字节青训营第十三课之深入浅出RPC框架的笔记与总结.md
基本概念
本地函数调用
函数调用完整过程如图,藏实际上编译器经常优化,参数和返回值少时直接将其存在寄存器,不需操作栈,直接online不需call:
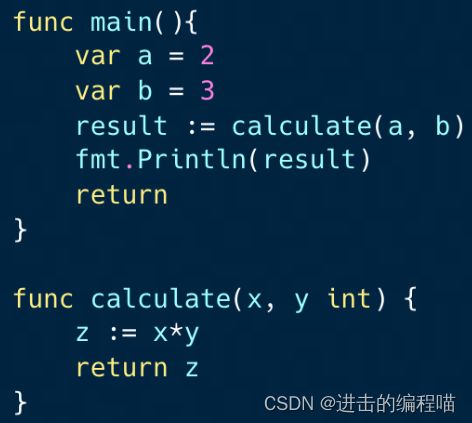
- 将a和b的值入栈
- 经函数指针找到calculate,进入函数取栈中值2和3赋给x和y
- 计算x*y并将结果存在z
- 将z的值压栈,再从calculate返回
- 从栈中取出z返回值付给result
远程函数调用
RPC需解决的问题:
- 函数映射
远程调用无法根据函数指针确定函数,因为两进程地址空间完全不同,因此函数都有自己的ID,做RPC时都要附上该ID,且要有ID和函数的对照关系表,以此经ID找到函数并执行
- 客户端如何传参给远程函数
本地只需参数入栈,函数自己去栈中读,但远程调用时,客户和服务端进程不同不能经内存传参,需客户端把参数先转成字节流,传给服务端后,在把字节流转成自己能读取的格式
- 网络传输
远程调用往往在网络上,需保证网络上高效稳定传输数据
RPC概念模型
RPC最早由Nelson发表的论文<
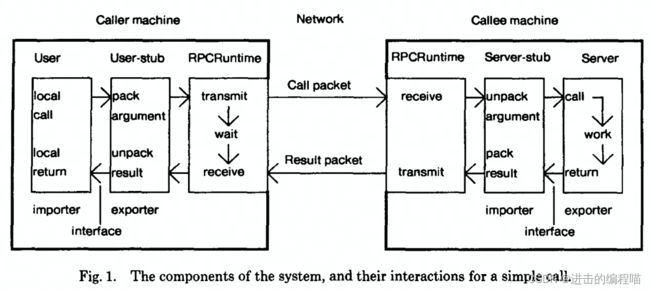
一次RPC完整过程
一次RPC的完整过程包括IDL文件、生成代码、编解码、通信协议、网络传输。如图:

- IDL文件:通过中立的方式描述接口(方法和参数),使不同平台运行对象和不同语言的程序可相互通信
- 生成代码:编译器工具把IDL文件转成语言对应的静态库
- 编解码:从内存中表示到字节序列的转换称为编码,反之为解码,也叫序列化和反序列化
- 通信协议:规范数据在网络中的传输内容和格式,除必须的请求/响应数据外,通常还包含额外的元数据
- 网络传输:通常基于成熟网络库走TCP/UDP传输
RPC的好处
- 单一职责,有利于分工协作和运维开发,开发部署及运维都独立
- 可扩展性强,资源使率更优,如压力大时扩展资源,底层基础服务可复用
- 故障隔离,某个模块发生故障不影响整体可靠性,服务的整体可靠性更高
RPC带来的问题
当然RPC也带来很多问题:
- 假如服务宕机,对方如何处理
- 调用过程中发生网络异常,如何保证消息可达性
- 请求量突增导致服务无法及时处理,应对措施有哪些
分层设计
以Apache Thrift为例,分层如图:

编解码层
