Kaldi语音识别技术(三) ----- 完成L.fst的生成
Kaldi语音识别技术(三) ----- 完成L.fst的生成
文章目录
- Kaldi语音识别技术(三) ----- 完成L.fst的生成
-
-
- 基础知识
- 一、运行环境准备
- 二、文件准备
-
- lexicon.txt
- phones.txt
- silence_phones.txt
- nonsilence_phones.txt
- optional_silence.txt
- 三、L.fst的生成
-
- prepare_lang.sh 脚本的使用
- 四、L.fst可视化
-
- 1. fstprint 查看
- 2. fstdraw 绘图
- 五、小的L.fst
-
- 文件准备
- 生成并查看
- 六、封装成shell脚本调用
-
基础知识
一个完整的Kaldi需要得到下面四个FST
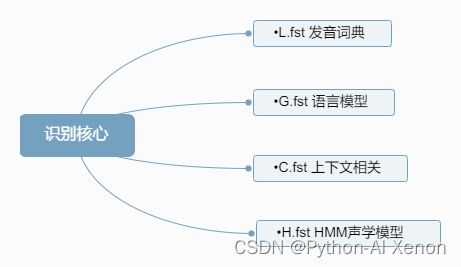
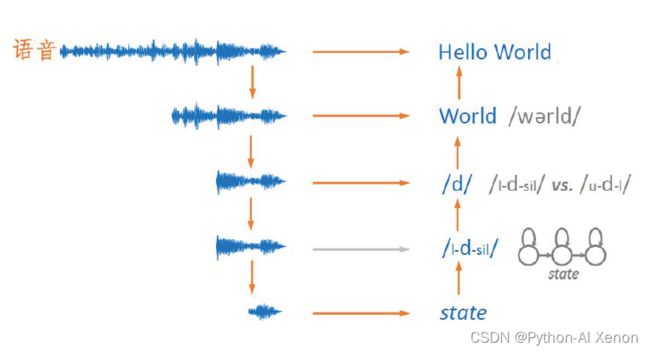
识别流程如下:
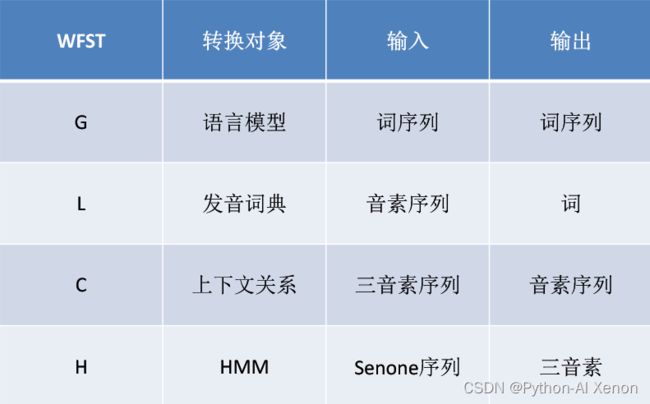
本章节完成以下内容:(路径以我写的为准,自己根据情况更改)
一、运行环境准备
- 安装 dot 相关的包
yum install ghostscript
yum install graphviz
- 软链接运行环境(亲测使用软连接的会使L_disambig.fst生成失败,用不了,可忽略)
cd /root/kaldi/kaldi/data
ln -s /root/kaldi/kaldi/egs/wsj/s5/utils/ ./
ln -s /root/kaldi/kaldi/egs/wsj/s5/steps/ ./
- 执行 path.sh 使用kaldi环境, 其在
/root/kaldi/kaldi/egs/wsj/s5/下面,可以自己cp后更改位置
二、文件准备
所有文件放在 ~/kaldi/data/dict 路径下面 (而不是 data/local/dict)
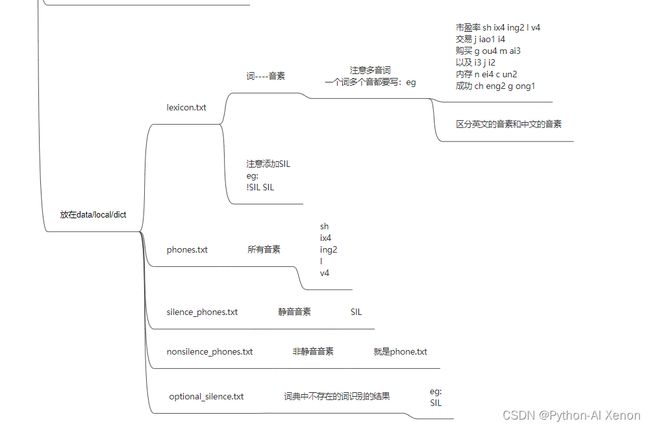
lexicon.txt
•字典
使用之前的 lexicon.txt ,放在路径 ~/kaldi/data/dict下面
phones.txt
•所有音素
这里我们使用python脚本得到所有音素,代码如下:
# -*- coding: utf-8 -*-
# @Author : yxn
# @Date : 2022/11/6 21:24
# @IDE : PyCharm(2022.2.3) Python3.9.13
def get_phones(data):
