MMsegmentation文档学习
1.了解配置
config文件结构:
config/_base_下有4种基本组件类型:
dataset
model
schedule
default_runtime
同一文件夹下的所有配置,建议只具有一个原始配置,所有其他配置从原始配置继承,这样继承级别的最大值为3
为了便于理解,如果用户在DeepLabV3的基础上进行一些修改,建议用户可以先通过继承基本的DeepLabV3结构,然后再配置文件中修改必要的字段
_base_ = ../deeplabv3/deeplabv3_r50_512x1024_40ki_cityscapes.py
如果要建立一个不与任何现有方法共享结构的全新方法,可以在configs下创建一个新文件夹xxnet
Config命名格式:
{model}_{backbone}_[misc]_[gpu x batch_per_gpu]_{resolution}_{schedule}_{dataset}
{xxx}是必填字段,[yyy]是可选字段。
{model}:型号类型等psp,deeplabv3等。
{backbone}:骨干类型,例如r50(ResNet-50),x101(ResNeXt-101)。
[misc]:杂项设置/模型的插件,例如dconv,gcb,attention,mstrain。
[gpu x batch_per_gpu]:8x2默认使用GPU和每个GPU的样本。
{schedule}:训练时间表,20ki意味着20k次迭代。
{dataset}:数据集cityscapes,voc12aug,ade
SyncBN:
SyncBN即在数据并行分布式训练时,将各显卡上分配的数据汇总到一起进行规范化处理,也就是计算所有数据全局的均值和方差。按照沐神的说法,如果分别计算均值和方差,就需要做两次数据同步。可以分布求全局的xi的和与xi²的和。这样就只需要做一次数据同步。
requires_grad是Pytorch中通用数据结构Tensor的一个属性,用于说明当前量是否需要在计算中保留对应的梯度信息,以线性回归为例,容易知道权重w和偏差b为需要训练的对象,为了得到最合适的参数值,我们需要设置一个相关的损失函数,根据梯度回传的思路进行训练。

DeepLab V3的示例
# model settings
norm_cfg = dict(type='SyncBN', requires_grad=True) # 分割通常使用SyncBN
model = dict(
type='EncoderDecoder', # 分割器名称
pretrained='open-mmlab://resnet50_v1c', # 加载ImageNet预训练的backbone
backbone=dict(
type='ResNetV1c', # backbone的类型
depth=50, # backbone的深度,一般用50,101
num_stages=4, # backbone的阶段数
out_indices=(0, 1, 2, 3), # 每个阶段生成的输出特征图的索引
dilations=(1, 1, 2, 4), # 每层的膨胀率
strides=(1, 2, 1, 1), # 每层的步幅
norm_cfg=norm_cfg, # 规范层的配置
norm_eval=False, # 是否冻结BN中的统计信息
style='pytorch', # 主干的样式,“ pytorch”表示第2步的步幅为3x3卷积,“ caffe”表示第2步的步幅为1x1卷积
contract_dilation=True), # 当扩张> 1时,是否收缩第一层扩张。
decode_head=dict(
type='ASPPHead', # 解码器的类型,请参阅mmseg / models / decode_heads了解可用选项。
in_channels=2048, # 解码器头输入通道数
in_index=3, # 选择特征图的索引
channels=512, # 解码器头的中间通道数
dilations=(1, 12, 24, 36),
dropout_ratio=0.1, # 在最终分类层之前的dropout率
num_classes=19, # 分割类别的数量,通常对于城市景观为19,对于VOC为21,对于ADE20k为150。
norm_cfg=norm_cfg,
align_corners=False, # 用于在解码时调整大小
loss_decode=dict( # 解码器损失函数的配置
type='CrossEntropyLoss', # 用于分割的损失函数的类型
use_sigmoid=False, # 是否使用sigmode激活函数
loss_weight=1.0)), # 解码器的损失权重
auxiliary_head=dict(
type='FCNHead', # auxiliary_head(辅助头)的类型,请参阅mmseg / models / decode_heads了解可用选项。
in_channels=1024, # 辅助头的输入通道数
in_index=2, # 选择特征图索引
channels=256, # 解码器的中间通道
num_convs=1, # FCNHead的卷积数,在auxiliary_head通常是1
concat_input=False, # 是否将convs的输出与分类器之前的输入进行拼接
dropout_ratio=0.1, # 最终分类器之前的dropout率
num_classes=19, #