编解码层中客户端和服务端都依赖IDL文件,生成不同语言的CodeGen,如C++和Golang等
-
数据格式包括三种:
- 语言特定格式:很多编程语言内置的将内存对象编码为字节序列的支持,但通常与特定编程语言深度绑定,其他语言很难读取,同时可能有安全和兼容性问题
- 文本格式:有较好人类可读性,如json、xml、csv等文本格式,但编码会有歧义,如xml和csv不能区分数字和字符串,json虽然可区分,但不区分整数和浮点数且不能指定精度,json需反射机制故性能较差
- 二进制编码:跨语言和高效能的优点,实现可有TLV和Varint编码,常用Protobuf和Thrift的BinaryProtocol
-
二进制编码
- TLV编码:Tag标签,理解为类型;Length长度;Value值,也可是个TLV结构。如图:首个byte是类型如string、int、list,其次是field tag而不是字符串如userName等,取代key,后续分别是长和值。尽管TLV简单扩展性好,但增加Type和Length两冗余信息,有内存开销因此也有Varint编码,不详叙
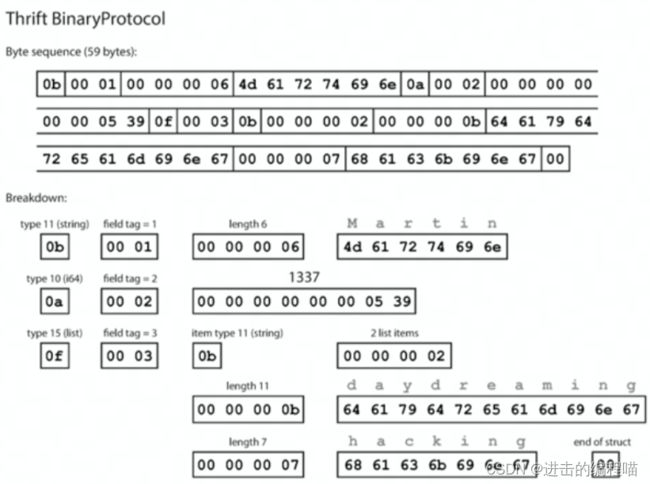
- TLV编码:Tag标签,理解为类型;Length长度;Value值,也可是个TLV结构。如图:首个byte是类型如string、int、list,其次是field tag而不是字符串如userName等,取代key,后续分别是长和值。尽管TLV简单扩展性好,但增加Type和Length两冗余信息,有内存开销因此也有Varint编码,不详叙
-
选型:从三个层面考虑选型:兼容性、通用性、性能
- 兼容性:支持自动增加新字段而不影响老服务,这件提高系统灵活度以适应需求的变化
- 通用性:技术层面是否支持跨平台、跨语言,流程程度,使用少的协议意味着高成本学习,流行度低往往缺乏成熟跨语言、跨平台公共包
- 性能:空间开销,序列化需在原有数据上加描述字段,以反序列化解析,若开销过高可能导致网络磁盘压力,时间开销,复杂协议解析需较长时间
协议层
协议是双方确定的通信的语义。包括两种:
- 特殊结束符协议:特殊字符作为协议单元结束的标示,如http协议头以回车和换行符号作为结束标示
- 变长协议:定长和变长部分组成,定长部分需描述不定长内容长度
下图是变长协议,除长度和内容外,还包括其他内容如版本信息、数据包序列化等:

协议解析包括以下几部分:

网络通信层
通信流程
底层通过socket api进行通信:
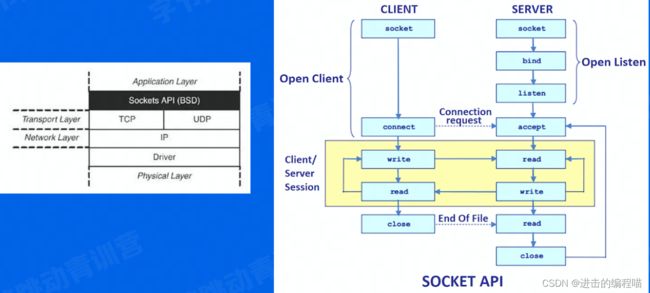
socket API
socket创建套接字,bind将套接字绑定到地址,listen监听进来的连接,参数backlog指定挂起的连接队列的长度,当客户端连接时,服务器可能正处理其他逻辑而未调accept接受连接,会导致该连接被挂起,内核维护挂起的连接队列,accept从队列中取出连接请求并接收它,该连接从挂起队列移除。若队列未满,调用connect马上成功,若满可能会阻塞等待队列未满(实际测试并不是这样后面专门研究)。backlog默认128,通常指定128即可。connect客户端向服务器发起连接,accept接收一个连接请求。得到客户端的fd后,可调read,write和客户端通讯,read/write从fd读/写数据,socket默认阻塞,如果对方没有写/读数据,read/write会一直阻塞
对端socket关闭后,这端尝试去读会得到一个EOF并返回0。去写会触发SIGPIPE信号并返回-1和errno=EPIPE,SIGPIPE默认终止程序,故通常应忽略该信号,以免程序终止。但如果这端不读写,可能无法知道对端socket关闭
网络库
- 提供易用API,封装底层socket API,连接管理和事件分发
- 协议支持tcp、udp等,支持优雅退出异常处理等功能
- 应用层buffer减少copy,支持高性能定时器、对象池等以满足性能要求
关键指标
稳定性
保障策略
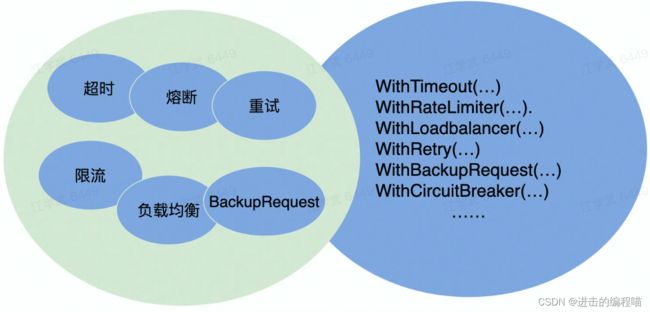
稳定性是保障策略,包括熔断、限流、超时三方面,某种程度上说,超时、限流、熔断也是服务降级手段:
- 熔断:保护调用方,防止被调用服务出现问题影响整个链路。如A调服务B时,B又调C,若C响应超时,C超时导致B业务一直等待,A继续调B,服务8就可能堆积大量的请求而导致宕机,由此导致服务雪崩
- 限流:保护被调用方,防止大流量把服务压垮,当调用端发请求过来时,服务端在执行业务逻辑前先检查限流逻辑,若访问量过大且超出限流条件,就让服务端降级或返回给调用方限流异常
- 超时:当下游服务因某种原因响应过慢,下游服务主动停掉不太重要的业务,释放服务器资源避免浪废
请求成功率
