第七章 树与森林
树与森林
7.1树的概念与表示
7.1.1树的定义及相关术语
1.树的定义
树(Tree)是n(n≥0)个有限数据元素的集合。当n=0时,称这棵树为空树。在一棵非树T中:
⑴有一个特殊的数据元素称为树的根结点,根结点没有前驱结点。
⑵若n>1,除根结点之外的其余数据元素被分成m(m>0)个互不相交的集合T1,T2,…,Tm,其中每一个集合Ti(1≤i≤m)本身又是一棵树。树T1,T2,…,Tm称为这个根结点的子树。
可以看出,在树的定义中用了递归概念,即用树来定义树。因此,树结构的算法类同于二叉树结构的算法,也可以使用递归方法。
树的定义还可形式化的描述为二元组的形式:
T=(D,R)
其中,D为树T中结点的集合,R为树中结点之间关系的集合。
当树为空树时,D=Φ;当树T不为空树时有:
D={Root}∪DF其中,Root为树T的根结点,DF为树T的根Root的子树集合。DF可由下式表示:
DF=D1∪D2∪…∪Dm且Di∩Dj=Φ
(i≠j,1≤i≤m,1≤j≤m)
当树T中结点个数n≤1时,R=Φ;当树T中结点个数n>1时有:
R={
其中,Root为树T的根结点,ri是树T的根结点Root的子树Ti的根结点。
下图是一棵具有9个结点的树,即T={A,B,C,…,H,I},结点A为树T的根结点,除根结点A之外的其余结点分为两个不相交的集合:
T1={B,D,E,F,H,I}和T2={C,G}
T1和T2构成了结点A的两棵子树,T1和T2本身也分别是一棵树。
从树的定义和前面示例可以看出,树具有下面两个特点:
⑴树的根结点没有前驱结点,除根结点之外的所有结点有且只有一个前驱结点。
⑵树中所有结点可以有零个或多个后继结点。
下图所示的是不是树结构?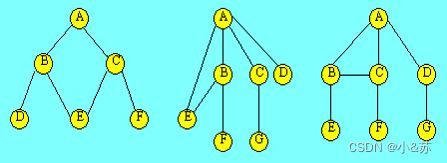
2.相关术语
在二叉树中介绍的有关概念在树中仍然适用。除此之外,再介绍两个关于树的术语。
⑴有序树和无序树:如果一棵树中结点的各子树丛左到右是有次序的,即若交换了某结点各子树的相对位置,则构成不同的树,称这棵树为有序树;反之,则称为无序树。
⑵森林:零棵或有限棵不相交的树的集合称为森林。自然界中树和森林是不同的概念,但在数据结构中,树和森林只有很小的差别。任何一棵树,删去根结点就变成了森林。
7.1.2树的表示
树的表示方法有四种,各用于不同的目的。
1.直观表示法
树的直观表示法就是以倒着的分支树的形式表示,下图就是数据结构中最常用的树的描述方法。其特点就是对树的逻辑结构的描述非常直观。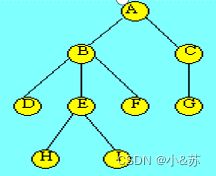
2.嵌套集合表示法
所谓嵌套集合是指一些集合的集体,对于其中任何两个集合,或者不相交,或者一个包含另一个。
用嵌套集合的形式表示树,就是将根结点视为一个大的集合,其若干棵子树构成这个大集合中若干个互不相交的子集,如此嵌套下去,即构成一棵树的嵌套集合表示。下图就是一棵树的嵌套集合表示。
3.凹入表示法
树的凹入表示法如图所示。
4.广义表表示法
树用广义表表示,就是将根作为由子树森林组成的表的名字写在表的左边,这样依次将树表示出来。
(A(B(D,E(H,I),F),C(G)))
7.2树的基本操作与存储
7.2.1树的基本操作
树的基本操作通常有以下几种:
⑴Initiate(t)初始化一棵空树t。
⑵Root(x)求结点x所在树的根结点。
⑶Parent(t,x)求树t中结点x的双亲结点。
