【论文学习笔记】《Tacotron: Towards End-To-End Speech Synthesis》
Tacotron 论文学习
文章目录
- Tacotron 论文学习
-
- 摘要
- 1 简介
- 2 相关工作
- 3 模型架构
-
- 3.1 CBHG模块
- 3.2 编码器
- 3.3 解码器
- 3.4 后置处理网络与波形合成
- 4 模型细节
- 5 实验
-
- 5.1 烧蚀分析
- 5.2 平均意见得分测验
- 6 讨论
摘要
文本-语音合成系统通常由多个阶段组成,例如文本分析前端、声学模型和音频合成模块。构建这些组件通常需要广泛的领域专业知识,并可能包含脆弱的设计选型。
在本文中,我们提出了 Tacotron ,一个端到端生成文本到语音模型,直接从字符合成语音。
给出 <文本,音频> 数据对,通过随机初始化,模型可以完全从零开始训练。
我们提出了几个关键的技术,使序列到序列框架在这一具有挑战性的任务中表现良好。
Tacotron 在美式英语的主观五级平均意见得分为 3.82 分,在自然度方面优于产品参数化系统。
此外,由于 Tacotron 在帧级生成语音,它实质上比样本级自回归方法快。
1 简介
现代文本到语音( TTS )管道非常复杂(《Text-to-speech synthesis》)。
例如,统计参数 TTS 通常具有提取各种语言特征的文本前端、持续时间模型、声学特征预测模型和基于复杂信号处理的声码器(《Vocaine the vocoder and applications in speech synthesis》)。
这些组件基于广泛的领域专家知识,设计起来很费力。
它们也是独立训练的,所以每个成分的错误可能会复合。
现代 TTS 设计的复杂性导致在构建新系统时需要大量的工程成本。
因此,集成的端到端 TTS 系统有许多优点,可以在文本、音频对上使用最少的人工注释进行训练。
首先,这样的系统减轻了费力的特征工程的需要,这可能涉及启发式和脆弱的设计选择。
其次,它更容易允许对各种属性进行丰富的条件设置,比如说话者或语言,或者像情绪这样的高级特性。
这是因为条件作用可以发生在模型的最开始,而不是只发生在某些组件上。
同样,适应新数据也可能更容易。
最后,单个模型可能比多阶段模型更有鲁棒性,在多阶段模型中,每个组成部分的误差可能复合。
这些优势意味着端到端模型可以让我们在现实世界中发现的大量丰富、富有表现力但经常有噪声的数据上进行训练。
TTS 是一个大规模的反问题:一个高度压缩的源(文本)被解压成音频。
由于相同的文本可能对应不同的发音或说话风格,这对端到端模型来说是一项特别困难的学习任务:它必须应对给定输入信号水平上的巨大变化。
此外,与端到端语音识别(《Listen, attend and spell: A neural network for large vocabulary conversational speech recognition》)或机器翻译(《Google s neural machine translation system: Bridging the gap between human and machine translation》)不同, TTS 输出是连续的,输出序列通常比输入序列长得多。
这些属性会导致预测错误迅速累积。
在本文中,我们提出了一种基于序列对序列(seq2seq) (《Sequence to sequence learning with neural networks》)和注意范式(《Neural machine translation by jointly learning to align and translate》)的端到端生成 TTS 模型 Tacotron 。
我们的模型以字符作为原始谱图的输入和输出,使用了几种技术来提高 vanilla seq2seq 模型的能力。
给定<音频, 文本>对, Tacotron 可以完全从头开始随机初始化训练。
它不需要音素水平的校准,所以它可以很容易地扩展到使用大量的声学数据与转录本。
使用简单的波形合成技术, Tacotron 在一个美式英语评估集上产生 3.82 的平均意见得分( MOS ),在自然度方面优于参数生产系统。
2 相关工作
WaveNet 是一个强大的音频生成模型。它的 TTS 表现很好,但由于它的样本水平自回归性质,速度很慢。它还需要适应现有 TTS 前端的语言特征,因此不是端到端的。它只能取代声码器和声学模型。
