李沐动手学深度学习第4章-4.1多层感知机
在colab中运行本节内容需先安装d2l
!pip install d2l==0.14.1、隐藏层
我们可以通过在网络中加入一个或多个隐藏层来克服线性模型的限制, 使其能处理更普遍的函数关系类型。

多层感知机可以通过隐藏神经元,捕捉到输入之间复杂的相互作用, 这些神经元依赖于每个输入的值。
虽然一个单隐层网络能学习任何函数, 但并不意味着我们应该尝试使用单隐藏层网络来解决所有问题。 事实上,通过使用更深(而不是更广)的网络,我们可以更容易地逼近许多函数。
2. 激活函数
通过计算加权和并加上偏置来确定神经元是否应该被激活, 它们将输入信号转换为输出的可微运算。 大多数激活函数都是非线性的。
导入需要的包:
%matplotlib inline
import torch
from d2l import torch as d2l2.1. ReLU函数
最受欢迎的激活函数是修正线性单元(Rectified linear unit,ReLU)
RELU(x)=max(x,0)
通俗地说,ReLU函数通过将相应的活性值设为0,仅保留正元素并丢弃所有负元素。 为了直观感受一下,我们可以画出函数的曲线图。 正如从图中所看到,激活函数是分段线性的。
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.relu(x)
d2l.plot(x.detach(), y.detach(), 'x', 'relu(x)', figsize=(5, 2.5))
当输入为负时,ReLU函数的导数为0,而当输入为正时,ReLU函数的导数为1。
下面我们绘制ReLU函数的导数。
y.backward(torch.ones_like(x), retain_graph=True) #自动求导
d2l.plot(x.detach(), x.grad, 'x', 'grad of relu', figsize=(5, 2.5))
它求导表现得特别好:要么让参数消失,要么让参数通过。 这使得优化表现得更好,并且ReLU减轻了困扰以往神经网络的梯度消失问题
2.2. sigmoid函数
sigmoid函数将输入变换为区间(0, 1)上的输出。

绘制sigmoid函数。 注意,当输入接近0时,sigmoid函数接近线性变换。
y = torch.sigmoid(x)
d2l.plot(x.detach(), y.detach(), 'x', 'sigmoid(x)', figsize=(5, 2.5))
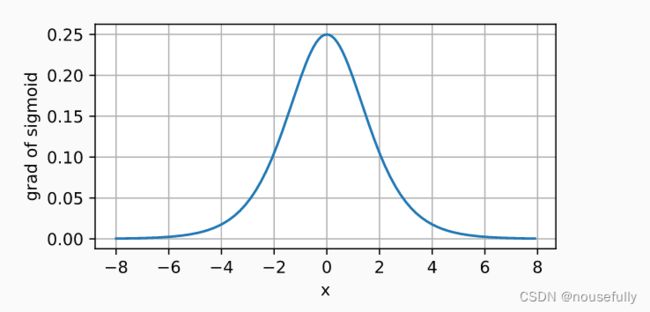
sigmoid函数的导数图像如下所示
# 清除以前的梯度
x.grad.data.zero_()
y.backward(torch.ones_like(x),retain_graph=True)
d2l.plot(x.detach(), x.grad, 'x', 'grad of sigmoid', figsize=(5, 2.5))
2.3. tanh函数
tanh(双曲正切)函数也能将其输入压缩转换到区间(-1, 1)上

当输入在0附近时,tanh函数接近线性变换。
y = torch.tanh(x)
d2l.plot(x.detach(), y.detach(), 'x', 'tanh(x)', figsize=(5, 2.5))
tanh函数的导数图像如下所示。
# 清除以前的梯度
x.grad.data.zero_()
y.backward(torch.ones_like(x),retain_graph=True)
d2l.plot(x.detach(), x.grad, 'x', 'grad of tanh', figsize=(5, 2.5))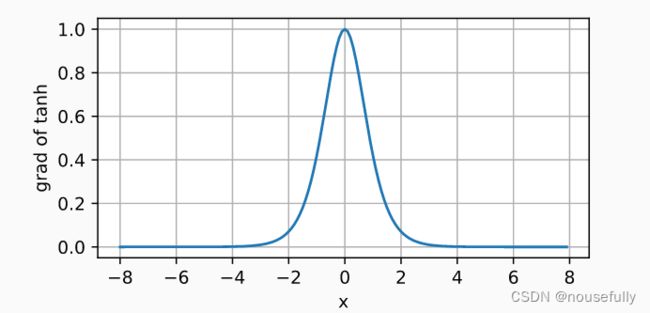
3. 小结
-
多层感知机在输出层和输入层之间增加一个或多个全连接隐藏层,并通过激活函数转换隐藏层的输出。
-
常用的激活函数包括ReLU函数、sigmoid函数和tanh函数。