为提高请求成功率,有负载均衡和重试方法,前者根据服务集群情况,通过算法将请求分发给空闲的服务器,使所有服务器负载处于平衡状态。后者重新请求看是否成功,但重试会加大下游负载,可能放大故障风险,防止重试风暴,应限制单点重试和限制链路重试
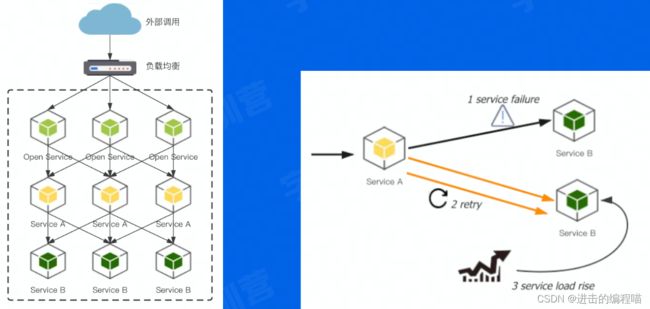
长尾请求
一般指延迟明显高于均值的那部分占比较小的请求。P99标准把单个请求响应耗时从小到大排序,99%后的1%可认为是长尾请求。在复杂系统中,长尾延时总会存在。造成的原因有网络抖动、GC、系统调度
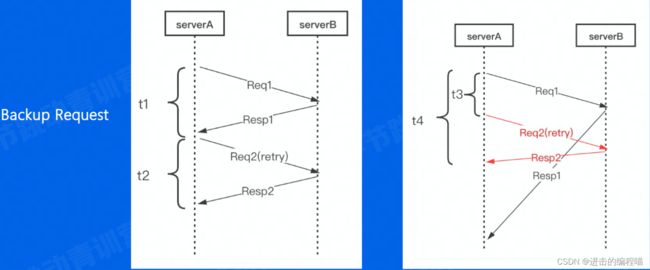
假定阈值t3(比超时时间小,通常建议是RPC求延时的pct99),Req1发出去后超过t3时间没返回,就直接发起重试Req2,相当于同时两个请求运行。等待请求返回,只要Resp1或Resp2任意返回成功,就可立即结束,整体的耗时是t4,表示首个请求发出到成功返回之间的时间,相比等待超时后再请求,该机制大大减少整体延时
注册中间件
上述提到的策略及请求成功率、长尾请求都可通过中间件实现,Kitex Client和Server的创建接口均采用Option模式,提供极大灵活性,很方便就能实现
易用性
- 开箱即用:合理的默认参数选项、丰富的文档
- 周边工具:生成代码工具、脚手架工具
Kitex使用Suite来打包自定义功能,提供一键配置基础依赖的体验,简单易用,支持protobuf和thrift,内置功能丰富选项,支持自定义生成代码插件等
扩展性
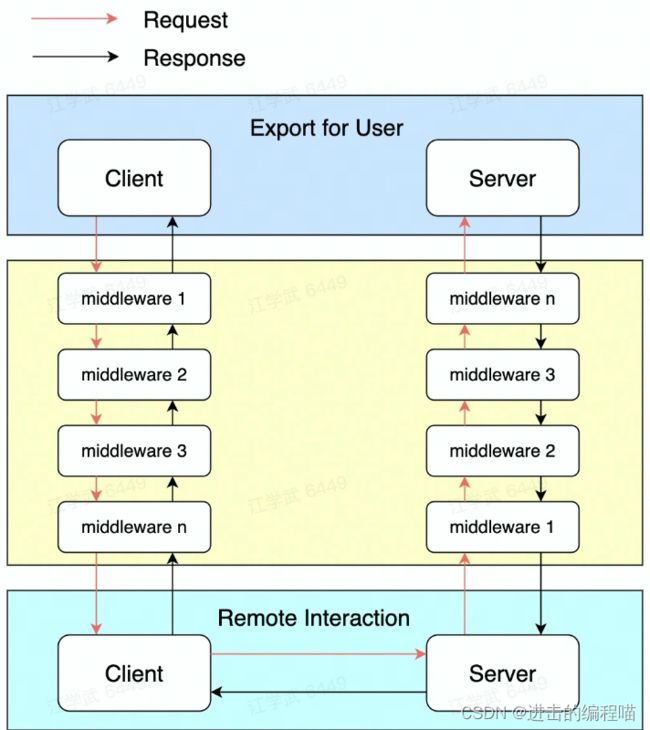
请求发起会首先经过治理层面,治理相关逻辑被封装在middleware中,这些middleware会被构造成有序调用链逐个执行,如服务发现、路由、负载均衡、超时控制等,执行后进入remote模块,完成通信
观测性
除传统的Log、Metric、Tracing三件套外,对于框架来说可能还不够,还有些框架自身状态需暴露出来,如当前环境变量、配置、CIient/Server初始化参数、缓存信息等
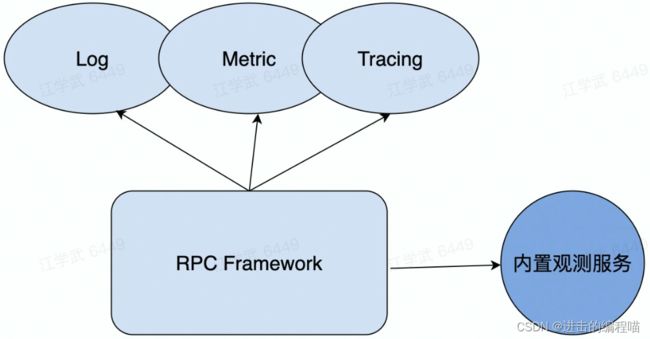
高性能
高性能场景:单机多机、单连接多连接、单/多client 单/多server、不同大小请求包、不同请求类型
目标:高吞吐和低延迟,两者都重要甚至大部分场景下低延迟更重要
手段:连接池、多路复用、高性能编解码协议、高性能网络库
企业实践
