盘点 深度学习妖怪 之 激活函数妖
盘点 深度学习妖怪 之 激活函数妖
哈哈,捉妖师的我这次给大家简单盘点一下那些在深度神经网络中兴风作浪的激活函数都有哪些妖怪吧,个个身手不凡,狡猾狡猾滴!
在此之前先给说下我们在使用神经网络的时候为啥要用到激活函数,什么?!激活函数是什么你都不知道?哈哈哈,太正常了,字面意思就是脑细胞之间相连接的树突和轴突(高中生物都没忘吧?)相当于电路中的导线。想想看你是不在肢解电子设备的时候会遇到各种五颜六色不同形状接口的线?它们的作用还千奇百怪,这就是我们要讲的激活函数了,要说它们的功能吧。。。嗯就是让脑细胞,让电子设备一下就启动,就活过来了。怎么激活?专业上讲,说的是运行在神经元之间的函数,它们将非线性引入到神经网络中(其实线性函数也是一种激活函数,也是一种激活形式,他们叫这种网络感知机,但是大家都嫌弃它笨,只会一刀切,不会拐弯,解决不了异或问题,然后它就有很多进化版本成了各种非线性形式啦),为啥要用非线性函数呢?因为有个哥们证明了如果使用非线性函数,那么神经网络可以逼近任意非线性函数,用途一下子就很广,吃得开了。但是花花世界非线性无处不在,什么样子的非线性函数好呢?在什么情况下使用什么样的激活函数效果最好?这就是本次捉妖师的我给大家要讲的内容啦!赶紧掏出不离身的小本本记下来。
再讲讲常见激活函数的一些性质,大部分激活函数具有一定的共性,也存在个性,如何要去评价一个激活函数的好坏呢?除了跑模型看结果外,大概可以参考以下介绍的几种性质:
-非线性:即导数不是常数;
-可微性:保证优化中梯度的可计算性,可以存在有限个点处不可微, 但处处subgradient;
-计算是否简单;
-非饱和性:就是在某些区间梯度接近于0,参数无法更新,饱和分为软饱和(sigmoid/tanh)和硬饱和;
-单调性:导数符号不变, 如果激活函数是单调的,单层网络可以保证是凸函数,但是这并不必须,因为神经网络本来是非凸的;
-参数计算量:激活函数有的自带参数,有的会计算原参数的k倍(没错说的就是Maxout)。
A. Sigmoid
首先介绍我们的老朋友老伙计Sigmoid(西戈莫伊),哈哈哈,想必大家对它十分熟悉了,它原本是在生物学中常见的S 型生长曲线,由于其单调递增以及反函数也递增等性质,可以用来做阈值函数,不管你什么来头先直接原子空间 一顿骚操作将变量映射(0, 1)之间。看一下公式先:
s i g m o i d ( x ) = σ ( x ) = 1 1 + e − x sigmoid(x) = \sigma(x)=\frac{1}{1+e^{-x}} sigmoid(x)=σ(x)=1+e−x1
sigmoid 函数是一个 logistic 函数 ,其图像长这样:
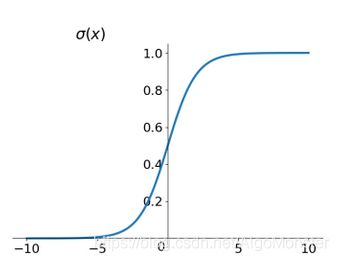
导数为:
σ ˙ ( x ) = σ ( x ) ( 1 − σ ( x ) ) \dot{\sigma}(x)=\sigma(x)(1-\sigma(x)) σ˙(x)=σ(x)(1−σ(x))
