神经网络编译器的Tensor优化:auto tune和auto schedule
一般情况下,深度神经网络的计算本质上是一对tensor的计算,例如常见的conv2d的计算本质上是一个7层的for循环,那么底层的硬件,例如内存大小,SM的数量,threads和blocks等都会对最终的for循环造成影响。
现存的深度学习框架(例如Tensorflow,PyTorch ,MXNet)会将DNN中的计算映射到其底层提供的向量计算内核库(例如cuDNN,MKL-DNN)来实现高性能。 但是,这些内核库存在以下几个问题:
- 现存的加速库cuDnn,MKL-DNN针对Tensor的优化是需要耗费大量的人力和经验的。
- 硬件的发展导致会有更多的硬件出现,这种情况下再去人工手写就很窒息。
因此,目前大家希望设计一套自动搜索的过程。
- 搜什么:搜tensor计算的for循环如何部署,例如for循环如何安排,如何切割,如何和底层PE map,因此我们针对一个for循环,其实是可以得到一个模板的,每个模板是有参数的。因此搜索就分为两个:搜模板和搜参数。例如图a展示的就是现在模板定了(for循环的次序定了),只需要搜 for循环的参数;图b展示的是搜模板,是通过我规定模板的次序(譬如说先split循环的轴,然后reorder等),然后按照我们规定的顺序进行搜索。所谓的beam搜索是指站在当前的搜索节点上,我们选择最优的几个节点,站在这个节点上往下一个搜索节点走,这种beam 搜索会导致一个问题:局部最优解不一定是全局最优解。

- 怎么搜:在搜模板的过程中,当前节点表示应用某些优化原语(例如split,unroll等)后的for循环那么当应用新的原语的时候,for循环变化了,此时就相当于节点的状态变化了,而添加新的原语的过程被称为action。那么问题就会转变为,每一个状态可能根据参数会有不同的状态值,有些运行的比较快,有些比较慢;而状态之间的转移决定着整体的搜索策略(for循环最后长什么样子)。状态组成了一颗树,我们的目标就是从root节点找到叶子结点,使得运行的效率最好。首先每个节点状态的数值是有cost model定的,所谓的cost model就是指在当前的schedule的策略下,得出的表现。cost model可以是个理论值,也可以是仿真值(例如真实跑一下for循环,然后打得到运行时间)。找这条路径的策略就是解决怎么搜:例如上面提到的beam search,
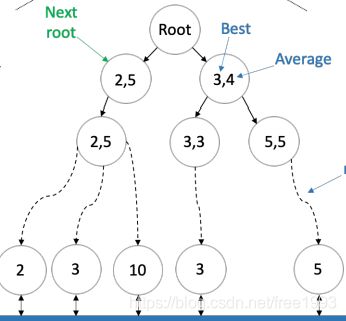
auto tune就是如何调整搜索过程中的参数 ,auto schedule就是找最后策略的过程。目前大家针对这种自动搜索,集中在下面几个问题:- 模板怎么定?是自动生成还是人工生成?
- cost model怎么定?如何抽象硬件?
- 搜索策略:利用机器学习的方法(例如强化学习、小的神经网络、蒙特卡罗树搜索)
论文
Ansor: Generating High-Performance Tensor Programs for Deep Learning by Lianmin Zheng et al., OSDI 2020
解决问题:现存的加速库cuDnn,MKL-DNN针对Tensor的优化是需要耗费大量的人力。
search-based compilation(例如TVM和FlexTensor的手写模板;Halide的auto-scheduler) ,共同的问题是搜索空空间小且受限。
解决方法:1.切割子图,针对每个子图生成搜索空间。提供各种优化策略(tile size,parallel等),然后进行枚举。
2.减小搜索空间:每次随机选一个集合,在一次使用cost model的fine tune过程中去除表现不好的集合同时加入新的集合。
3.将搜索的子图接起来。
Schedule Synthesis for Halide Pipelines on GPUs by Sioutas Savvas et al., TACO 2020
解决问题:目前写schedule的是两个:设计cost model和autotune framework.大多数的schedule是针对CPU,GPU优化的方式不多。
解决方法:加入了一些自己设计的原语:
active_SMs, active_threads,warp_size等
(拓展了模板,搜参数)
FlexTensor: An Automatic Schedule Exploration and Optimization Framework for Tensor Computation on Heterogeneous System by Size Zheng et al., ASPLOS 2020
解决问题:现存的加速库cuDnn,MKL-DNN针对Tensor的优化是需要耗费大量的人力。
解决方法:首先定了一个搜索策略(例如unroll-split),每一个状态是有一个状态函数,通过强化学习的方式,然后搜出最优的情况。
(搜模板和搜参数)
ProTuner: Tuning Programs with Monte Carlo Tree Search by Ameer Haj-Ali et al., arXiv 2020
解决问题:基于贪心算法的搜索算法beam-search algorithm(集束搜索),不一定搜出最优解,因为局部最优解不是全局最优解。这种搜索算法是在cost model找出的节点里面找局部最优的那个,然后往下一层走。。
解决方法:将所有的搜索可能性整理成Markov decision process (MDP),然后使用Monte Carlo Tree Search (蒙特卡罗树搜索)的四步。
1.选择(Selection):选择当前节点。
2.拓展(Expansion):找下一个拓展的节点
3.模拟(Simulation):计算cost model的结果
4.反向传播(Backpropagation):到达叶子节点之后,反向传播
Optimizing the Memory Hierarchy by Compositing Automatic Transformations on Computations and Data by Jie Zhao et al., MICRO 2020
解决问题:在循环优化时,fusion和tile之间相互交互,同时可能会产生多个kernel,最优解应该是尽可能融合kernel.因为launch kernel需要额外的代价。
解决方法:通过分析计算的数据依赖关系,利用多面体模型进行schedule的划分,将kernel(量化input,weight和进行卷积)尽可能的进行融合。同时针对融合后的kernel进行AST的分析,进行schedule的优化。
Chameleon: Adaptive Code Optimization for Expedited Deep Neural Network Compilation by Byung Hoon Ahn et al., ICLR 2020
解决问题:搜索schedule的空间有限并且搜索策略中的cost model非常耗时。
解决方法:提前定好了每层的模板,搜参数。根据预设的cost model先提前选出一些candidate,然后采样出候选集合放在实际的硬件上跑,得到实际的时间。整个过程是迭代的。Adaptive Exploration by leveraging Reinforcement Learning (RL)。
Learning to Optimize Halide with Tree Search and Random Programs by Andrew Adams et al., SIGGRAPH 2019
解决问题:当前的schedule的空间时有限的。
解决方法:首先使用tree来描述搜索空间,然后使用beam search减小无限的搜索空间。