另一个最近开发的神经模型是 DeepVoice ,它用相应的神经网络替换典型 TTS 管道中的每个组件。但是,每个组件都是独立训练的,所以将系统更改为以端到端的方式进行训练是很重要的。
据我们所知,《端到端参数化TTS合成的第一步:利用神经注意力生成光谱参数》是最早关注使用 seq2seq 进行端到端 TTS 的工作。然而,它需要一个预先训练的隐马尔可夫模型对齐器来帮助 seq2seq 模型学习对齐。很难说 seq2seq 本身学习了多少对齐。其次,一些技巧被用来训练模型,作者认为这损害了韵律。再者,它预测声码器参数,因此需要声码器。此外,该模型是根据音素输入进行训练的,实验结果似乎有一定的局限性。
Char2Wav 是一个独立开发的端到端模型,可以对字符进行训练。然而,在使用 SampleRNN 神经声码器之前, Char2Wav 仍然可以预测声码器参数,而 Tacotron 可以直接预测原始谱图。另外,他们的 seq2seq 和 SampleRNN 模型需要分别进行预训练,而我们的模型可以从头开始训练。最后,我们对普通的 seq2seq 范式做了几个关键的修改。如后文所示,普通的 seq2seq 模型不适用于字符级输入。
3 模型架构
Tacotron 的主干是一个具有注意力的 seq2seq 模型(《神经机器翻译通过共同学习对齐和翻译》、《用递归神经网络进行序列预测的调度采样》)
下图描述了这个模型,它包括一个编码器、一个基于注意力的解码器和一个后处理网络。
在高层次上,我们的模型接受字符作为输入,并产生频谱图帧,然后转换成波形。我们在后文描述这些组件。
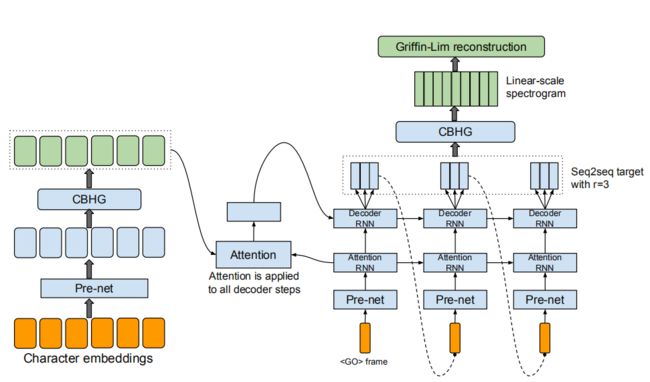
该模型以字符为输入,输出相应的原始声谱图,然后输入Griffin-Lim重构算法进行语音合成
3.1 CBHG模块
我们首先描述一个称为 CBHG 的构建块,如下图所示。

CBHG 包括一组一维卷积滤波器,接着是 Highway Networks (《Highway Networks》)和双向门控回归单元(GRU) (《Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling》)回归神经网络(RNN)。
CBHG 是一个从序列中提取表示的强大模块。
输入序列首先与 K 组1维卷积滤波器进行卷积,其中第 K 组包含宽度为 K 的 Ck 滤波器(即K = 1,2,…K);这些过滤器显式地建模局部和上下文信息(类似于建模 unigrams 、 bigrams 到 K-grams );卷积输出被堆叠在一起,并且随着时间的推移进一步最大地汇集以增加局部不变性。
我们进一步将处理后的序列传递给几个固定宽度的一维卷积,这些卷积的输出通过剩余连接与原始输入序列相加。(《 Deep residual learning for image recognition》)
批处理归一化(《Batch normalization: Accelerating deep network training by reducing internal covariate shift》)用于所有卷积层。卷积输出被输入到一个多层高速公路网络中,以提取高级特征
最后,我们将一个双向 GRU RNN 叠加在上面,从正向和反向上下文中提取序列特征。
CBHG 的灵感来自于机器翻译(《 Fully character-level neural machine translation without explicit segmentation》),其中的主要区别包括使用非因果卷积、批处理标准化、剩余连接和 stride=1 最大池化。
我们发现这些修改改善了泛化。
3.2 编码器
该编码器的目标是提取鲁棒的文本序列表示。
编码器的输入是一个字符序列,其中每个字符都表示为一个独热向量,并嵌入到一个连续向量中。
然后我们对每个嵌入应用一组非线性转换,统称为“预网络”。
在本研究中,我们使用了一个带有 dropout 的瓶颈层作为预网络,这有助于收敛和提高泛化能力。
CBHG 模块将前置网络的输出转换为注意模块使用的最终编码器表示。
我们发现,这种基于 CBHG 的编码器不仅减少了过拟合,而且比标准的多层 RNN 编码器的发音错误更少。
3.3 解码器
我们使用基于内容的tanh注意力解码器(《Grammar as a Foreign Language》),其中有状态循环层在每个解码器时间步长产生注意力查询。