norm_cfg=norm_cfg, # norm层的配置
align_corners=False, # 用于在解码时调整大小
loss_decode=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=0.4)), # Loss weight of auxiliary head, which is usually 0.4 of decode head
# model training and testing settings
train_cfg=dict(), # train_cfg目前仅是一个占位符
test_cfg=dict(mode='whole')) # 测试模块,‘whole’:整个图像全卷积测试,‘sliding’:裁剪图像
# dataset settings
dataset_type = 'CityscapesDataset' # 数据集类型,将用于定义数据集
data_root = 'data/cityscapes/' # 数据的根路径
img_norm_cfg = dict( # 图像归一化配置以对输入图像进行归一化
mean=[123.675, 116.28, 103.53], # 用于预训练预训练骨干模型的平均值
std=[58.395, 57.12, 57.375], # 用于预训练预训练骨干模型的标准方差
to_rgb=True) # 用于预训练预训练骨干模型的图像通道顺序
crop_size = (512, 1024) # 训练时的图像剪裁大小
train_pipeline = [ # 训练通道
dict(type='LoadImageFromFile'), # 从文件加载图像的第一个通道
dict(type='LoadAnnotations'), # 为当前图像加载注释的第二个通道
dict(type='Resize', # 增强通道以调整图像的大小及其注释
img_scale=(2048, 1024), # 最大图像比例
ratio_range=(0.5, 2.0)), # 扩大比率的范围
dict(type='RandomCrop', # 增强通道从当前图像中随机裁剪一patch
crop_size=crop_size, # patch的大小
cat_max_ratio=0.75), # 单个类别可以占用的最大面积比
dict(type='RandomFlip', # 翻转图像及其注释的增强通道
prob=0.5), # 翻转的比例或概率
dict(type='PhotoMetricDistortion'), # 增强通道,通过多种光度学方法使当前图像失真
dict(type='Normalize', # 标准化输入图像的增强通道
**img_norm_cfg),
dict(type='Pad', # 将图像填充到指定大小的增强通道
size=crop_size, # 填充的输出大小
pad_val=0, # 图片的填充值
seg_pad_val=255), # 'gt_semantic_seg'的填充值
dict(type='DefaultFormatBundle'), # 默认格式捆绑包,用于收集管道中的数据
dict(type='Collect', # 决定应将数据中的哪些键传递给分割器的管道
keys=['img', 'gt_semantic_seg']),
]
test_pipeline = [
dict(type='LoadImageFromFile'), # 第一个从文件路径加载图像的管道
dict(
type='MultiScaleFlipAug', # 封装测试时间扩展的封装
img_scale=(2048, 1024), # 确定用于调整管道大小的最大测试规模
# img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],#更改为多规模测试
flip=False, # 测试期间是否翻转图像
transforms=[
dict(type='Resize', # 使用调整大小的增强Use resize augmentation
keep_ratio=True), # 是否保持高宽比,此处设置的img_scale将被以上设置的img_scale取代
dict(type='RandomFlip'), # 以为RandomFlip是在管道中添加的,当flip = False时不使用
dict(type='Normalize', # 规范化配置,值来自img_norm_cfg
**img_norm_cfg),
dict(type='ImageToTensor', # 将图像转换为张量
keys=['img']),
dict(type='Collect', # 收集必要密钥以进行测试的Collect管道
keys=['img']),
])
]
data = dict(
samples_per_gpu=2, # 单个GPU的批处理大小
workers_per_gpu=2, # 为每个GPU预取数据
train=dict( # 训练数据集配置
type=dataset_type, # 数据集类型,有关详细信息,请参考mmseg / datasets /
data_root=data_root, # 数据集的位置
img_dir='leftImg8bit/train', # 数据集的图像目录
ann_dir='gtFine/train', # 数据集的注释目录
pipeline=train_pipeline), # 管道,这是由之前创建的train_pipeline传递的
