2022图像翻译/扩散模型:UNIT-DDPM: UNpaired Image Translation with Denoising Diffusion Probabilistic Models
2022图像翻译/扩散模型:UNIT-DDPM: UNpaired Image Translation with Denoising Diffusion Probabilistic Models. UNIT-DDPM:无配对图像翻译与去噪扩散概率模型
- 0.摘要
- 1.概述
- 2.相关工作
-
- 2.1.Image-to-Image翻译
-
- 2.1.1成对图像间翻译
- 2.1.2未配对的图像间翻译
- 2.2. 扩散概率模型去噪
- 3.方法
-
- 3.1.模型训练
- 3.2. 图像翻译推理
- 4.评估
-
- 4.1.基线
- 4.2.数据集
- 4.3.通过UNIT-DDPM的图像到图像翻译
- 4.4.结果
- 4.5.消融实验
- 4.6.局限
- 5.结论
- 参考文献
0.摘要
我们提出了一种新的无配对图像间翻译方法,该方法使用去噪扩散概率模型而不需要对抗训练。我们的方法,UNpaired Image Translation with Denoising Diffusion Probabilistic Models(UNIT-DDPM),训练一个生成模型,通过最小化另一个域条件下的去噪分数匹配目标,推断图像在两个域上的联合分布作为马尔可夫链。特别地,我们同时更新两个域转换模型,并基于Langevin dynamics,以输入源域图像为条件,通过去噪马尔可夫链蒙特卡罗方法生成目标域图像。我们的方法为图像到图像的转换提供了稳定的模型训练,并生成高质量的图像输出。这使得在若干公共数据集(包括彩色图像和多光谱图像)上的先进技术初始距离(FID)性能显著优于同时代的对抗性图像对图像翻译方法
1.概述
合成真实的图像是计算机视觉长期以来的目标,因为它能够实现有益和广泛的应用,如机器学习任务中的数据增强,隐私保护和数据采集中的成本降低。虽然有各种各样的替代方法用于图像合成,如物理模拟[7],分形景观[31],和图像编辑[30],随机生成建模[46]的使用继续提供显著的有效性,在特定领域中制作相似但不同的图像,而不需要任何特定领域的知识。值得注意的是,最近对生成建模的研究集中在深度神经网络(DNN)[10],即深度生成模型(DGNN),因为它们具有对真实世界数据模式的潜在建模能力。生成对抗网络(GAN)[11],自回归模型[12],基于流的模型如NICE[3],图1:使用去噪扩散概率模型的小说图像到图像翻译方法的概念说明。RealNVP[4]和Glow[22],变分自编码器(VAE)[32]和图像转换器[29]已经合成了非常合理的图像。类似地,在迭代生成模型中也有显著的进步,如去噪扩散概率模型(DDPM)[15]和噪声条件评分网络(NCSN)[38],它们已经证明了产生与其他当代方法相媲美的更高质量合成图像的能力,但不必执行(潜在的问题)对抗训练。为了实现这一目标,许多去噪自编码模型被训练去噪被不同级别的高斯噪声破坏的样本。然后通过马尔可夫链蒙特卡罗(MCMC)过程产生样本,从白噪声开始,逐步去噪并转换为有意义的高质量图像。生成马尔可夫链过程基于Langevin dynamics[36],通过反转前向扩散过程逐步将图像转换为噪声
DGNN在图像到图像(I2I)的翻译中也引起了极大的关注[8][20][19][44]。图像到图像是一项计算机视觉任务,用于建模不同视觉域之间的映射,如风格转换[8],着色[5],超分辨率[23],照片真实感图像合成[2],域适应[26]。对于样式转移,提出了样式转移网络[8]作为dnn,训练它将样式从一个图像转移到另一个图像,同时保留其语义内容。此外,样式传输网络用于图像样式[20]的随机化。对于一般用途,Pix2Pix[19]使用GAN使用成对训练数据对映射函数建模。为了降低配对训练的依赖性,提出了周期一致性GAN (CycleGAN)[44],利用周期一致性对训练进行正则化。然而,这种基于gan的方法需要在优化和架构上非常具体的选择来稳定训练,并且很容易无法覆盖所有数据分布模式[9]。

