【新手入门】课程10-深度学习进阶NLP-机器翻译
任务介绍
机器翻译:即用计算机实现从源语言到目标语言转换的过程,是自然语言处理的重要研究领域之一。
源语言:被翻译的语言
目标语言:翻译后的结果语言
数据集介绍
数据集:WMT-14数据集
该数据集有193319条训练数据,6003条测试数据,词典长度为30000。
Paddle接口paddle.dataset.wmt14中默认提供了一个经过预处理的较小规模的数据集。
数据预处理:
将每个源语言到目标语言的平行语料库文件合并为一个文件,合并每个xxx.src和xxx.trg文件为xxx;xxx中的第i行内容为xxx.src的第i行和xxx.trg中的第i行连接,用“t”分隔。
创建训练数据的源字典和目标字典。每个字典都有DICSIZE个单词,包括语料中词频最高的DICSIZE-3个单词和三个特殊符号:
-
< s >表示序列的开始 -
< e >表示序列的结束 -
< unk >表示未登录词
实践流程
1、准备数据
2、配置网络
-
定义网络 -
定义损失函数 -
定义优化算法
3、训练网络
4、模型评估
5、模型预测
In[ ]
#导入需要的包
import numpy as np
import paddle as paddle
import paddle.fluid as fluid
from PIL import Image
import os
import paddle.fluid.layers as pd
import sysIn[ ]
dict_size = 30000#字典维度
source_dict_dim = target_dict_dim = dict_size# source_dict_dim:源语言字典维度 target_dict_dim:目标语言字典维度
hidden_dim = 32 #解码中隐层大小
decoder_size = hidden_dim#解码中隐层大小
word_dim = 32 #词向量维度
batch_size = 200 #数据提供器每次读入的数据批次大小
max_length = 8#生成句子的最大长度
topk_size = 50
beam_size = 2 #柱宽度
is_sparse = True#系数矩阵
model_save_dir = "machine_translation.inference.model"In[ ]
# *********获取训练数据读取器和测试数据读取器train_reader 和test_reader***************
train_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.wmt14.train(dict_size),buf_size=1000),#dict_size:字典维度 buf_size:乱序时的缓存大小
batch_size=batch_size) #batch_size:批次数据大小
#加载预测的数据
test_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.wmt14.test(dict_size), buf_size=1000),
batch_size=batch_size)编码器解码器框架
解决的问题:由任意一个长度的原序列到另一个长度的目标序列的变化问题
-
编码:将整个原序列表征成一个向量 -
解码:通过最大化预测序列概率,从中解码出整个目标序列
柱搜索算法
-
启发式搜索算法:在图或树中搜索每一步的最优扩展节点 -
贪心算法:每一步最优,全局不一定最优 -
场景:解空间非常大,内存装不下所有展开解的系统
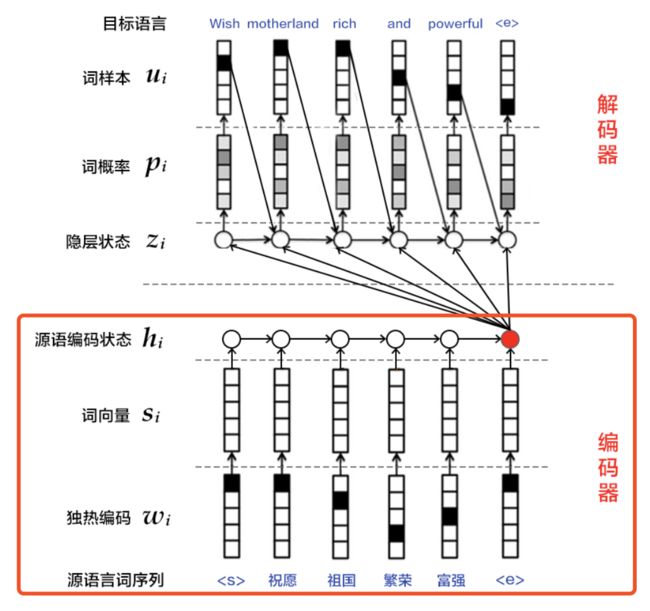
In[ ]
#************************实现编码器*******************************
def encoder():
#输入是一个文字序列,被表示成整型的序列。
src_word_id = pd.data(
name="src_word_id", shape=[1], dtype='int64', lod_level=1)
#将上述编码映射到低维语言空间的词向量
src_embedding = pd.embedding(
input=src_word_id, #输入为独热编码
size=[dict_size, word_dim],#dict_size:字典维度 word_dim:词向量维度
dtype='float32',
is_sparse=is_sparse,
param_attr=fluid.ParamAttr(name='vemb'))
#全连接
fc1 = pd.fc(input=src_embedding, size=hidden_dim * 4, act='tanh')
#初始化lstm网络
lstm_hidden0, lstm_0 = pd.dynamic_lstm(input=fc1, size=hidden_dim * 4)
#完成所有时间步内的lstm计算,得到编码的最终输出
encoder_out = pd.sequence_last_step(input=lstm_hidden0)
return encoder_out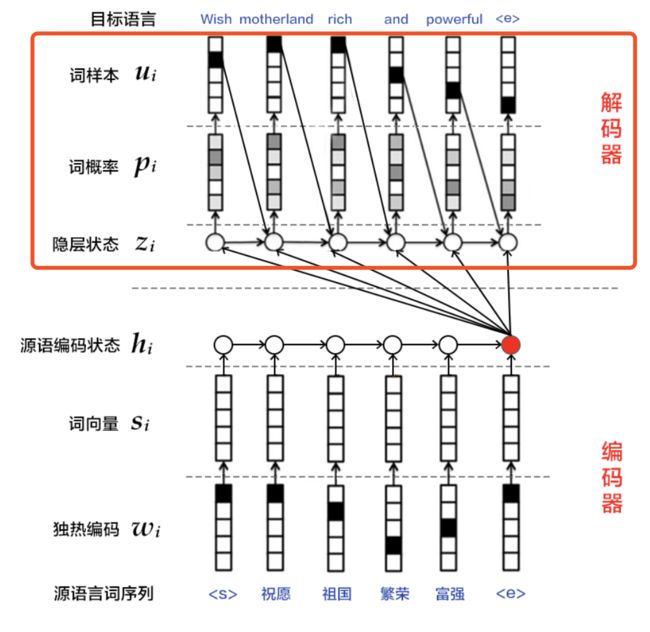
In[ ]
#************************定义训练模式下的解码器*******************************
def train_decoder(context):
#获取目标语言序列
trg_language_word = pd.data(
name="target_language_word", shape=[1], dtype='int64', lod_level=1)
#获取目标语言的词向量
trg_embedding = pd.embedding(
input=trg_language_word,
