[Transformer]Segtran:Medical Image Segmentation Using Squeeze-and-Expansion Transformers
SegTran:基于Squeeze-Expansion的Transformer用于医学图像分割
- Abstract
- Section I Introduction
- Section II Related Work
- Section III Squeeze-and-Expansion Transformer
-
- Part 1 Squeezed Attention Block I
- Part 2 Expanded Attention Block
- Section IV Segtran Architecture
-
- Part 1 CNN Backbone
- Part 2 Transformer Layers
- Part 3 Feature Pyramids and Segmentation Head
- Section V Experiments
-
- Part 1 Ablation Studies
- Part 2 Comparison with Baselines
- Part 3 Computation Efficiency
-
- Part 4 Impact of pre-training
- Section VI Conclusions
Paper
Abstract
医学图像分割对计算机辅助诊断至关重要,为了得到较好的分割结果需要同时获得图像的全局特征和细节信息,即学习全局上下文的而同时保持高空间分辨率的图像特征。UNet及其变体,作为最广泛选用的模型通过skip connection和encoder-decoder结构提取和融合多尺度特征。但是融合的特征仍然受限于有限的感受野,限制了自身的能力。
本文提出了一种基于Transformer的替代分割模型-Segtran,即使在高特征分辨率下的感受野也不受限制。
Segtran的核心是Squeeze-Expansion Transformer:squeese模块负责对transformer的注意力进行正则化,expansion模块负责学习多样化的特征表述。
此外本文还提出一种新的特征编码方式,可以对图像施加持续的归纳偏执。
在视杯视盘分割、结肠息肉分割、脑补肿瘤分割等2D和3D医学图像分割任务上进行了实验,Segtran均获得了最高的分割精度,并且表现出良好的泛化能力。
Section I Introduction
自动化医学图像分割会自动描绘解剖结构和其他感兴趣区域(ROI),是计算机辅助诊断的重要步骤,可以用于量化组织体积、提取关键的病理指标等。精确的分割结果需要同时捕获图像的全局特征和细节特征,但是CNN难以做到。
因为CNN的高级语义特征是通过牺牲特征分辨率得到的。
自从UNet问世以来,其在医学图像分割领域大获成功。UNet是一种编解码结构,其中编码器通过连续的下采样操作获得不同尺度的上下文特征,decoder则会对上下文特征进行上采样和融合。但是随着卷积层的堆叠,远处像素的影响显著降低,因此使得UNet的有效感受野远远小于其理论分析值。
![[Transformer]Segtran:Medical Image Segmentation Using Squeeze-and-Expansion Transformers_第1张图片](http://img.e-com-net.com/image/info8/cddb5c26e60245e7a6163a4a92865df0.jpg)
由Fig 2可以看到,UNet和DeepLabV3+的有效感受野仅在90像素左右,也就是说它们的决策是基于这么大有效感受野做出的,但实际任务中需要ROI的高度/宽度远大于200像素,远远超过了有效感受野的范围。因此在无法看到全局的情况下,UNet可能受局部感受野的误导产生误分割。
许多研究也对UNet进行了改进,如UNet++和UNet3+使用了更为复杂的skip connection;Attention UNet则是引入了注意力门;3D-UNet,V-Net则进一步将UNet拓展到3D图像;Eff-Unet则是将encder部分替换为了预训练的EfficientNet.