导数的图像长这样:

特点:
-梯度平滑;
-输出值在(0,1)之间;
-计算量较大;
-梯度消失:在sigmoid两侧,函数导数趋近于0,梯度趋近于0,无法更新参数;
-梯度爆炸发生概率很小:当网络权值初始化为 (1,+∞)(1,+∞) 区间内的值,则会出现梯度爆炸情况;
-输出不是0为中心;
B. Tanh
Tanh激活函数是Sigmoid的“胞弟”,很像,是一个双曲函数(大名双曲正切),是由基本双曲函数双曲正弦与双曲余弦推导而来,公式如下:
t a n h ( x ) = e x − e − x e x + e − x = 2 s i g m o i d ( 2 x ) − 1 tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}=2sigmoid(2x)-1 tanh(x)=ex+e−xex−e−x=2sigmoid(2x)−1
tanh函数的图像长这样:
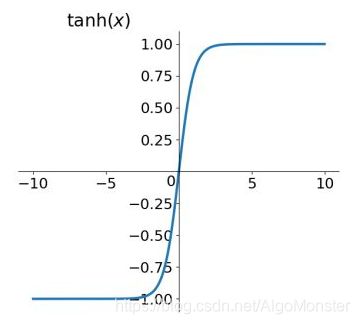
其导数为:
t a n h ( x ) ˙ = 1 − t a n h ( x ) 2 \dot{tanh(x)}=1-tanh(x)^2 tanh(x)˙=1−tanh(x)2
其导数图像长这样:

特点:
-梯度平滑;
-输出在(-1,+1)之间;
-梯度消失问题较轻(还是会饱和),收敛更快;
-输出以0为中心;
-计算量不小;
C. ReLU
ReLU(修正线性单元函数,什么鬼?)可是大家津津乐道的好妖怪,既熟悉有简单,对于深度学习刚入门的小白小青来说真是友好的不得了,哈哈,简单来回顾一下公式:
r e l u ( x ) = m a x ( 0 , x ) relu(x)=max(0,x) relu(x)=max(0,x)
图像嘛,就是感觉没啥的这个:
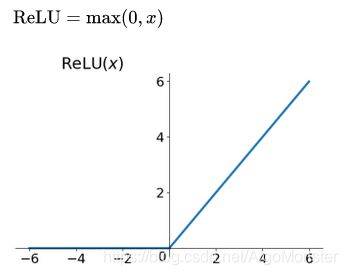
其导数公式我就不写了,也来个图吧:

特点:
-简单高效;
-不是以0为中心;
-一定程度缓解梯度消失问题(正区间内不会饱和),因为导数为1,连乘梯度不会消失(x≥0);
-负响应导致神经元dead,但是这也叫稀疏性,有时候不见得是坏事;
-如果学习率设的过大,神经元会死的很多,较小学习率会降低这种情况的发生。
D. Softplus
Softplus这个激活函数小妖怪,大家可能有的不熟悉,但是它的“辈分”可不低呢,与ReLU一起竞争过“C位”,虽然Softplus相比于ReLU更加平滑,还能保存小于0的数,可惜由于自己计算量过大,且效果真不比ReLU好,所以地位不保,不像前辈sigmoid和tanh毕竟曾今辉煌过。不过我们也来学习一下它的公式吧:
S o f t p l u s ( x ) = ln ( 1 + e x ) Softplus(x)=\ln(1+e^x) Softplus(x)=ln(1+ex)
图像长这样:
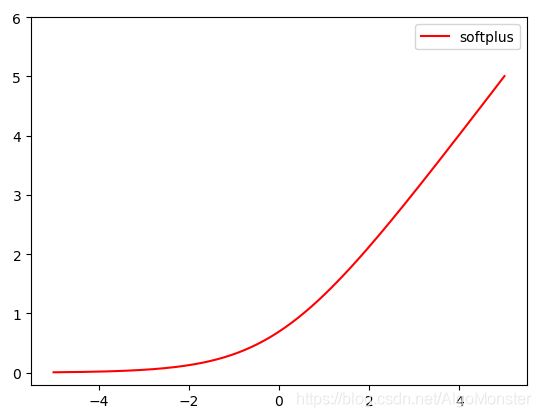
其导数是什么呢?哈哈不是别的妖怪就是前辈sigmoid函数!惊不惊喜?意不意外?!(一点都不意外,毕竟俺们可都是学过微积分的人儿),这里就不再赘述了(懒)
E. ReLU6
ReLU6就好比“山寨版”的ReLU,类似情节有真假美猴王哈哈,它是是什么呢?就是在ReLU无穷大上面加了限制约束,实验上限是6比较好(毕竟要666嘛), 这是为了在移动端设备float16的低精度的时候,也能有很好的数值分辨率,如果对ReLU的激活范围不加限制,输出范围为0到正无穷,如果激活值非常大,分布在一个很大的范围内,则低精度的float16无法很好地精确描述如此大范围的数值,带来精度损失(原来是部署工程师想偷懒,呵呵)。来看下公式:
r e l u ( x ) = m i n ( m a x ( 0 , x ) , 6 ) relu(x)=min(max(0,x),6) relu(x)=min(max(0,x),6)
函数图像及导数公式和图像就不赘述啦,相信屏幕前的你早就明白了,哈哈。
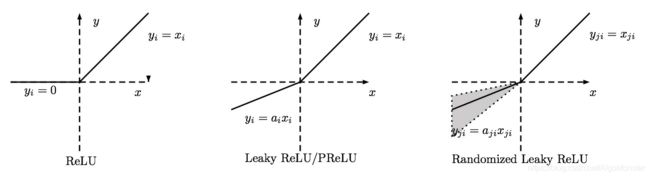
F. PReLU & RReLU & Leaky ReLU
PReLU( Parametric Rectifier ), RReLU( Randomized Leaky ReLU ) 和 Leaky ReLU,那可是形影不离的ReLU进阶版本三兄弟,彼此差别很微小到不好意思单独讲,我们先上个公式瞅瞅:
f ( x ) = m a x ( a x , x ) f(x)=max(ax, x) f(x)=max(ax,x)
当x<0时候,f(x)=αx,其中α很小,这样可以避免在x<0时,神经元dead的现象,这个就称为PReLU,α是可以学习的参数(测试时候要固定下来)。
当固定α=0.01(常用范围0.1-0.3)时(α值固定),变成Leaky ReLU。
当α服从高斯分布中随机产生时,就变成RReLU。
哈哈,感觉α怎么那么调皮?一会会变来变去换马甲。当然他们的优缺点都是类似的:
-简单,速度快,没有指数运算;
-比sigmoid/tanh前辈收敛快;
-避免神经元dead问题;
-无法避免梯度爆炸问题;
-两部分都是线性,Leaky ReLU的α还需要人工指定。
最后来张对比图感受一下:
G. CReLU
CReLU(余弦相似ReLU)这也算是新朋友啦。大家知道余弦相似度(cos距离)的概念吧?余弦相似度的取值范围在[-1, +1],越接近-1说明两个向量是负相关,越接近+1说明两个向量是正相关关系。然后有人就统计了不同层的卷积核之间的最小相似度卷积核,然后绘制出下面这幅图:(paper: http://cn.arxiv.org/abs/1603.05201 )

上图的意思就是在网络的浅层参数分布又更强的负相关性,越深这种负相关关系越弱,但是如果用ReLU不是会抹掉负响应嘛,这就不好了呀,造成卷积核冗余,一半为负的卷积核都白干了!