图1:使用去噪扩散概率模型的四种新的图像转换方法的概念说明
本文提出了一种新的I2I翻译方法,使用DDPM作为后端,而不是对抗网络,以缓解不稳定训练的限制,提高生成图像的质量(图1)。本文的主要贡献是:
- 基于双域马尔可夫链的生成视频模型——引入了一种马尔可夫链I2I翻译方法,近似源域和目标域的数据分布,使它们相互关联(第3节)。
- 稳定的基于非gan的图像对图像翻译训练——该方法不需要对抗训练,然而,该模型生成了真实的输出,根据不同级别噪声的扰动捕获了高频变化(第3.1节)。
- 马尔可夫链蒙特卡罗抽样(Markov Chain Monte Carlo Sampling)的新应用。提出的采样算法可以以未配对的源域图像为条件来合成目标域图像(章节3.2)。
- 的标准数据集(Facade[39],照片-地图[44],夏季-冬季[44],和rgb - thermal[17])(表1和图5),详见第4节。
2.相关工作
我们回顾了两个相关主题的之前工作:图像对图像的翻译和去噪扩散概率模型
2.1.Image-to-Image翻译
I2I翻译的目标是学习来自源域的图像和来自目标域的图像之间的映射,I2I翻译通常分为两种方法:成对和非成对。
2.1.1成对图像间翻译
有监督I2I方法的目的是学习输入图像和输出图像之间的映射,通过训练一组对齐的图像对。早期的工作提出使用预先训练的CNN和Gram矩阵来获得图像[6]的感知分解。这分离了图像内容和风格,在保留语义内容的同时支持风格变化。最近的许多I2I方法都是使用GAN[11]进行对抗训练的,这是一个生成模型,设计为具有一个生成器和一个鉴别器组件,它们彼此竞争。该生成器经过训练,通过鉴别器输出将随机值映射到真实数据示例。该鉴别器同时被训练来鉴别由生成器产生的真实和虚假数据示例。Pix2Pix[19]提供了一个通用的对抗框架,将图像从一个域转换到另一个域。使用U-Net[34]代替自动编码器,在输入和输出之间共享底层信息。BicycleGAN[45]结合了条件VAE-GAN(CVAE-GAN)和一种恢复潜伏代码的方法,这提高了性能,其中CVAE-GAN重构特定类别的图像[1]。
2.1.2未配对的图像间翻译
配对I2I翻译需要源域和目标域的对齐图像对,而非配对方法学习的源和目标图像集是完全独立的,没有两个域之间的成对例子。CycleGAN[44]是一种使用GAN的未配对I2I翻译方法。CycleGAN修改生成器G和鉴别器D,使其从源图像 x s ∈ X s x_s∈X_s xs∈Xs传输到目标图像 x t ∈ X t x_t∈X_t xt∈Xt。这不仅学习了横向变换G,还学习了双向变换路径 G t ( x s ) G_t(x_s) Gt(xs), G s ( x t ) G_s(x_t) Gs(xt)。此外,这采用了一个新的损失度量,命名为循环一致性损失 L c y c ( G s , G t ) L_{cyc}(G_s,G_t) Lcyc(Gs,Gt):
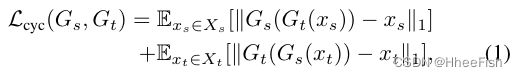
它强制每个域的真实图像和它们生成的对应图像之间的一致性。
无监督图像对图像翻译网络(UNIT)[25]在其方法中进一步假设了共享潜在空间。为了解决多模态问题,Multi-modalUNIT(MUNIT)[16]和multi-image-to-image Translation via Disentangled Representations (DIRT++)[24]采用了一种解耦合特征表示,分离了图像中特定领域的属性和共享的内容信息,进一步从未配对的图像样本中实现多样化的I2I翻译。
2.2. 扩散概率模型去噪
去噪扩散概率模型(DDPM)[15]序列败坏图像与增加的噪声,并学习逆转败坏作为一个生成模型。特别是,生成过程被定义为马尔可夫扩散过程的逆过程,从白噪声化开始,逐步将样本降噪为图像
DDPM将数据作为潜变量的形式 p θ ( x 0 ) : = ∫ p θ ( x 0 : T ) d x 1 : T p_θ(x_0):=\int{p_θ(x_{0:T})}dx_{1:T} pθ(x0):=∫pθ(x0:T)dx1:T,其中 x 0 q ( x 0 ) x_0 ~ q(x_0) x0 q(x0)为图像,T是马尔可夫链的长度, x 1 , … , x T x_1,…,x_T x1,…,xT与图像维度相同, p θ ( x 0 : T ) p_θ(x_{0:T}) pθ(x0:T)是一个具有已知高斯跃迁的马尔可夫链(逆过程)