val=dict(
type=dataset_type, # 验证数据集配置
data_root=data_root,
img_dir='leftImg8bit/val',
ann_dir='gtFine/val',
pipeline=test_pipeline), # 管道由之前创建的test_pipeline传递
test=dict(
type=dataset_type,
data_root=data_root,
img_dir='leftImg8bit/val',
ann_dir='gtFine/val',
pipeline=test_pipeline))
# yapf:disable
log_config = dict( # 配置注册记录器钩子
interval=50, # 间隔打印日志
hooks=[
dict(type='TextLoggerHook', by_epoch=False),
# dict(type='TensorboardLoggerHook')#还支持Tensorboard记录器
])
# yapf:enable
dist_params = dict(backend='nccl') # 参数设置分布式训练,也可以设置端口
log_level = 'INFO' # 日志级别
load_from = None # 从给定路径将模型加载为预训练模型。 这不会恢复训练
resume_from = None # 从给定路径恢复检查点,保存检查点后,训练将从迭代中恢复
workflow = [('train',
1)] # Workflow for runner [('train',1)]表示只有一个工作流程,名为'train'的工作流程只执行一次。
# 工作流程根据`runner.max_iters`进行了40000次迭代训练模型。
cudnn_benchmark = True # 是否使用cudnn_benchmark加快速度,只适用于固定输入大小
# optimizer
optimizer = dict( # 用于构建优化器的Config,支持PyTorch中的所有优化器,其参数也与PyTorch中的参数相同
type='SGD', # 优化程序的类型,
# 请参阅https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/optimizer/default_constructor.py#L13了解更多信息
lr=0.01, # 优化器的学习率,请参阅PyTorch文档中参数的详细用法
momentum=0.9, # 动量
weight_decay=0.0005) # SGD的重量衰减
optimizer_config = dict() # 用于构建优化程序挂钩的配置,
# 有关实现的详细信息,请参阅https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/optimizer.py#L8。
# learning policy
lr_config = dict(policy='poly',
# scheduler的策略还支持Step,CosineAnnealing,Cyclic等。
# 请参阅https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py#所支持的LrUpdater的详细信息。 L9。
power=0.9, # 多项式衰减的幂
min_lr=1e-4, # 稳定训练的最低学习率
by_epoch=False) # 是否按epoch计数
# runtime settings
runner = dict(type='IterBasedRunner', # 要使用的运行程序类型(即IterBasedRunner或EpochBasedRunner)
max_iters=40000) # 迭代总数。 对于EpochBasedRunner使用`max_epochs`
checkpoint_config = dict(
# 进行配置以设置检查点挂钩,有关实现请参阅https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py
by_epoch=False, # 是否按epoch计数
interval=4000) # 保存间隔
evaluation = dict( # 用于构建评估挂钩的配置。 有关详细信息,请参考mmseg / core / evaulation / eval_hook.py
interval=4000, # 评估间隔
metric='mIoU') # 评估指标
2.自定义数据集
最简单的方法就是重组数据,以此作为数据集
文件结构的示例:
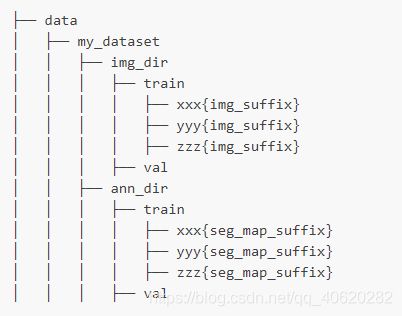
- 通过混合数据集来自定义数据集
MMSegmentation支持这种混合数据集以进行训练。目前,它支持合并和重复数据集。
混合数据集有以下几种方式
- 重复数据集
使用RepeatDataset包装器来重复数据集,以下是重复数据集Dataset_A示例
dataset_A_train = dict(
type='RepeatDataset',
times=N,
dataset=dict( # This is the original config of Dataset_A 数据集A的原始配置
type='Dataset_A',
...