"""得到所有音素,生成phones.txt"""
# 使用集合进行去重处理
phones = set() # set集合可实现自动去重
with open(data, "r", encoding="utf-8") as f:
for i in f.readlines():
# 获取每一个音素操作
[phones.add(x) for x in i.strip("\n").strip().split("\t")[1].split(" ")]
# 保存文件
save_path = "/root/kaldi/data/dict/phones.txt" # 保存位置 ~/kaldi/data/dict/
with open(save_path, "w", encoding="utf-8") as f:
for i in phones:
f.writelines(i + "\n")
print("phones.txt生成成功! ")
if __name__ == '__main__':
lexicon_path = "../data/dict/lexicon.txt" # /root/kaldi/kaldi/data/dict/lexicon.txt
get_phones(lexicon_path)
silence_phones.txt
•静音音素
vim silence_phones.txt
# 输入
SIL
# wq保存退出
nonsilence_phones.txt
•非静音音素,就是去除静音音素的 phones.txt
cp phones.txt nonsilence_phones.txt # 复制phones.txt
vim nonsilence_phones.txt
# 删除 SIL 后保存退出
optional_silence.txt
•词典中不存在的词识别的结果
为了方便我们将其识别为 SIL
vim optional_silence.txt
# 输入 SIL 后保存退出
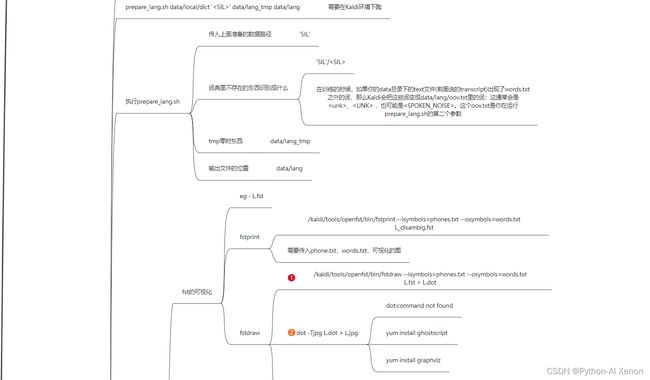
三、L.fst的生成
prepare_lang.sh 脚本的使用
根据经验需要到 kaldi环境执行 我的环境为~/kaldi/kaldi/egs/wsj/s5
cd ~/kaldi/kaldi/egs/wsj/s5
utils/prepare_lang.sh ~/kaldi/data/dict '' ~/kaldi/data/tmp/01 ~/kaldi/data/L/lang
# prepare_lang.sh 一共需要输入4个参数,各参数解释见基础知识
如果执行失败参考 https://blog.csdn.net/yxn4065/article/details/127723474 添加环境变量!