DDPM还近似于正向过程中的posterior q ( x 1 : T ∣ x 0 ) q(x_{1:T}|x_0) q(x1:T∣x0)。这个马尔可夫链逐渐向图像中添加渐进的高斯噪声:

其中αt∈{α1,…,αT}为噪声的调度权值,因此式(5)根据方差调度αT逐步添加高斯噪声。式(6)是噪声和图像的线性插值函数,它允许以任意时间步长采样xt:

其中:

为了近似 p θ ( x t − 1 ∣ x t ) p_θ(x_{t−1}|x_t) pθ(xt−1∣xt), DDPM优化了模型参数θ通过去噪分数匹配(DSM)[41]。因此,损失函数被重新定义为一种更简单的形式:
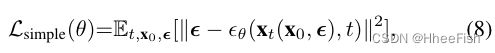
其中 ϵ θ \epsilon_θ ϵθ是通过t时刻和xt预测所加上的噪声 ϵ \epsilon ϵ的非线性函数。使用近似的 ϵ θ \epsilon_θ ϵθ, μ θ \mu_θ μθ可以被预测为:

(3)中的 ∑ θ \sum_{\theta} ∑θ被设定为 ∑ θ ( x t , t ) = ( 1 − α t ) I \sum_{\theta}(x_t,t)=(1-\alpha_t)I ∑θ(xt,t)=(1−αt)I,这允许从 x t x_t xt中采样 x t − 1 x_{t-1} xt−1:

这允许采样至 x 0 x_0 x0
我们的方法应用通过DDPM近似的潜在信息来学习图像的不同领域,并在这些领域的潜在信息之间建立联系。因此,它允许在目标域内,以与输入源域图像相关的方式,从噪声中逐步采样,逐步对图像进行噪声处理。
3.方法

图2:我们的方法的处理流程。模型训练(顶部)和图像翻译推理(底部)
我们的目标是在图像的不同域之间发展I2I平移,其分布分别形成为式(2)的联合概率。该方法需要通过经验风险最小化从给定的源域和目标域数据集中学习模型的参数,然后能够从对应的源域图像推断目标域图像。
3.1.模型训练
个人理解 : 正向过程是从噪声到图像的建模 , 反向过程就是图像到噪声的建模 , θ 是两个域的反向扩散模型的参数 \color{red}{个人理解:正向过程是从噪声到图像的建模,反向过程就是图像到噪声的建模,θ是两个域的反向扩散模型的参数} 个人理解:正向过程是从噪声到图像的建模,反向过程就是图像到噪声的建模,θ是两个域的反向扩散模型的参数
ϕ 则是图像翻译网络的参数 \color{red}{\phi则是图像翻译网络的参数} ϕ则是图像翻译网络的参数
假设一个源域 x 0 A ∈ X A x^A_0∈X^A x0A∈XA和一个目标域 x 0 B ∈ X B x^B_0∈X^B x0B∈XB,我们迭代优化每个域 p θ A A p^A_{θ^A} pθAA, p θ B B p^B_{θ^B} pθBB的反向过程和领域翻译函数 x ~ 0 B = g ϕ A A ( x 0 A ) , x ~ 0 A = g ϕ B B ( x 0 B ) \tilde{x}^B_0=g^A_{\phi^A}(x^A_0),\tilde{x}^A_0=g^B_{\phi^B}(x^B_0) x~0B=gϕAA(x0A),x~0A=gϕBB(x0B),它们仅用于模型训练,通过DSM(Domain-Specific Modeling?)分别将域A转移到B和B转移到A(图2(上))。为了使源域和目标域图像对之间能够转换 p θ A A p^A_{θ^A} pθAA, p θ B B p^B_{θ^B} pθBB被修改为 p θ A A ( x t − 1 A ∣ x t A , x ~ t B ) , p θ B B ( x t − 1 B ∣ x t B , x ~ t A ) p^A_{θ^A}(x^A_{t−1}|x^A_t,\tilde{x}^B_t),p^B_{θ^B}(x^B_{t−1}|x^B_t,\tilde{x}^A_t) pθAA(xt−1A∣xtA,x~tB),pθBB(xt−1B∣xtB,x~tA)等对生成的图像具有条件。在反向过程优化步骤中,模型参数θA、θB更新为基于式(8)的最小损失函数,重写为:

域平移函数的参数 ϕ A , ϕ B \phi^A,\phi^B ϕA,ϕB更新为最小化DSM目标,固定θA、θB

重点解释一下 ( 11 ) ( 12 ) 损失的含义 , 关键是理清几个记法 \color{red}{重点解释一下(11)(12)损失的含义,关键是理清几个记法} 重点解释一下(11)(12)损失的含义,关键是理清几个记法
t A , t B 分别表示 A 、 B 域的扩散时刻 \color{red}{t^A,t^B分别表示A、B域的扩散时刻} tA,tB分别表示A、B域的扩散时刻
ϵ θ A A 代表 A 领域的建模的扩散模型 \color{red}{\epsilon^A_{\theta^A}代表A领域的建模的扩散模型} ϵθAA代表A领域的建模的扩散模型
x t ( x 0 A , ϵ ) 代表 A 领域 t 时刻的加噪图像 \color{red}{x_t(x^A_0,\epsilon)代表A领域t时刻的加噪图像} xt(x0A,ϵ)代表A领域t时刻的加噪图像
x ~ 0 B = g ϕ A A ( x 0 A ) , x ~ 0 A = g ϕ B B ( x 0 B ) 代表无噪声的原始图像经过翻译网络翻译的结果 \color{red}{\tilde{x}^B_0=g^A_{\phi^A}(x^A_0),\tilde{x}^A_0=g^B_{\phi^B}(x^B_0)代表无噪声的原始图像经过翻译网络翻译的结果} x~0B=gϕAA(x0A),x~0A=gϕBB(x0B)代表无噪声的原始图像经过翻译网络翻译的结果
x t ( g ϕ B B ( x 0 B ) , ϵ ) 代表经过翻译后的 B 域图像在 t 时刻的加噪图像 \color{red}{x_t(g^B_{\phi^B}(x^B_0),\epsilon)代表经过翻译后的B域图像在t时刻的加噪图像} xt(gϕBB(x0B),ϵ)代表经过翻译后的B域图像在t时刻的加噪图像
g ϕ B B ( x t ( x 0 B ) , ϵ ) 代表 B 域在 t 时刻的加噪图像经过翻译后的结果 \color{red}{g^B_{\phi^B}(x_t(x^B_0),\epsilon)代表B域在t时刻的加噪图像经过翻译后的结果} gϕBB(xt(x0B),ϵ)代表B域在t时刻的加噪图像经过翻译后的结果
x t ( g ϕ B B ( x 0 B ) , ϵ ) = x ~ t B A 表示无噪声的 B 影像翻译至域 A 在 t B 时刻的加噪图像, x t ( g ϕ A A ( x 0 A ) , ϵ ) = x ~ t A B \color{red}{x_t(g^B_{\phi^B}(x^B_0),\epsilon)=\tilde{x}^A_{t^B}表示无噪声的B影像翻译至域A在t^B时刻的加噪图像,x_t(g^A_{\phi^A}(x^A_0),\epsilon)=\tilde{x}^B_{t^A}} xt(gϕBB(x0B),ϵ)=x~tBA表示无噪声的B影像翻译至域A在tB时刻的加噪图像,xt(gϕAA(x0A),ϵ)=x~tAB
g ϕ B B ( x t ( x 0 B ) , ϵ ) = x ~ t A B 表示无噪声的 A 影像翻译至域 B 在 t A 时刻的加噪图像, g ϕ A A ( x t ( x 0 A ) , ϵ ) = x ~ t B A \color{red}{g^B_{\phi^B}(x_t(x^B_0),\epsilon)=\tilde{x}^B_{t^A}表示无噪声的A影像翻译至域B在t^A时刻的加噪图像,g^A_{\phi^A}(x_t(x^A_0),\epsilon)=\tilde{x}^A_{t^B}} gϕBB(xt(x0B),ϵ)=x~tAB表示无噪声的A影像翻译至域B在tA时刻的加噪图像,gϕAA(xt(x0A),ϵ)=x~tBA
10.11 未理清,慎看,等我慢慢来 \color{red}{10.11未理清,慎看,等我慢慢来} 10.11未理清,慎看,等我慢慢来
此外,通过[44]中提出的周期一致性损失对训练进行正则化,使两个域翻译模型都是双客观的。将(1)式的循环一致性损失改写为:
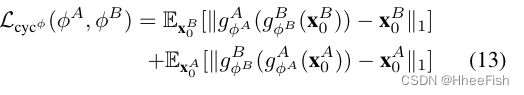
损失函数描述如下:
![]()
其中λcyc为循环一致性损失的权重。算法1给出了整个训练过程。

