ECCV2022 | 生成对抗网络GAN论文汇总(图像转换-图像编辑-图像修复-少样本生成-3D等)...
图像转换/图像可控编辑
视频生成
少样本生成
图像外修复/结合transformer
GAN改进
新数据集
图像增强
3D
图像来源归属分析
一、图像转换/图像可控编辑
1、VecGAN: Image-to-Image Translation with Interpretable Latent Directions
提出VecGAN,图像到图像的转换方法,用于具有可解释的潜在方向的人脸属性编辑。人脸属性编辑任务面临着强度可控的精确属性编辑和保留图像其它非目标属性的挑战。为此,通过潜在空间分解来设计属性编辑,并且对于每个属性,学习一个与其他属性正交的线性方向。另一个组件是变化的可控强度,一个标量值去表示,这个标量可以通过投影从参考图像中采样或编码。
受到预训练 GAN 的潜在空间分解工作的启发,虽然这些模型无法进行端到端训练并且难以精确地编辑编码图像,但 VecGAN 是针对图像转换任务进行端到端训练,且成功编辑单个属性,同时保留了其他属性。

2、Dynamic Sparse Transformer for Exemplar-Guided Image Generation
示例引导的图像生成任务,一个关键挑战在于在输入图像和引导图像之间建立细粒度的对应关系。先前的方法,尽管取得了可喜的结果,但依赖于估计密集注意力来计算每点匹配,由于二次内存成本,这仅限于粗略的尺度,或者固定对应的数量以实现线性复杂性,这缺乏灵活性。
本文提出一种基于动态稀疏注意力的 Transformer 模型,称为 Dynamic Sparse Transformer (DynaST),以实现具有良好效率的精细匹配。方法核心是一个新的动态注意单元,致力于覆盖一个位置应该关注的最佳tokens数量的变化。具体来说,DynaST 利用了 Transformer 结构的多层特性,并以级联方式执行动态注意方案,以优化匹配结果并合成视觉上令人愉悦的输出。
此外,为 DynaST 引入了统一的训练目标,使其成为适用于有监督和无监督场景的通用基于参考的图像转换框架。在三个应用任务(姿势引导的人物图像生成、基于边缘的人脸合成和不失真的图像风格转移)上的广泛实验表明,DynaST 在局部细节方面取得了卓越的性能,在降低计算成本的同时超越了现有技术。
代码在:https://github.com/Huage001/DynaST

3、Context-Consistent Semantic Image Editing with Style-Preserved Modulation
语义图像编辑利用局部语义标签图、在编辑区域中生成所需的内容。比如有些工作是借用 SPADE 块来实现语义图像编辑。但是,由于编辑区域和周围像素之间的差异,不能产生满意结果。本文认为,这是因为 SPADE 仅使用与图像无关的局部语义布局,但忽略了已知像素中包含的图像特定风格。
为了解决这个问题,提出一种保留风格的调制(SPM),包括两个过程:第一个结合了上下文风格和语义布局,然后生成两个融合的调制参数。第二个采用融合参数来调制特征图。通过使用这两种调制,SPM 可以注入给定的语义布局,同时保留图像特定的上下文风格。此外,设计了一种渐进式架构,用于以粗到细的方式生成编辑内容。所提出的方法可以获得上下文一致的结果,并明显缓解生成区域与已知像素之间的不自然边界。
https://github.com/WuyangLuo/SPMPGAN