⑷Child(t,x,i)求树t中结点x的第i个孩子结点。
⑸RightSibling(t,x)求树t中结点x的第一个右边兄弟结点。
⑹Insert(t,x,i,s)把以s为根结点的树插入到树t中作为结点x的第i棵子树。
⑺Delete(t,x,i)在树t中删除结点x的第i棵子树。
⑻Tranverse(t)是树的遍历操作,即按某种方式访问树t中的每个结点,且使每个结点只被访问一次。
7.2.2 树的存储结构
1.双亲表示法
树中的每个结点都有唯一的一个双亲结点。根据这一特性,可用一组连续的存储空间(一维数组)存储树中的各个结点,数组中的一个元素表示树中的一个结点。
数组元素为结构体类型,其中包括结点本身的信息以及结点的双亲结点在数组中的序号,树的这种存储方法称为双亲表示法。其存储表示可描述为:
#define MAXNODE <树中结点的最大个数>
typedef struct {
elemtype data;
int parent;
}NodeType;
NodeType t[MAXNODE];
下图所示为树的双亲表示。图中用parent域的值为-1表示该结点无双亲结点,即该结点是一个根结点。
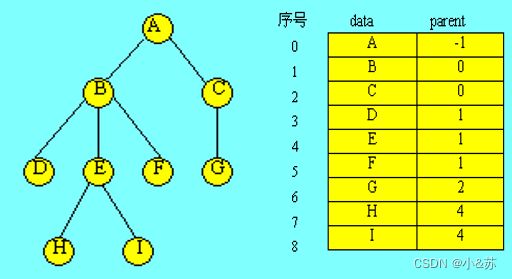
优点:树的双亲表示法对于实现Parent(t,x)操作和Root(x)操作很方便。
缺点:
①若求某结点的孩子结点,即实现Child(t,x,i)操作时,则需查询整个数组。
②这种存储方式不能够反映各兄弟结点之间的关系,所以实现RightSibling(t,x)操作也比较困难。
解决办法:在实际中,如果需要实现这些操作,可在结点结构中增设存放第一个孩子的域和存放第一个右兄弟的域,就能较方便地实现上述操作了。
2.孩子表示法
⑴多重链表法
由于树中每个结点都有零个或多个孩子结点,因此,可以令每个结点包括一个结点信息域和多个指针域,每个指针域指向该结点的一个孩子结点,通过各个指针域值反映出树中各结点之间的逻辑关系。在这种表示法中,树中每个结点有多个指针域,形成了多条链表,所以这种方法又常称为多重链表法。
在一棵树中,各结点的度数各异,因此结点的指针域个数的设置有两种方法:
①每个结点指针域的个数等于该结点的度数;(变长)
②每个结点指针域的个数等于树的度数。(定长)
⑵孩子链表表示法
孩子链表法是将树按如下图所示的形式存储。其主体是一个与结点个数一样大小的一维数组,数组的每一个元素有两个域组成,一个域用来存放结点信息,另一个用来存放指针,该指针指向由该结点孩子组成的单链表的首位置。单链表的结构也由两个域组成,一个存放孩子结点在一维数组中的序号,另一个是指针域,指向下一个孩子。
在孩子表示法中查找双亲比较困难,查找孩子却十分方便,故适用于对孩子操作多的应用。这种存储表示可描述为:
#define MAXNODE <树中结点的最大个数>
typedef struct ChildNode{
int childcode;
struct ChildNode *nextchild;
};
typedef struct {
elemtype data;
struct ChildNode *firstchild;
}NodeType;
NodeType t[MAXNODE];
3.双亲孩子表示法
