unet语义分割模型
Unet模型介绍
Unet可以分为三个部分,如下图所示:
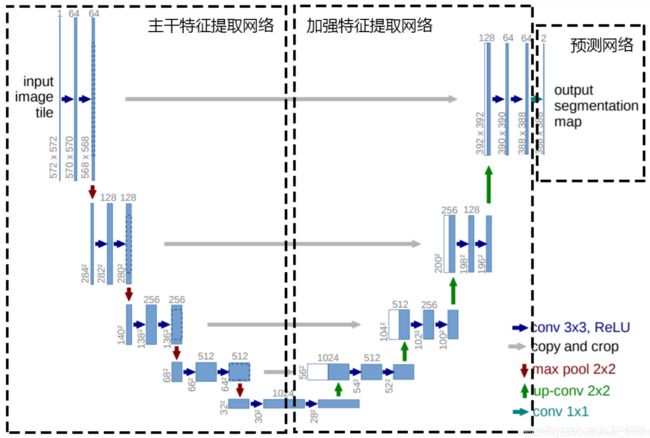
-
第一部分是主干特征提取部分,我们可以利用主干部分获得一个又一个的特征层,Unet的主干特征提取部分与VGG相似,为卷积和最大池化的堆叠。利用主干特征提取部分我们可以获得五个初步有效特征层,在第二步中,我们会利用这五个有效特征层可以进行特征融合。
-
第二部分是加强特征提取部分,我们可以利用主干部分获取到的五个初步有效特征层进行上采样,并且进行特征融合(对上采样得到的结果进行通道的堆叠),获得一个最终的,融合了所有特征的有效特征层。
-
第三部分是预测部分,我们会利用最终获得的最后一个有效特征层对每一个特征点进行分类,相当于对每一个像素点进行分类。
Unet实现思路
一、预测部分
(一)主干特征提取部分

Unet的主干特征提取部分由卷积+最大池化组成,整体结构与VGG类似。

当我们使用VGG16作为主干特征提取网络的时候,我们只会用到两种类型的层,分别是卷积层和最大池化层。
- 当输入的图像大小为512x512x3的时候,具体执行方式如下:

- VGG16代码实现(unet主干特征提取网络只使用到其中的features)
import torch
import torch.nn as nn
from torchvision.models.utils import load_state_dict_from_url
class VGG(nn.Module):
def __init__(self, features, num_classes=1000):
super(VGG, self).__init__()
self.features = features # 即构建的make_layers
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_layers(cfg, batch_norm=False, in_channels = 3):
layers = []
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']
}
def VGG16(pretrained, in_channels, **kwargs):
model = VGG(make_layers(cfgs["D"], batch_norm = False, in_channels = in_channels), **kwargs)
if pretrained:
state_dict = load_state_dict_from_url("https://download.pytorch.org/models/vgg16-397923af.pth", model_dir="./model_data")
model.load_state_dict(state_dict)
del model.avgpool
del model.classifier
return model
(二)加强特征提取结构
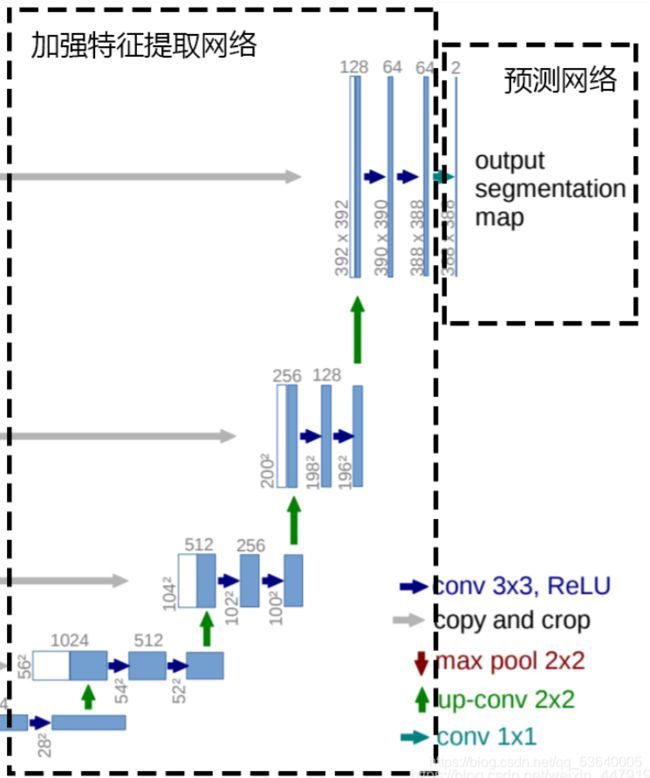
- Unet所使用的加强特征提取网络是一个U的形状。在加强特征提取网络这里,我们会利用这五个初步的有效特征层进行特征融合,特征融合的方式就是对特征层进行上采样并且进行堆叠。
- 为了方便网络的构建与更好的通用性,在上采样时直接进行两倍上采样再进行特征融合,最终获得的特征层和输入图片的高宽相同(没有crop操作)
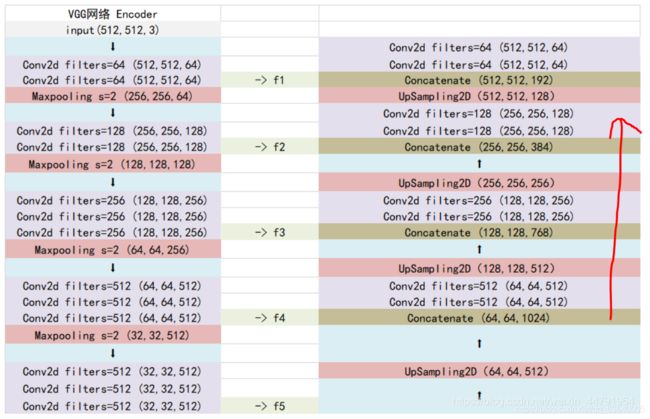
- 加强特征提取网络代码
# unet加强特征提取网络
# 特征融合——unetup(上采样 + 堆叠 + 两次卷积)
class unetUp(nn.Module):
def __init__(self, in_size, out_size):
super(unetUp, self).__init__()
self.conv1 = nn.Conv2d(in_size, out_size, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(out_size, out_size, kernel_size=3, padding=1)
self.up = nn.UpsamplingBilinear2d(scale_factor=2) # 上采样
def forward(self, inputs1, inputs2):
# inputs1和inputs2分别对应两个初步有效特征提取层
outputs = torch.cat([inputs1, self.up(inputs2)], 1) # 堆叠
# 两次卷积
outputs = self.conv1(outputs)