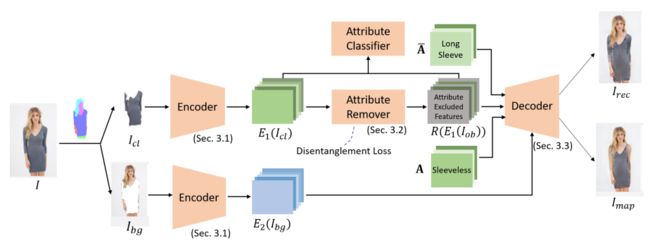
4、Supervised Attribute Information Removal and Reconstruction for Image Manipulation
属性操作的目标是控制给定图像中的指定属性。先前的工作通过学习每个属性的解耦表示来解决这个问题,使其能够将编码的源属性操纵到目标属性。然而,编码属性通常与相关的图像内容相关联。因此,源属性信息通常会隐藏在解耦的特征中,从而导致不需要的图像编辑效果。
本文提出一种属性信息删除和重建 (Attribute Information Removal and Reconstruction ,AIRR) 网络,该网络通过学习如何完全删除属性信息、创建属性排除特征,然后学习在重建图像中直接注入所需的属性来防止此类信息隐藏。在具有各种属性的四个不同数据集上评估方法,包括 DeepFashion Synthesis、DeepFashion Fine-grained Attribute、CelebA 和 CelebA-HQ,其中模型将属性操作准确度和 top-k 检索率平均提高了 10%。
https://github.com/NannanLi999/AIRR
二、视频生成
5、Fast-Vid2Vid: Spatial-Temporal Compression for Video-to-Video Synthesis
视频到视频合成 (Vid2Vid) ,对一系列语义图,生成照片般逼真的视频。存在计算成本高和推理延迟长的问题,这在很大程度上取决于两个基本因素:1)网络架构参数,2)顺序数据流。最近,基于图像的生成模型的参数已通过更有效的网络架构得到显著压缩。然而,现有的方法主要集中在精简网络架构,而忽略了顺序数据流的大小。此外,由于缺乏时间相干性,基于图像的压缩不足以压缩视频任务。
本文提出一个时空压缩框架 Fast-Vid2Vid,它专注于生成模型的数据方面。它首次尝试在时间维度上减少计算资源并加速推理。具体来说,在空间上压缩输入数据流并减少时间冗余。在提出的时空知识蒸馏之后,模型可以使用低分辨率数据流合成关键帧。最后,Fast-Vid2Vid 通过具有轻微延迟的运动补偿对中间帧进行插值。在标准基准测试中,Fast-Vid2Vid 实现了大约 20 FPS 的实时性能,并在单个 V100 GPU 上节省了大约 8 倍的计算成本。
https://github.com/fast-vid2vid/fast-vid2vid

三、少样本生成
6、Adaptive Feature Interpolation for Low-Shot Image Generation
生成模型的训练,尤其是生成对抗网络的训练,在少数据情况下尤显困难。为了缓解这个问题,提出了一种新的隐式数据增强方法,该方法有助于稳定训练并在不需要标签信息的情况下合成高质量的样本。
具体来说,将判别器视为真实数据流形的度量嵌入,它提供了真实数据点之间的适当距离。然后,利用特征空间中的信息来开发一种完全无监督和数据驱动的增强方法。对小样本生成任务的实验表明,所提出的方法显著改善了具有数百个训练样本的强基线的结果。
7、Frequency-aware GAN for High-Fidelity Few-shot Image Generation
https://github.com/kobeshegu/ECCV2022_WaveGAN
现有的少样本图像生成方法,通常在图像或特征级别上采用基于融合的策略来生成新图像。然而,以前的方法难以合成具有精细细节的高频信号,从而降低了合成质量。
为了解决这个问题,提出 WaveGAN,一种用于少样本图像生成的、频率感知的模型。具体来说,将编码特征分解为多个频率分量,并执行低频跳跃连接以保留轮廓和结构信息。然后,通过使用高频跳跃连接来缓解生成器合成精细细节的困难,从而为生成器提供信息丰富的频率信息。此外,在生成的真实图像上使用频率 L 1-loss 来进一步阻止频率信息丢失。大量实验证明了方法在三个数据集上的有效性和先进性。在 Flower、Animal Faces 和 VGGFace 上分别实现了 FID 42.17、LPIPS 0.3868、FID 30.35、LPIPS 0.5076 和 FID 4.96、LPIPS 0.3822 的最好指标。

8、FakeCLR: Exploring Contrastive Learning for Solving Latent Discontinuity in Data-Efficient GANs
https://github.com/iceli1007/FakeCLR
数据高效 GAN (Data-Efficient GANs,DE-GAN) 旨在使用有限的训练数据来学习生成模型,但在生成高质量样本方面遇到了一些挑战。由于数据增强策略在很大程度上缓解了训练的不稳定性,如何进一步提高 DE-GANs 的生成性能成为一个热点。最近,对比学习已经显示出提高 DE-GAN 合成质量的巨大潜力,但相关原理尚未得到很好的探索。
本文重新审视和比较了 DE-GAN 中的不同对比学习策略,并确定(i)当前生成性能的瓶颈是潜在空间的不连续性;(ii) 与其他对比学习策略相比,实例扰动致力于潜在空间连续性,这为 DE-GAN 带来了重大改进。基于这些观察,提出了 FakeCLR,它只对扰动的假样本应用对比学习,并设计了三种相关的训练技术:噪声相关的潜在增强、多样性感知队列和队列的遗忘因子。实验结果表明了小样本生成和有限数据生成的最新技术。在多个数据集上,与现有的 DE-GAN 相比,FakeCLR 获得了超过 15% 的 FID 改进。