Transformer在CV领域越来越受到关注,因为他可以有效通过SA的计算捕获所有输入单元之间的交互作用,结合它们的特征生成上下文信息。
Transformer的上下文提取类似Unet中的上采样网络,但是它的感受野不是局部的,因此可以捕获长程依赖关系。因此Transformer也适合于图像分割任务。
本文提出的SegTran是一种基于Transformer的分割网络,如果直接将Transformer1嵌入分割网络,只能带来些许的性能提升。因为Transformer最初是用于NLP的,应用到图像任务还可以做进一步改进。
因此本文提出一种新的Transformer结构:Squeeze-Expansion Transformer,借助squeeze attention block对注意力矩阵进行正则化,借助expansion block来学习丰富的特征表述。
此外本文还提出一种新的位置嵌入编码方法,可以对Transformer嵌入连续的归纳偏置,从而提升分割效果。
本文在2D图像的视杯视盘分割、息肉分割;以及3D图像的脑肿瘤分割任务上进行了测试,与其他peerwork和基准网络相比,均取得了最佳性能。
Section II Related Work
本文的灵感来自于DETR,DETR使用transformer layer来生成上下文表述代表不同物体,然后通过一系列的object query来提取目标的位置和类别;DETR也可以用于做全景分割,但是需要两阶段,不适合医学图像分割;Cell-DETR也使用Transformer来做医学图像分割,但是还是基于DETR结构,没有添加向我们这种squeeze-expansion组件。最近SETR,TransUNet也基于Transformer做医学图像分割,主要是将Transformer作为encoder来提取特征,此时图像特征已经包含了全局上下文信息,然后使用一些卷积层作为decoder来生成分割图。相比之下,Segtran基于CNN提取的局部特征之上来构建全局上下文信息,然后借助FPN生成最终的分割图。
此外,Muras等人尝试对CNN通道引入编码信息,并且验证了对分割性能的提升。
本文则是通过消融实验验证位置编码确实可以提升Segtran的分割性能。
虽然UNet可以通过搭建更深的网络层次来增大感受野,但是这增加了网络参数量还增加了过拟合的风险;另一种方法是在下采样时采用更大的步长,但是这样会降低特征图的空间精度,于分割不利。
Section III Squeeze-and-Expansion Transformer
Transformer的核心是self-attention的计算,首先会计算每一对输入之间的注意力系数,然后计算所有注意力系数乘上之后的加权平均和。
基于SA的多头注意力(MHA)旨在捕获输入之间不同类型的关联信息,因此每个head会单独计算注意力,最终的输出通过级联后作为最终的MHA的输出,不同的head在不同的特征子空间中计算。
本文认为Transformer可以从以下四方面进行改进:
(1)SA的计算中,attention matrix是通过输入经过投影之后线性组合得到的,当N很大时容易受到噪声影响,因此应当低秩注意力矩阵;
(2)在原始Transformer中输出特征时单模态的,即只是一组特征映射,不能更好的建模特中标书,就像通过高斯混合比单一的高斯分布 能更好的描述数据分布一样,因此将k个transformer混合可以更好的捕捉数据变化;
(3)在原始Transformer中,k,q是分开学习的,这样可以捕获NLP中不同token之间的非对称关系;但是在图像中像素之间的关系通常是对称的,比如验证两个像素点是否属于同一类别;
(4)图像的像素点具有很强的局部性和语义连续性,目前两类主流的位置编码方法都没有完全建模出这种关系,因此可以进一步改进位置编码方法。
本文的Segtrna旨在对上述4方面进行改进,Squeeze Attention会计算当前输入与M个inducingpoint之间的注意力,并将注意力矩阵压缩至NxM大小;Expansion Module则混合了Nm个专家的知识;此外在上面两个模块中,Q,K的映射是绑在一起的,这样计算的注意力是对称的,从而更适合建模图像元素之间的对称关系。
最后,本文还提出了一种新的科学系的正弦位置编码方法来更好的捕获空间关系。
Part 1 Squeezed Attention Block I
SAB中提出的Induced Set Attention Block将inducing point引入Transformer,最初是为了更好的学习无序目标的特征,本文则将这种squeeze设计引入到注意力矩阵的计算中来减少噪声和过拟合的风险,本文将ISAB中的这一方法重命名为Squeezed Attention Block(SAB)来强调在本文中全新的租用。
原始注意力矩阵计算的是MxM大小的矩阵,SAB中计算的则是M个元素到N个inducing point的注意力,具体计算过程如下:
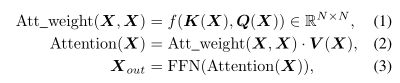