执行成功输出结果如下: (全部为SUCCESS则成功)
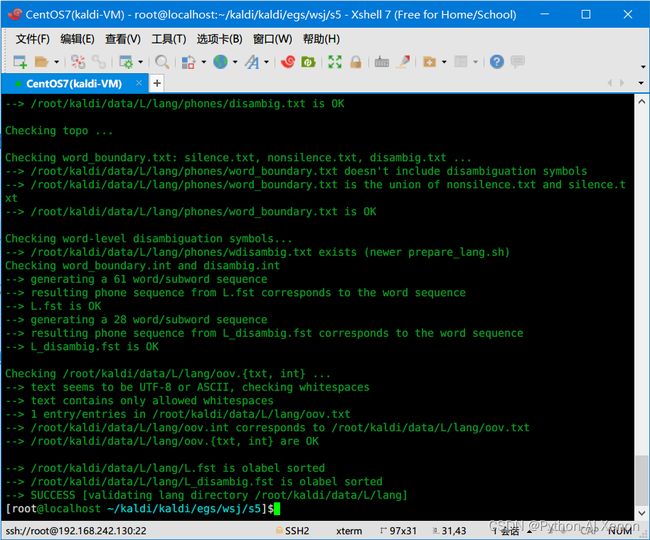
同时 ~/kaldi/data/L/lang目录下会生成以下文件:
![]()
•1、L.fst
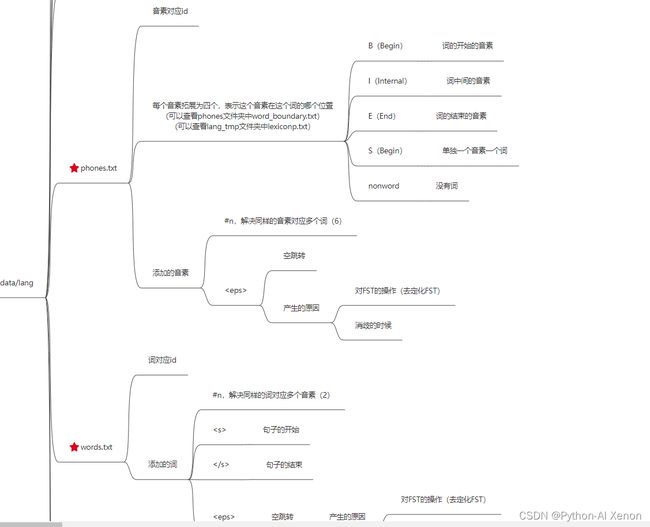
•2、phones.txt 所有音素对应的id
•3、words.txt 所有词对应的id
•4、oov.txt 词典之外的词===>SIL
•5、oov.int 词典之外的词id
•6、topo HMM状态结构图
•7、L_disambig.fst 消岐后的L.fst
各文件详细说明见下面:
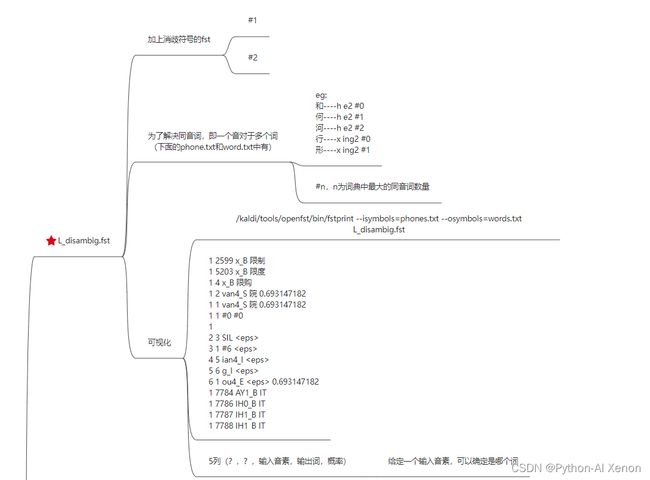
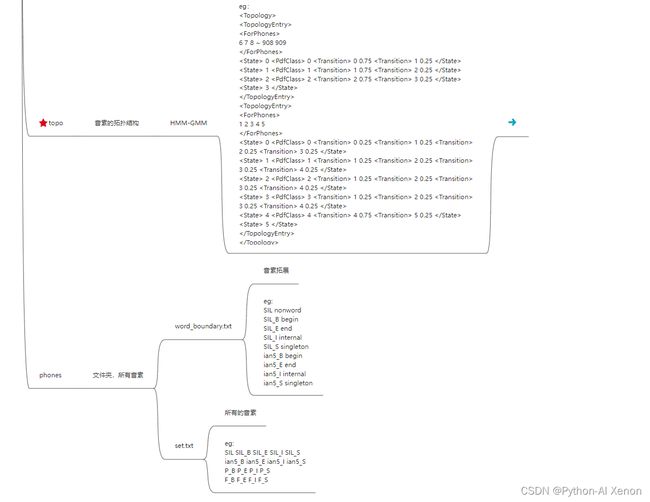
~/kaldi/data/tmp/01目录下会生成以下文件:
![]()
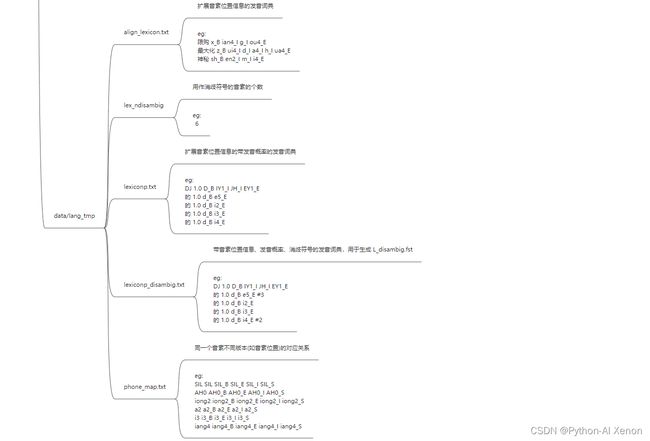
四、L.fst可视化
关于 phones.txt 的内容说明
•将一个音素重新划分为4个音素(BEIS)其中,静音音素多了一个音素。
•B:Begin 开始
•E:End 结束
•I:Internal 中间
•S:Singleton 单个
•注:可以在生成的临时目录中找到lexiconp.txt查看 ~/kaldi/data/dict/lexiconp.txt
1. fstprint 查看
cd ~/kaldi/data
fstprint --isymbols=./L/lang/phones.txt --osymbols=./L/lang/words.txt ./L/lang/L.fst > ./L/see/L_detail.txt