四、图像外修复
9、Outpainting by Queries
https://github.com/Kaiseem/QueryOTR
使用基于CNN的方法很好地研究了图像外修复(outpainting),然而,CNN 依赖于固有的归纳偏差来实现有效的样本学习,这可能会降低性能上限。本文依据 Transformer 架构中具有最小归纳偏差的灵活自注意机制的特点,将广义图像外修复问题重新定义为一个patch方式的序列到序列自回归问题,从而实现基于查询的图像外修复。
具体来说,提出了一种新的基于混合视觉Transformer 的编码器-解码器,名为 Query Outpainting TRansformer (QueryOTR),用于在给定图像周围全面推断视觉上下文。
Patch-wise 模式的全局建模能力能够从注意力机制的查询角度推断图像。一种新的查询扩展模块(QEM)根据编码器的输出整合来自预测查询的信息,从而加速纯Transformer 的收敛,即使数据集相对较小的情况下。为了进一步增强每个patch之间的连通性,所提出的patch平滑模块(PSM)重新分配和平均重叠区域,从而提供无缝预测图像。通过实验证明, QueryOTR 可以针对最先进的图像外修复方法平滑而逼真地生成视觉上吸引人的结果。

五、GAN改进
10、Generator Knows What Discriminator Should Learn in Unconditional GANs
最近的条件图像生成方法受益于密集监督“”dense supervision”,例如分割标签图,以实现高保真度。然而,很少有人探索使用密集监督来生成无条件的图像。
在这里,探讨了密集监督在无条件生成中的功效,并发现生成器特征图可以替代成本高昂的语义标签图。提出一种新的生成器引导判别器正则化(GGDR),其中生成器特征图监督判别器在无条件生成中具有丰富的语义表示。具体来说,采用 U-Net 架构作为判别器,该架构经过训练以预测给定假图像作为输入的生成器特征图。
在多个数据集上进行的大量实验表明,GGDR 在定量和定性方面不断提高基线方法的性能。
代码:https://github.com/naver-ai/GGDR

六、新数据集
11、CelebV-HQ: A Large-Scale Video Facial Attributes Dataset
大规模数据集在最近人脸生成/编辑的成功中发挥了不可或缺的作用,并极大地促进了新兴研究领域的进步。然而,学术界仍然缺乏具有多样化人脸属性标签的视频数据集,这对于人脸相关视频的研究至关重要。
这项工作提出一个具有丰富面部属性标签的大规模、高质量和多样化的视频数据集,称为高质量名人视频数据集 (CelebV-HQ)。CelebV-HQ 包含 35666 个视频片段,分辨率至少为 512×512,涉及 15653 个身份。所有剪辑都手动标记了 83 个面部属性,包括外观、动作和情感。从年龄、种族、亮度稳定性、运动平滑度、头部姿势多样性和数据质量等方面进行综合分析,以证明 CelebV-HQ 的多样性和时间连贯性。此外,它的多功能性和潜力在两个代表性任务上得到验证,即无条件视频生成和视频人脸属性编辑。此外,展望了CelebV-HQ的未来潜力,以及它将给相关研究方向带来的新机遇和挑战。
数据、代码和模型公开:https://github.com/CelebV-HQ/CelebV-HQ

七、图像增强
12、Unsupervised Night Image Enhancement:When Layer Decomposition Meets Light-Effects Suppression
夜间图像不仅受到光线不足的影响,而且还受到光线分布不均匀的影响。大多数现有的夜间能见度增强方法主要集中在增强弱光区域。这不可避免地会导致明亮区域的过度增强和饱和。为了解决这个问题,我们需要抑制亮区的光效应,同时提高暗区的强度。
本文引入了一种集成了层分解网络和光效抑制网络的无监督方法。给定单个夜间图像作为输入,分解网络在无监督层特定的先验损失的指导下学习分解阴影、反射和光效层。光效抑制网络进一步抑制了光效,同时增强了黑暗区域的照明。这个光效抑制网络利用估计的光效层作为指导来关注光效区域。为了恢复背景细节并减少幻觉/伪影,提出了结构和高频一致性损失。
对真实图像的定量和定性评估表明,方法在抑制夜光效应和提高暗区强度方面优于最先进的方法
https://github.com/jinyeying/night-enhancement

