Day 1: Swin Transformer: Hierarchical Vision Transformer using Shifted Window
第一篇论文是最近大火的 Swin Transformer. Swin 应该是 Shifted Windows 的缩写,也是全文最重要的一个贡献之处。
稍微概括一下,本文的主要几个贡献点有:
- 提出 shifted windows 的概念,在做到仅限于 local self-attention 的同时,将全局也打通了。
- 以往的 Transformer,包括 Vit 和 DeiT,在计算量上都是随着输入图片的尺寸呈二次方增长,因此在高精度输入图片的情况下非常不实用,会占用大量的内存空间。本论文可以使计算量与图片尺寸呈线性增长,提高了实用性。
- 此论文有可能成为计算机视觉处理上的一个转折点,有可能在将来替代CNN,成为新的方向。
Introduction
之前 Transformer在视觉领域没有太多出彩的原因有二。
- 缩放(scale)。不像在自然语言处理中,每一个单词符号可以作为它的一个基本元素,视觉元素会在大小上有非常大的差异,比如目标检测中,需要检测的目标就可大可小,差异明显。
- 和文本句子中的单词相比,图片中的像素有着高得多的像素。这在语义分割中又会带来问题,特别是它的计算复杂度和图片的尺寸是呈成二次方的关系增长。
Core Ideas and Contribution
- 提出了“滑动窗口”方法,在让自注意力集中在不重叠的局部窗口的情况下,允许不同窗口间的信息交流,极大地提升了效率。(Proposed a shifted windowing scheme, brought greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection.)
- 达到了计算复杂度和图片尺寸成线性增长。(It achieved linear computational complexity with respect to image size.)
Methods and Approaches
General Description
Constructs a hierarchical representation by
- 从图中可以看出,我们先从小尺寸的图片模块开始(图中被灰色边框框住的方块),之后在Transformer更深层中,将它们合并到一起,形成一个分层次的结构。这样的话,之后我们可以利用像特征金字塔这样的高级技巧。(start from small-sized patches (in gray), and gradually merging neighboring patches in deeper Transformer layers.)
- 我们通过只在每个不重叠的窗口中(图中红色边框的部分)计算自注意力,达到线性复杂度。linear computational complexity is achieved by computing self-attention locally within non-overlapping windows that partition an image (in red)
- 每个窗口中的图片块(灰色框)数量是固定的,所以计算复杂度是线性的。

Shift Window
- Swin Transformer 最关键的部分就是在连续的自注意力层之间滑动窗口,这些滑动的窗口在前后层之间充当桥梁,提供连接,极大地增强了模型的性能。It bridge the windows of the preceding layer, providing connections among them that significantly enhance modeling power.
- 所有在同一个 window 内的 query 图片块共享一套 key,使在硬件中对内存的读取更加容易且方便。然而以前的方法在普通的硬件上会有时延问题,因为不同的 query 像素有不同的 key。(这一块理解不够,翻译可能不准)Old sliding window methods suffer from low latency on general hardware due to different key sets for different query pixels.
- 实际应用中,像普通的“滑动窗口”方法,在内存的读取上效率会很低。it is difficult for a sliding-window based self-attention layer to have efficient memory access in practice

Detailed Description
Overall Structure
- 首先,将输入图片像ViT中一样,分成不重叠的图片块(每一个红色框)。每个图片块被当成一个 token,RGB三个通道的值concat起来作为这个token的特征。在我们的实现中,patch size 是 4 × 4 4 \times 4 4×4,因此每个patch的特征维度是 4 × 4 × 3 = 48 4 \times 4 \times 3 = 48 4×4×3=48。
splits an input RGB image into non-overlapping patchesby a patch splitting module.Each patch is treated as a "token" and its feature is set as a concatenation of the raw pixel RGB value(need to check the code and see how it is done).- In this paper, the authors used patch size of 4 x 4, and the feature dimension of each patch is 4 x 4 x 3 = 48. (since they concatenated the RGB channnels, why is it x 3 here?)
- 用一个线性嵌入层,将这个feature映射到一个指定大小的维度(命名为C)。a linear embedding layer is applied on this raw-valued feature to project it to an arbitrary dimension (denoted as C)
- 将带有修改后的 self-attention 模块的Transformer应用到这些图片块 token 上,并始终保持token的总数为( H 4 × W 4 \frac{H}{4} \times \frac{W}{4} 4H×4W),且和接下来的线性嵌入层一起被称为“Stage 1”。Transformer blocks with modified self-attention computation (Swin Transformer Blocks) are then applied on these patch tokens, the blocks maintain the number of tokens ( H 4 × W 4 \frac{H}{4} \times \frac{W}{4} 4H×4W), together with the linear embedding are referred as “Stage 1”.
