向毕业妥协系列之机器学习笔记:无监督学习-异常检测
目录
一.发现异常事件
二.高斯正态分布
三.异常检测算法
四.开发与评估异常检测系统
五.异常检测与监督学习对比
六.选择使用什么特征
一.发现异常事件
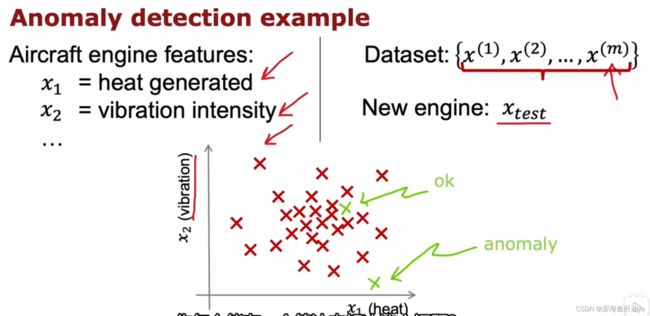
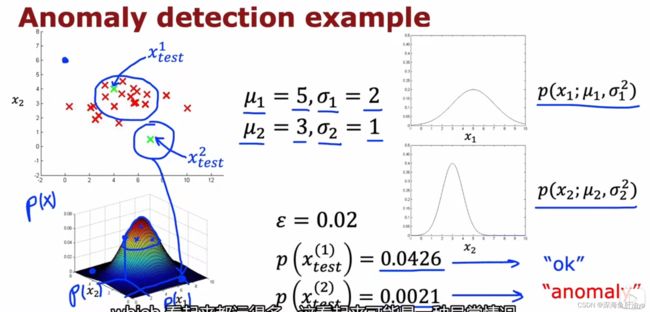
下图的例子是飞机发动机的制造,有很多特征,我们为了方便讲解取其中的两个特征:发动机产生的热量和震动强度,然后数据集是m个(发动机,每个发动机有两个特征),我们这个异常检测的问题就是测试新的数据和原来的数据是否相似,可以看到下图的坐标轴图像的示例 ,有一个合格的示例,也有一个异常的示例。
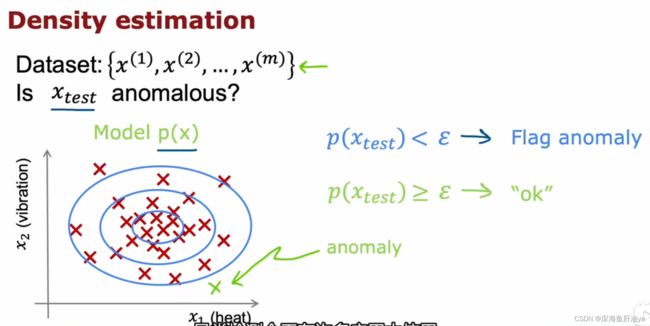
那么如何检测呢,一个方法是密度估计,如下图示新的测试数据落到内圈的概率最高(因为那里最密集),越往外越稀疏(落到外圈的概率也就越来越小),所以我们就有一个概率模型p,用于计算新数据x_test的概率,如果 概率小于设定的epsilon值,那么就认定是异常,如果≥设定的epsilon值,就认为是正常。
二.高斯正态分布
其实就是正态分布。越学越觉得数学的魅力,不愧是宇宙第一学科。
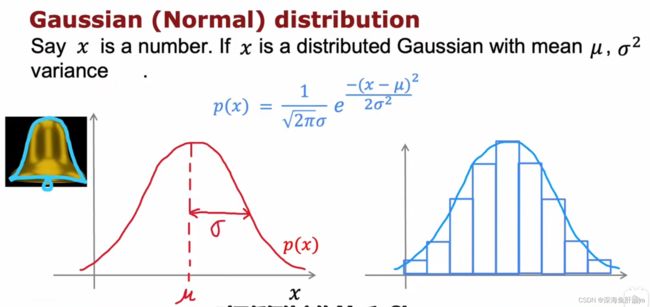
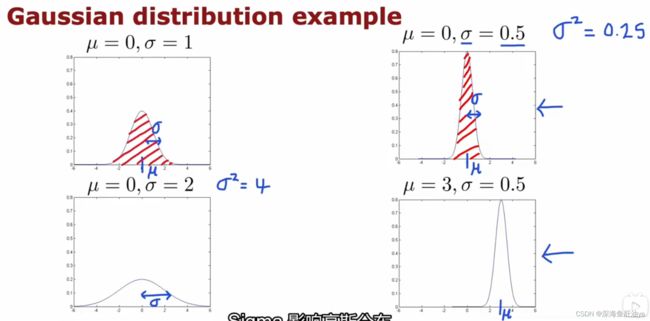
因为概率总和是1,所以图中的阴影部分的面积是不变的,所以所以当σ(sigma)减小时,图像变窄的同时也会变宽
下图,根据坐标轴的散点,咱们可以套用公式来计算出μ和σ,然后正态分布的图像就有了
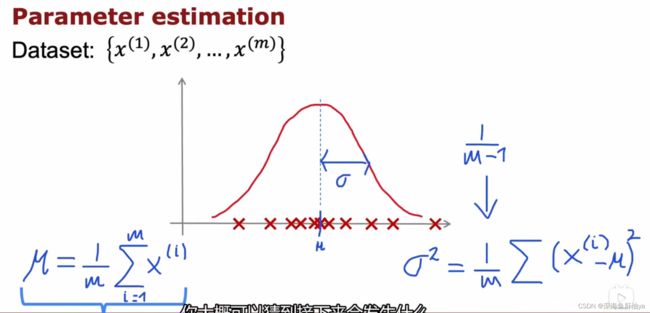
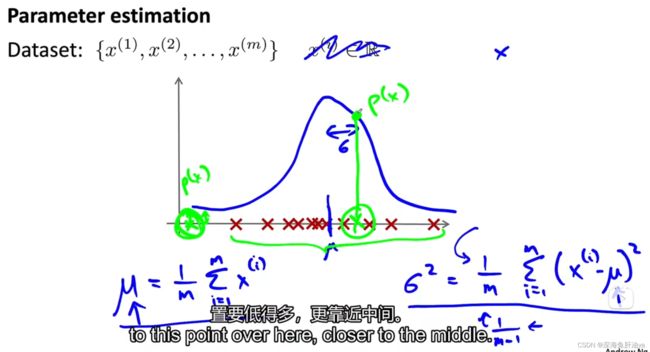
检测方法如下图,绿色的是新的数据,可以看到随着位置的不同对应于不同的概率,概率越小也就越远离大部队,当低于一定概率之后就会被认为是异常示例。
三.异常检测算法
下图中的x_i其实应该写成x^(i),意思就是每个x^(i)都有n个特征,每个特征x^(i)_ j都对应一组μ_ j和σ^2_ j,然后训练示例的各个特征的概率累乘即可得到这个训练示例的概率。
举例来说明一下这个思想:
比如温度过高的概率是1/10,震动过大的概率是1/20,那么温度过高且震动过大的概率就是
(1/10)*(1/20)=1/200