双亲表示法是将双亲表示法和孩子表示法相结合的结果。其仍将各结点的孩子结点分别组成单链表,同时用一维数组顺序存储树中的各结点,数组元素除了包括结点本身的信息和该结点的孩子结点链表的头指针之外,还增设一个域,存储该结点双亲结点在数组中的序号。下图所示为采用这种方法的存储示意图。 #### 4.孩子兄弟表示法
#### 4.孩子兄弟表示法
这是一种常用的存储结构。其方法是这样的:在树中,每个结点除其信息域外,再增加两个分别指向该结点的第一个孩子结点和下一个兄弟结点的指针。
在这种存储结构下,树中结点的存储表示可描述为:
typedef struct TreeNode {
elemtype data;
struct TreeNode *lchild;
struct TreeNode *nextsibling;
}NodeType, *CSTree;
下图给出采用孩子兄弟表示法时的存储示意图。
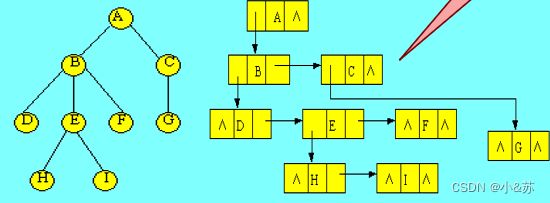
从树的孩子兄弟表示法可以看到,如果设定一定规则,就可用二叉树结构表示树和森林,这样,对树的操作实现就可以借助二叉树存储,利用二叉树上的操作来实现。
7.3树、森林与二叉树的转换
7.3.1树转换为二叉树
将一棵树转换为二叉树的方法是:
⑴树中所有相邻兄弟之间加一条连线。
⑵对树中的每个结点,只保留它与第一个孩子结点之间的连线,删去它与其它孩子结点之间的连线。
⑶以树的根结点为轴心,将整棵树顺时针转动一定的角度,使之结构层次分明。
由上面的转换可以看出,在二叉树中,左分支上的各结点在原来的树中是父子关系,而右分支上的各结点在原来的树中是兄弟关系。由于树的根结点没有兄弟,所以变换后的二叉树的根结点的右孩子必为空。
例 转换为二叉树的转换过程示意图。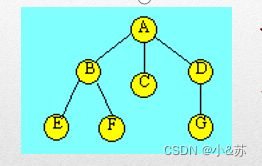
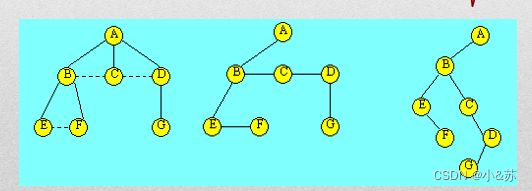
!!兄弟变父子
7.3.2森林转换为二叉树
由森林的概念可知,森林是若干棵树的集合,只要将森林中各棵树的根视为兄弟,森林同样可以用二叉树表示。
森林转换为二叉树的方法如下:
⑴将森林中的每棵树转换成相应的二叉树。
⑵第一棵二叉树不动,从第二棵二叉树开始,依次把后一棵二叉树的根结点作为前一棵二叉树根结点的右孩子,当所有二叉树连起来后,此时所得到的二叉树就是由森林转换得到的二叉树。
下图给出森林及其转换为二叉树的过程。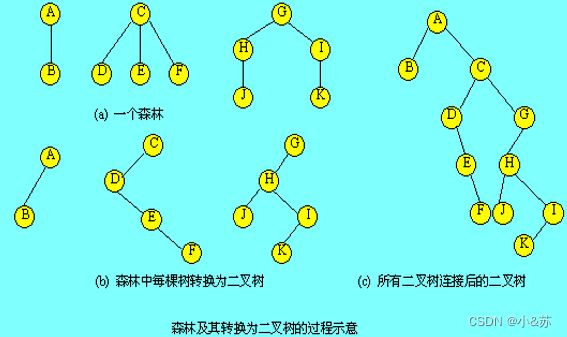
这一方法可形式化描述为:
如果F={ T1,T2,…,Tm }是森林,则可按如下规则转换成一棵二叉树B=(root,LB,RB)。
⑴若F为空,即m=0,则B为空树;
⑵若F非空,即m≠0,则B的根root即为森林中第一棵树的根Root(T1);B的左子树LB是从T1中根结点的子树森林F1={ T11,T12,…,T1m1 }转换而成的二叉树;其右子树RB是从森林F’={ T2,T3,…,Tm }转换而成的二叉树。
7.3.3二叉树转换为树和森林
树和森林都可以转换为二叉树,这一转换过程是可逆的,即可以将一棵二叉树还原为树或森林,具体方法如下:
⑴若某结点是其双亲的左孩子,则把该结点的右孩子、右孩子的右孩子……都与该结点的双亲结点用线连起来;
⑵删去原二叉树中所有的双亲结点与右孩子结点的连线;
⑶整理由⑴、⑵两步所得到的树或森林,使之结构层次分明。
下图给出一棵二叉树还原为森林的过程示意。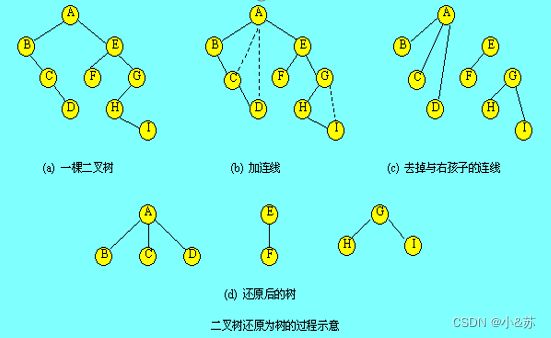