- 为了形成一个层级结构,当层数越来越深时,我们用一个模块融合层,来减少token的数量。To produce a hierarchical representation, the number of takens is reduced by patch merging layers when the network goes deeper.
- 第一个融合层将邻近的 2 × 2 2 \times 2 2×2个patch的全集(即邻近的几个红框圈起来的部分,见上图)拼接(concat)在一起,然后在形成的大小为 4 C 4C 4C的特征上(个人理解:原本每个token的特征维度都分别为C。为了减少token的数量(看上图,即从最下面的 4 × 4 4 \times 4 4×4个token到中间的 2 × 2 2 \times 2 2×2个token),当将邻近的几个patch融合后,新加入的patch的特征维度全部叠加(concat)在原来的patch上,因此每个 token 的特征维度从之前的 C C C上升到现在的 4 C 4C 4C,之后请自行看代码确定理解无误),加上一层线性层。这样使得 token 的数量减少了4倍,输出的维度设为 2 C 2C 2C。再之后,Swin Transformer 开始作用在输出上,并将分辨率保持在 H 8 × W 8 \frac{H}{8} \times \frac{W}{8} 8H×8W。第一个融合模块和特征转换一起被称为“Stage 2”。
- 之后同样的结构重复两次,生成 stage 3 和 stage 4,输出的分辨率分别为( H 16 × W 16 \frac{H}{16} \times \frac{W}{16} 16H×16W) 和( H 32 × W 32 \frac{H}{32} \times \frac {W}{32} 32H×32W)。The first patch merging layer
concatenates the features of each group of 2 × 2 neighboring patches, and applies a linear layer on the 4C-dimensional concatenated features. This reduces the number of tokens by a multiple of 2×2 = 4 (2× downsampling of resolution), and the output dimension is set to 2C. Swin Transformer blocks are applied afterwards for feature transformation, with the resolution kept at H 8 × W 8 \frac{H}{8} \times \frac{W}{8} 8H×8W. This block is called “Stage 2”, and is repeated twice, get Stage 3 and Stage 4 with resolution of ( H 16 × W 16 \frac{H}{16} \times \frac{W}{16} 16H×16W) and ( H 32 × W 32 \frac{H}{32} \times \frac {W}{32} 32H×32W), respectively.
Swin Transformer Block
- 将原始Transformer中的多头注意力模块替换成基于滑动窗口的模块,其它部分保持不变。It is built by
replacing the standard multi-head self attention (MSA) module in a Transformer block by a module based on shifted window, with other layers the same. - 这个 Swin Transformer Block 由一个基于滑动窗口的自注意力模块,后跟一个两层的MLP(两层MLP之间使用GELU非线性层)组成。 It consists of a shifted window based MSA module, followed by a 2-layer MLP with GELU non-linearity in between.
- 每个多头注意力层,和每个MLP层之间,都加上一层LayerNorm,模块后面使用残差连接。A LayerNorm (LN) layer is applied before each MSA module and each MLP, a residual connection is also applied after each module.

Shifted Window based Self-Attention
- Standard Transformer conduct global self-attention, where the relationship between a token and all other tokens are computed, thus leads to a quadratic complexity with respect to the number of tokens, making it unsuitable for many vision problems. (main reason why previous Transformer models were consuming a lot of memory)
Self-attention in non-overlapped windows
- They propose it to compute self-attention within local windows. The windows are arranged to evenly partition the image in a non-overlapping manner. Supposing each window contains M × M M \times M M×M patches, then the computation complexity of a global MSA module and a window based one on an image of h × w h \times w h×w patches are:
Ω ( M S A ) = 4 h w C 2 + 2 ( h w ) 2 C Ω ( W − M S A ) = 4 h w C 2 + 2 M 2 h w C \begin{array}{l}\Omega(\mathrm{MSA})=4 h w C^{2}+2(h w)^{2} C \\\Omega(\mathrm{W}-\mathrm{MSA})=4 h w C^{2}+2 M^{2} h w C\end{array} Ω(MSA)=4hwC2+2(hw)2CΩ(W−MSA)=4hwC2+2M2hwC
- 上式可知,前者与size成二次方,后者成线性关系。where the former is quadratic to patch number h w hw hw, and the latter is linear when M M M is fixed (the authors use 7 by default).
Shifted window partitioning in successive blocks
- the first module uses a regular window partitioning strategy which starts from the top-left pixel, and the 8 × 8 feature map is evenly partitioned into 2 × 2 windows of size 4 × 4 (M = 4). Then, the next module adopts a windowing configuration that is shifted from that of the preceding layer, by displacing the windows by ( ⌊ M 2 ⌋ , ⌊ M 2 ⌋ ) \left(\left\lfloor\frac{M}{2}\right\rfloor,\left\lfloor\frac{M}{2}\right\rfloor\right) (⌊2M⌋,⌊2M⌋) pixels from the regularly partitioned windows.
