大数据实战项目之电商数仓(一)
大数据实战项目之电商数仓(一)
项目介绍
数据仓库概念
数据仓库是为企业所有决策制定过程,提供所有系统数据支持的战略集合。通过对数据仓库中数据的分析,可以帮助企业改进业务流程,控制成本,提高产品质量等。
数据仓库,并不是数据的最终目的地,而是为数据最终目的地做好准备。这些准备包括对数据的清洗,转义,分类,重组,合并,拆分,统计等。
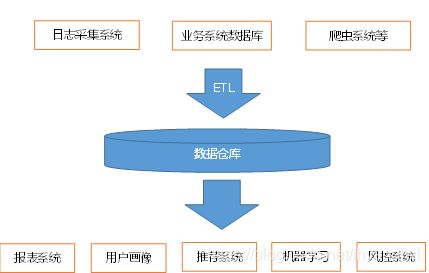
项目需求分析
一、项目需求
1、数据采集平台搭建
2、实现用户行为数据仓库的分层搭建
3、实现业务数据的分成搭建
4、针对数据仓库中的数据进行留存,转化率,GMV(成交总额),复购率,活跃等报表分析
项目框架
数据采集传输:Flume、Kafka、Sqoop
数据储存:MySql、HDFS
数据计算:Hive、Tez
数据查询:Presto、Druid、Kylin
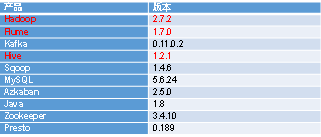
框架版本
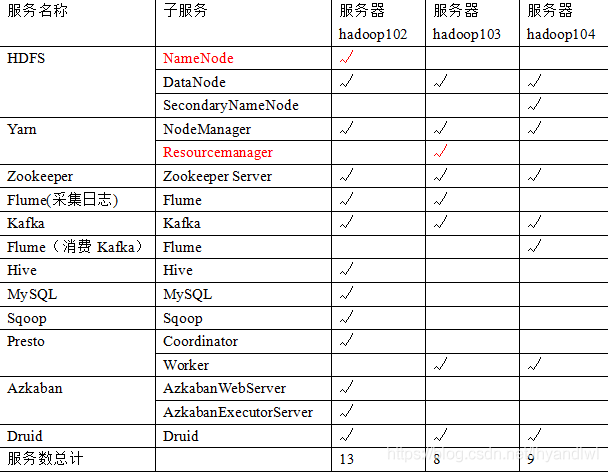
测试集群服务器规划
数据采集模块搭建
Hadoop运行环境搭建
虚拟机环境准备
1、克隆虚拟机
2、修改克隆虚拟机静态ip
vim /etc/sysconfig/network-scripts/ifcfg-eth0
3、修改主机名
vim /etc/sysconfig/network
4、关闭防火墙
5、创建使用者用户
6、配置该用户具有的root权限
vim /etc/sudoers
免密登录配置
(1)生成密钥
ssh-keygen -t rsa
(2) 分发密钥
ssh-copy-id yu101#地址
集群分发脚本编写
#!/bin/bash
#验证参数
if(($#!=1))
then
echo 请输入要分发的文件!
exit;
fi
#获取分发文件的绝对路径
dirpath=$(cd -P `dirname $1`;pwd)
filename=$(basename $1)
echo "您要分发的文件路径是:$dirpath/$filename"
user=$(whoami)
for((i=102;i<=104;i++))
do
echo ----------------------hadoop$i-----------------------
rsync -rvlt $dirpath/$filename $user@hadoop$i:$dirpath
done
集群 执行命令脚本
#!/bin/bash
if(($#==0))
then
echo 请输入要执行的命令!
exit;
fi
echo "要执行的命令是:$*"
#执行命令
for((i=102;i<=104;i++))
do
echo ------------------hadoop$i------------------
ssh hadoop$i $*
done
JDK环境准备
(1)查询是否安装Java软件
rpm -qa | grep java
(2)如果安装的版本低于1.7,卸载该JDK
sudo rpm -e 软件包
(3)查看JDK安装路径:
which java
(4) 配置环境变量
由于集群其他机器是通过ssh登录的直接通过群执行脚本是无法生效生效的需要编辑"/"目录的.bashrc。在文件最后添加
source /etc/profile
Hadoop安装与配置
(1) 解压hadoop安装包
(2) 配置环境变量
(3) 配置core-site.xml
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop102:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/module/hadoop-2.7.2/data/tmpvalue>
property>
(4)配置hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>hadoop104:50090value>
property>
(5)配置yarn-site.xml
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoop103value>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
(6)配置mapred-site.xml
<property>
<name>mapreduce.jobhistory.addressname>
<value>hadoop102:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>hadoop102:19888value>
property>
<property>
<name>yarn.log.server.urlname>
<value>http://hadoop102:19888/jobhistory/logsvalue>
property>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
Hadoop群起脚本与格式化
(1) 群起配置
编辑Hadoop下etc/hadoop/slaves文件配置集群机器名称
(2) 格式化namenode节点
hadoop namenode -format
hadoop一键启动脚本
#!/bin/bash
#hadoop集群一键启动脚本
if(($#!=1))
then
echo 请输入start|stop参数!
