【论文精读4】MVSNet系列论文详解-CVP-MVSNet
CVP-MVSNet全文名为“Cost Volume Pyramid Based Depth Inference for Multi-View Stereo”,主要创新点在于使用由粗到细(coarse-to-fine)模式来构建代价体金字塔(cost volume pyramid),流程如下:
(1)构建不同分辨率的L+1层图片金字塔(Image Pyramid),首先用最低精度L+1层的N张图像基于MVSNet流程推断深度图DL+1,上采样得到L层的初始深度图DL
(2)以该初始深度图DL为基础、结合L层的N张图像,通过重投影的方式构建一个局部代价体(partial cost volumes)并依次推断出初始深度图DL上各像素的残差深度(residual depth,即相对于初始深度的Δd),相加之后得到当前L层的最终深度图DL
(3)不断重复第(2)步直至推断出最终第0层即原始尺寸的深度图
本文是MVSNet系列的第4篇,建议看过【论文精读1】MVSNet系列论文详解-MVSNet之后再看便于理解。
一、问题引入&创新点
这篇论文主要是提高精度的同时,解决基于学习方法完成MVS重建时的时效问题,指出优化后的RMVSNet虽然减少了内存消耗但导致时间变长,而与本文思路类似的Point-MVSNet虽然也coarse-to-fine迭代优化深度图,但由于直接在点云上操作耗时也较长。
创新点主要概括为两点:
- 以coarse-to-fine方式构建代价体金字塔,实现一个比Point-MVSNet快6倍的MVS深度推断网络,且消耗内存较少。
- 在构建代价体金字塔的每一层,尤其是第一层之后来构建局部代价体时使用到残差深度搜索范围(即相对初始深度要在多大范围上搜索Δd),并给出该搜索范围选取与图像分辨率关系的详细分析。
二、论文模型

1.特征金字塔
首先构建图像金字塔,并使用一个共享参数的9层卷积神经网络(Leaky-ReLU作激活函数)来提取特征,输出通道数为16,宽高尺寸为[W/2l,H/2l],组成特征金字塔供接下来使用。
2.代价体金字塔
2.1 用于粗略深度图估计的代价体(第L+1层)
这一步就是标准MVSNet推断流程,值得一提的是论文解释了单应矩阵H作用:描述了参考视图上像素x与源视图i上像素xi的可能对应关系,即可以表述为λixi=Hi(d)x,λi代表xi在源视图i下的深度。
2.2 用于多尺度深度残差估计的代价体(第L层-第0层)
首先在2.1中我们得到了第L+1层的深度图DL+1,将其上采样得到第L层的初始深度图DL+1 ↑,该步骤的目的是得到结合了残差深度估计的第L层最终深度图DL=DL+1 ↑+ΔDL。
随后重复该步骤至第0层得到最终深度图。
这一步是核心步骤,这张图一定要看懂!
首先,对于2.1上采样后的初始深度图DL+1 ↑,我们定义第L层图像上像素点p(u,v)深度为dp=DL+1 ↑(u,v)。
下图是该操作的两个步骤,左边为重投影操作,右边为提取特征和构建局部代价体的操作。

2.2.1 左边重投影过程
依据当前点p的初始深度找出对应3D点(绿色),加、减一个值作为最远和最近的、可能真实3D点(紫色、红色),残差搜索深度sp就是指紫色点和红色点之间的距离(该范围选定方法将在3.1详细解释),残差深度平面就是在中间划分M个可能的深度值平面,此时残差深度平面的距离间隔为Δdp=sp/M,M个可能3D点的深度值为(DL+1 ↑(u,v)+mΔdp),其中m∈{-M/2, … ,M/2-1}。
【可以理解为以初始深度为起始点,初始深度加、减sp/2为可能的3D点最远、最近深度,这也是Δdp残差深度的含义】
此时对于当前参考视图下的像素点p,我们可以将其M个不同深度的可能3D点的按照以下公式投影,在一张源视图下得到M个深度对应的特征,如图上设置的紫色、绿色、红色三个深度点在各个源视图下都对应了一个特征。
![]()
2.2.2 右边构建局部代价体
右边便是将这些不同深度的可能3D点投影后的特征做方差,并将方差值作为像素点p在该深度的代价值;由于有M个假设深度,共HxW个像素点,因此便构成了[H,W,M]的局部代价体,将其通过同样的3D CNN之后便可以推断出这个残差深度Δd。
【这里和MVSNet构建代价体都使用方差法,只不过MVSNet是通过假设一系列深度值,将各源视图上的像素特征通过单应矩阵H变换到对应的深度、某个应该在的像素处,而这里是通过假设真实3D点位置来找到各源视图上该点的特征——即MVSNet是将特征从源视图变到参考视图下某个像素处,本文是从参考视图像素点找源视图对应的特征】
3.深度图推断
3.1 代价体金字塔的深度采样

论文观察到对于假设深度平面的采样应该与图像分辨率有关——如上图所示,太过密集的深度采样会导致3D点投影后的图像特征过于紧密、且并未提供额外的深度推断信息,因此是没有必要的。

因此,论文首先使用像素点p的初始深度值找到对应的3D点(绿色),将其投影至各源视图,沿级线方向(利用极限搜索原理,之前说过*********)搜索左右两个方向上离投影点2像素(?)远的像素点,并将其重投影至3D射线,此时两射线与参考视图的深度方向交集就是搜索深度。
原文:find points that are two pixels away from the its projection along the epipolar line in both directions(see Fig. 3 “2 pixel length”),
按原文意思应该是左右像素点都是离投影点2像素?那图中标识的应该是4 Pixel length才对
3.2 深度图推断
之后便与MVSNet一样把代价体放入3D卷积网络中聚合上下文信息并输出概率体,由概率体通过soft-argmax求期望得到深度图,特殊之处在于代价体是沿着金字塔自上而下构建的,每次得到的该层最终深度图(除第L+1层)都应该按以下公式计算:
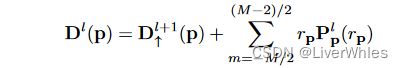
即上采样的深度+该层的局部代价体所得概率体推断出的期望残差深度
4.损失函数

与MVSNet一致,对每层深度图与真实深度求l1损失求和作为loss.
三、总结
- 图画的很好看
- 构思比较巧妙,用图像由粗到细做肯定比在点云上操作快,先得到小尺寸初始深度图,然后不断上采样再加残差深度迭代至最后深度图,求残差深度的局部代价体构建其实还是MVSNet的方差法,但是寻找特征的思路与MVSNet相反。
- 对于如何选取残差采样深度给出了详细的思考和分析,由投影点跟左右2像素点反投影至射线来作为搜索深度,理由是图像上点太密的话其实无法提供额外信息,从而减少了采样数过多带来的内存消耗问题,这个深度采样的大小、方式在P-MVSNet里也做了改进,但其inverse-depth设置并没有仔细讲,跟本文最后的3D卷积网络一样说是在supplyment material里,不过说明这块还是可以做文章创新点的。