Towards Semi-Supervised Deep Facial Expression Recognition with An Adaptive Confidence Margin 论文笔记
2022CVPR面部表情识别论文:面向具有自适应置信度的半监督深度面部表情识别
以下内容是对论文的翻译和重点标注及笔记,后期还会对论文在此博客进行重难点更新和总结,请随时关注此博文。论文地址在下方已给出,源码下载链接在论文里。
下载论文地址:https://arxiv.org/pdf/2203.12341.pdf
摘要
只有部分的未标记数据会被选择为大多数半监督学习方法的训练模型,这些方法的置信度分数通常高于预定义的阈值(即置信度裕度)(裕度,留有一定余地的程度,是统计学术语。统计学术语裕度是指留有一定余地的程度,允许有一定的误差)。我们认为,通过充分利用所有未标记的数据,可以进一步提高识别性能。在本文中,我们学习了一个自适应置信边际(Ada-CM)来充分利用所有的未标记数据进行半监督的深度面部表情识别。通过将每个训练阶段自适应学习的置信度进行比较,将所有未标记样本划分为两个子集: (1)子集I包括置信度不低于置信度的样本;(2)子集II包括置信度低于置信度的样本。对于子集I中的样本,我们限制它们的预测以匹配伪标签。同时,子集II中的样本参与特征水平的对比目标,学习有效的面部表情特征。我们在四个具有挑战性的数据集上广泛地评估了Ada-CM,表明我们的方法达到了最先进的性能,特别是在半监督的方式下超过了完全监督的基线。消融研究进一步证明了该方法的有效性。源代码可以在https://github.com/hangyu94/Ada-CM上找到。

图1.30名志愿者对10张面孔的信心得分,并标注了7个类别,包括惊讶、恐惧、厌恶、快乐、悲伤、愤怒和中性。每个脸的左上角都标有它的置信分数。所有的面孔根据置信得分被分为三组。研究结果表明,不同类别之间的置信度得分可能不一致,甚至同一类别内表达式之间的置信度差距也可能很大,例如,带有悲伤注释的面孔。
1介绍
面部表情识别(FER)旨在让计算机理解视觉情感。最近,深度FER的发展在很大程度上得到了大规模标记数据集的推动,如RAF-DB [16]和AffectNet [22]。然而,大规模的标签的收集是相当昂贵和困难的。此外,现有的标签往往不能做到这一点满足实际的细粒度需求,重新标记的数据需要专业人士。因此,迫切需要开发一种强大的方法来在大量没有相应标签的数据上训练模型,即半监督深度面部表情识别(SS-DFER)。
最近的半监督学习(SSL)算法通过预测未标记数据的人工标签来实现竞争激烈的性能。例如,伪标记方法[12,14,24,35]利用模型预测作为人工标记(伪标签技术就是利用在已标注数据所训练的模型在未标注的数据上进行预测,根据预测结果对样本进行筛选,再次输入模型中进行训练的一个过程),对CNN模型进行再训练。通常,FixMatch [28]探索弱增强和强增强的数据对,并只选择具有高置信度预测的未标记样本,这些样本的置信度得分高于预定义的固定阈值(例如,0.95)。
尽管在普通分类任务上具有良好的性能,但基于阈值的伪标记策略对于SS-DFER仍然具有挑战性,主要原因有两个: (1)所有类别的阈值都固定。对不同类别的面部表情有不同程度的难度分类。为了更好地理解这一点,我们随机选择来自RAF-DB [16]的图像并进行用户研究。如图1所示,对于标注有幸福的面部,置信得分远高于其他面部表情。特别是,最可能和最不可能者之间的置信差距高达28%。因此,固定的阈值对不同的面部表情是不公平的。换句话说,固定的阈值(例如,0.95)可能会导致选择太多的高置信分数的表达(例如,快乐),以及太少的低或较低的置信分数的表达(例如,厌恶)。此外,固定的设置在每个训练时期都不够自适应。(2)数据利用效率低下。在不同的类内样本的置信度得分之间存在着很大的差距。例如,标注有悲伤的人脸之间的置信度差距高达25%(见图1)。这一问题可能导致一些置信度得分较低的类内样本无法被选择作为训练模型,例如,置信度得分为0.71的悲伤度。这激励我们思考,低置信度分数的样本是如何有助于特征学习的。因此,充分利用具有自适应阈值的未标记数据对于SS-DFER是至关重要的。
