YOLOV5详细解读
YOLOV5检测算法详解
学习前言
本文主要是对基于深度学习的目标检测算法进行细节解读,以YOLOV5为例;
基于深度学习的目标检测整体流程
基于深度学习的目标检测主要包括训练和测试两个部分。
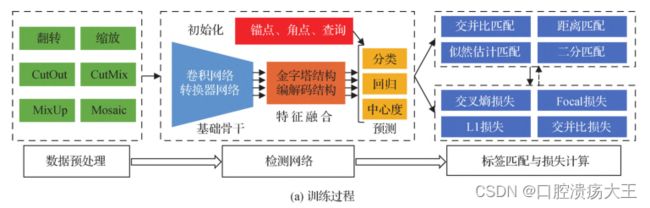
训练阶段
训练的目的是利用训练数据集进行检测网络的参数学习,其中训练数据集包含大量的视觉图像和标注信息(物体位
置及类别)。训练阶段的主要过程包括数据预处理、检测网络以及标签匹配与损失计算等部分。
1.数据预处理
数据预处理的目的在于增强训练数据多样性,进而提升检测网络的检测能力。
YOLOV5所采用的预处理方式主要有:翻转、缩放、扭曲、色域变换、Mosaic
翻转:
image = image.transpose(Image.FLIP_LEFT_RIGHT) #利用PIL库对图片直接翻转
box[:, [0,2]] = iw - box[:, [2,0]] #翻转图片后要对目标框同时进行调整
缩放:
#由于实际图像w和h不是相等的,所以采用不失真的resize,将长边resize到和输入尺寸一样大小,然后其余部分
放上灰条
scale = min(w/iw, h/ih) #iw、ih是数据集中图像实际尺寸,w,h为网络输入的图像尺寸,scale为图像缩放因子
nw = int(iw*scale) #图像宽缩放后尺寸
nh = int(ih*scale) #图像长缩放后尺寸
dx = (w-nw)//2 #缩放后图像放在灰度图像上的位置
dy = (h-nh)//2 #缩放后图像放在灰度图像上的位置
image = image.resize((nw,nh), Image.BICUBIC) #将输入图像插值到实际缩放后的尺寸大小
new_image = Image.new('RGB', (w,h), (128,128,128)) #生成一个三通的,大小为(w,h)的灰度图像
new_image.paste(image, (dx, dy)) #将缩放后的实际图像放在灰度图像 (dx, dy)的位置上
image_data = np.array(new_image, np.float32) #再转换成数组格式
扭曲:
new_ar = iw/ih * self.rand(1-jitter,1+jitter) / self.rand(1-jitter,1+jitter) #iw、ih是数据集中图像实际尺寸,jitter扭曲因子
scale = self.rand(.25, 2)
if new_ar < 1:
nh = int(scale*h)
nw = int(nh*new_ar)
else:
nw = int(scale*w)
nh = int(nw/new_ar)
image = image.resize((nw,nh), Image.BICUBIC)
色域变换:
r = np.random.uniform(-1, 1, 3) * [hue, sat, val] + 1
hue, sat, val = cv2.split(cv2.cvtColor(image_data, cv2.COLOR_RGB2HSV)) #j将图片转换成HSV格式,再把每个通道分离开来
dtype = image_data.dtype
x = np.arange(0, 256, dtype=r.dtype)
lut_hue = ((x * r[0]) % 180).astype(dtype)
lut_sat = np.clip(x * r[1], 0, 255).astype(dtype)
lut_val = np.clip(x * r[2], 0, 255).astype(dtype)
image_data = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val))) image_data = cv2.cvtColor(image_data, cv2.COLOR_HSV2RGB)
Mosaic:
train_annotation_path = '1.txt'
with open(train_annotation_path, encoding='utf-8') as f:
train_lines = f.readlines()
jitter = 0.3
h, w = [640,640]
min_offset_x = rand(0.3, 0.7)
min_offset_y = rand(0.3, 0.7)
image_datas = []
box_datas = []
index = 0
lines = sample(train_lines, 3)
lines.append(train_lines[index])
shuffle(lines) #从训练集中随机取4张图片进行拼接
for line in lines:
line_content = line.split()
image = Image.open(line_content[0])