3.2. 图像翻译推理
使用训练过的θA、θB,将输入图像从源域转换到目标域。在推理中不再使用域翻译函数。相反,目标域图像由高斯噪声和噪声源域图像逐步合成.在采样过程中,生成过程以输入源域图像为条件,这些源域图像受来自t=T直到任意时间步长tr∈[1,T]正向过程的扰动。然后,这个时间步骤通过反向过程重新生成,我们将其表示为释放时间(图2(底部))。从域A x 0 A x^A_0 x0A转移到域B x ^ 0 B \hat{x}^B_0 x^0B 的情况描述如下:

整个翻译(推理)过程在Algorithm2中介绍

4.评估
我们的方法与之前的未配对图像到图像翻译方法[44][25][16][24]在公共数据集上进行了评估,其中地面真相输入输出对是可用的[39][44][17]
4.1.基线
从我们提出的方法中推断出的输出图像与CycleGAN[44]、UNIT[25]、MUNIT[16]和DRIT++[24]的输出图像进行了定量和定性比较(图5)。
4.2.数据集
我们为实验准备了以下数据集。每个数据集包括图像的两个域(此处缩写为域A和域B),并分为训练和测试数据集。所有图像的大小都提前调整为64×64像素。
Facade:CMP Facades dataset中的(A)照片和(B)语义分割标记了建筑物图像[39]。包括400对用于训练,106对用于测试
Photos-Maps:(A)照片和(B)地图图像是从谷歌地图中抓取的[44]。训练1096对,测试1098对。
Summer-Winter:使用Flickr API下载的(A)summer和(B)winterYosemite图像[44]。数据集包括1231张夏季和962张冬季训练图像,309张夏季和238张冬季测试图像。
RGB-Thermal:KAIST多光谱行人数据集的(A)可见和(B)行人热红外图像[17]。此数据集包含各种常规交通场景中的对齐可见图像和热图像。由于图像标注了行人边界框的区域,我们从一个场景(set00)中裁剪723对行人区域(大于64×64像素大小)用于训练,从另一个场景中裁剪425对行人区域用于测试(图3)。

图3:RGB–从KAIST多光谱行人数据集裁剪的热数据集[17]。
4.3.通过UNIT-DDPM的图像到图像翻译

图4:我们的U-net架构图。每个Conv2d或ConvTranspose2d在输入之前都包括BatchNorm2d和ReLU。
我们方法的去噪模型是使用基于PixelCNN[35]和Wide ResNet[43]的U-Net[34]实现的,变压器正弦位置嵌入[40]对时间步长T=1000进行编码,αT从α1=0.9999线性减少到αT=0.98,与原始DDPM[15]相同,但用ReLU[27]替换Swith[33],组归一化[42]与批归一化[18],并移除自我注意块以减少计算(图4)。域转换函数具有ResNet[13]体系结构,与U-net具有相同的层深度。在训练中,一对训练样本和另一个伪域样本连接为输入。模型参数更新为λcyc=10.0,批次大小B=16,通过Adam(初始学习率η=10−5,β1= 0.5,β2= 0.999)迭代20000epochs
4.4.结果