size=[dict_size, word_dim],#dict_size:字典维度 word_dim:词向量维度
dtype='float32',
is_sparse=is_sparse,
param_attr=fluid.ParamAttr(name='vemb'))
rnn = pd.DynamicRNN()
with rnn.block():
current_word = rnn.step_input(trg_embedding)#current_word:当前节点的输入
pre_state = rnn.memory(init=context, need_reorder=True)#pre_state:上个节点的输出
current_state = pd.fc(
input=[current_word, pre_state], size=decoder_size, act='tanh')#得到当前节点的输出
#对可能输出的单词进行打分,再用softmax函数进行归一化得到当前节点的概率
current_score = pd.fc(input=current_state, size=target_dict_dim, act='softmax')
#更新当前节点的输出为上个节点的输出
rnn.update_memory(pre_state, current_state)
rnn.output(current_score)
return rnn()In[ ]
#得到编码器
context = encoder()
#得到解码器
rnn_out = train_decoder(context)In[ ]
# 定义损失函数&计算平均
cost = pd.cross_entropy(input=rnn_out, label=label)
avg_cost = pd.mean(cost)In[ ]
#定义优化方法
optimizer= fluid.optimizer.Adagrad(
learning_rate=1e-4,
regularization=fluid.regularizer.L2DecayRegularizer(#正则化函数
regularization_coeff=0.1))
opts = optimizer.minimize(avg_cost)In[ ]
#定义张量
label = pd.data(name="target_language_next_word", shape=[1], dtype='int64', lod_level=1)In[ ]
#*************创建Executor*********************
# 定义使用CPU还是GPU,使用CPU时use_cuda = False,使用GPU时use_cuda = True
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
exe = fluid.Executor(place)
# 进行参数初始化
exe.run(fluid.default_startup_program())In[ ]
#定义数据映射器
feeder = fluid.DataFeeder( place=place,feed_list=[ 'src_word_id',
'target_language_word',
'target_language_next_word'])In[ ]
for pass_id in range(1):
# 进行训练
train_cost = 0
for batch_id, data in enumerate(train_reader()): #遍历train_reader迭代器
train_cost = exe.run(program=fluid.default_main_program(), #运行主程序
feed=feeder.feed(data), #喂入一个batch的数据
fetch_list=[avg_cost]) #fetch均方误差
if batch_id % 10 == 0: #每40次batch打印一次训练、进行一次测试
print('Pass:%d, Batch:%d, Cost:%0.5f' % (pass_id, batch_id, train_cost[0]))
#保存模型
# 如果保存路径不存在就创建
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
print ('save models to %s' % (model_save_dir))
fluid.io.save_inference_model(model_save_dir, ['src_word_id'], [rnn_out], exe)In[ ]
###
###预测阶段
###
dict_size = 30000
source_dict_dim = target_dict_dim = dict_size
hidden_dim = 32
word_dim = 32
batch_size = 2
max_length = 8
topk_size = 50
beam_size = 2
is_sparse = True
decoder_size = hidden_dim
#预测阶段编码器
def encoder():
src_word_id = pd.data(
name="src_word_id", shape=[1], dtype='int64', lod_level=1)
src_embedding = pd.embedding(
input=src_word_id,
size=[dict_size, word_dim],
dtype='float32',
is_sparse=is_sparse,
param_attr=fluid.ParamAttr(name='vemb'))
fc1 = pd.fc(input=src_embedding, size=hidden_dim * 4, act='tanh')
lstm_hidden0, lstm_0 = pd.dynamic_lstm(input=fc1, size=hidden_dim * 4)