exit;
fi
#只允许传入start和stop参数
if [ $1 == start ] || [ $1 == stop ]
then
$1-dfs.sh
$1-yarn.sh
ssh hadoop102 mr-jobhistory-daemon.sh $1 historyserver
else
echo 请输入start|stop参数!
fi
编译Hadoop支持lzo压缩的jar包
(1) 将编译好的jar包放入/opt/module/hadoop-2.7.2/share/hadoop/common/目录
(2) 配置hadoop使用lzo压缩格式
编辑core-site.xml
<property>
<name>io.compression.codecsname>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
value>
property>
<property>
<name>io.compression.codec.lzo.classname>
<value>com.hadoop.compression.lzo.LzoCodecvalue>
property>
测试lzo压缩是否启用
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec /input /output
为lzo文件创建索引
hadoop jar ./share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /output
Hadoop集群性能测试
(1) 测试HDFS写性能
hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB
(2)测试HDFS读性能
hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB
(3)删除测试生成的数据
hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar TestDFSIO -clean
Hadoop参数调优
(1) HDFS参数调优hdfs-site.xml
(1)dfs.namenode.handler.count=20 * log2(Cluster Size),比如集群规模为8台时,此参数设置为60
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。对于大集群或者有大量客户端的集群来说,通常需要增大参数dfs.namenode.handler.count的默认值10。设置该值的一般原则是将其设置为集群大小的自然对数乘以20,即20logN,N为集群大小。
(2) YARN参数调优yarn-site.xml
(1)情景描述:总共7台机器,每天几亿条数据,数据源->Flume->Kafka->HDFS->Hive
面临问题:数据统计主要用HiveSQL,没有数据倾斜,小文件已经做了合并处理,开启的JVM重用,而且IO没有阻塞,内存用了不到50%。但是还是跑的非常慢,而且数据量洪峰过来时,整个集群都会宕掉。基于这种情况有没有优化方案。
(2)解决办法:
内存利用率不够。这个一般是Yarn的2个配置造成的,单个任务可以申请的最大内存大小,和Hadoop单个节点可用内存大小。调节这两个参数能提高系统内存的利用率。
(a)yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。
(b)yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB)。
3)Hadoop宕机
(1)如果MR造成系统宕机。此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认是8192MB)
(2)如果写入文件过量造成NameNode宕机。那么调高Kafka的存储大小,控制从Kafka到HDFS的写入速度。高峰期的时候用Kafka进行缓存,高峰期过去数据同步会自动跟上。
Zookeeper环境搭建
(1) 配置环境变量
(2) 配置conf下zoo.cfg文件
将zoo_sample.cfg文件重命名为zoo.cfg文件
修改数据储存路径
dataDir=/opt/module/zookeeper-3.4.10/zkData
配置zoo.cfg
server.102=hadoop102:2888:3888
server.103=hadoop103:2888:3888
server.104=hadoop104:2888:3888
在/opt/module/zookeeper-3.4.10/zkData目录下创建一个myid的文件
编辑对应的id号
Zookeeper群起脚本
#!/bin/bash
if(($#!=1))
then
echo 请输入start|stop|status!
exit;
fi
if [ $1 = start ] || [ $1 = stop ] || [ $1 = status ]
then
xcall zkServer.sh $1
else
echo 请输入start|stop|status!
