FCN 全卷积神经网络代码解读
FCN网络一开始是用来作为网络分割的,如下图;
FCN最大的优势就是对于图片的输入大小没有限制-因为全部采用卷积模块,不像全连接神经网络一样是固定数目的节点个数,本文主要讲解fcn的网络结构并训练一个图像分割的数据集。
- 首先是fcn的网络结构部分,直接一张图可以概况
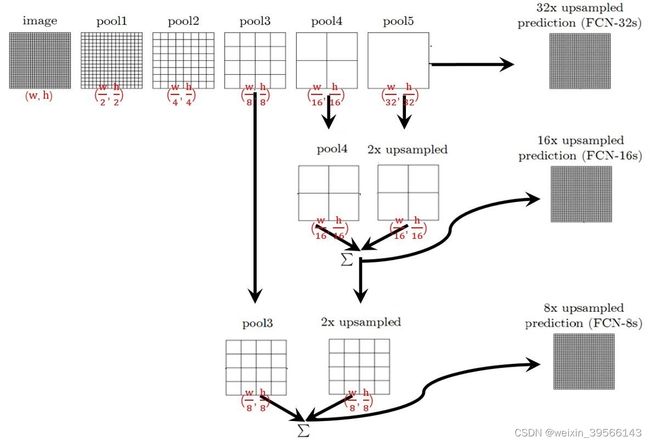
最开始的image通过一系列卷积池化操作可以获得不同尺寸的特征图,一般一次卷次或者池化操作会将特征图宽高减半,所以从image到pool1,特征图变成了(w/2,h/2),后面的pool1到pool5,以此类推。这部分的网络结构可以采用Resnet或者VGG等等。
到pool5这个特征图,特征图的大小变为原图像的1/32,为了进行像素级别的分割任务,需要将特征图还原到image的图像大小(这样输出和输入图片的像素才能一一对应),这里有三种方式可以完成,分别是插值,反卷积和反池化,下面代码里用的反卷积,所以这里就大概描述一样反卷积算法。
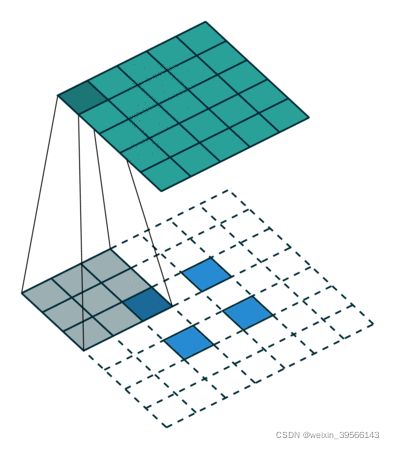
直观来看,就是对原始特征图先进行填充0,然后再进行正常的卷积运算,一般情况下输出与输入的尺度关系为
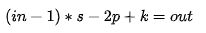
in为输入尺寸,s为步长,p为padding,k为kernel size,out为输出尺寸,一般还可以在反卷积过后的输出上面再进行padding,也就是out padding。
下面的代码里几乎都是反卷积模块,其参数如下
kerne size = 3,stride = 2,padding = 1,out padding = 1
所以其输出大小为(in-1)*2 - 2*1 +3 +1 = 2 * in
也就是将输入尺寸扩大两倍,跟文章一开始讲的缩小2倍正好相反。比如上面题到pool5的输出为输入的32分之一,
那么只需要用对pool5的输出进行5次反卷积即可恢复到原图像大小。
下面贴FCN-32s的模型
# -*- coding: utf-8 -*-
from __future__ import print_function
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision.models.vgg import VGG
class FCN32s(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
self.n_class = n_class
self.pretrained_net = pretrained_net
self.relu = nn.ReLU(inplace=True)
# h_out = (h_in - 1) * stride - 2 * padding + kernel_size
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, n_class, kernel_size=1)
def forward(self, x):
output = self.pretrained_net(x)
x5 = output['x5'] # size=(N, 512, x.H/32, x.W/32)
score = self.bn1(self.relu(self.deconv1(x5))) # size=(N, 512, x.H/16, x.W/16)
score = self.bn2(self.relu(self.deconv2(score))) # size=(N, 256, x.H/8, x.W/8)
score = self.bn3(self.relu(self.deconv3(score))) # size=(N, 128, x.H/4, x.W/4)
score = self.bn4(self.relu(self.deconv4(score))) # size=(N, 64, x.H/2, x.W/2)
score = self.bn5(self.relu(self.deconv5(score))) # size=(N, 32, x.H, x.W)
score = self.classifier(score) # size=(N, n_class, x.H/1, x.W/1)
return score # size=(N, n_class, x.H/1, x.W/1)
每行后面都有注释目前的特征图大小,过程与上述的讲解一样,就是5次连续的反卷积过程。
接下来是FCN-16s,有一点点不一样的地方。
class FCN16s(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
self.n_class = n_class
self.pretrained_net = pretrained_net
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, n_class, kernel_size=1)
def forward(self, x):
output = self.pretrained_net(x)
x5 = output['x5'] # size=(N, 512, x.H/32, x.W/32)
x4 = output['x4'] # size=(N, 512, x.H/16, x.W/16)
score = self.relu(self.deconv1(x5)) # size=(N, 512, x.H/16, x.W/16)
score = self.bn1(score + x4) # 这里不一样 element-wise add, size=(N, 512, x.H/16, x.W/16)
score = self.bn2(self.relu(self.deconv2(score))) # size=(N, 256, x.H/8, x.W/8)
score = self.bn3(self.relu(self.deconv3(score))) # size=(N, 128, x.H/4, x.W/4)
score = self.bn4(self.relu(self.deconv4(score))) # size=(N, 64, x.H/2, x.W/2)
score = self.bn5(self.relu(self.deconv5(score))) # size=(N, 32, x.H, x.W)
score = self.classifier(score) # size=(N, n_class, x.H/1, x.W/1)
return score # size=(N, n_class, x.H/1, x.W/1)
这里使用了pool4和pool5两层的特征图,前面说了pool5是图像的32分之一大小,pool4是16分之一,所以先对pool5的特征图进行反卷积变成与pool4的输入一样大,然后再把两者加起来(逐元素相加),最后跟连续进行4从反卷积,就可以得到原图的尺寸。