表1:不同图像到图像转换方法的Fríechet初始距离(FID)[14]分数
图5:不同图像到图像转换方法生成的输出图像示例。
图6:通过我们的方法生成渐进图像的示例
由每种方法合成的输出图像如图5所示,从图中可以明显看出,我们的方法在质量上比CycleGAN[44]、UNIT[25]、MUNIT[16]和DRIT++[24]生成的图像更逼真。我们还发现,我们的方法根本没有受到模式崩溃的影响,由于不需要对抗训练,因此得到的模型训练更加稳定。此外,图6显示了反向过程中通过我们的方法进行的累进采样。通过地面实况和输出图像之间的Fríechet InceptionDistance(FID)[14]进行比较,如表1所示。在所有基准数据集Facade、Photos–Maps、Summer–Winter、,and RGB–Thermal使∼在所有此类数据集中,与之前的方法相比,为20%。
4.5.消融实验

图7:FID与释放时间的比较。
我们通过从tr=1变为900来分析释放时间对性能的影响。FID的比较(图7)显示没有显著变化。我们可以观察到归因于释放时间变化的细微差异,但这取决于数据集。这一结果表明,释放时间超参数的调整依赖于数据集,进一步的分析代表了未来工作的方向
4.6.局限
图4:我们的U-net架构图。每个Conv2d或ConvTranspose2d在输入之前都包括BatchNorm2d和ReLU。
图8:使用我们的方法训练的模型生成的256×256像素的输出图像示例(Facade数据集大小调整为256×256像素)
我们还观察了输入图像分辨率增加256×256像素时的输出图像。高分辨率模型使用相同的网络架构(图4)和第节中的学习参数进行训练。4.3.图8所示的输出在整个像素上被错误着色。这表明,由于高维图像空间的复杂性增加,模型无法学习图像的全局信息。一种可能的解决方案是在去噪模型中的Unet中添加更多层和注意机制,以便捕获更精确的图像多分辨率结构,这将在未来的工作中进行研究。
5.结论
本文提出了一种新的非成对I2I翻译方法,该方法使用DDPM而不需要对抗训练,称为带去噪扩散概率模型的未成对图像翻译(UNIT-DDPM)。我们的方法训练一个生成模型,通过最小化另一个域上的DSM目标,将两个域上图像的联合分布推断为马尔可夫链。随后,领域翻译模型将同时更新,以最小化该DSM目标。在联合优化这些生成和翻译模型后,我们通过去噪MCMC方法生成目标域图像,该方法以基于Langevin动力学的输入源域图像为条件。我们的方法为I2I翻译提供稳定的模型训练,并生成高质量的图像输出。
尽管实验显示了令人信服的结果,但我们方法的当前形式远远不是一致肯定的,特别是在分辨率更高的情况下。为了解决这个问题,需要修改实现以更准确地建模大型图像。
此外,DDPM的一个缺点是图像生成的时间。然而,这可以通过修改马尔可夫过程来加速,例如去噪扩散隐式模型[37]或使用可学习∑θ[28]减少时间步长。未来的工作将考虑修改以实现更短的采样时间和更高质量的图像输出,以及将合成图像应用于其他下游计算机视觉系统(如对象分类)时的性能评估。
参考文献
[1] Jianmin Bao, Dong Chen, Fang Wen, Houqiang Li, andGang Hua. Cvae-gan: fine-grained image generation throughasymmetric training. InProc. of the IEEE Intl. Conf. onComputer Vision, 2017. 2
[2] Qifeng Chen and Vladlen Koltun.Photographic imagesynthesis with cascaded refinement networks. InProc. ofthe IEEE Intl. Conf. on Computer Vision, 2017. 2
[3] Laurent Dinh, David Krueger, and Yoshua Bengio. Nice:Non-linear independent components estimation.Proc. 3rdIntl Conf. on Learning Representations, 2015.
[4] Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio.Density estimation using real nvp. InProc. 5th Intl Conf.on Learning Representations, 2017. 1
[5] Z. Dong, S. Kamata, and T.P. Breckon.Infrared imagecolorization using s-shape network. InProc. Int. Conf. onImage Processing, 2018. 2
[6] Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge.A neural algorithm of artistic style.CoRR abs/1508.06576,2015. 2
[7] G Gerhart, G Martin, and T Gonda.Thermal imagemodeling.InInfrared Sensors and Sensor Fusion.International Society for Optics and Photonics, 1987. 1
[8] Golnaz Ghiasi, Honglak Lee, Manjunath Kudlur, VincentDumoulin, and Jonathon Shlens. Exploring the structure ofa real-time, arbitrary neural artistic stylization network. InProc. British Machine Vision Conf., 2017. 1, 2
[9] Ian Goodfellow. Nips 2016 tutorial: Generative adversarialnetworks.CoRR abs/1701.00160, 2017. 2
[10] Ian Goodfellow, Yoshua Bengio, and Aaron C. Courville.Deep learning.Nature, 521:436–444, 2015. 1
[11] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, BingXu, David Warde-Farley, Sherjil Ozair, Aaron Courville, andYoshua Bengio. Generative adversarial nets. InAdvances inNeural Information Processing Systems 27. 2014. 1, 2