indicative:指示的,表明的,象征的
异常检测算法过程:


以只有两个特征为例,最后的模型pru如下,是一个三维图
四.开发与评估异常检测系统
异常检测算法是一个非监督学习算法,意味着我们无法根据结果变量
的值来告诉我们数据是否真的是异常的。我们需要另一种方法来帮助检验算法是否有效。当我们开发一个异常检测系统时,我们从带标记(异常或正常)的数据着手,我们从其中选择一部分正常数据用于构建训练集,然后用剩下的正常数据和异常数据混合的数据构成交叉检验集和测试集。
例如:我们有10000台正常引擎的数据,有20台异常引擎的数据。 我们这样分配数据:
6000台正常引擎的数据作为训练集
2000台正常引擎和10台异常引擎的数据作为交叉检验集
2000台正常引擎和10台异常引擎的数据作为测试集
具体的评价方法如下:
- 根据测试集数据,我们估计特征的平均值和方差并构建p(x)函数
- 对交叉检验集,我们尝试使用不同的ε值作为阀值,并预测数据是否异常,根据F1值或者查准率与查全率的比例来选择ε
- 选出ε后,针对测试集进行预测,计算异常检验系统的F1值,或者查准率与查全率之比
五.异常检测与监督学习对比
之前我们构建的异常检测系统也使用了带标记的数据,与监督学习有些相似,下面的对比有助于选择采用监督学习还是异常检测:
两者比较:

希望这节课能让你明白一个学习问题的什么样的特征,能让你把这个问题当做是一个异常检测,或者是一个监督学习的问题。另外,对于很多技术公司可能会遇到的一些问题,通常来说,正样本的数量很少,甚至有时候是0,也就是说,出现了太多没见过的不同的异常类型,那么对于这些问题,通常应该使用的算法就是异常检测算法。

六.选择使用什么特征

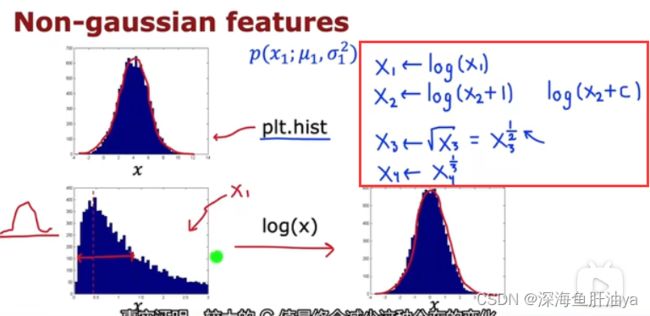
尽量选取符合高斯分布的特征作为咱们训练的特征,即便是不符合高斯分布的特征我们也可以尽量把它转变成符合高斯分布的特征。转换的方式可以参考下图的红框处的方式,可以取对数,一般的形式是log(x_2+C),C是一个常数值,事实证明较大的C值最终会减少高斯分布的变化。也可以取冥,比如平方根,立方根等等。
但是这种像向高斯数据的转变一般都是试出来的,比如试多个C的值。
误差分析:
一个常见的问题是一些异常的数据可能也会有较高的值,因而被算法认为是正常的。比如说购物时,黄牛要薅羊毛,用了一些违规程序去抢购,系统检测打字速度等特征,就可以明显分出这些异常示例。这种情况下误差分析能够帮助我们,我们可以分析那些被算法错误预测为正常的数据,观察能否找出一些问题。我们可能能从问题中发现我们需要增加一些新的特征,增加这些新特征后获得的新算法能够帮助我们更好地进行异常检测。
异常检测误差分析:
我们通常可以通过将一些相关的特征进行组合,来获得一些新的更好的特征(异常数据的该特征值异常地大或小),例如,在检测数据中心的计算机状况的例子中,我们可以用CPU负载与网络通信量的比例作为一个新的特征,如果该值异常地大,便有可能意味着该服务器是陷入了一些问题中。

我们介绍了如何选择特征,以及对特征进行一些小小的转换,让数据更像正态分布,然后再把数据输入异常检测算法。同时也介绍了建立特征时,进行的误差分析方法,来捕捉各种异常的可能。希望你通过这些方法,能够了解如何选择好的特征变量,从而帮助你的异常检测算法,捕捉到各种不同的异常情况。