为此,我们提出了一种具有自适应置信裕度(Ada-CM)的半监督DFER算法,以享受其在所有未标记数据的学习方面的自适应能力。具体来说,所提出的Ada-CM首先运行所有给定的标记数据,并根据不同面部表情的学习难度自适应地更新置信度。重要的是,置信度在训练时期逐渐提高。然后,它预测的置信分数,与学习置信边际相比所有未标记样本划分成两个子集:子集I包括置信分数高的样本(即置信分数不低于边际)和子集II包括低置信分数的样本(即置信分数低于边际)。对于子集I中的样本,Ada-CM利用强增强的未标记样本和来自其弱增强版本的伪标签来计算交叉熵损失。此外,对于子集II,我们通过应用InfoNCE损失[4]来进行特征级的对比目标来学习有效的特征。总的来说,我们的主要贡献可以总结如下:
通过自适应学习置信裕度,提出了一种新的端到端半监督DFER方法。据我们所知,这是探索SS-DFER中动态置信裕度的第一个解决方案。
•自适应置信度用于动态学习所有未标记数据进行模型训练。更重要的是,利用具有低置信度分数的样本来增强特征级别的相似性。
•在四个具有挑战性的数据集上进行的广泛实验显示了我们提出的Ada-CM的有效性。特别是,我们的方法取得了优越的性能,在半监督的方式超过了完全监督的基线。
这里我们简单讲解一下置信度和置信区间
首先要明确一点,95% 置信区间的意思并不是真值在这个区间内的概率是 95%。真值要么在,要么不在,而是有 95% 的置信区间会包含真值。置信区间是一个随机的区间。所谓随机,就是指端点为随机变量,这个随机变量通常是一个统计量,当抽取不同的样本时就对应不同的值,从而对应不同的区间。对于某些样本来说,对应的区间包含参数真值,另一些不包含。若在100次随机抽样中构造的100个区间如果95次包含了参数真值,那么置信度为95%。这就好像用渔网捞鱼,我知道一百次网下去,大约会有95次网到我想要的鱼,但是我并不知道是不是现在这一网。
置信区间又称估计区间,是用来估计参数的取值范围的。常见的52%-64%,或8-12,就是置信区间(估计区间)。当我们做某个试验时,没有办法完全消除误差,这种情况下,我们会给结果一个可接受的误差范围,统计学上叫置信区间,置信区间是随机变量,它根据所抽取的样本决定,每抽取一个样本就会有一个置信区间。
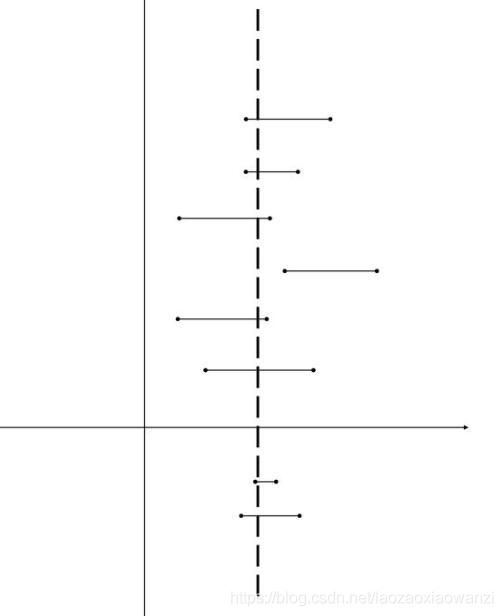
如图所示,大虚线是真实值,上面的短线是置信区间,假设我调查100次,这100次中有95次(即100个置信区间有95个置信区间)都包括真实值,那么置信度就是95%。即有的置信区间包含真实值,有的不包含,其中95%的置信区间包含真实值,置信度是95%。
2相关工作
2.1面部表情识别
近些年,已经提出了许多FER方法 [15,16,27,36]。关于FER的研究主要有两条线,即手工功能和基于深度学习的方法。传统上,早期的尝试 [11,21,23] 集中在实验室FER数据集上的纹理信息,例如CK [20] 和Oulu-CASIA [42]。在大规模无约束FER数据集 [1,16,22] 的激励下,DFER算法设计了有效的CNN网络或损失函数,以实现卓越的性能。从一开始,Li等。[16] 提出了一种保留位置的损失,以了解更多的歧视性面部表情特征。受注意机制的启发,Wang等 [32] 提出了基于区域的注意网络来捕获重要的面部区域。Li等 [19] 探索了部分闭塞的面部表情识别。此外,一些作品 [27,31,39] 考虑了DFER中的不一致注释问题。此外,薛等人。[36] 首先探索了基于变压器的DFER的关系感知表示。