pipeline=train_pipeline
)
)
连接数据集
两种方法:
(1)如果要连接的数据集属于同一类型,但带有不同的注释文件,则可以如下连接数据集配置
1.连接两个ann_dir

2.连接两个split
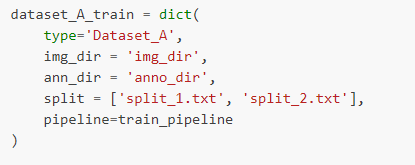
3.同时连接两个ann_dir和两个split

这种情况下,ann_dir_1和ann_dir_2对应于split_1.txt和split_2.txt
(2)如果要连接的数据集不同,则使用如下的配置

重复Dataset_A N次,Dataset_B M次,分别再连接每个重复的数据集

3.自定义数据通道
数据管道设计
资料载入
- LoadImageFromFile
添加img,img_shape,ori_shape
- LoadAnnotations
添加gt_semantic_seg,seg_fields
预处理
Resize
- add:scale, scale_idx, pad_shape, scale_factor, keep_ratio
- update:img, img_shape, *seg_fields
RandomFlip
- add: flip
- update: img, *seg_fields
Pad
- add: pad_fixed_size, pad_size_divisor
- update: img, pad_shape, *seg_fields
RandomCrop
- update: img, pad_shape, *seg_fields
Normalize
- add: img_norm_cfg
- update: img
SegRescale
- update: gt_semantic_seg
PhotoMetricDistortion
- update: img
格式设定
ToTensor
- update: specified by keys
ImageToTensor
- update: specified by keys
Transpose
- update: specified by keys
ToDataContainer
- update: specified by fields
DefaultFormatBundle
- update: img, gt_semantic_seg
Collect
- add: img_meta (the keys of img_meta is specified by meta_keys)
img_meta的键由meta_keys指定
- remove: all other keys except for those specified by keys
除按键指定的按键外的其他所有按键
测试时间增强
MultiScaleFlipAug
扩展和使用自定义通道
1.再任意文件中编写新的通道my_pipeline.py,他以一个dict作为输入并返回一个dict
from mmseg.datasets import PIPELINES
@PIPELINES.register_module()
class MyTransform:
def __call__(self, results):
results['dummy'] = True
return results
2.导入新类
from .my_pipeline import MyTransform
3.再配置文件中使用它
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
crop_size = (512, 1024)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=(2048, 1024), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
dict(type='MyTransform'),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg']),
]
4.自定义模型
自定义优化器
假设要添加一个优化器名为MyOptimizer,现有一个arguments包含a,b,c
我们在mmseg/core/optimizer/my_optimizer.py文件中实现一个新的优化器
from mmcv.runner import OPTIMIZERS
from torch.optim import Optimizer
@OPTIMIZERS.register_module
class MyOptimizer(Optimizer):
def __init__(self, a, b, c)
然后在mmseg/core/optimizer/__init__.py中添加这个模块,目的是注册器会找到这个新模块并且添加它
from .my_optimizer import MyOptimizer
你可以用optimizer文件中的MyOptimizer来配置文件,在配置文件中,优化器被optimizer文件定义为如下
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
使用自己的优化器可以改为
optimizer = dict(type='MyOptimizer', a=a_value, b=b_value, c=c_value)
自定义优化器构造函数
某些模型可能具有一些特定于参数的设置以进行优化,用户可以通过自定义优化器构造函数来进行那些细粒度(具体是什么类型的狗)的参数调整
from mmcv.utils import build_from_cfg
from mmcv.runner import OPTIMIZER_BUILDERS
from .cocktail_optimizer import CocktailOptimizer
@OPTIMIZER_BUILDERS.register_module
class CocktailOptimizerConstructor(object):
def __init__(self, optimizer_cfg, paramwise_cfg=None):
def __call__(self, model):
return my_optimizer
开发新组件
MMSegmentation中主要有两种类型的组件
- backbone:通常是卷积网络堆栈,以提取特征图,例如ResNet,HRNet。
- head:用于语义分割图解码的组件。
添加新的backbone
1.创建一个新文件mmseg/models/backbones/resnet.py
import torch.nn as nn
from ..registry import BACKBONES
@BACKBONES.register_module
class ResNet(nn.Module):
def __init__(self, arg1, arg2):
pass
def forward(self, x): # should return a tuple
pass
def init_weights(self, pretrained=None):
pass
1.在mmseg/models/backbones/__init__.py中导入模块
from .resnet import ResNet
1.在自己的配置文件中使用
model = dict(
...