[12] Karol Gregor, Ivo Danihelka, Andriy Mnih, CharlesBlundell, and Daan Wierstra. Deep autoregressive networks.InProc. Intl. Conf. on Machine Learning, 2014. 1
[13] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.Deep residual learning for image recognition. InProc. ofthe IEEE Conf. on Computer Vision and Pattern Recognition,2016. 5
[14] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner,Bernhard Nessler, and Sepp Hochreiter. Gans trained bya two time-scale update rule converge to a local nashequilibrium.InProc. Advances in Neural InformationProcessing Systems 30. 2017. 2, 7
[15] Jonathan Ho, Ajay Jain, and Pieter Abbeel.Denoisingdiffusionprobabilisticmodels.arXivpreprintarXiv:2006.11239, 2020. 1, 3, 5
[16] Xun Huang, Ming-Yu Liu, Serge Belongie, and Jan Kautz.Multimodal unsupervised image-to-image translation.InProc. of the European Conf. on Computer Vision, 2018. 2, 3,5, 6, 7
[17] Soonmin Hwang, Jaesik Park, Namil Kim, Yukyung Choi,and In So Kweon.Multispectral pedestrian detection:Benchmark dataset and baselines. InProc. of IEEE Conf.on Computer Vision and Pattern Recognition, 2015. 2, 5
[18] Sergey Ioffe and Christian Szegedy. Batch normalization:Accelerating deep network training by reducing internalcovariate shift. InProc. Intl. Conf. on Machine Learning,2015. 5
[19] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei AEfros.Image-to-image translation with conditionaladversarial networks.InProc. of the IEEE Conf. onComputer Vision and Pattern Recognition, 2017. 1, 2
[20] Philip T. G. Jackson, Amir Atapour Abarghouei, StephenBonner, Toby P. Breckon, and Boguslaw Obara.Styleaugmentation: Data augmentation via style randomization.InProc. IEEE Conf. on Computer Vision and PatternRecognition Workshops, 2019
[21] Diederik P. Kingma and Jimmy Ba. Adam: A method forstochastic optimization. InProc. 3rd Intl. Conf. on LearningRepresentations, 2015. 7
[22] Durk P Kingma and Prafulla Dhariwal. Glow: Generativeflow with invertible 1x1 convolutions. InProc. Advances inNeural Information Processing Systems 31, 2018. 1
[23] Christian Ledig, Lucas Theis, Ferenc Husz ́ar, JoseCaballero, Andrew Cunningham, Alejandro Acosta, AndrewAitken, Alykhan Tejani, Johannes Totz, Zehan Wang,et al. Photo-realistic single image super-resolution using agenerative adversarial network. InProc. of the IEEE Conf.on Computer Vision and Pattern Recognition, 2017. 2
[24] Hsin-Ying Lee, Hung-Yu Tseng, Jia-Bin Huang, ManeeshSingh, and Ming-Hsuan Yang.Diverse image-to-imagetranslation via disentangled representations. InProc. of theEuropean Conf. on Computer Vision, 2018. 2, 3, 5, 6, 7
[25] Ming-Yu Liu, Thomas Breuel, and Jan Kautz. Unsupervisedimage-to-image translation networks. InAdvances in NeuralInformation Processing Systems 30. 2017. 2, 3, 5, 6, 7
[26] Zak Murez, Soheil Kolouri, David Kriegman, RaviRamamoorthi, and Kyungnam Kim.Image to imagetranslation for domain adaptation. InProc. of the IEEE Conf.on Computer Vision and Pattern Recognition, 2018. 2
[27] Vinod Nair and Geoffrey E Hinton. Rectified linear unitsimprove restricted boltzmann machines. InProc. of the 27thIntl. Conf. on Machine Learning, 2010. 5