# 各参数解释
# --isymbols=./L/lang/phones.txt 生成的音素信息
# --osymbols=./L/lang/words.txt 生成的词信息
# ./L/lang/L.fst L.fst位置
# > ./L/see/L_detail.txt 输出保存到 ~/kaldi/data/L/see/L_detail.txt
vim ./L/see/L_detail.txt查看内容如下
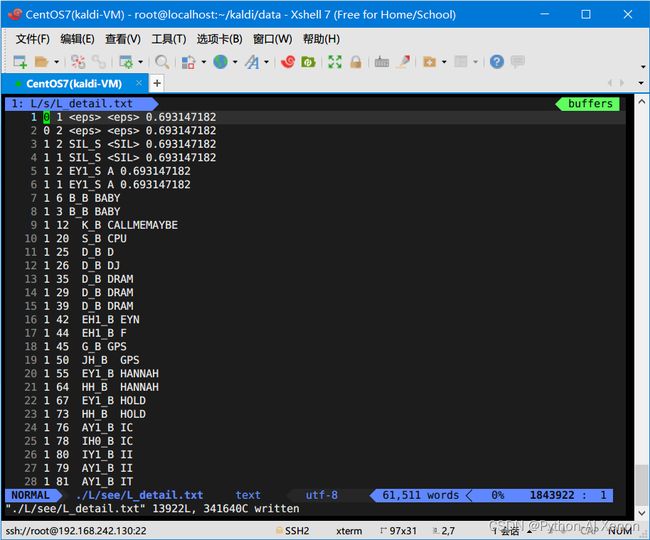
注:生成结果中的
2. fstdraw 绘图
- 生成dot文件
cd ~/kaldi/data
fstdraw --isymbols=./L/lang/phones.txt --osymbols=./L/lang/words.txt ./L/lang/L.fst > ./L/see/L.dot
# cd ~/kaldi/data/L/lang/
# fstdraw --isymbols=phones.txt --osymbols=words.txt L.fst > L.dot
# vim ./L/see/L.dot可进行查看
- 直观可视化(当前文件不建议执行下面操作,太大了会导致虚拟机卡死,时间会比较长)
cd ~/kaldi/data/L/lang
dot -Tjpg L.dot > L.jpg # 转成jpg图片
dot -Tsvg L.dot > L.svg # 转成svg矢量图(放大不会失真)
dot -Tjpg -Gdpi300 L.dot > L.jpg # 转成jpg图片并设置图片质量
五、小的L.fst
由于我们的数据比较多,导致L.fst的图片无法生成查看,所以在课程当中我们采用更少的语音来识别做为学习的辅助理解!