所以CReLU就上场了,它是怎么解决的?很简单:
C R e L U ( x ) = [ R e L U ( x ) , R e L U ( − x ) ] CReLU(x)=[ReLU(x),ReLU(-x)] CReLU(x)=[ReLU(x),ReLU(−x)]
输出维度会自动加倍,不过你观察也发现这个最好用在浅层效果较好。
H. ELU
ELU(exponential linear unit)指数线性单元,被证实有偶较高的噪声鲁棒性,同时能够使神经元的平均激活均值趋于0,但是计算量大,公式:
E L U ( x ) = { α ( e x − 1 ) , x ≤ 0 x , x > 0 ELU(x)=\begin{cases}\alpha(e^x-1),&x\le0\\x,&x>0 \end{cases} ELU(x)={α(ex−1),x,x≤0x>0
导数为:
E L U ˙ ( x ) = { E L U ( x ) + α , x ≤ 0 1 , x > 0 \dot{ELU}(x)=\begin{cases}ELU(x)+\alpha,&x\le0 \\ 1,&x>0\end{cases} ELU˙(x)={ELU(x)+α,1,x≤0x>0
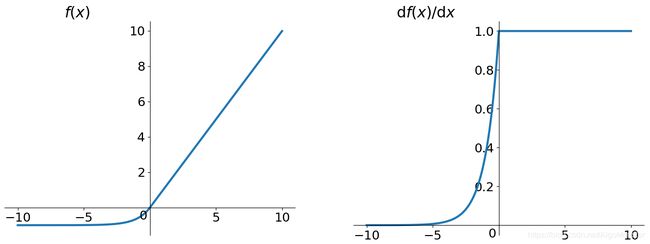
ELU为解决ReLU存在问题而存在,所以它不会有神经元dead问题,输出的均值接近0。α是不学习的。
I. SELU
SELU(扩展型指数线性单元激活函数),其实就是ELU乘上λ,且这个λ大于1,在论文《 Self-Normalizing Neural Networks》中,作者给出λ和α的值:
λ=1.0507…
α=1.67326…
这两个谜之数值可不是乱猜的,是十分复杂的推导得出的(懒得不想去推导),SELU公式及其导数如下:
S E L U ( x ) = λ { α ( e x − 1 ) , x ≤ 0 x , x > 0 SELU(x)=\lambda\begin{cases}\alpha(e^x-1),&x\le0\\x,&x>0 \end{cases} SELU(x)=λ{α(ex−1),x,x≤0x>0
S E L U ˙ ( x ) = λ { α e x , x ≤ 0 1 , x > 0 \dot{SELU}(x)=\lambda\begin{cases}\alpha e^x,&x\le0\\1,&x>0 \end{cases} SELU˙(x)=λ{αex,1,x≤0x>0
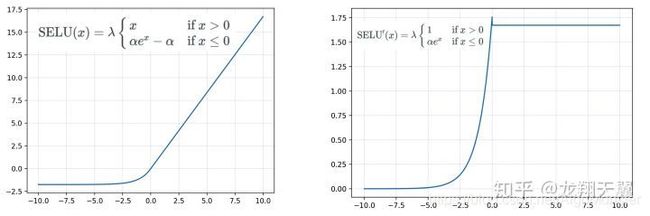
特点:
-对神经元进行自归一化(self-normalizing);
-内部归一化的速度比外部归一化快,这意味着网络能更快收敛 ;
-不太可能出现梯度消失或爆炸问题,原文提供了证明(俺也不知道咋个证明,感兴趣就去看看论文);
