OUT。/** * The accumulator is used to keep a running sum and a count. The {@code getResult} method * computes the average. */ private static class AverageAggregate implements AggregateFunction<Tuple2<String, Long>, Tuple2<Long, Long>, Double> { @Override public Tuple2<Long, Long> createAccumulator() { return new Tuple2<>(0L, 0L); } @Override public Tuple2<Long, Long> add(Tuple2<String, Long> value, Tuple2<Long, Long> accumulator) { return new Tuple2<>(accumulator.f0 + value.f1, accumulator.f1 + 1L); } @Override public Double getResult(Tuple2<Long, Long> accumulator) { return ((double) accumulator.f0) / accumulator.f1; } @Override public Tuple2<Long, Long> merge(Tuple2<Long, Long> a, Tuple2<Long, Long> b) { return new Tuple2<>(a.f0 + b.f0, a.f1 + b.f1); } } DataStream<Tuple2<String, Long>> input = ...; input .keyBy(<key selector>) .window(<window assigner>) .aggregate(new AverageAggregate());
2.3.2 全量窗口计算
全量窗口包含ProcessWindowFunction,相比于增量窗口提供了一个可以访问窗口时间和状态的上下文对象,也能提供比其他窗口更加灵活的操作,但这些都是以牺牲性能为代价的。
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(t -> t.f0)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(new MyProcessWindowFunction());
/* ... */
public class MyProcessWindowFunction
extends ProcessWindowFunction<Tuple2<String, Long>, String, String, TimeWindow> {
@Override
public void process(String key, Context context, Iterable<Tuple2<String, Long>> input, Collector<String> out) {
long count = 0;
for (Tuple2<String, Long> in: input) {
count++;
}
out.collect("Window: " + context.window() + "count: " + count);
}
}
2.3.3 带增量聚合的ProcessWindowFunction
通过将ProcessWindowFunction于ReduceFunction或AggregateFunction相结合的方式,实现增量窗口计算并可以获取到窗口的元数据信息,更加方便灵活的进行窗口计算。
DataStream<SensorReading> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce(new MyReduceFunction(), new MyProcessWindowFunction());
// Function definitions
private static class MyReduceFunction implements ReduceFunction<SensorReading> {
public SensorReading reduce(SensorReading r1, SensorReading r2) {
return r1.value() > r2.value() ? r2 : r1;
}
}
private static class MyProcessWindowFunction
extends ProcessWindowFunction<SensorReading, Tuple2<Long, SensorReading>, String, TimeWindow> {
public void process(String key,
Context context,
Iterable<SensorReading> minReadings,
Collector<Tuple2<Long, SensorReading>> out) {
SensorReading min = minReadings.iterator().next();
out.collect(new Tuple2<Long, SensorReading>(context.window().getStart(), min));
}
}
2.3.4 窗口函数简单案例
public class WindowDemo {
private static final Logger LOG = LoggerFactory.getLogger(WindowDemo.class);
public static void main(String[] args) throws Exception {
// 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度为1
env.setParallelism(1);
// 2.读取端口数据
DataStreamSource<String> socketTextStream = env.socketTextStream("hadoop04", 9999);
// 3.压平并转换为元组
SingleOutputStreamOperator<Tuple2<String, Integer>> wordToOneDS = socketTextStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(new Tuple2<>(word, 1));
}
}
});
// 4.按照单词分组
KeyedStream<Tuple2<String, Integer>, String> keyedStream = wordToOneDS.keyBy(data -> data.f0);
// 5.开窗,最后一个参数offset是窗口的偏移量,向后偏移1秒
// 时间窗口:5的倍数窗口开和关
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowedStream = keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(5), Time.seconds(1)));
// 6.增量聚合计算
// SingleOutputStreamOperator> result = windowedStream.sum(1);
// SingleOutputStreamOperator> result = windowedStream.aggregate(new AggregateFunction, Integer, Integer>() {
// @Override
// public Integer createAccumulator() {
// return 0;
// }
//
// @Override
// public Integer add(Tuple2 value, Integer accumulator) {
// return accumulator + 1;
// }
//
// @Override
// public Integer getResult(Integer accumulator) {
// return accumulator;
// }
//
// @Override
// public Integer merge(Integer a, Integer b) {
// return a + b;
// }
// }, (WindowFunction, String, TimeWindow>) (key, window, input, out) -> {
// // 取出迭代器的数据
// Integer next = input.iterator().next();
// // 输出
// out.collect(new Tuple2<>(new Timestamp(window.getStart()) + ":" + key, next));
// });
// SingleOutputStreamOperator> result = windowedStream.reduce(new ReduceFunction>() {
// @Override
// public Tuple2 reduce(Tuple2 value1, Tuple2 value2) throws Exception {
// return new Tuple2<>(value1.f0, value1.f1 + value2.f1);
// }
// });
// 6.全窗口聚合
// 经常用在计算平均值或者计算前百分之多少的需求之中,也就是说必须要窗口内的全部数据
// 全窗口可以获取窗口的信息
SingleOutputStreamOperator<Tuple2<String, Integer>> result = windowedStream.process(new ProcessWindowFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, String, TimeWindow>() {
@Override
public void process(String key, ProcessWindowFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, String, TimeWindow>.Context context, Iterable<Tuple2<String, Integer>> elements, Collector<Tuple2<String, Integer>> out) throws Exception {
// 窗口的开始时间
LOG.info("窗口开始时间:{}", new Timestamp(context.window().getStart()));
// 取出迭代器的东西
ArrayList<Tuple2<String, Integer>> arrayList = Lists.newArrayList(elements.iterator());
// 输出数据
out.collect(new Tuple2<>(key, arrayList.size()));
// 窗口的结束时间
LOG.info("窗口结束时间:{}", new Timestamp(context.window().getEnd()));
}
});
// 7.打印
result.print();
// 8.执行任务
env.execute("Flink Job: " + WindowDemo.class.getSimpleName());
}
}
2.4 窗口的其他API及生命周期
窗口分类中我们可以看到除了window之外,之后还可以使用Trigger、Evictor、AllowedLateness和SideOutputLateData,分别对应了触发器、移除器、允许迟到数据以及侧输出流。Trigger是指当窗口中的数据或者条件达到了要计算窗口中的数据的时候,则通过触发器触发计算逻辑。Evictor是指在进行窗口计算之前或者之后可以对窗口中的数据进行移除操作。AllowedLateness是指在watermark设置延迟窗口关闭之外还可以通过该API设置一定的延迟策略。SideOutputLateData是指在延迟之后的迟到数据可以写入到侧输出流,需要添加一个OutputTag,最后需要通过getSideOutput来从主流中获取侧数据流的内容。
窗口的生命周期从窗口分配器开始,然后经过触发器触发窗口计算,之后根据Trigger的逻辑销毁窗口,需要注意的是TimeWindow有销毁机制,CountWindow没有销毁机制,是因为CountWindow是基于GlobalWindow实现的,而全局窗口不会清除状态, 所以就不会被销毁。