这里我们以 “今天天气真好 ”、“今天天气还不行 ” 这2句话来制作小的可视化数据
文件准备
mkdir -p ~/kaldi/data/dict_learn
cd ~/kaldi/data/dict_learn
•lexicon.txt
SIL
今天 j in1 t ian1
真好 zh en1 h ao3
天气 t ian1 q i4
还 h uan2
还 h ai2
不行 b u2 x ing2
•vim phones.txt
SIL
ai2
ao3
b
en1
h
i4
ian1
in1
ing2
•vim silence_phones.txt
SIL
•nonsilence_phones
ai2
ao3
b
en1
h
i4
ian1
in1
ing2
j
•vim optional_ silence.txt
SIL
生成并查看
# 1.执行prepare_lang.sh脚本生成L.fst
cd ~/kaldi/kaldi/egs/wsj/s5
utils/prepare_lang.sh ~/kaldi/data/dict_learn '' ~/kaldi/data/tmp/01_learn ~/kaldi/data/L/lang_learn
# 2. 绘图查看
cd ~/kaldi/data
fstdraw --isymbols=./L/lang_learn/phones.txt --osymbols=./L/lang_learn/words.txt ./L/lang_learn/L.fst > ./L/see/L_learn.dot
cd ~/kaldi/data/L/see
dot -Tjpg -Gdpi300 L_learn.dot > L_learn.jpg
结果如下:
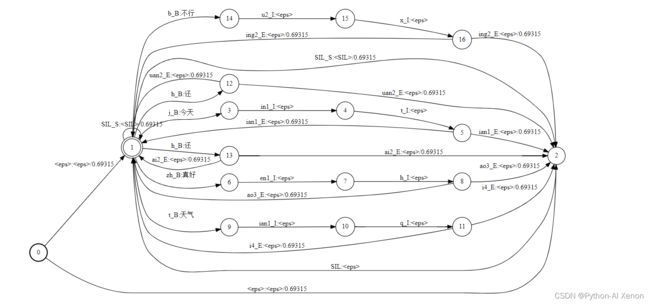
在 本机电脑上使用 scp 命令下载 (也可以用winscp,xftp等下载),如果你的CentOS安装了图形化界面可以直接查看
scp [email protected]:~/kaldi/data/L/see/L_learn.jpg ./
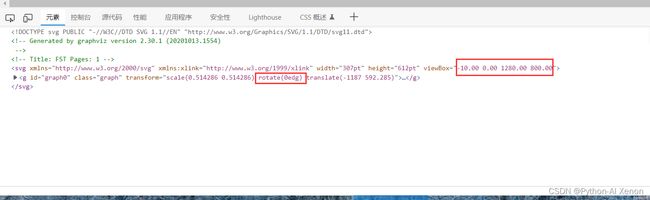
如果是生成 的svg矢量图,旋转方式如下:
F12 打开开发者模式,修改内容,现在图片就是正的啦
六、封装成shell脚本调用
shell命令入门: https://www.runoob.com/linux/linux-shell.html
cd ~/kaldi/data
vim run.sh
# 该脚本完成L.fst的生成
#
target=~/kaldi/kaldi/egs/wsj/s5
tar_1="_learn"
tar_2="_dism"
echo "========脚本开始执行======="
cd ${target}
. path.sh
mkdir -p ~/kaldi/data/tmp/01 ~/kaldi/data/L/lang
# 执行prepare_lang.sh脚本生成L.fst
utils/prepare_lang.sh ~/kaldi/data/dict '' ~/kaldi/data/tmp/01 ~/kaldi/data/L/lang
echo "========prepare_lang.sh执行结束======="
mkdir -p ~/kaldi/data/L/see
# 生成L.dot
fstdraw --isymbols=~/kaldi/data/L/lang/phones.txt --osymbols=~/kaldi/data/L/lang/words.txt ~/kaldi/data/L/lang/L.fst > ~/kaldi/data/L/see/L.dot
echo "========L.dot生成结束======="
# 生成 L.jpg
cd ~/kaldi/data/L/see/
dot -Tjpg -Gdpi300 L.dot > L.jpg
echo "========L.jpg 生成结束======="
## 该脚本还在完善当中