[28] AlexNicholandPrafullaDhariwal.Improveddenoising diffusion probabilistic models.arXiv preprintarXiv:2102.09672, 2021. 8
[29] Niki Parmar, Ashish Vaswani, Jakob Uszkoreit, ŁukaszKaiser, Noam Shazeer, Alexander Ku, and Dustin Tran.Image transformer.InProc. 6th Intl Conf. on LearningRepresentations, 2018. 1
[30] Patrick P ́erez, Michel Gangnet, and Andrew Blake. Poissonimage editing. InACM SIGGRAPH 2003 Papers, 2003. 1
[31] Przemyslaw Prusinkiewicz and Mark Hammel. A fractalmodel of mountains and rivers. InGraphics Interface, 1993.1
[32] Yunchen Pu, Zhe Gan, Ricardo Henao, Xin Yuan, ChunyuanLi, Andrew Stevens, and Lawrence Carin.Variationalautoencoder for deep learning of images, labels and captions.InAdvances in Neural Information Processing Systems 29.2016. 1
[33] Prajit Ramachandran, Barret Zoph, and Quoc V. Le.Searching for activation functions.CoRR abs/1710.05941,2017. 5
[34] Olaf Ronneberger, Philipp Fischer, and Thomas Brox.U-net:Convolutional networks for biomedical imagesegmentation. InIntl. Conf. on Medical Image Computingand Computer-Assisted Intervention, 2015. 2, 5
[35] Tim Salimans, Andrej Karpathy, Xi Chen, and Diederik P.Kingma.Pixelcnn++:A pixelcnn implementationwith discretized logistic mixture likelihood and othermodifications.InProc. 5th Intl Conf. on LearningRepresentations, 2017
[36] Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan,and Surya Ganguli.Deep unsupervised learning usingnonequilibrium thermodynamics.InProc. of MachineLearning Research 37, 2015. 1
[37] Jiaming Song,Chenlin Meng,and Stefano Ermon.Denoising diffusion implicit models.arXiv preprintarXiv:2010.02502, 2020. 8
[38] Yang Song and Stefano Ermon. Generative modeling byestimating gradients of the data distribution.InProc.Advances in Neural Information Processing Systems 32.2019. 1
[39] Radim Tyleˇcek and RadimˇS ́ara. Spatial pattern templatesfor recognition of objects with regular structure. InGermanConference on Pattern Recognition, 2013. 2, 5
[40] Ashish Vaswani, Noam Shazeer, Niki Parmar, JakobUszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, andIllia Polosukhin. Attention is all you need. InProc. Advancesin Neural Information Processing Systems 30, 2017. 5
[41] Pascal Vincent.A connection between score matchingand denoising autoencoders.Neural computation,23(7):1661–1674, 2011. 3
[42] Yuxin Wu and Kaiming He. Group normalization. InProc.of the European Conf. on Computer Vision, 2018. 5
[43] Sergey Zagoruyko and Nikos Komodakis. Wide residualnetworks. InProc. of the British Machine Vision Conference,2016. 5
[44] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A.Efros.Unpaired image-to-image translation usingcycle-consistent adversarial networks.InProc. IEEEIntl. Conf. on Computer Vision, 2017. 1, 2, 3, 4, 5, 6, 7
[45] Jun-Yan Zhu, Richard Zhang, Deepak Pathak, TrevorDarrell, Alexei A Efros, Oliver Wang, and Eli Shechtman.Toward multimodal image-to-image translation. InProc.Advances in Neural Information Processing Systems 30.2017. 2
[46] Song-Chun Zhu. Statistical modeling and conceptualizationof visual patterns.IEEE Transactions on Pattern Analysisand Machine Intelligence, 25(6):691–712, 2003. 110