image = cvtColor(image)
iw, ih = image.size
box = np.array([np.array(list(map(int,box.split(',')))) for box in line_content[1:]])
new_ar = iw / ih * rand(1 - jitter, 1 + jitter) / rand(1 - jitter, 1 + jitter)
scale = rand(.4, 1)
if new_ar < 1:
nh = int(scale * h)
nw = int(nh * new_ar)
else:
nw = int(scale * w)
nh = int(nw / new_ar)
image = image.resize((nw, nh), Image.BICUBIC)
if index == 0: #分别计算出四张图片分别摆放的位置
dx = int(w * min_offset_x) - nw
dy = int(h * min_offset_y) - nh
elif index == 1:
dx = int(w * min_offset_x) - nw
dy = int(h * min_offset_y)
elif index == 2:
dx = int(w * min_offset_x)
dy = int(h * min_offset_y)
elif index == 3:
dx = int(w * min_offset_x)
dy = int(h * min_offset_y) - nh
new_image = Image.new('RGB', (w, h), (128, 128, 128))
new_image.paste(image, (dx, dy))
image_data = np.array(new_image)
index = index + 1
box_data = []
if len(box) > 0: #对box重新进行处理,超出边界,都要将其限制在图像里面
np.random.shuffle(box)
box[:, [0, 2]] = box[:, [0, 2]] * nw / iw + dx
box[:, [1, 3]] = box[:, [1, 3]] * nh / ih + dy
box[:, 0:2][box[:, 0:2] < 0] = 0
box[:, 2][box[:, 2] > w] = w
box[:, 3][box[:, 3] > h] = h
box_w = box[:, 2] - box[:, 0]
box_h = box[:, 3] - box[:, 1]
box = box[np.logical_and(box_w > 1, box_h > 1)]
box_data = np.zeros((len(box), 5))
box_data[:len(box)] = box
image_datas.append(image_data)
box_datas.append(box_data)
cutx = int(w * min_offset_x)
cuty = int(h * min_offset_y)
new_image = np.zeros([h, w, 3])
new_image[:cuty, :cutx, :] = image_datas[0][:cuty, :cutx, :]
new_image[cuty:, :cutx, :] = image_datas[1][cuty:, :cutx, :]
new_image[cuty:, cutx:, :] = image_datas[2][cuty:, cutx:, :]
new_image[:cuty, cutx:, :] = image_datas[3][:cuty, cutx:, :]
new_image = np.array(new_image, np.uint8)
merge_bbox = []
for i in range(len(bboxes)): #在四张拼接图上面对框进行调整,防止其超出界限
for box in bboxes[i]:
tmp_box = []
x1, y1, x2, y2 = box[0], box[1], box[2], box[3]
if i == 0:
if y1 > cuty or x1 > cutx:
continue
if y2 >= cuty and y1 <= cuty:
y2 = cuty
if x2 >= cutx and x1 <= cutx:
x2 = cutx
if i == 1:
if y2 < cuty or x1 > cutx:
continue
if y2 >= cuty and y1 <= cuty:
y1 = cuty
if x2 >= cutx and x1 <= cutx:
x2 = cutx
if i == 2:
if y2 < cuty or x2 < cutx:
continue