outputs = self.conv2(outputs)
return outputs
class Unet(nn.Module):
def __init__(self, num_classes=21, in_channels=3, pretrained=False):
super(Unet, self).__init__()
self.vgg = VGG16(pretrained=pretrained,in_channels=in_channels)
in_filters = [192, 384, 768, 1024]
out_filters = [64, 128, 256, 512]
# # upsampling(上采样) <-- 倒序
self.up_concat4 = unetUp(in_filters[3], out_filters[3]) # 64x64x512
self.up_concat3 = unetUp(in_filters[2], out_filters[2]) # 128x128x256
self.up_concat2 = unetUp(in_filters[1], out_filters[1]) # 256x256x128
self.up_concat1 = unetUp(in_filters[0], out_filters[0]) # 512x512x64
(三)利用特征获得预测结果
- 利用特征获得预测结果的过程为:利用一个1x1卷积进行通道调整,将最终特征层的通道数调整成num_classes

- 代码实现(接上面的代码)
# final conv (without any concat)
# 获得预测结果 --> 利用 1x1 卷积将最终特征层的通道数调整为num_classes
self.final = nn.Conv2d(out_filters[0], num_classes, 1)
def forward(self, inputs):
feat1 = self.vgg.features[ :4 ](inputs)
feat2 = self.vgg.features[4 :9 ](feat1)
feat3 = self.vgg.features[9 :16](feat2)
feat4 = self.vgg.features[16:23](feat3)
feat5 = self.vgg.features[23:-1](feat4)
up4 = self.up_concat4(feat4, feat5)
up3 = self.up_concat3(feat3, up4)
up2 = self.up_concat2(feat2, up3)
up1 = self.up_concat1(feat1, up2)
final = self.final(up1)
return final
def _initialize_weights(self, *stages):
for modules in stages:
for module in modules.modules():
if isinstance(module, nn.Conv2d):
nn.init.kaiming_normal_(module.weight)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.BatchNorm2d):
module.weight.data.fill_(1)
module.bias.data.zero_()
整个unet的预测过程代码实现
def letterbox_image(self ,image, size):
image = image.convert("RGB")
iw, ih = image.size
w, h = size
scale = min(w/iw, h/ih)
nw = int(iw*scale)
nh = int(ih*scale)
image = image.resize((nw,nh), Image.BICUBIC)
new_image = Image.new('RGB', size, (128,128,128))
new_image.paste(image, ((w-nw)//2, (h-nh)//2))
return new_image,nw,nh
# 检测图片
def detect_image(self, image):
# 在这里将图像转换成RGB图像,防止灰度图在预测时报错
image = image.convert('RGB')
# 对输入图像进行一个备份,后面用于绘图
old_img = copy.deepcopy(image)
# 计算输入图片的高和宽
orininal_h = np.array(image).shape[0]
orininal_w = np.array(image).shape[1]