上述方法以完全监督的方式执行FER。不同的是,Florea等人 [7] 提出了MixMatch [3] 的扩展,即Margin-Mix,并利用未标记的样本来解决密集区问题。实际上,边距混合通过类中心的嵌入而不是置信边距来确定未标记样本的人工标签。此外,中心更新既昂贵又耗时。据我们所知,尚未针对SS-DFER任务提出基于阈值的伪标记方法。在我们的工作中,自适应置信度裕度旨在产生具有高置信度得分的未标记样本的高质量伪标签。
2.2半监督学习
近年来,半监督学习方法已成功应用于一些具有挑战性的问题 [28444,40]。关于SSL的现有工作部署了一致性正则化 [26,34],熵最小化 [8,14] 和传统正则化 [3],以利用未标记的数据。其中,伪标注是从模型预测中获取硬标注的一种先锋SSL方法。特别是,基于阈值的方法 [25,28] 选择具有高置信度预测的未标记样本。FixMatch [28] 和UDA [34] 基于固定阈值获得伪标签,并利用弱增强和强增强来实现一致性正则化。此外,还有几项工作对动态阈值进行了研究 [35,40]。例如,Xu等 [35] 提出了一种通用方法来动态选择具有高置信度预测的样本。在我们的工作中,这是首次尝试学习SS-DFER的自适应置信度。此外,所有未标记的样本都是学习的,这也是SSL(半监督学习)的第一次尝试。

图2。Ada-CM的说明。在每一次正向传递中,将弱增强(WA)标记的样本输入模型,以学习自适应置信裕度。具体来说,当模型的预测等于ground truth时,将相应的置信度得分输入置信裕度,然后用平均值作为学习裕度。接下来,将两个WA未标记样本分别输入模型,得到概率分布pa和pb。然后,Ada-CM根据置信度分数(即平均概率分布中的最大值pc)和置信度边际Tt c之间的关系,将所有未标记的数据划分为两个子集。最后,分别利用熵最小化目标和对比目标研究了伪标签子集I中的样本和子集II中样本的特征相似性。为了清晰起见,我们用三种颜色呈现相同的模型来区分不同的输入。
3方法
3.1问题公式化
一般来说,C-class完全监督DFER任务,有一组实例标签对C =(X,Y),其中![]() 的训练数据和相应的one-hot标签(one-hot向量这个向量的表示为一项属性的特征向量,也就是同一时间只有一个激活点(不为0),这个向量只有一个特征是不为0的,其他都是0。特别稀疏,这个稀疏矩阵用来组成一个多特征的训练集样本,相当于样本是一个二维矩阵,行代表特征数,列表示为特征数的one-hot向量),和N表示带标签训练数据的数量。传统的损失函数是对标记的训练数据的交叉熵损失:
的训练数据和相应的one-hot标签(one-hot向量这个向量的表示为一项属性的特征向量,也就是同一时间只有一个激活点(不为0),这个向量只有一个特征是不为0的,其他都是0。特别稀疏,这个稀疏矩阵用来组成一个多特征的训练集样本,相当于样本是一个二维矩阵,行代表特征数,列表示为特征数的one-hot向量),和N表示带标签训练数据的数量。传统的损失函数是对标记的训练数据的交叉熵损失:

其中pc(xi,θ)为模型参数θ对C-class的预测概率。然而,对于半监督DFER的问题,标签并不能保证是完全可用的。一般情况下,原始的训练样本被分为两个集,包括一个标记集还有一个未标记的集合。让
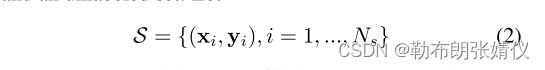
是带有标记的训练集。n是带有标记的训练数据的数量。除已标记的训练集S外,未标记的训练集具有相同的类别,记为
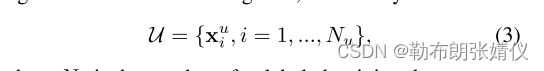
其中,Nu为未标记的训练数据的数量。
基于上述数据,现有的伪标签方法[14,28,34]旨在为一个样本xu i生成伪标签yi。然后,利用交叉熵损失对标记集S和具有伪标签的未标记集U上的模型进行优化。例如,FixMatch [28]对所有类别都采用了一个固定的阈值,并选择具有置信度得分高于该阈值的高置信度预测的未标记数据。至关重要的是,对于SSL中的一致性正则化[3],FixMatch进行了两个独立的弱增(WA)和强增(SA)操作,并基于WA数据估计伪标签。(这是一种一致性正则化的形式,其中模型应该对WA和SA数据输出相同的预测)。