fi
Flume环境搭建
(1) 配置环境变量
Kafka环境搭建
(1) 配置环境变量
(2) 配置conf/server.properties
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能
delete.topic.enable=true
#kafka运行日志存放的路径
log.dirs=/opt/module/kafka/datas
#配置连接Zookeeper集群地址
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181
注意 kafka启动不起来或者kafka启动闪退
(1) free -h 查看内存占用比例

(2) 默认kafka启动读取的内存大小为1G,不够的可以增加内存大小
(3) 可以设置kafka-server-start.sh文件中的参数
![]()
flume数据采集通道搭建
flume第一层采集通道
设置flume的配置文件f1.conf
#a1是agent的名称,a1中定义了一个叫r1的source,如果有多个,使用空格间隔
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#组名名.属性名=属性值
a1.sources.r1.type=TAILDIR
a1.sources.r1.filegroups=f1
#读取/tmp/logs/app-yyyy-mm-dd.log ^代表以xxx开头$代表以什么结尾 .代表匹配任意字符
#+代表匹配任意位置
a1.sources.r1.filegroups.f1=/tmp/logs/^app.+.log$
#JSON文件的保存位置
a1.sources.r1.positionFile=/opt/module/flume/test/log_position.json
#定义拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.dw.flume.MyInterceptor$Builder
#定义sink
a1.sinks.k1.type=logger
#定义chanel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
#连接组件 同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
flume第一层通道的启动和关闭脚本f1
#!/bin/bash
if(($#!=1))
then
echo 请输入start或stop!
exit;
fi
cmd=cmd
if [ $1 = start ]
then
cmd="nohup flume-ng agent -c $FLUME_HOME/conf/ -n a1 -f $FLUME_HOME/myagents/f1.conf -Dflume.root.logger=DEBUG,console > /home/atguigu/f1.log 2>&1 &"
elif [ $1 = stop ]
then
cmd="ps -ef | grep f1.conf | grep -v grep | awk -F ' ' '{print \$2}' | xargs kill -9"
else
echo 请输入start或stop!
fi
#在hadoop102和hadoop103开启采集
for i in hadoop102 hadoop103
do
ssh $i $cmd
done
flume第二层采集通道
设置flume的配置文件f1.conf
#配置文件编写
a1.sources = r1 r2
a1.sinks = k1 k2
a1.channels = c1 c2
#配置source
a1.sources.r1.type=org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_start
a1.sources.r1.kafka.consumer.auto.offset.reset=earliest
a1.sources.r1.kafka.consumer.group.id=CG_Start
a1.sources.r2.type=org.apache.flume.source.kafka.KafkaSource
a1.sources.r2.kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r2.kafka.topics=topic_event
a1.sources.r2.kafka.consumer.auto.offset.reset=earliest
a1.sources.r2.kafka.consumer.group.id=CG_Event
#配置channel
a1.channels.c1.type=file
a1.channels.c1.checkpointDir=/opt/module/flume/c1/checkpoint
#启动备用checkpoint
a1.channels.c1.useDualCheckpoints=true
a1.channels.c1.backupCheckpointDir=/opt/module/flume/c1/backupcheckpoint
#event存储的目录
a1.channels.c1.dataDirs=/opt/module/flume/c1/datas
a1.channels.c2.type=file
a1.channels.c2.checkpointDir=/opt/module/flume/c2/checkpoint
a1.channels.c2.useDualCheckpoints=true
a1.channels.c2.backupCheckpointDir=/opt/module/flume/c2/backupcheckpoint
a1.channels.c2.dataDirs=/opt/module/flume/c2/datas
#sink
a1.sinks.k1.type = hdfs
#一旦路径中含有基于时间的转义序列,要求event的header中必须有timestamp=时间戳,如果没有需要将useLocalTimeStamp = true
a1.sinks.k1.hdfs.path = hdfs://hadoop102:9000/origin_data/gmall/log/topic_start/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = logstart-
a1.sinks.k1.hdfs.batchSize = 1000
#文件的滚动
#60秒滚动生成一个新的文件
a1.sinks.k1.hdfs.rollInterval = 30
#设置每个文件到128M时滚动
a1.sinks.k1.hdfs.rollSize = 134217700
#禁用基于event数量的文件滚动策略
a1.sinks.k1.hdfs.rollCount = 0
#指定文件使用LZO压缩格式
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
#a1.sinks.k1.hdfs.round = true
#a1.sinks.k1.hdfs.roundValue = 10
#a1.sinks.k1.hdfs.roundUnit = second
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = hdfs://hadoop102:9000/origin_data/gmall/log/topic_event/%Y-%m-%d
a1.sinks.k2.hdfs.filePrefix = logevent-
a1.sinks.k2.hdfs.batchSize = 1000
a1.sinks.k2.hdfs.rollInterval = 30
a1.sinks.k2.hdfs.rollSize = 134217700
a1.sinks.k2.hdfs.rollCount = 0
a1.sinks.k2.hdfs.fileType = CompressedStream
a1.sinks.k2.hdfs.codeC = lzop
#a1.sinks.k2.hdfs.round = true
#a1.sinks.k2.hdfs.roundValue = 10
#a1.sinks.k2.hdfs.roundUnit = second
#连接组件
a1.sources.r1.channels=c1
a1.sources.r2.channels=c2
a1.sinks.k1.channel=c1
a1.sinks.k2.channel=c2
flume写入hdfs采用lzo格式需要先向core-site.xml添加相关压缩格式的配置
io.compression.codecs
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
io.compression.codec.lzo.class
com.hadoop.compression.lzo.LzoCodec
flume第二层通道的启动和关闭脚本f2
#!/bin/bash
if(($#!=1))
then
echo 请输入start或stop!