- Swin Transformer blocks are computed as
z ^ l = W − M S A ( L N ( z l − 1 ) ) + z l − 1 z l = MLP ( L N ( z ^ l ) ) + z ^ l , z ^ l + 1 = S W − M S A ( L N ( z l ) ) + z l z l + 1 = M L P ( LN ( z ^ l + 1 ) ) + z ^ l + 1 \begin{array}{l}\hat{\mathbf{z}}^{l}=\mathrm{W}-\mathrm{MSA}\left(\mathrm{LN}\left(\mathbf{z}^{l-1}\right)\right)+\mathbf{z}^{l-1} \\\mathbf{z}^{l}=\operatorname{MLP}\left(\mathrm{LN}\left(\hat{\mathbf{z}}^{l}\right)\right)+\hat{\mathbf{z}}^{l}, \\\hat{\mathbf{z}}^{l+1}=\mathrm{SW}-\mathrm{MSA}\left(\mathrm{LN}\left(\mathbf{z}^{l}\right)\right)+\mathbf{z}^{l} \\\mathbf{z}^{l+1}=\mathrm{MLP}\left(\operatorname{LN}\left(\hat{\mathbf{z}}^{l+1}\right)\right)+\hat{\mathbf{z}}^{l+1}\end{array} z^l=W−MSA(LN(zl−1))+zl−1zl=MLP(LN(z^l))+z^l,z^l+1=SW−MSA(LN(zl))+zlzl+1=MLP(LN(z^l+1))+z^l+1
- Issue: it will result in more windows, from ⌈ h M ⌉ × ⌈ w M ⌉ \left\lceil\frac{h}{M}\right\rceil \times\left\lceil\frac{w}{M}\right\rceil ⌈Mh⌉×⌈Mw⌉ to ( ⌈ h M ⌉ + 1 ) × ( ⌈ w M ⌉ + 1 ) \left(\left\lceil\frac{h}{M}\right\rceil+1\right) \times \left(\left\lceil\frac{w}{M}\right\rceil+1\right) (⌈Mh⌉+1)×(⌈Mw⌉+1), and some of the windows will be smaller than M × M M \times M M×M. (To make the window size ( M , M M,M M,M) divisible by the feature map size of ( h , w h,w h,w), bottom-right padding is employed on the feature map if needed)
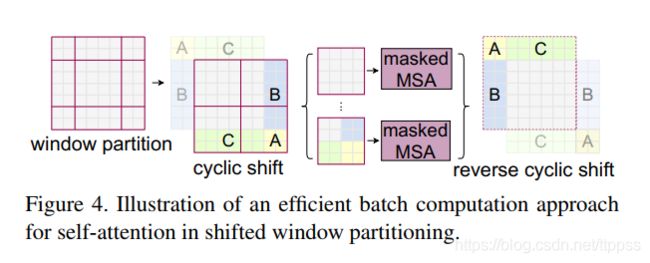
Efficient batch computation for shifted configuration
not sure how it works yet
Found a good explanation here:
https://blog.csdn.net/jackzhang11/article/details/116274498
- cyclic-shifting toward the top-left direction
- After this shift, a batched window may be composed of several sub-windows that are not adjacent in the feature map, so a masking mechanism is employed to limit self-attention computation to within each sub-window
Relative Position Bias
-
When computing self-attention, we include a relative position bias B ∈ R M 2 × M 2 B \in \mathbb{R}^{M^{2} \times M^{2}} B∈RM2×M2 to each head in computing similarity:
Attention ( Q , K , V ) = SoftMax ( Q K T / d + B ) V \operatorname{Attention}(Q, K, V)=\operatorname{SoftMax}\left(Q K^{T} / \sqrt{d}+B\right) V Attention(Q,K,V)=SoftMax(QKT/d+B)V
where Q , K , V ∈ R M 2 × d Q, K, V \in \mathbb{R}^{M^{2} \times d} Q,K,V∈RM2×d are the query, key and value matrices; d d d is the query/key dimension, and M 2 M^{2} M2 is the number of patches in a window. Since the relative position along each axis lies in the range [ − M + 1 , M − 1 ] [-M+1, M-1] [−M+1,M−1], we parameterize a smaller-sized bias matrix B ^ ∈ R ( 2 M − 1 ) × ( 2 M − 1 ) \hat{B} \in \mathbb{R}^{(2 M-1) \times(2 M-1)} B^∈R(2M−1)×(2M−1), and values in B B B are taken from B ^ \hat{B} B^.