八、3D
13、Generative Multiplane Images: Making a 2D GAN 3D-Aware
如何让现有的 2D GAN变成3D感知的?
本文尽可能少地修改经典 GAN,即 StyleGANv2,发现只有两个修改是绝对必要的:1)一个多平面图像风格生成器分支,它产生一组以深度为条件的阿尔法图;2)一个姿势条件判别器。
将生成的输出称为“生成多平面图像”(generative multiplane image,GMPI),并强调其渲染不仅质量高,而且保证视图一致。重要的是,alpha 映射的数量可以动态调整,并且可以在训练和推理之间有所不同,从而减轻内存问题并在不到半天的时间内以 1024 分辨率快速训练。
https://github.com/apple/ml-gmpi
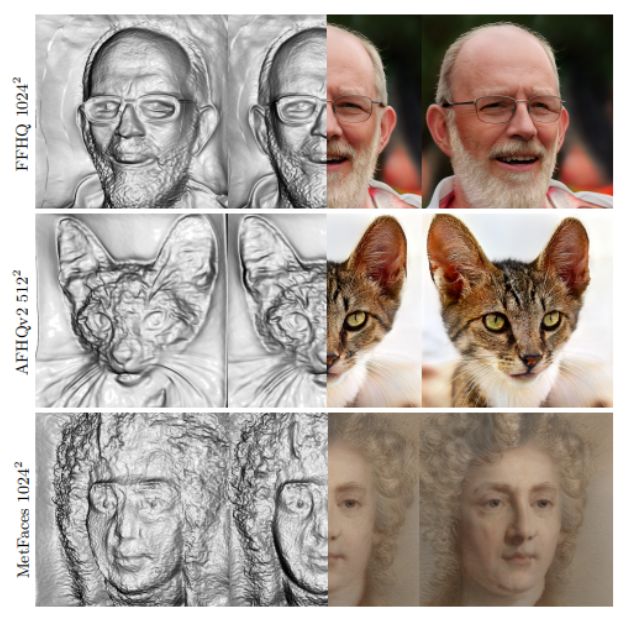
14、Monocular 3D Object Reconstruction with GAN Inversion
从单目图像中恢复带纹理的 3D mesh 非常具有挑战性,这项工作提出了 Mesh Inversion,利用3D 纹理mesh 进行预训练 3D GAN 的先验来改进重建。
具体而言,通过在 3D GAN 中搜索与目标最相似的潜在空间来实现重建。由于预训练的 GAN 在几何和纹理方面蕴含了丰富的 3D 语义,因此在 GAN 流形内进行搜索自然地规范了重建的真实性和保真度。重要的是,这种正则化直接应用于 3D 空间,为 2D 空间中未观察到的网格部分提供关键指导。实验表明,框架在观察到的和未观察到的部分获得了具有一致几何和纹理的忠实 3D 重建。此外,它可以很好地推广到不太常见的网格,例如可变形物体的扩展关节。
代码在:https://github.com/junzhezhang/mesh-inversion

九、图像来源归属分析
15、RepMix: Representation Mixing for Robust Attribution of Synthesized Images
生成对抗网络 (GAN) 的快速发展为image attribution提出了新的挑战;检测图像是否是合成的,如果是,则确定创建它的 GAN 架构。本文为这项任务提供了一种解决方案,能够 1)匹配与其语义内容不变的图像;2) 对在线重新共享图像时常见的转换(质量、分辨率、形状等的变化)具有鲁棒性。
收集了一个具有挑战性的基准 Attribution88,以实现可靠且实用的image attribution。然后,提出了RepMix,基于表示混合和新损失的 GAN 指纹识别技术。验证了它追踪 GAN 图像的来源的能力,它不受图像语义内容的影响,并且对扰动也具有鲁棒性。方法在语义泛化和鲁棒性方面比现有的 GAN 指纹识别工作有明显改进。
数据和代码:https://github.com/TuBui/image_attribution

猜您喜欢:
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!
一顿午饭外卖,成为CV视觉前沿弄潮儿!
CVPR 2022 | 25+方向、最新50篇GAN论文
ICCV 2021 | 35个主题GAN论文汇总
超110篇!CVPR 2021最全GAN论文梳理
超100篇!CVPR 2020最全GAN论文梳理
拆解组新的GAN:解耦表征MixNMatch
StarGAN第2版:多域多样性图像生成
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 |《计算机视觉中的数学方法》分享
《基于深度学习的表面缺陷检测方法综述》
《零样本图像分类综述: 十年进展》
《基于深度神经网络的少样本学习综述》