backbone=dict(
type='ResNet',
arg1=xxx,
arg2=xxx),
…
添加新的heads
在mmsegmentation中,作者为所有的segmentation head提供了基本的BaseDecodeHead,所有新实现的decode heads应该源于它
首先,在mmseg/models/decode_heads/psp_head.py中添加一个新的decode head,实现decode head我们需要实现以下三个函数:
@HEADS.register_module()
class PSPHead(BaseDecodeHead):
def __init__(self, pool_scales=(1, 2, 3, 6), **kwargs):
super(PSPHead, self).__init__(**kwargs)
def init_weights(self):
def forward(self, inputs):
然后需要在mmseg/models/decode_heads/__init__.py中添加这个模块使得相应的注册表找到并加载
norm_cfg = dict(type='SyncBN', requires_grad=True)
model = dict(
type='EncoderDecoder',
pretrained='pretrain_model/resnet50_v1c_trick-2cccc1ad.pth',
backbone=dict(
type='ResNetV1c',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
dilations=(1, 1, 2, 4),
strides=(1, 2, 1, 1),
norm_cfg=norm_cfg,
norm_eval=False,
style='pytorch',
contract_dilation=True),
decode_head=dict(
type='PSPHead',
in_channels=2048,
in_index=3,
channels=512,
pool_scales=(1, 2, 3, 6),
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)))
添加新的损失函数
用户添加新的损失函数MyLoss需要在mmseg/models/losses/my_loss.py(需要新建)中实现,
装饰器weighted_loss使得对每一个函数的损失得以加权
import torch
import torch.nn as nn
from ..builder import LOSSES
from .utils import weighted_loss
@weighted_loss
def my_loss(pred, target):
assert pred.size() == target.size() and target.numel() > 0
loss = torch.abs(pred - target)
return loss
@LOSSES.register_module
class MyLoss(nn.Module):
def __init__(self, reduction='mean', loss_weight=1.0):
super(MyLoss, self).__init__()
self.reduction = reduction
self.loss_weight = loss_weight
def forward(self,
pred,
target,
weight=None,
avg_factor=None,
reduction_override=None):
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
loss = self.loss_weight * my_loss(
pred, target, weight, reduction=reduction, avg_factor=avg_factor)
return loss
然后用户需要在mmseg/models/losses/__init__.py中添加
from .my_loss import MyLoss, my_loss
使用它需要修改loss_xxx字段,然后需要修改在head中的loss_decode字段,loss_weight可以被用来平衡多重损失
loss_decode=dict(type='MyLoss', loss_weight=1.0)
5.训练技巧
Backbone与Heads的学习率不同
在语义分割中,一些方法使头部的LR大于主干的LR,以实现更好的性能或更快的收敛。
在MMSegmentation中,您可以在配置中添加以下行,以使头部的LR达到主干的10倍。
optimizer=dict(
paramwise_cfg = dict(
custom_keys={
'head': dict(lr_mult=10.)}))
Online Hard Example Mining (OHEM)
_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
model=dict(
decode_head=dict(
sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=100000)) )
类平衡损失(在一组样本中不同类别的样本量差异非常大)
对于类别分布不平衡的数据集,您可以更改每个类别的损失权重。这是城市景观数据集的示例
_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
model=dict(
decode_head=dict(
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0,
# DeepLab used this class weight for cityscapes
class_weight=[0.8373, 0.9180, 0.8660, 1.0345, 1.0166, 0.9969, 0.9754,
1.0489, 0.8786, 1.0023, 0.9539, 0.9843, 1.1116, 0.9037,
1.0865, 1.0955, 1.0865, 1.1529, 1.0507])))
6.自定义运行是设置
自定义自我实现的优化器
(1)定义一个新的优化器
假设要添加一个优化器名为MyOptimizer,现有一个arguments包含a,b,c
我们需要在一个文件中实现一个新的优化器比如mmseg/core/optimizer/my_optimizer.py
from mmcv.runner import OPTIMIZERS
from torch.optim import Optimizer
@OPTIMIZERS.register_module
class MyOptimizer(Optimizer):
def __init__(self, a, b, c)
(2)将优化器添加到注册表