encoder_out = pd.sequence_last_step(input=lstm_hidden0)
return encoder_out假设字典为[a,b,c],beam size选择2,则如下图有:
1、在生成第1个词的时候,选择概率最大的2个词,那么当前序列就是a或b;
2、生成第2个词的时候,我们将当前序列a或b,分别与字典中的所有词进行组合,得到新的6个序列aa ab ac ba bb bc,然后从其中选择2个概率最高的,作为当前序列,即ab或bb;
3、不断重复这个过程,直到遇到结束符为止。最终输出2个概率最高的序列。

In[ ]
#预测阶段解码器
def decode(context):
init_state = context
array_len = pd.fill_constant(shape=[1], dtype='int64', value=max_length)
counter = pd.zeros(shape=[1], dtype='int64', force_cpu=True)
# fill the first element with init_state
state_array = pd.create_array('float32')
pd.array_write(init_state, array=state_array, i=counter)
# ids, scores as memory
ids_array = pd.create_array('int64')
scores_array = pd.create_array('float32')
init_ids = pd.data(name="init_ids", shape=[1], dtype="int64", lod_level=2)
init_scores = pd.data(
name="init_scores", shape=[1], dtype="float32", lod_level=2)
pd.array_write(init_ids, array=ids_array, i=counter)
pd.array_write(init_scores, array=scores_array, i=counter)
cond = pd.less_than(x=counter, y=array_len)
while_op = pd.While(cond=cond)
with while_op.block():
pre_ids = pd.array_read(array=ids_array, i=counter)
pre_state = pd.array_read(array=state_array, i=counter)
pre_score = pd.array_read(array=scores_array, i=counter)
# expand the lod of pre_state to be the same with pre_score
pre_state_expanded = pd.sequence_expand(pre_state, pre_score)
pre_ids_emb = pd.embedding(
input=pre_ids,
size=[dict_size, word_dim],
dtype='float32',
is_sparse=is_sparse,
param_attr=fluid.ParamAttr(name='vemb'))
# use rnn unit to update rnn
current_state = pd.fc(
input=[pre_state_expanded, pre_ids_emb],
size=decoder_size,
act='tanh')
current_state_with_lod = pd.lod_reset(x=current_state, y=pre_score)
################################
# use score to do beam search
################################
current_score = pd.fc(
input=current_state_with_lod, size=target_dict_dim, act='softmax')
topk_scores, topk_indices = pd.topk(current_score, k=beam_size)
# calculate accumulated scores after topk to reduce computation cost
accu_scores = pd.elementwise_add(
x=pd.log(topk_scores), y=pd.reshape(pre_score, shape=[-1]), axis=0)
selected_ids, selected_scores = pd.beam_search(
pre_ids,
pre_score,
topk_indices,
accu_scores,
beam_size,
end_id=10,
level=0)
with pd.Switch() as switch:
with switch.case(pd.is_empty(selected_ids)):
pd.fill_constant(
shape=[1], value=0, dtype='bool', force_cpu=True, out=cond)
with switch.default():
pd.increment(x=counter, value=1, in_place=True)
# update the memories
pd.array_write(current_state, array=state_array, i=counter)
pd.array_write(selected_ids, array=ids_array, i=counter)
