使用TextRank算法进行文本摘要(python)
文本摘要的方法
Text summarization can broadly be divided into two categories — Extractive Summarization and Abstractive Summarization.
1.Extractive Summarization: These methods rely on extracting several parts, such as phrases and sentences, from a piece of text and stack them together to create a summary. Therefore, identifying the right sentences for summarization is of utmost importance in an extractive method.
2.Abstractive Summarization: These methods use advanced NLP techniques to generate an entirely new summary. Some parts of this summary may not even appear in the original text.
在这篇文章中主要介绍了提取摘要
PageRank
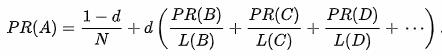
TextRank算法
现在,我们对PageRank有所了解,让我们了解TextRank算法。我在下面列出了这两种算法之间的相似之处:
我们使用句子代替网页
任何两个句子之间的相似度都等同于网页转换概率
相似度得分存储在一个正方形矩阵中,类似于用于PageRank的矩阵M
TextRank是一种提取性和无监督的文本摘要技术。让我们看一下我们将要遵循的TextRank算法的流程:
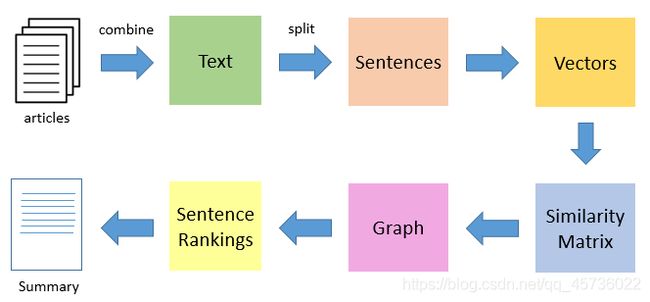
1.第一步是将文章中包含的所有文本连接起来
2.然后将文本分成单个句子
3.在下一步中,我们将为每个句子找到向量表示(词嵌入)
4.然后计算句子向量之间的相似度并将其存储在矩阵中
5.然后将相似度矩阵转换为图,以句子为顶点,以相似度分数为边,以计算句子等级
6.最后,一定数量的排名靠前的句子构成了最终摘要
算法实现
导入所需的库
import numpy as np
import pandas as pd
import nltk
nltk.download('punkt')#一次执行
import re
读取数据
df = pd.read_csv(“ tennis_articles_v4.csv”)
检查数据
df.head()
df ['article_text'] [0]
输出
"Maria Sharapova has basically no friends as tennis players on the WTA Tour. The Russian player
has no problems in openly speaking about it and in a recent interview she said: 'I don’t really
hide any feelings too much. I think everyone knows this is my job here. When I’m on the courts
or when I’m on the court playing, I’m a competitor and I want to beat every single person whether
they’re in the locker room or across the net…
将文本拆分成句子
from nltk.tokenize import sent_tokenize
sentences = []
for s in df['article_text']:
sentences.append(sent_tokenize(s))
sentences = [y for x in sentences for y in x] # flatten list
输出
[‘Maria Sharapova has basically no friends as tennis players on the WTA Tour.’,
“The Russian player has no problems in openly speaking about it and in a recent
interview she said: 'I don’t really hide any feelings too much.”,
‘I think everyone knows this is my job here.’,
“When I’m on the courts or when I’m on the court playing,
I’m a competitor and I want to beat every single person whether they’re in the
locker room or across the net.So I’m not the one to strike up a conversation about
the weather and know that in the next few minutes I have to go and try to win a tennis match.”,
“I’m a pretty competitive girl.”]
下载GloVe词嵌入
!wget http://nlp.stanford.edu/data/glove.6B.zip
!unzip glove*.zip
# Extract word vectors
word_embeddings = {}
f = open('glove.6B.100d.txt', encoding='utf-8')
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
word_embeddings[word] = coefs
f.close()
文字预处理
# remove punctuations, numbers and special characters
clean_sentences = pd.Series(sentences).str.replace("[^a-zA-Z]", " ")
# make alphabets lowercase
clean_sentences = [s.lower() for s in clean_sentences]
nltk.download('stopwords')
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
# function to remove stopwords
def remove_stopwords(sen):
sen_new = " ".join([i for i in sen if i not in stop_words])
return sen_new
# remove stopwords from the sentences
clean_sentences = [remove_stopwords(r.split()) for r in clean_sentences]
句子的向量表示
sentence_vectors = []
for i in clean_sentences:
if len(i) != 0:
v = sum([word_embeddings.get(w, np.zeros((100,))) for w in i.split()])/(len(i.split())+0.001)
else:
v = np.zeros((100,))
sentence_vectors.append(v)
相似度矩阵准备
# similarity matrix
sim_mat = np.zeros([len(sentences), len(sentences)])
from sklearn.metrics.pairwise import cosine_similarity
for i in range(len(sentences)):
for j in range(len(sentences)):
if i != j:
sim_mat[i][j] = cosine_similarity(sentence_vectors[i].reshape(1,100), sentence_vectors[j].reshape(1,100))[0,0]
应用PageRank算法
import networkx as nx
nx_graph = nx.from_numpy_array(sim_mat)
scores = nx.pagerank(nx_graph)
摘要提取
ranked_sentences = sorted(((scores[i],s) for i,s in enumerate(sentences)), reverse=True)
# Extract top 10 sentences as the summary
for i in range(10):
print(ranked_sentences[i][1])
下一步是什么?
自动文本摘要是研究的热门话题,在本文中,我们仅介绍了冰山一角。展望未来,我们将探索深度学习在其中发挥重要作用的抽象文本摘要技术。此外,我们还可以研究以下汇总任务:
特定问题
多域文字摘要
单一文件摘要
跨语言文本摘要(以某种语言提供来源,以另一种语言提供摘要)
特定于算法
使用RNN和LSTM进行文本汇总
使用强化学习进行文本总结
使用生成对抗网络(GAN)进行文本摘要