这样注意力矩阵为MxN,计算更紧凑。
SAB类似于原始Transformer中的codebook,是一种低秩矩阵因式分解的方法,将原来NxN的矩阵分别为两个NxD矩阵的计算,这可以看做是一种正则化手段,可以有效避免过拟合、抵抗噪声。
Fig 3分别展示了Full SA和Squeezed Atention,SA的特征维度是NxN,SAB则是将NxN的计算分别为两个NxM的计算。
Part 2 Expanded Attention Block
Expanded Attention Block(EAB)包含Nm个节点,每一个节点代表一个单头的trnasformer,因此输出则是Nm个transformer聚合的结果。
EAB是一种Mixture-of-Experts的方法,Fig 4展示了EAB与MHA的区别,可以看到MHA是不同特征的级联,而EAB每一个Node代表一种子空间内的映射模式,最后混合得到的结果汇包含更多的信息。
![[Transformer]Segtran:Medical Image Segmentation Using Squeeze-and-Expansion Transformers_第2张图片](http://img.e-com-net.com/image/info8/6fbc2ead49364a20b0b559b323ab73e4.jpg)
## Part 3 Learnable Sinusoidal Positional Encoding
图像中的一种关键的归纳偏执就是局部像素之间的语义连续性,借助CNN可以有效建模;但是Transformer把输入展平了,PE是空间信息的唯一来源,这样虽然可以接受任意长度的输入,但是引入的位置信息缺失比较简单的。
目前主流的两种PE方案分别是:正弦编码和离散可学习编码。前者在空间上是连续的但是缺乏适应性,因为编码方案是预先给定的;后者会为每个坐标学习单独的位置编码方案,但是却是不连续的。
因此本文提出了一种可学习的正弦PE方案,同时保证了编码方案的连续性和适应性。表示为:
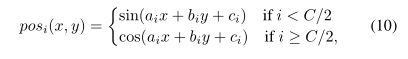
i代表第i个位置,a,b,c分别是需要学习的权重,C则是图像特征的维度,通过可学习的a,b,c对输入坐标进行映射,按照维度进行不同的编码,最后再将坐标归一化到[0,1]得到PE之后的结果。 这样编码的结果是会随着像素坐标进行一定的平滑,当前坐标附近的元素或得到相似的位置编码,从而使得他们之间的注意力权值更大,这就是连续性偏置的精髓。通过可学习的权值和正弦激活函数可以建模更复杂的空间关系。
Section IV Segtran Architecture
分割作为像素级别的预测任务,需要解决全局上下文(更低的分辨率)和细节的信息(更高的分辨率)之间的冲突。Segtran通过计算像素之间的特征提取,避免了空间分辨率的损失。Segtran包含5大主要部分,分别为:
(1)CNN backbone提取输入图像特征;
(2)对输入和输出通过金字塔进行上采样
;
(3)可学习的正弦位置编码方案
;
(4)Squeeze-and-Expansion transformer layer用来提取上下文特征
;
(5)分割头
![[Transformer]Segtran:Medical Image Segmentation Using Squeeze-and-Expansion Transformers_第3张图片](http://img.e-com-net.com/image/info8/b03e430143194079853fb4145f16107f.jpg)
Fig 1展示的是Segtran的网络结构。首先原始图像会经过CNN Backbone提取特征,然后进行位置信息的嵌入;随后将迁入之后的特征项链展平成序列,输入Transformer中。Transformer中则是通过一系列Squeeze-and-Expansion Transformer layer来记性处理;最后为了扩大空间分辨率,在Transformer的前后都加入两个FPN来提升空间分辨率。
Part 1 CNN Backbone
本文采用预训练的CNN进行特征提取,处理2D图像采用的是ResNet-101或者Efficient-D4;处理3D图像用的是I3D。
Part 2 Transformer Layers
在送入Transformer之前还要进行PE。 Transformer layer包含多层,输入输出维度保持一致,具体结构就是前面介绍的Squeeze-and-Expansion block。
Part 3 Feature Pyramids and Segmentation Head
通常给Transformer输入具有更丰富语义特征的feature map效果会更好,因此本文增加了特征金字塔网络(FPN)来融合提取到的多尺度特征,比如f34是融合第三层发和第四层的feature map,他们的分辨率分别是1/8和1/16.
随后将融合之后的特征图展平并进行PE,送入Transformer.