# letterbox_image进行不失真的resize,添加灰条
image, nw, nh = self.letterbox_image(image,(self.model_image_size[1],self.model_image_size[0]))
images = [np.array(image)/255] # 进行图像归一化,然后加上batch_size的维度
images = np.transpose(images,(0,3,1,2)) # 将batch_size后的通道转到第一维度
# 图片传入网络进行预测
with torch.no_grad():
images = torch.from_numpy(images).type(torch.FloatTensor)
if self.cuda:
images =images.cuda()
pr = self.net(images)[0]
# permute将通道转到最后一维,然后softmax取出每一个像素点对应的最大概率的种类
pr = F.softmax(pr.permute(1,2,0),dim = -1).cpu().numpy().argmax(axis=-1)
# 将灰条部分截取掉
pr = pr[int((self.model_image_size[0]-nh)//2):int((self.model_image_size[0]-nh)//2+nh), int((self.model_image_size[1]-nw)//2):int((self.model_image_size[1]-nw)//2+nw)]
# 创建一副新图,并根据每个像素点的种类赋予颜色
seg_img = np.zeros((np.shape(pr)[0],np.shape(pr)[1],3))
for c in range(self.num_classes):
seg_img[:,:,0] += ((pr[:,: ] == c )*( self.colors[c][0] )).astype('uint8')
seg_img[:,:,1] += ((pr[:,: ] == c )*( self.colors[c][1] )).astype('uint8')
seg_img[:,:,2] += ((pr[:,: ] == c )*( self.colors[c][2] )).astype('uint8')
# 将新图片转换成Image的形式
image = Image.fromarray(np.uint8(seg_img)).resize((orininal_w,orininal_h))
# 将新图片和原图片混合
if self.blend:
image = Image.blend(old_img,image,0.7)
训练
训练参数
if __name__ == "__main__":
log_dir = "logs/"
inputs_size = [512,512,3] # 输入图片的大小
NUM_CLASSES = 21 # 分类个数+1
# 种类少(几类)时,设置为True
# 种类多(十几类)时,如果batch_size比较大(10以上),那么设置为True
# 种类多(十几类)时,如果batch_size比较小(10以下),那么设置为False
dice_loss = False
pretrained = False # 主干网络预训练权重的使用
Cuda = True # Cuda的使用
dataset_path = "VOCdevkit/VOC2007/" # 数据集路径
model = Unet(num_classes=NUM_CLASSES, in_channels=inputs_size[-1], pretrained=pretrained).train()
loss_history = LossHistory("logs/")
model_path = r"model_data/unet_voc.pth" # 权值和主干特征提取网络一定要对应
print('Loading weights into state dict...')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model_dict = model.state_dict()
pretrained_dict = torch.load(model_path, map_location=device)
pretrained_dict = {k: v for k, v in pretrained_dict.items() if np.shape(model_dict[k]) == np.shape(v)}
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict)
print('Finished!')
