python强化学习实例:寻路Q-Learn演示
文章目录
- python强化学习-寻路Q-Learn演示
- 1. 简介
-
- 1.1 项目简介
- 1.2 运行方式
- 1.3 参考
- 2 Q-Learn
-
- 2.1 简介
- 2.2 项目里的Q表
- 3. 演示
- 4. 后记
python强化学习-寻路Q-Learn演示
1. 简介
项目包含的所有资源已经上传到GitHub,欢迎访问:https://github.com/BlueShark002/QLearn
1.1 项目简介
这是一个关于Q-Learn的寻路项目。我构建了一个方块MxN的“世界”,里面一共有四个元素:
- “ P ” 玩家;
- “ X ” 陷阱;
- “ E ” 终点;
- “ ” 空地点,玩家可以自由出入。
玩家会在这个方块的小世界里按Q表移动,到达终点“E”即游戏胜利,到达"X"游戏结束。通过给与玩家的每一次移动不同的奖励,来规正玩家到达终点的路线。玩家踩到陷阱奖励-100分,到达终点奖励100分,到达空方块奖励-1分 。如下所示:

1.2 运行方式
src目录下有两个主要的py文件,QLearn.py和display.py,这是两个不同画面表现的脚本,QLearn.py只拥有命令行下的字符界面;display.py在前者的基础上利用pygame增加了可视化窗口,可以实时看到玩家采取下一动作的可能性,箭头越红表示玩家越有可能去箭头指向地点,如下所示:

在脚本所在目录命令行输入如下指令即可运行:
python QLearn.pypython display.py
第一次运行,将会在工作目录下得到一个mapPosMxN.txt文件,里面以json格式储存了Q table里的数值。M 表示列数,N表示行数,每一次改变行列大小都会得到一个新的json文件。
1.3 参考
- 手把手教你实现Qlearning算法[实战篇](附代码及代码分析)
2 Q-Learn
2.1 简介
Q-Learn是强化学习的一种算法。通过穷尽状态来描述智能体,在当前状态下执行某一行为或动作后,状态会朝着下一状态转变,因此下一状态发生与否取决当前状态,这些状态之间彼此关联。Q-Learn就是通过维护这样一个状态-动作的评估表来判断当前状态下执行何种动作的效用最高,从而选定该动作执行。每一个状态下都有若干动作,好比一张二维的表格,行表示状态,列表示动作,行列即是该行状态下该列动作的效用评估大小,如下图所示:
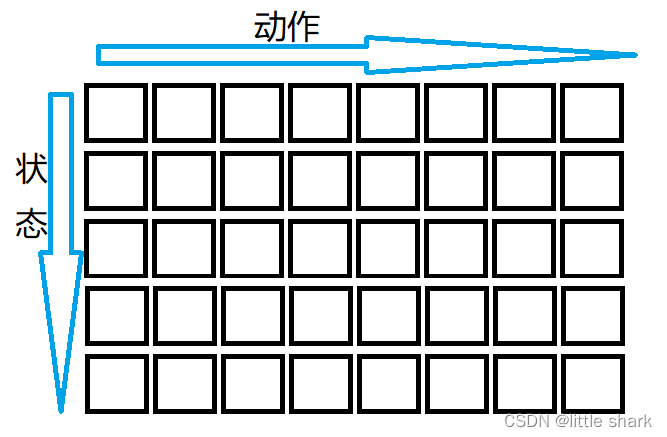
那么这些评估值如何设置?
这些评估值,根据你给予的奖励和状态之间转移确定,初始时你可以随机给出这些值,在玩家每一次移动后都要对其进行更新,这样奖励为正的行为将会得到加强,奖励为负的将会得到抑制,更新公式如下:
Q ( S , A ) = Q ( S , A ) + α [ R + γ m a x a ( S ′ , a ) − Q ( S , A ) ] Q(S,A) = Q(S, A) + \alpha[R+\gamma max_a(S', a) - Q(S, A)] Q(S,A)=Q(S,A)+α[R+γmaxa(S′,a)−Q(S,A)]
Q(S,A)表示当前状态动作下对应的Q表中的值,alpha gamma是0-1常量,***maxa(S’,a)***表示执行动作a后能到达的下一状态的q值最大,这里就是用于找到能使下一状态-动作q值最大的动作a。R是处于当前状态的奖励大小。
状态的理解和定义?
状态要根据你设计的项目来理解和定义。对于智能体来说状态就是对“环境的感知”,比如吃豆人游戏里,鬼魂的位置,玩家自己的位置,豆子的位置就是几个比较重的感知元素,智能体将这些感知元素作为对世界的理解,这些元素通过和奖励措施的有机结合在对玩家不断的训练下,智能体渐渐表现出了符合游戏规则努力获胜的行为,就像一个人类玩家那样,懂得躲避鬼魂,吞吃豆子等。有的时候我们甚至会把智能体所处环境的全部信息作为状态,比如棋盘类游戏,在象棋里我们就需要把棋盘上当前所有棋子的类型和位置作为状态来定义。
以上两个举例分别是对环境的有限感知和全部感知而且状态是离散的,连续的环境值可以通过分段切割成离散的小区间来近似离散表示。
总之,一个好的状态定义需要结合游戏规则,并实施适合的奖励措施,能对环境做出准确的描述帮助智能体符合获胜的趋势,形式根据项目的不同往往是多种多样的
2.2 项目里的Q表
项目里的Q表我采用的是python字典数据结构,键为(X,Y)action的字符,(X,Y)表示玩家当前所在的位置坐标,action表示上一次执行的动作,这里会与直觉矛盾,我这么设计是出于方便更新Q表的目的。
3. 演示
以下演示为display.py运行后的界面,左边是字符打印,右面是pygame界面,箭头的颜色从深蓝到深红表示,去往下一地点的可能性从越低到越高,颜色越红表示玩家越有可能进入指向的目的点。
演示参数:
- 界面大小:7x7
- 玩家起点在(0, 3)
- 终点在(5, 5)
- 陷阱在(5, 4) (5, 6)
开始时,玩家不断探索,对于空白地点,奖励为-1值,于是降低向此地点移动的可能,导致其他地点被探索的可能性增加,如上图所示,开始时大部分地区的指向都为红色,经过一段时间的探索,这些非终点指向的地点被降低了探索的价值,最后程序逐渐找到了一条合适的道路。
4. 后记
Q-Learn的缺点也是显而易见的,对于存在大量状态的空间,维护一个Q表往往比较困难,同时对于连续的状态空间,Q-Learn也会比较吃力。
让我们回到项目中来,我们只聚焦于两个状态,当前和之后,因此在起点到终点这条道路上只有指向终点最后的那个“箭头”得到加强,其他都是减弱的,因为我们对于空白方块的奖励较小,即使经过多次探索,它仍然具有比周边更大的探索价值,因此在后面的每一局中,玩家都保持着相同的路径,如果加大惩罚力度,比如-20,玩家花在路上的步数会更多,最终仍会找到终点。假设玩家从A点开始在到达E点的过程如下:

我们的奖励措施只会加强从D到E这个过程,也就是说只要玩家到达D后,即使D点周边有许多其他地点,玩家也会毫不犹豫地进入E。我们理应上要对整条路径进行加强,如果这条路径是最短的路径,那也没什么问题,可是如果不是的话,我们的整体加强会失去其他路径,可能会错过最短路径。我们可以通过记录下不同的路径,达到迭代次数后筛出最短的路径来解决这个问题。另外也可以计算路径上总的奖励,再均分给路径上的节点进行整体的奖励,这样理论上节点数越少,得到的平均奖励也就越多。因此,状态的表示,奖励的选择,是强化学习里比较重要的两个点。
实际上当前状态甚至会有可能影响甚至决定了未来的状态,就像在周期较长的实验过程中,前期准备了许多,期间实验体经过不同阶段的生长发育变化,临近结束时,可能会因为前期准备中的失误而功亏一篑。状态之间复杂难名的关系,也是AI的一个挑战。另外,在一个分支巨大的状态搜索空间中,不同的策略组合,不同的组合数,都会穷尽当前计算机的算力,这也加大了对长状态预测的困难,比如围棋就是一个具有巨大分支状态的项目,目前比较好的解决办法是“蒙特卡洛树搜索(MCTS)”,并不穷尽所有,只是选择几种可能的方式,进行一定深度的推演等。
在我看来,目前人工智能还有很长的路要走,我关注的还是游戏AI方面的知识,希望能做出一个强力的Boss。
谢谢各位,如有错误,敬请指正