以Kitex为例,它是字节内部多年最佳时间沉淀出来的高性能可扩展性的go rpc框架,难能可贵的是以大型互联网公司内部的实践经验为例,拓展技术视野
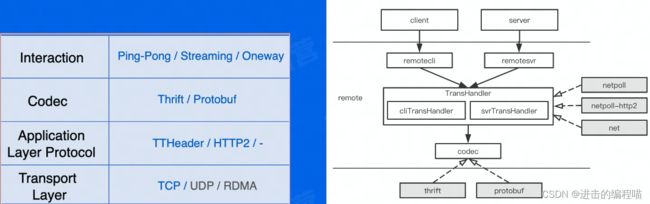
整体架构

core是核心组件,是主干逻辑,定义框架层次结构、接口及默认实现,最上面的client和server对用户暴露,下面的是框架治理层面的功能模块和交互元信息,remote是与对端交互的模块,包括编解码和网络通信。右边绿色的byted是字节内部的扩展,集成内部的二方库还有与字节相关的非通用的实现,byted部分是在生成代码中初始化client和server时通过suite集成进来的,方便与字节内部特性解耦,方便后续开源拆分,右边tool则是与生成代码相关的实现,包括id解析、校验、代码生成、插件支持、自更新等
自研网络库
背景
- 原生库无法感知连接状态:使用连接池时,池中存在失效连接,影响连接池的复用
- 原生库存在goroutine暴涨的风险
一个连接一个goroutine的模式,由于连接利用率低下,存在大量goroutine占用调度开销,影响性能
自研网络库Netpoll
Go Net VS Netpool
- GoNet使用Epoll ET,Netpoll使LT
- Netpoll在大包场景下占更多的内存
- GoNet只有一个EpoII事件循环(因为ET模式被唤醒的少,且事件循环内无需负责读写活少),而Netpoll允许有多个事件循环(循环内需要负责读写活多,读写越重,越需要开更多Loops)
- GoNet一个连接一个Goroutine,Netpoll连接数和Goroutine数量无关,和请求数有关,但是有Gopool
- GoNet不支持ZeroCopy,甚至若用户想实现BufferdConnection这类缓存读取,还会产生二次拷贝。Netpoll支持管理一个Buffer池直接交给户,且上层用户可不使用Read(p []byte)接口而使用特定零拷贝读取接口,对Buffer管理,实现零拷贝能力的传涕
Netpoll
- 解决无法感知连接状态问题:Go Net无法感知连接状态,在用长连接池时,池中存在失效连接,严重影响连接池的使和效率。Netpoll引入epoll主动监听机制,感知连接状态
- 解决goroutine暴涨的风险:Go Net缺乏协程数量的管理,Kite采取一个连接一个goroutine模式,连接利用率低,存在较多无用goroutine,占用调度开销影响性能,Netpoll建立goroutine池,复用goroutine