pd.array_write(selected_scores, array=scores_array, i=counter)
# update the break condition: up to the max length or all candidates of
# source sentences have ended.
length_cond = pd.less_than(x=counter, y=array_len)
finish_cond = pd.logical_not(pd.is_empty(x=selected_ids))
pd.logical_and(x=length_cond, y=finish_cond, out=cond)
translation_ids, translation_scores = pd.beam_search_decode(
ids=ids_array, scores=scores_array, beam_size=beam_size, end_id=10)
return translation_ids, translation_scores
def decode_main(use_cuda):
# if use_cuda and not fluid.core.is_compiled_with_cuda():
# return
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
exe = fluid.Executor(place)
# 进行参数初始化
exe.run(fluid.default_startup_program())
context = encoder()
translation_ids, translation_scores = decode(context)
fluid.io.load_persistables(executor=exe, dirname=model_save_dir)
init_ids_data = np.array([1 for _ in range(batch_size)], dtype='int64')
init_scores_data = np.array(
[1. for _ in range(batch_size)], dtype='float32')
init_ids_data = init_ids_data.reshape((batch_size, 1))
init_scores_data = init_scores_data.reshape((batch_size, 1))
init_lod = [1] * batch_size
init_lod = [init_lod, init_lod]
init_ids = fluid.create_lod_tensor(init_ids_data, init_lod, place)
init_scores = fluid.create_lod_tensor(init_scores_data, init_lod, place)
test_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.wmt14.test(dict_size), buf_size=1000),
batch_size=batch_size)
feed_order = ['src_word_id']
feed_list = [
fluid.default_main_program().global_block().var(var_name)
for var_name in feed_order
]
feeder = fluid.DataFeeder(feed_list, place)
src_dict, trg_dict = paddle.dataset.wmt14.get_dict(dict_size)
#开始预测结果
for data in test_reader():
feed_data = map(lambda x: [x[0]], data)
feed_dict = feeder.feed(feed_data)
feed_dict['init_ids'] = init_ids
feed_dict['init_scores'] = init_scores
results = exe.run(
fluid.default_main_program(),
feed=feed_dict,
fetch_list=[translation_ids, translation_scores],
return_numpy=False)
result_ids = np.array(results[0])
result_ids_lod = results[0].lod()
result_scores = np.array(results[1])
print("Original sentence:")
print(" ".join([src_dict[w] for w in feed_data[0][0][1:-1]]))
print("Translated score and sentence:")
for i in xrange(beam_size):
start_pos = result_ids_lod[1][i] + 1
end_pos = result_ids_lod[1][i + 1]
print("%d\t%.4f\t%s\n" % (
i + 1, result_scores[end_pos - 1],
" ".join([trg_dict[w] for w in result_ids[start_pos:end_pos]])))
break
def main(use_cuda):
decode_main(False) # Beam Search does not support CUDA
if __name__ == '__main__':
main(False)