更重要的是,伪标签的质量取决于阈值,而阈值可以决定置信度分数的水平。然而,现有的方法只能使确保具有高置信度分数的样本被用于模型的训练。此外,许多面部表情(如幸福)通常比某些面部表情有更高的置信得分,这对其他类别是不公平的。在这项工作中,我们关注基于置信边缘的管道,并利用所有未标记的数据,而不管置信分数的程度。
3.2提出的Ada-CM
在3.2.1中,我们首先在Sec中介绍总体框架。在3.2.2,我们提出了一个自适应置信裕度,它包含了不同的面部表情类别的阈值。此外,在3.2.3我们还介绍了对所有未标记数据的学习。最后,我们在3.2.4中展示了整个训练目标。
3.2.1整体框架
为了充分利用未标记的数据,我们提出了一种半监督的DFER方法(见图2)。与所有类别的固定阈值不同,我们提出了一个自适应置信裕度(Ada-CM),它由每个面部表情类别的不同阈值组成。然后,我们的Ada-CM通过比较置信度分数(对于已标记数据和未标记数据,置信度值可以分别视为ground truth(真实值)对应的概率值和概率分布中的最大值。)和边界,将所有未标记的数据划分为两个子集。一旦未标记数据的置信值(即平均概率分布pc中的最大值)不低于边缘中相应的阈值,SA版本的预测将通过交叉熵损失与上述WA版本的伪标签相匹配。否则,将利用对比目标来增强两个WA特征之间的相似性。因此,我们的Ada-CM主要包含两个组成部分,包括学习自适应置信裕度和对未标记数据的自适应学习。我们将依次详细阐述关键技术。
3.2.2自适应置信度
最近的SSL进展,[14,28,34]选择具有高置信分数的未标记样本,基于所有类别的固定阈值更新模型。然而,由于置信分数因类别而异,这对不同的面部表情是不公平的。为此,我们旨在基于给定的标记数据评估置信度,并建立一个自适应的置信度。请注意,我们的方法不需要额外的标记数据来确定裕度。
对于标记的集合S = {(xi,yi),i = 1,...,Ns},我们想探索不同面部表情的置信度。一个经典的思想是获得所有标记样本的预测,并计算不同的阈值,平均相应的置信度分数。然而,这种做法给SS-DFER显示了一个致命的问题。特别是,一些研究表明,在DFER数据集[27,31]中存在有噪声标签,这表明样本的某些置信度分数是不可取的。因此,我们提出了基于正确置信分数的自适应置信度。
具体来说,我们首先获得所有标记样本的预测值,并确定预测的标签。与ground truth {yi ∈ {0,1} C,i = 1,2,...,Ns} 相比,我们挑选出正确预测的样本ST = {(xi,yi,si),i = 1,...,Nst},其中,si为第i个标注数据的置信度分数,y i ∈ {1,2,...,C} 表示第i个标注,Nst为ST中的数据个数。然后,我们通过以下方式构造自适应置信度T = {(T1,...,TC)| Tc ∈ R,c = 1,...,C}

其中,Nst反映了在St中样本注释的数量。众所周知,随着epoch的增加,DFER模型的判别能力更强。因此,我们认为置信度也随着训练epoch而自适应地提高。在数学上,epoch t的置信度由下式给出
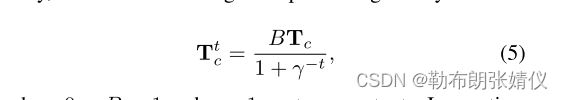
其中0
3.2.3对未标记数据进行自适应学习
建议的自适应置信度是确定置信度得分水平的重要标准。为了有效利用所有未标记的样本,我们设计了一种自适应学习策略,以探索所有未标记的数据以更新模型参数
为此,我们建议根据上述自适应置信裕度对所有未标记数据进行自适应学习。具体来说,我们首先生成两个WA版本xa i = Ta(xu i) 和xb i = Tb(xu i),并利用相同的模型来提取面部表情特征和概率分布。基于两个概率分布pa和pb,我们计算平均概率分布