我们将上下文向量和注意力 RNN 细胞输出连接起来,形成 RNN 解码器的输入。我们使用带有垂直剩余连接的 GRUs 堆栈(《Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation》)作为解码器。
我们发现残余连接可以加快收敛速度。解码器目标是一个重要的设计选择。
虽然我们可以直接预测原始谱图,但对于学习语音信号和文本对齐的目的来说,这是一个高度冗余的表示(这正是使用 seq2seq 进行这项任务的真正动机)。
由于这种冗余,我们使用不同的目标来进行 seq2seq 解码和波形合成。只要 seq2seq 目标为反转过程提供足够的可理解性和韵律信息,就可以对其进行高度压缩,这些信息可以被修复或训练。
我们使用 80 波段的 mel 尺度谱图作为目标,但可以使用更少的波段或更简洁的目标,如倒谱。我们使用后处理网络将 seq2seq 目标转换为波形。
我们使用一个简单的全连接输出层来预测解码器的目标。我们发现的一个重要技巧是在每个解码器步骤中预测多个、不重叠的输出帧。
一次预测 r 帧将解码器的总步长除以 r ,这减少了模型大小、训练时间和推理时间。更重要的是,我们发现这个技巧可以大幅提高收敛速度,这可以通过从注意力中学到的更快也更稳定的对齐来衡量。
这可能是因为相邻的语音帧是相关的,每个字符通常对应多个帧。每次发出一帧迫使模型在多个时间步处理相同的输入令牌;发出多个帧可以让注意力在训练早期向前移动。
解码器的第一步是在全零帧条件下进行的,该帧表示一个
注意,提供最后一个预测是一个特别的选择,这里我们可以使用所有的r预测。
在训练过程中,我们总是将每一个r-th地面真值帧发送给解码器。
由于我们不使用预定采样等技术(《Scheduled sampling for sequence prediction with recurrent neural networks》)(我们发现这会损害音频质量),预网络中的 dropout 对于模型的推广至关重要,因为它提供了一个噪声源来解决输出分布中的多个模态。
3.4 后置处理网络与波形合成
如上文所述,后处理网络的任务是将 seq2seq 目标转化为可以合成成波形的目标。由于我们使用 Griffin-Lim 作为合成器,后处理网络学习预测在线性频率尺度上采样的光谱幅度。
使用后处理网络的另一个动机是它可以看到完整的解码序列。
与总是从左到右运行的 seq2seq 不同,它同时有向前和向后的信息来纠正每一帧的预测错误。在这项工作中,我们为后处理网络使用 CBHG 模块,尽管一个更简单的体系结构也可能起作用。
后处理网络的概念是非常普遍的。它可用于预测替代目标,如声码器参数,或作为类波神经声码器(《WaveNet: A generative model for raw audio》、《SampleRNN: An unconditional end-to-end neural audio generation model》、《 Deep voice: Real-time neural text-to-speech》),直接合成波形样本。
我们使用 Griffin- lim 算法(《 Signal estimation from modified short-time fourier transform 》)从预测的谱图合成波形。
我们在 TensorFlow 中实现了 Griffin-Lim (《 TensorFlow: Large-scale machine learning on heterogeneous distributed systems 》),因此它也是模型的一部分。
虽然 Griffin-Lim 是可微的(它没有可训练的权重),但我们在本研究中不会对它施加任何损失。
我们选择 Griffin-Lim 是为了简单;虽然它已经产生强大的结果,发展一个快速和高质量可训练的频谱图波形逆变器正在进行的工作。
4 模型细节
超参数和网络结构如下表所示。
我们使用带有Hann加窗、50ms帧长、12.5 ms帧移和2048点傅立叶变换的对数幅度谱图。
我们还发现预加强是有帮助的。所有实验均采用24khz采样率。
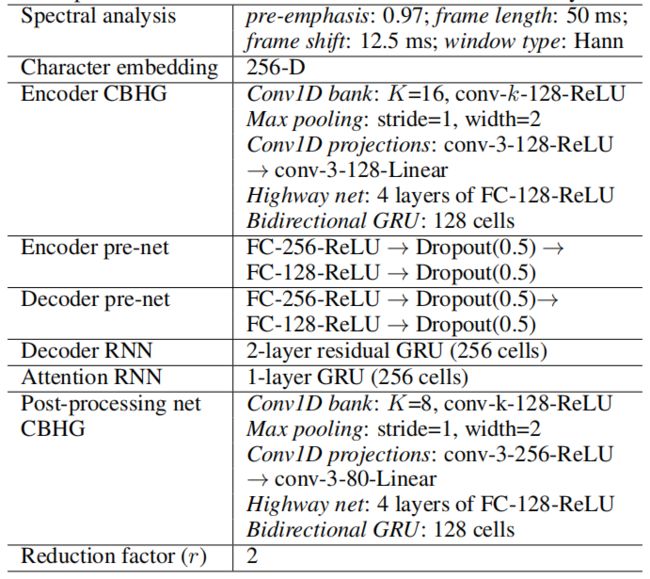
在本文中,我们使用r = 2(输出层减少因子)作为 MOS 的结果,尽管较大的r值(例如r = 5)也可以很好地工作。