然后在mmseg/core/optimizer/__init__.py中添加这个模块,注册器会找到这个新模块并且添加它
from .my_optimizer import MyOptimizer
使用custom_imports在配置文件中手动导入
custom_imports = dict(imports=['mmseg.core.optimizer.my_optimizer'], allow_failed_imports=False)
该模块mmseg.core.optimizer.my_optimizer将在程序开始时导入,MyOptimizer然后自动注册该类。请注意,仅MyOptimizer应导入包含该类的包。 mmseg.core.optimizer.my_optimizer.MyOptimizer 无法直接导入。
实际上,只要模块根目录可以位于中,用户就可以使用这种导入方法使用完全不同的文件目录结构PYTHONPATH
(3)在配置文件中指定优化器
你可以用optimizer文件中的MyOptimizer来配置文件,在配置文件中,优化器被optimizer文件定义为如下
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
使用自己的优化器可以改为
optimizer = dict(type='MyOptimizer', a=a_value, b=b_value, c=c_value)
自定义优化器构造函数
某些模型可能具有一些特定于参数的设置以进行优化,例如BatchNorm层的权重衰减。用户可以通过自定义优化器构造函数来进行那些细粒度的参数调整。
from mmcv.utils import build_from_cfg
from mmcv.runner.optimizer import OPTIMIZER_BUILDERS, OPTIMIZERS
from mmseg.utils import get_root_logger
from .my_optimizer import MyOptimizer
@OPTIMIZER_BUILDERS.register_module()
class MyOptimizerConstructor(object):
def __init__(self, optimizer_cfg, paramwise_cfg=None):
def __call__(self, model):
return my_optimizer
附加设置
一些可以稳定训练或加快训练速度的常用设置
使用渐变剪辑来稳定训练:某些模型需要渐变剪辑来剪辑梯度以稳定训练过程。一个例子如下:
optimizer_config = dict(
_delete_=True, grad_clip=dict(max_norm=35, norm_type=2))
使用动量进度表来加速模型收敛:我们支持动量进度表根据学习率修改模型的动量,这可以使模型更快地收敛。动量调度程序通常与LR调度程序一起使用,例如,以下配置用于3D检测以加速收敛。
lr_config = dict(
policy='cyclic',
target_ratio=(10, 1e-4),
cyclic_times=1,
step_ratio_up=0.4,
)
momentum_config = dict(
policy='cyclic',
target_ratio=(0.85 / 0.95, 1),
cyclic_times=1,
step_ratio_up=0.4,
)
自定义训练计划
一般情况下我们将逐步学习率与40k/80k计划一起使用,mmsegmentation支持许多学习率计划,例如CosineAnnealing和Poly计划
Step schedule:
lr_config = dict(policy='step', step=[9, 10])
ConsineAnnealing schedule:
lr_config = dict(
policy='CosineAnnealing',
warmup='linear',
warmup_iters=1000,
warmup_ratio=1.0 / 10,
min_lr_ratio=1e-5)
自定义工作流程
工作流是(阶段,时期)的列表,用于指定运行顺序和时期。默认情况下,它设置为
workflow = [('train', 1)]
这意味着要进行1个时期的训练。有时,用户可能想检查有关验证集中模型的某些指标(例如,损失,准确性)。在这种情况下,我们可以将工作流程设置为
[('train', 1), ('val', 1)]
运行1个训练时间和1个验证时间。
注意事项:
1.val epoch期间不会更新模型的参数
2.配置中的关键字total_epochs仅控制训练时期的数量,不会影响验证工作流程
3.工作流[('train',1),('val',1)]和[('train',1)]不会更改EvalHook的行为,因为EvalHook由after_train_epoch调用,并且验证工作流仅影响被调用的钩子 通过after_val_epoch。 因此,[('train',1),('val',1)]和[('train',1)]之间的唯一区别是,跑步者将在每个训练时期后根据验证集计算损失
自定义挂钩
使用MMCV中实现的挂钩
如果该挂钩已在MMCV中实现,则可以直接修改配置以使用该挂钩,如下所示
custom_hooks = [
dict(type='MyHook', a=a_value, b=b_value, priority='NORMAL')
]
修改默认的运行时挂钩
有一些未通过注册的常见钩子custom_hooks,它们是
log_config
checkpoint_config
评估
lr_config
optimizer_config
动量配置
在这些钩子中,只有记录器钩子的优先级为VERY_LOW,其他钩子的优先级为NORMAL。 上述教程已经介绍了如何修改optimizer_config,momentum_config和lr_config。 在这里,我们揭示了如何使用log_config,checkpoint_config和评估功能。
检查点配置
MMCV运行程序将用于checkpoint_config初始化CheckpointHook。
checkpoint_config = dict(interval=1)
用户可以设置max_keep_ckpts为仅保存少量检查点,或者通过决定是否存储优化器的状态字典save_optimizer。参数的更多详细信息在这里
日志配置
该log_config包装的多个记录器的钩和能够设定的时间间隔。现在MMCV支持WandbLoggerHook,MlflowLoggerHook和TensorboardLoggerHook。详细用法可以在doc中找到。
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook'),
dict(type='TensorboardLoggerHook')
])
评估配置
评估配置将用于初始化EvalHook。 除键间隔外,其他参数(例如metric)将传递给数据集。evaluate()
evaluation = dict(interval=1, metric='mIoU')