-计算量大,而且如果想用dropout,必须使用α-dropout版本。
J. GELU
GELU(Gaussian Error Linear Unit), 高斯误差线性单元激活函数在 Transformer 模型(谷歌的 BERT 和 OpenAI 的 GPT-2)中得到了应用。GELU在x(服从标准正态分布)的基础上乘以一个伯努利分布φ(x)=P(X≤x)。因此GELU(x)=x*P(X≤x)。
随着x降低,它被归0的概率会升高,将当前输入x在其他所有输入中的位置做参考缩放x。
但是这个函数无法直接计算,只能来逼近,所以作者得出俩逼近函数:
G E L U ( x ) = 0.5 x ( 1 + t a n h ( 2 / π ( x + 0.044715 x 3 ) ) ) GELU(x)=0.5x(1+tanh(\sqrt{2/\pi}(x+0.044715x^3))) GELU(x)=0.5x(1+tanh(2/π(x+0.044715x3)))

其导数大概长这样:
G E L U ′ ( x ) = 0.5 t a n h ( 0.0356774 x 3 + 0.797885 x ) + ( 0.0535161 x 3 + 0.398942 x ) s e c h 2 ( 0.0356774 x 3 + 0.797885 x ) + 0.5 GELU′(x)=0.5tanh(0.0356774x3+0.797885x)+ \\(0.0535161x3+0.398942x)sech2(0.0356774x3+0.797885x)+0.5 GELU′(x)=0.5tanh(0.0356774x3+0.797885x)+(0.0535161x3+0.398942x)sech2(0.0356774x3+0.797885x)+0.5
还有另一个:
x σ ( 1.702 x ) x\sigma(1.702x) xσ(1.702x)
第二个逼近函数很像之后要讲的swish,这里不再赘述。
-也是涉及指数运算,计算量大。
K. Maxout
在众多激活函数中,Maxout可算是最特别的一个了,为啥这么说呢?因为它可以看作是在神经网络中加入一层激活函数层,包含一个参数k,这一层的特殊之处在于增加了k个神经元,然后输出激活值最大的值,看一个经典的PPT介绍:
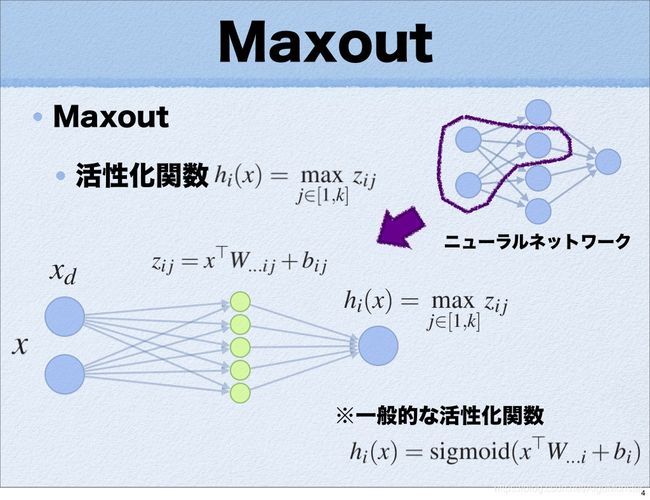
再一个与其他常规激活函数不同的是它是一个可学习的分段线性函数!
我们应该知道任何一个凸函数都可以由线性分段函数进行逼近,看一下其它函数是怎么被逼近的:

上图前两种激活函数ReLU,abs函数就可以用Maxout来逼近,k=2。
再来数一数Maxout的优缺点吧:
优点:
-拟合能力强,可以拟合任意凸函数;
-具有ReLU所有有点,线性,不饱和性;
-没有ReLU的神经元dead的缺点;
缺点:
-从PPT图像中就可以看出,参数量多增加了k倍,这样整体参数的数量噌的一下就上去了!