exit;
fi
if [ $1 = start ]
then
ssh hadoop104 "nohup flume-ng agent -c $FLUME_HOME/conf/ -n a1 -f $FLUME_HOME/myagents/f2.conf -Dflume.root.logger=INFO,console > /home/atguigu/f2.log 2>&1 &"
elif [ $1 = stop ]
then
ssh hadoop104 "ps -ef | grep f2.conf | grep -v grep | awk -F ' ' '{print \$2}' | xargs kill -9"
else
echo 请输入start或stop!
fi
数据采集集群一键启动脚本
#!/bin/bash
if(($#!=1))
then
echo 请输入start或stop!
exits;
fi
#编写函数,这个函数的功能为返回集群中启动成功的broker的数量
function countKafkaBrokers()
{
count=0
for((i=102;i<=104;i++))
do
result=$(ssh hadoop$i "jps | grep Kafka | wc -l")
count=$[$result+$count]
done
#函数可以定义返回值,如果定义,返回函数最后一行命令的状态(返回0,代表成功,非0,即为异常)
return $count
}
#启动
if [ $1 = start ]
then
zk start
hd start
kf start
#保证kafka集群已经启动,才能启动f1,f2采集通道
while [ 1 ]
do
countKafkaBrokers
if(($?==3))
then
break
fi
sleep 2s
done
f1 start
f2 start
#查看已经启动进程
xcall jps
elif [ $1 = stop ]
then
f1 stop
f2 stop
kf stop
#在kafka没有停止完成之前,不能停止zk集群
while [ 1 ]
do
countKafkaBrokers
if(($?==0))
then
break
fi
sleep 2s
done
zk stop
hd stop
#查看还剩那些进程
xcall jps
else
echo echo 请输入start或stop!
fi
HDFS-HA配置
配置nameservice,编写hdfs-sitx.xml
vim hdfs-site.xml
<property>
<name>dfs.nameservicesname>
<value>myclustervalue>
property>
<property>
<name>dfs.ha.namenodes.myclustername>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1name>
<value>hadoop101:8020value>
property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1name>
<value>hadoop101:50070value>
property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2name>
<value>hadoop102:50070value>
property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2name>
<value>hadoop102:8020value>
property>
<property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://hadoop101:8485;hadoop102:8485;hadoop103:8485/myclustervalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/opt/module/hadoop-2.7.2/data/datavalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>sshfencevalue>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/home/atguigu/.ssh/id_rsavalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.myclustername>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>hadoop103:50090value>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
(2)编写core-site.xml
<property>
<name>fs.defaultFSname>
<value>hdfs://myclustervalue>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/module/hadoop-2.7.2/data/tmpvalue>
property>
<property>
<name>ha.zookeeper.quorumname> <value>hadoop101:2181,hadoop102:2181,hadoop103:2181value>
property>
启动journalnode
xcall hadoop-daemon.sh start journalnode
在nn1上对namenode进行格式化
hadoop namenode -format
hdfs namenode -bootstrapStandby
在nn2上对namenode信息进行拷贝
stop-all.sh
hdfs zkfc -formatZK
start-dfs.sh
ResouceManager-HA配置
(1)编写yarn-site.xml
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>cluster1value>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>hadoop101value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>hadoop102value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1name>
<value>hadoop101:8088value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2name>
<value>hadoop102:8088value>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>hadoop101:2181,hadoop102:2181,hadoop103:2181value>
property>
<property>
<name>yarn.resourcemanager.recovery.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.store.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStorevalue>
property>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>