- 提升性能:Netpoll基于epoll的Reactor模型,服务端主从Reactor模型,主reactor接受调用端的连接,将建立好的连接注册到某从Reactor上,从Reactor负责监听连接上的读写事件,将事件分发到协程池处理;引入NocopyBuffer,向上层提供NoCopy的调用接口,编解码层面零拷贝
扩展性设计
支持多协议,也支持灵活自定义协议扩展
框架内部不强依赖任何协议和网络模块,可基于接口扩展,在传输层上则可集成其他库进行扩展,目前集成有自研的Netpoll,基于netpoll实现http2库
性能优化
- 调度优化:epoll_wait在调度上的控制;gopool重用goroutine降低同时运行协程数
- LinkBuffer:读写并行无锁,支持nocopy地流式读写;高效扩缩容;NocopyBuffer池化,减少GC
- Pool:引入内存池和对象池,减少GC开销
- Codegen:预计算并预分配内存,减少内存操作次数,包括内存分配和拷贝;lnline减少函数调用次数和避免不必要的反射操作等;自研Go语言实现的Thrift IDL解析和代码生成器,支持完善的Thrift IDL语法和语义检查,并支持插件机制-Thriftgo
- JIT:使用JIT编译技术改善用户体验的同时带来更强的编解码性能,减轻用户维护生成代码的负担;基于JIT编译技术的高性能动态Thrift编解码器-Frugal
合并部署
微服务过微,传输和序列化开销越来越大;将亲和性强的服务实例尽可能调度到同一个物理机,远程RPC调用优化为本地IPC调用
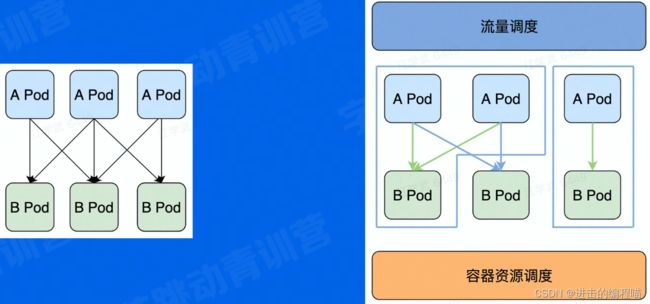
- 中心化的部署调度和流量控制
- 基于共享内存的通信协议
- 定制化的服务发现和连接池实现
- 定制化的服务启动和监听逻辑
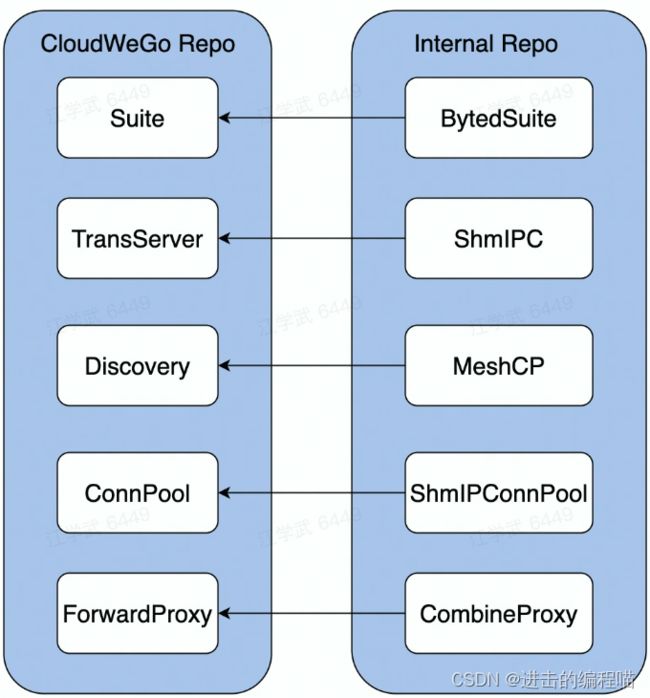
某抖音服务,30%合并流量,服务端CPU减少19%,延迟PCT99减少29%
参考文献
-
官方文档 Kitex Netpoll
-
字节跳动 Go RPC 框架 KiteX 性能优化实践_架构_字节跳动技术团队_InfoQ精选文章
-
[字节跳动微服务架构体系演进_架构_字节跳动技术团队_InfoQ精选文章](