L. Swish
Swish是Sigmoid的改良版(google2017)或者说是ReLU的另一个改良版(ReLU竟然有这么多改良版,是有多受欢迎啊!),其计算公式是:
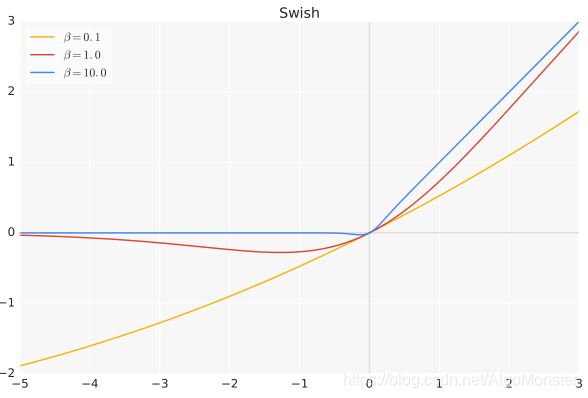
s w i s h ( x ) = x ⋅ s i g m o i d ( β x ) swish(x)=x \cdot{sigmoid(\beta x)} swish(x)=x⋅sigmoid(βx)
β 是个常数或可训练的参数,Swish具备无上界有下界、平滑、非单调的特性,且在深层模型上效果好于ReLU,当β=0时,Swish变为线性函数:
f ( x ) = x 2 f(x)=\frac{x}{2} f(x)=2x
β→∞时,σ(x)为0或1,Swish变为ReLU:
f ( x ) = 2 m a x ( 0 , x ) f(x)=2max(0, x) f(x)=2max(0,x)
所以Swish函数可以看作是介于线性函数与ReLU之间的平滑函数。
其函数图像为:
Swish的导数为:
s w i s h ( x ) ˙ = β f ( x ) + σ ( β x ) ( 1 − β f ( x ) ) \dot{swish(x)}=\beta f(x)+\sigma (\beta x)(1-\beta f(x)) swish(x)˙=βf(x)+σ(βx)(1−βf(x))
导数图像如下:

Swish很能打,是个十分优秀的激活函数,除了计算量有点大,所以才有下面要介绍的这个。
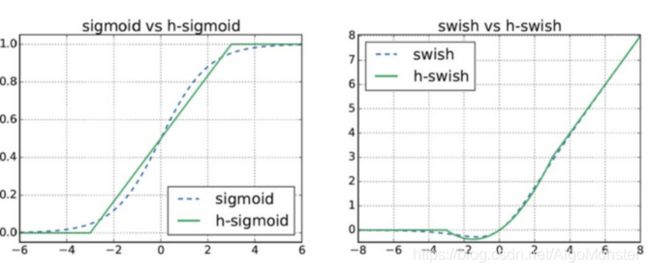
M. H-Swish
H-Swish是Swish的低精度化版本,“硬”Swish,论文称可以比使用ReLU或Swish的过滤器减少一半通道数(32→16)而达到相同的精度。这么优秀的吗?先看看其公式:
H . S w i s h ( x ) = x R e L U 6 ( x + 3 ) 6 H.Swish(x)=x\frac{ReLU6(x+3)}{6} H.Swish(x)=x6ReLU6(x+3)
其图像和sigmid,swish的比较:
N. Mish
Mish激活函数是2019年新出的激活函数(据说差点干掉Swish),有效性有待验证,类似于Swish,其公式如下:
M i s h ( x ) = x ∗ t a n h ( ln ( 1 + e x ) ) Mish(x)=x*tanh(\ln(1+e^x)) Mish(x)=x∗tanh(ln(1+ex))
图像如下:

-
Mish 函数保证在曲线上几乎所有点上的平滑度;
-
随着层深的增加,ReLU 精度迅速下降,其次是 Swish。 而 Mish 能更好地保持准确性。
等等等等,此外还有很多其他的不常用的激活函数, 比如abs函数,Noisy ReLU, Softsign,SQNL,Thresholded ReLU,Hard Sigmoid,Aria-2,Dice, 软阈值化 等等吧,这里就不一一展开讲了(懒!),当然你完全可以自己创造激活函数,只要它表现够好!哈哈哈,其实容易,也不容易。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LE2xM2Ub-1594539852283)(激活函数总览.gif)]
https://github.com/casperbh96/Activation-Functions-Search 这个开源项目可以让你测试自己想要哪个激活函数,感兴趣的童鞋可以去试试。

那么接下来,探讨几个问题:
激活函数输出是不是以0为中心
以Sigmoid函数为例,如果所有的输入均为正数或负数,那么其对输入的导数也总是正数或负数,这会导致如下图所见的阶梯式更新,显然不是一个很好的优化路径。当然,如果按照Batch去训练,输入有正有负,这个问题可以缓解,影响不是很大。

关于梯度消失和梯度爆炸问题
本质上讲,当 0
SELU进行网络自归一化
归一化首先是减去均值,然后除以标准差。因此,经过归一化之后,网络的组件(权重、偏置和激活)的均值为 0,标准差为 1。而这正是 SELU 激活函数的输出值 ,当乘或加这样的网络分量时,网络仍被视为符合高斯分布。我们就称之为归一化。SELU输出可称为内部归一化(外部归一化如BN),内部归一化速度快于外部归一化,一段论文翻译:
SELU 允许构建一个映射 g,其性质能够实现 SNN(自归一化神经网络)。SNN 不能通过(扩展型)修正线性单元(ReLU)、sigmoid 单元、tanh 单元和 Leaky ReLU 实现。这个激活函数需要有:(1)负值和正值,以便控制均值;(2)饱和区域(导数趋近于零),以便抑制更低层中较大的方差;(3)大于 1 的斜率,以便在更低层中的方差过小时增大方差;(4)连续曲线。后者能确保一个固定点,其中方差抑制可通过方差增大来获得均衡。我们能通过乘上指数线性单元(ELU)来满足激活函数的这些性质,而且 λ>1 能够确保正值净输入的斜率大于 1。
(使用SELU论文: https://arxiv.org/pdf/1905.01338.pdf )
Dead ReLU产生的原因
假设有一个神经网络的输入W遵循某种分布,对于一组固定的参数(样本),w的分布也就是ReLU的输入的分布。假设ReLU输入是一个低方差中心在+0.1的高斯分布。
在这个场景下:
- 大多数ReLU的输入是正数,因此
- 大多数输入经过ReLU函数能得到一个正值(ReLU is open),因此
- 大多数输入能够反向传播通过ReLU得到一个梯度,因此
- ReLU的输入(w)一般都能得到更新通过随机反向传播(SGD)
现在,假设在随机反向传播的过程中,有一个巨大的梯度经过ReLU,由于ReLU是打开的,将会有一个巨大的梯度传给输入(w)。这会引起输入w巨大的变化,也就是说输入w的分布会发生变化,假设输入w的分布现在变成了一个低方差的,中心在-0.1高斯分布。
在这个场景下:
- 大多数ReLU的输入是负数,因此
- 大多数输入经过ReLU函数能得到一个0(ReLU is close),因此
- 大多数输入不能反向传播通过ReLU得到一个梯度,因此
- ReLU的输入w一般都得不到更新通过随机反向传播(SGD)
激活函数选择不成熟建议:
-首先尝试ReLU,注意训练状态;
-再次尝试LReLU,或Maxout 等及其变种;
-尝试tanh;
-sigmoid/tanh在RNN(LSTM,attention, transfomer)结构中有所应用;
-浅层网络可以选择多种激活函数,影响不大;
-试试Wish?Mish?GELU等,哈哈。
参考:
Leaky ReLU论文:https://ai.stanford.edu/~amaas/papers/relu_hybrid_icml2013_final.pdf
ELU 论文:https://arxiv.org/pdf/1511.07289.pdf
SELU 论文:https://arxiv.org/pdf/1706.02515.pdf
GELU 论文:https://arxiv.org/pdf/1606.08415.pdf
https://mlfromscratch.com/activation-functions-explained/#/
https://www.cnblogs.com/makefile/p/activation-function.html
https://zhuanlan.zhihu.com/p/25110450
https://blog.csdn.net/tyhj_sf/article/details/79932893
https://liam.page/2018/04/17/zero-centered-active-function/
https://blog.csdn.net/disiwei1012/article/details/79204243
https://www.quora.com/What-is-the-dying-ReLU-problem-in-neural-networks
https://www.cnblogs.com/wzdLY/p/9710478.html
https://www.zhihu.com/question/29021768
https://www.sohu.com/a/147936491_465975
https://my.oschina.net/u/4505302/blog/3230965
关于激活函数如果存在不可微的有限点,该如何反向传播问题:
https://www.zhihu.com/question/297337220/answer/936415957
最后,该博文同步微信公众号,知乎社区,大家可以点点关注哦!直接搜索“算法妖怪”,一起来抓妖!