这一方法可形式化描述为:
如果B=(root,LB,RB)是一棵二叉树,则可按如下规则转换成森林F={ T1,T2,…,Tm }。
⑴若B为空,则F为空;
⑵若B非空,则森林中第一棵树T1的根ROOT(T1)即为B的根root;T1中根结点的子树森林F1是由B的左子树LB转换而成的森林;F中除T1之外其余树组成的森林F’={ T2,T3,…,Tm }是由B的右子树RB转换而成的森林。
7.4树和森林的遍历
7.4.1树的遍历
1.先根遍历
先根遍历的定义为:
⑴访问根结点;
⑵按照从左到右的顺序先根遍历根结点的每一棵子树。
按照树的先根遍历的定义,对上图所示的树进行先根遍历,得到的结果序列为:
A B E F C D G
2.后根遍历
后根遍历的定义为:
⑴按照从左到右的顺序后根遍历根结点的每一棵子树。
⑵访问根结点;
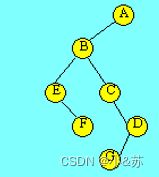
按照树的后根遍历的定义,对上图所示的树进行后根遍历,得到的结果序列为:
E F B C G D A
7.4.2森林的遍历
1.先序遍历
先序遍历的定义为:
⑴访问森林中第一棵树的根结点;
⑵先序遍历第一棵树的根结点的子树;
⑶先序遍历去掉第一棵树后的子森林。
对于下图所示的森林进行先序遍历,得到的结果序列为:
A B C D E F G H J I K
2.后序遍历
后序遍历的定义为:
⑴后序遍历第一棵树的根结点的子树;
⑵访问森林中第一棵树的根结点;
⑶后序遍历去掉第一棵树后的子森林。
对于下图所示的森林进行后序遍历,得到的结果序列为: B A D E F C J H K I G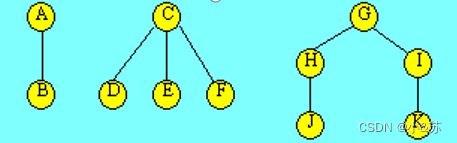
7.5树的应用
*7.5.1 判定树
在实际应用中,树可用于判定问题的描述和解决。
设有八枚硬币,分别表示为a,b,c,d,e,f,g,h,其中有一枚且仅有一枚硬币是伪造的,假硬币的重量与真硬币的重量不同,可能轻,也可能重。现要求以天平为工具,用最少的比较次数挑选出假硬币,并同时确定这枚硬币的重量比其它真硬币是轻还是重。
问题的解决过程如下图所示,解决过程中的一系列判断构成了树结构,我们称这样的树为判定树。
7.5.2 集合的表示
集合是一种常用的数据表示方法,对集合可以作多种操作,假设集合S由若干个元素组成,可以按照某一规则把集合S划分成若干个互不相交的子集合,例如,集合S={1,2,3,4,5,6,7,8,9,10},可以被分成如下三个互不相交的子集合:
S1={1,2,4,7}
S2={3,5,8}
S3={6,9,10}
集合{S1,S2,S3}就被称为集合S的一个划分。
此外,在集合上还有最常用的一些运算,比如集合的交、并、补、差以及判定一个元素是否是集合中的元素,等等。
为了有效地对集合执行各种操作,可以用树结构表示集合。用树中的一个结点表示集合中的一个元素,树结构采用双亲表示法存储。例如,集合S1、S2和S3可分别表示为图(a)、(b)、©所示的结构。将它们作为集合S的一个划分,存储在一维数组中,如下图所示。
数组元素结构的存储表示描述如下:
typedef struct {
elemtype data;
int parent;
}NodeType;
其中data域存储结点本身的数据,parent域为指向双亲结点的指针,即存储双亲结点在数组中的序号。