if Cuda:
net = torch.nn.DataParallel(model)
cudnn.benchmark = True
net = net.cuda()
# 打开数据集的txt
with open(os.path.join(dataset_path, "ImageSets/Segmentation/train.txt"),"r") as f:
train_lines = f.readlines()
# 打开数据集的txt
with open(os.path.join(dataset_path, "ImageSets/Segmentation/val.txt"),"r") as f:
val_lines = f.readlines()
# 主干特征提取网络特征通用,冻结训练可以加快训练速度,也可以在训练初期防止权值被破坏
if True:
lr = 1e-4
Init_Epoch = 0 # Epoch为总训练世代,Init_Epoch为起始世代
Interval_Epoch = 50 # Interval_Epoch为冻结训练的世代
Batch_size = 2 # 提示OOM或者显存不足请调小Batch_size
optimizer = optim.Adam(model.parameters(),lr)
lr_scheduler = optim.lr_scheduler.StepLR(optimizer,step_size=1,gamma=0.92)
train_dataset = DeeplabDataset(train_lines, inputs_size, NUM_CLASSES, True, dataset_path)
val_dataset = DeeplabDataset(val_lines, inputs_size, NUM_CLASSES, False, dataset_path)
gen = DataLoader(train_dataset, batch_size=Batch_size, num_workers=4, pin_memory=True,
drop_last=True, collate_fn=deeplab_dataset_collate)
gen_val = DataLoader(val_dataset, batch_size=Batch_size, num_workers=4,pin_memory=True,
drop_last=True, collate_fn=deeplab_dataset_collate)
epoch_size = len(train_lines) // Batch_size
epoch_size_val = len(val_lines) // Batch_size
if epoch_size == 0 or epoch_size_val == 0:
raise ValueError("数据集过小,无法进行训练,请扩充数据集。")
for param in model.vgg.parameters():
param.requires_grad = False
for epoch in range(Init_Epoch,Interval_Epoch):
fit_one_epoch(model,epoch,epoch_size,epoch_size_val,gen,gen_val,Interval_Epoch,Cuda)
lr_scheduler.step()
if True:
lr = 1e-5
Interval_Epoch = 50
Epoch = 100
Batch_size = 2
optimizer = optim.Adam(model.parameters(),lr)
lr_scheduler = optim.lr_scheduler.StepLR(optimizer,step_size=1,gamma=0.92)
train_dataset = DeeplabDataset(train_lines, inputs_size, NUM_CLASSES, True, dataset_path)
val_dataset = DeeplabDataset(val_lines, inputs_size, NUM_CLASSES, False, dataset_path)
gen = DataLoader(train_dataset, batch_size=Batch_size, num_workers=4, pin_memory=True,
drop_last=True, collate_fn=deeplab_dataset_collate)
gen_val = DataLoader(val_dataset, batch_size=Batch_size, num_workers=4,pin_memory=True,
drop_last=True, collate_fn=deeplab_dataset_collate)
epoch_size = len(train_lines) // Batch_size
epoch_size_val = len(val_lines) // Batch_size
if epoch_size == 0 or epoch_size_val == 0:
raise ValueError("数据集过小,无法进行训练,请扩充数据集。")
for param in model.vgg.parameters():
param.requires_grad = True
for epoch in range(Interval_Epoch,Epoch):
fit_one_epoch(model,epoch,epoch_size,epoch_size_val,gen,gen_val,Epoch,Cuda)
lr_scheduler.step()