![]()
在output也设置了一个FPN来上采样输出结果,具体操作为:
![]()
会分别融合input FPN和Transformer的结果。 最终经过1x1卷积层获得最终的segmentation map。
Section V Experiments
本文在三个任务上验证了Segtrans的有效性,分别是:
视杯视盘分割: REFUGE20
2D图 training:validation= 200:400
结肠镜息肉分割: Polyp Segmentation 2D图像
数据集:CVC612(612 images),Kvasir
training:validation = 80:20
脑部肿瘤分割:Tumor segmentation
分割神经胶质瘤,是BraTS’19挑战赛的一部分,需要分割四部分:WT整个肿瘤,TC肿瘤核心,ET增强肿瘤,背景
Part 1 Ablation Studies
Table 1展示了Squeeze-and-Expansion层的效果,可以看到二者均对视杯视盘分割精度有提升;Table 2则是加入PE之后的效果,如果不加PE,精度会下降1-2%,一种可能的解释是Transformer可以设法从CNN backbone中提取位置信息。 Table 3则展示了transformer层数的影响,可以看到层数并不是越多越高,增加到3层之后,使用4层精度反而会有一定下降。因为较多层可能导致了过拟合。
Part 2 Comparison with Baselines
2D分割对比的网络有:
UNet,UNet++,U-Net3+,PraNet,DeepLabV3+,Attention based UNets(AttU-Net,AttR2U-Net),nn-UNet,Deformable U-Net,SETR,TransUNet
3D分割对比的网络有:
nn-UNet变体,Bag-of-Tricks(BraTS排名第二的搭配)
Table 4和Table 5分别展示了对比结果。
可以看到基于Transformer的模型中,SETR,Trans-UNet,和本文的Segtran均取得了优异的性能,以ResNet101为backbone时Segtran性能最佳,换成Efficient-B4时效果更好,在REFUGE20挑战中取得了top5的好成绩。
![[Transformer]Segtran:Medical Image Segmentation Using Squeeze-and-Expansion Transformers_第4张图片](http://img.e-com-net.com/image/info8/da8e4621fdeb4db8bed908f04c1dd130.jpg)
![[Transformer]Segtran:Medical Image Segmentation Using Squeeze-and-Expansion Transformers_第5张图片](http://img.e-com-net.com/image/info8/462a1446ae9943258b1660ab28d7d7f1.jpg)
![[Transformer]Segtran:Medical Image Segmentation Using Squeeze-and-Expansion Transformers_第6张图片](http://img.e-com-net.com/image/info8/bfd1a0f9ed8e4127970b9353e64607a3.jpg)
Part 3 Computation Efficiency
![[Transformer]Segtran:Medical Image Segmentation Using Squeeze-and-Expansion Transformers_第7张图片](http://img.e-com-net.com/image/info8/1130a45ef86f4eadbecaa152195a82f6.jpg)
Table 7对比了不同网络的参数量和FLOPs,可以看到基于Transformer的网络参数量都会略大,消耗更多的内存资源;而本文的Segtran参数量主要取决于output FPN,因此采取不同的backbone会对参数量有巨大影响。
选择EfficientNet时参数量最少,如果选ResNet为backbone参数连会略有上升。因此当计算资源有限时不推荐以ResNet为backbone。
Part 4 Impact of pre-training
Table 8展示的是预训练的影响,乐意看到预训练一般会到来2.5%的精度提升。
![[Transformer]Segtran:Medical Image Segmentation Using Squeeze-and-Expansion Transformers_第8张图片](http://img.e-com-net.com/image/info8/9041b932ce224e6081cdbdda6f951cb0.jpg)
![[Transformer]Segtran:Medical Image Segmentation Using Squeeze-and-Expansion Transformers_第9张图片](http://img.e-com-net.com/image/info8/f619727a98a14bb3b60a7cca0b0b89bf.jpg)
Section VI Conclusions
本文提出的Segtran是一种基于Transformer的医学图像分割框架,有效的改善了CNN感受野有限的问题,此外借助改进的Squeese-and-Expansion Transformer layer可以同时获取全局上下文和细节特征,更好的完成图像分割任务。
本文在2D和3D图上均测试了Segtran的性能,实验结果表示Segtran优于现有的方法,可以进一步推广到其他领域。