if y2 >= cuty and y1 <= cuty:
y1 = cuty
if x2 >= cutx and x1 <= cutx:
x1 = cutx
if i == 3:
if y1 > cuty or x2 < cutx:
continue
if y2 >= cuty and y1 <= cuty:
y2 = cuty
if x2 >= cutx and x1 <= cutx:
x1 = cutx
tmp_box.append(x1)
tmp_box.append(y1)
tmp_box.append(x2)
tmp_box.append(y2)
tmp_box.append(box[-1])
merge_bbox.append(tmp_box)
2.检测网络
检测网络一般包括主干特征提取网络、特征融合网络以及预测网络
主干特征提取网络
YOLOV5采用CSPDarknet作为特征提取网络,结构如图所示:
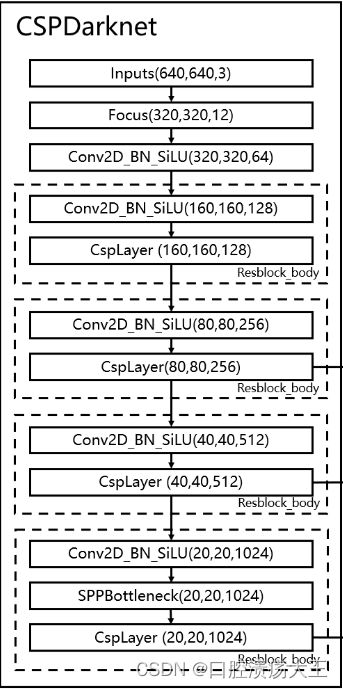
(1)Focus结构
实际上就是矩阵的切片索引操作,在每个通道上的w和h方向上分别每隔一个像素点进行取值,最终一个通道图像变成四个通道图像,最终3通道变成12通道,将图片空间信息转换到通道维度,

class Focus(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
def forward(self, x):
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
(2)Csplayer结构
借鉴了CSPnet结构,实际上是残差结构里面嵌套着残差结构,self.cv2是是大残差边,self.m是嵌套的残差结构,
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
(3)SPP结构
通过不同池化核大小的最大池化进行特征提取,提高网络的感受野。
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
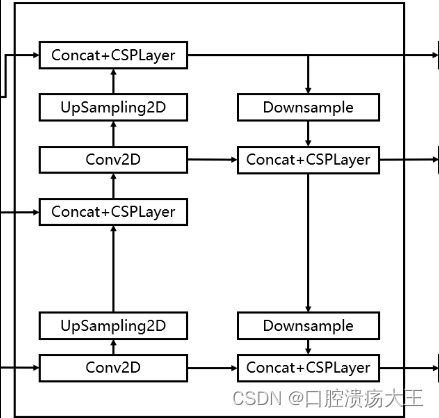
特征聚合网络
YOLOV5是采用FPN+PAN的结构进行特征聚合,将主干网络后三部分提取的特征层进行聚合,浅层特征通过下采样,与深层特征进行拼接,深层特征也会采用上采样,与浅层特征进行拼接,同时还会采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能力。
预测网络
YOLOV5采用一个卷积层得到最后的结果
yolo_head = nn.Conv2d(c1, len(anchors_mask[2]) * (5 + num_classes), 1) #最后的输出通道数为3个特征层上的预测结果,包括预测框四个参数、置信度、,所有类别的概率
3.标签分配与损失计算
标签分配主要是为检测器预测提供真实值,在目标检测中,标签分配的准则包括交并比准则、距离准则、似然估计准则、二分匹配。然后基于标签分类的结果,采用损失函数计算分类和回归等任务的损失,并利用反向传播算法更新检测网络的权重,常用的分类损失函数有交叉熵损失函数、聚焦损失函数、平滑L1损失函数‘、交并比IOU损失函数、GIOU损失函数
YOLOV5
训练时正样本的选取分为两步:寻找最优先验框;匹配特征点;
寻找最优先验框
YOLOV5在三个特征层上设置了9个先验框,用这9个先验框和GT进行宽高比的计算,将先验框宽高除以GT宽高,同时GT宽高除以先验框宽高,取二者中的大值,然后将这9个比值和提前设置好的阈值进行对比,小于阈值,就说明该先验框的大小是和真实框比较接近的,可以用来作为正样本进行训练的;
匹配特征点
我们在上一步选取了最优先验框,确定好了尺寸,但是还没有确定先验框的位置,所以我们计算真实框落在哪个网格内,则该网格的左上角特征点则为一个负责预测的特征点,同时为了增加正样本的数量,找出离真实框中心点最近的两个网格,因此一个真实框会对应三个特征点,每个特征点上的先验框大小由上一步确定。
损失计算
损失由三部分组成,回归损失、置信度损失、分类损失;
回归损失:利用网络得到的调整参数,对之前取得的先验框进行就算修正,得到预测框,利用真实框和预测框计算IOU损失;
置信度损失:根据特征点和正负样本是否包含物体计算交叉熵损失;
分类损失:根据真实框的种类和预测结果的种类计算交叉熵损失;
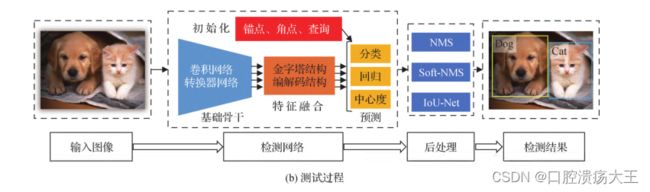
测试阶段
将测试图像输入训练好的检测网络中,得到预测结果,然后进行解码、非极大值抑制等后处理操作,最终识别出图像中存在物体的类别及位置信息;
NMS
非极大值抑制实际上跟冒泡排序原理是一样的,只不过,nms要先取出某一类别的置信度最大的那个预测框,然后将它和其他剩下的预测框进行IOU计算,如果重叠较大,则将该预测框删掉,如果重叠较小,也会同时将该框进行输出;知道所有重叠较大的预测框被剔除掉;
参考了Bubbliiiing大佬的代码和博客,十分感谢