当集合采用这种存储表示方法时,很容易实现集合的一些基本操作。例如,求两个集合的并集,就可以简单地把一个集合的树根结点作为另一个集合的树根结点的孩子结点。如求上述集合S1和S2的并集,可以表示为:
S1∪S2={1,2,3,4,5,7,8}
该结果用树结构表示如下图所示。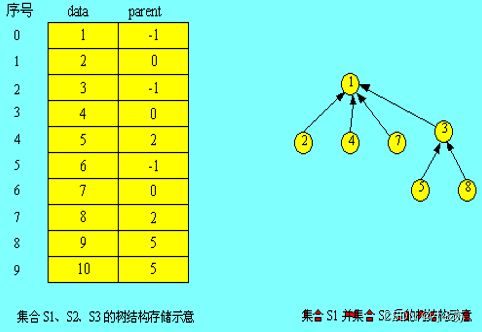
void Union(NodeType a[],int i,int j){
//合并以数组a的第i个元素和第j个元素为树根节点的集合
if(a[i].parent!=-1||a[j].parent!=-1)
{
cout<<"调用参数不正确"<<endl;
return;
}
a[j].parent=i;//将i置为两个集合共同的根结点
}
如果要查找某个元素所在的集合,可以沿着该元素的双亲域向上查,当查到某个元素的双亲域值为-1时,该元素就是所查元素所属集合的树根结点。
int Find(NodeType a[],DataType x){
//在数组a中查找值为x的元素所属的集合,若找到,返回树根节点在数组a中的序号;否则,返回-1.常量MAXNODE为数组a的最大容量
int i,j;
i=0;
while(i=MAXNODE)
return -1;//值为x的元素不属于该组集合,返回-1
j=i;
while(a[j].parent!=-1) j=a[j].paretn;
return j;//j为该集合的树根节点在数组a中的序号
}
*7.5.3 关系等价求等价类问题
1.问题:已知集合S及其上的等价关系R,求R在S上的一个划分{S1,S2,…,Sn},其中,S1,S2,…,Sn分别为R的等价类,它们满足:![]() Si=S 且 Si∩Sj=ф(i≠j)
Si=S 且 Si∩Sj=ф(i≠j)
设集合S中有n个元素,关系R中有m个序偶对。
2.算法思想:
⑴令S中每个元素各自形成一个单元素的子集,记作S1,S2,…,Sn; ⑵重复读入m个序偶对,对每个读入的序偶对
3.数据的存储结构:
对集合的存储采用双亲表示法来存储本算法中的集合。
4.算法实现
通过前面的分析可知,本算法在实现过程中所用到的基本操作有以下两个:
⑴Find(S,x)查找函数。确定集合S中的单元素x所属子集Si,函数的返回值为该子集树根结点在双亲表示法数组中的序号;
⑵Union(S,i,j)集合合并函数。将集合S的两个互不相交的子集合并,i和j分别为两个子集用树表示的根结点在双亲表示法数组中的序号。合并时,将一个子集的根结点的双亲域的值由没有双亲改为指向另一个子集的根结点。
这两个操作的实现在7.5.2小节中已经介绍过,下面就本问题的解决算法步骤给出描述:
①k=1
②若k>m则转⑦,否则转③
③读入一序偶对
④i= Find(S,x); j= Find(S,y)
⑤若i≠j,则Union(S,i,j);
⑥k++
⑦输出结果,结束。
5.算法的时间复杂性:
集合元素的查找算法和不相交集合的合并算法的时间复杂度分别为O(d)和O(1),其中d是树的深度。这种表示集合的树的深度和树的形成过程有关。在极端的情况下,每读入一个序偶对,就需要合并一次,即最多进行m次合并,若假设每次合并都是将含成员多的根结点指向含成员少的根结点,则最后得到的集合树的深度为n,而树的深度与查找有关。这样全部操作的时间复杂性可估计为O(mn)。
若将合并算法进行改进,即合并时将含成员少的根结点指向含成员多的根结点,这样会减少树的深度,从而减少了查找时的比较次数,促使整个算法效率的提高。