我们使用了 Adam 优化器(《Adam: A method for stochastic optimization》),学习速率从0.001开始衰减,在500K、1M和2M的全局步长后分别减小到0.0005、0.0003和0.0001。
我们对 seq2seq 解码器(梅尔尺度谱图)和后处理网络(线性尺度谱图)都使用了一个简单的’ 1损耗。这两种损失的权重相等。
我们使用32的批处理大小进行训练,其中所有序列都被填充为最大长度。通常的做法是用一个损耗掩模来训练序列模型,它屏蔽了零填充帧上的损耗。
然而,我们发现以这种方式训练的模型不知道何时停止输出,导致在接近尾声时重复发出声音。一个简单的技巧来解决这个问题,也是使用重构零填充框架。
5 实验
我们在一个内部的北美英语数据集上训练 Tacotron ,该数据集包含一位职业女性演讲者讲的约24.6小时的语音数据。
5.1 烧蚀分析
我们进行了一些烧蚀分析,以了解我们模型中的关键成分。
由于生成模型很常见,很难比较基于客观指标的模型,而客观指标往往与感知不太相关(《 A note on the evaluation of generative models》)。
相反,我们主要依靠视觉比较。我们强烈鼓励读者倾听所提供的示例。
首先,我们比较一个普通的 seq2seq 模型。编码器和解码器都使用了2层剩余的 RNN ,每层有 256 个 GRU 细胞(我们尝试了 LSTM ,得到了相似的结果)。
不使用预处理网和后处理网,解码器直接预测线性尺度的对数星等谱图。我们发现该模型需要预定采样(采样率0.5)来学习对齐和推广。
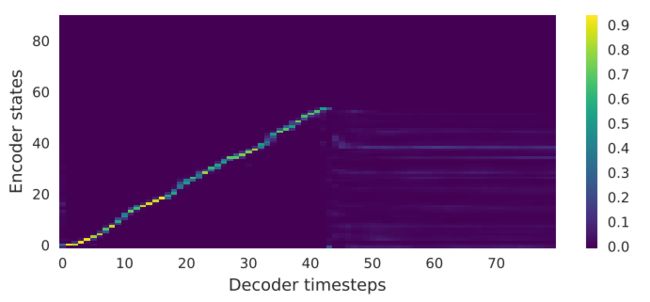
由上图可见,我们的模型学习了一个干净和平滑的对齐方式。
其次,我们比较了用两层剩余 GRU 编码器代替 CBHG 编码器的模型。模型的其余部分,包括编码器 预处理网络,完全保持不变。
从结果可知, GRU 编码器的对齐噪声更大。在听合成信号时,我们发现有噪声的对齐经常会导致读音错误。 CBHG 编码器减少了过拟合,并能很好地概括到长而复杂的短语。
我们训练了一个没有后处理网络的模型,同时保持所有其他部件不变(除了解码器 RNN 预测线性尺度谱图)。
有了更多的上下文信息,来自后处理网络的预测包含了更好的分辨谐波(例如在100和400之间的高谐波)和高频共振峰结构,这减少了合成伪影。
5.2 平均意见得分测验
我们进行了平均意见得分测试,受试者被要求在李克特量表(Likert scale)的5分评分中对刺激的自然性进行评分。
测试使用了 100 个看不见的短语,每个短语接受了 8 个评级。
当计算 MOS 时,我们只包括使用耳机的评级。
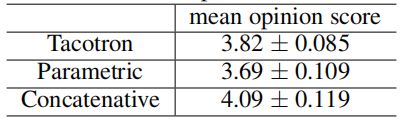
我们将我们的模型与参数(基于 LSTM (《 Fast, compact, and high quality LSTM-RNN based statistical parametric speech synthesizers for mobile devices 》))和连接系统(《Recent advances in Google real-time HMM-driven unit selection synthesizer》)进行比较,这两种系统都已运用于生产中。
如下表所示, Tacotron 的 MOS 值为 3.82 ,优于参数系统。考虑到强大的基线和 Griffin-Lim 合成引入的伪影,这是一个非常有前途的结果。
6 讨论
我们已经提出了一个集成的端到端生成 TTS 模型 Tacotron ,它以字符序列作为输入并输出相应的谱图。
一个非常简单的波形合成模块,它实现了在美式英语上 3.82 的 MOS 分数,在自然方面优于生产参数系统。
Tacotron 是基于框架的,因此推断基本上比样本水平的自回归方法快。
与以前的工作不同, Tacotron 不需要手工设计的语言特征或复杂的组件,如 HMM 对齐器。
它可以通过随机初始化从头开始训练。
我们执行简单的文本规范化,尽管学习文本规范化的最新进展(《RNN approaches to text normalization: A challenge》)可能会让这在未来变得不必要。
我们还需要研究模型的许多方面,许多早期的设计决定都没有改变。
我们的输出层,注意模块,损失功能,以及基于 Griffin-Lim 的波形合成器都是成熟的改进。
例如,众所周知, Griffin-Lim 的输出可能有声音伪影。
我们目前正致力于快速、高质量的基于神经网络的光谱图反演。