其中pc表示数据xu i关于c类的概率分布。现在,自适应学习策略比较两个值,即max(pc) 和Tt argmax c pc,以动态地将所有未标记数据划分为包括具有高置信度分数的样本的子集I和包括具有低置信度分数的样本的子集II。
对于子集I中的样本,为了方便起见,我们将平均值保留为当前时期的伪标签,即yi = argmax c pc,其中yi表示one-hot标签。为了实现一致性正则化(为了减少过拟合现象, 典型的监督学习中会添加一个新的损失项. 在半监督学习中, 同样存在一种正则化方法, 即一致性正则化),我们采用了强增强操作,并使SA版本的预测与从两个WA版本获得的伪标签相匹配。因此,给定一个高置信度样本xu i,无监督损失Lu定义为SA版本xs i = Ts(xu i) 与yi之间的交叉熵损失:
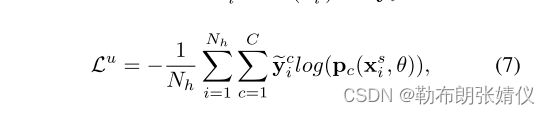
其中Nh表示子集I中的数据数量。
对于子集II中的样本,由于低置信度预测不能令人信服,因此不能使用交叉熵损失来指导模型的学习。受对比学习 [4,17,37] 的启发,我们考虑了同一未标记数据的两个WA版本之间的关系,以提高面部表情特征的判别能力。具体地说,特征级相似性首先通过
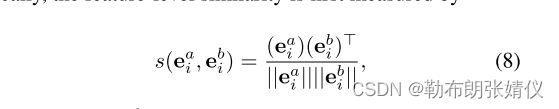
其中ea i和eb (8) i是两个弱增强的面部表情特征。根据获得的相似性度量,样本xu i的特征ea i的对比目标可以定义如下:

其中i,k ∈ I = {1,2,3,...,Nl},j ∈ I \{i},Nl是子集II中的数据数,τ 是控制柔度的温度参数 [10]。值得注意的是,此过程可以进一步提高特征的判别能力,并且不会引入其他可训练参数。
3.2.4总体目标函数
提出的具有自适应置信度裕度的ss-dfer方法在端到端过程中进行了优化。整个网络最小化以下损失函数:

其中Ls CE和Lu分别表示子集I中标记样本和未标记样本的交叉熵损失。Lc表示子集II中样本的对比目标。Λ1、 λ2和 λ3是平衡每个项强度的超参数。算法1总结了我们提出的方法的整个过程。

3.3讨论
在这里,我们讨论了所提出的Ada-CM、FixMatch [28]、Dash [35]和FlexMatch [40]之间的关系,它们具有相似的理念,但作用不同。与固定匹配[28]的关系。FixMatch侧重于固定的阈值,因此其建模能力在[35,40]的早期训练阶段受到限制。Ada-CM的目标是自适应置信度,这对早期训练是友好的。此外,FixMatch只通过所有类别的固定阈值选择置信度得分较高的未标记样本,而Ada-CM利用所有未标记的数据,学习不同面部表情的动态阈值。与Dash [35]的关系。Dash用于选择损失值小于动态阈值的未标记样本。然而,Ada-CM利用了所有未标记的样本,并比较了置信度得分,这直观地反映了未标记样本的预测。此外,Ada-CM是建立在对不同类别的正确预测的标记数据之上的,而Dash则利用整个标记集来获得所有类别的动态阈值。与FlexMatch [40]的关系。弹性匹配器首先要考虑的是他学习每个类别的困难,但仅选择具有高置信度分数的未标记数据。此外,FlexMatch根据预测属于该类别且高于固定阈值的未标记数据的数量,获得不同类别的动态阈值。而我们的Ada-CM是由不同类别中正确预测的标记数据的平均置信度分数决定的。
4实验
在本节中,我们进行了大量的实验来验证我们所提出的方法的有效性。在4.1我们首先简要介绍了实验设置。然后,4.2我们进行消融研究显示Ada-CM中每个组件的重要性。最后,4.3-4.5我们将我们的方法与最先进的方法比较。
4.1实验设置
数据集。我们在四个常用的数据集上评估了Ada-CM:RAF-DB、SFEW、AffectNet和CK+。RAF-DB [16]包括近30,000张面部图像,以及由40个注释者组成的两个不同的子集。在我们的实验中,我们选择了具有6个基本表情(即惊讶、恐惧、厌恶、快乐、悲伤和愤怒)的单标签子集和中性面孔,分别分为训练集和大小为12271和3068的训练集和测试集。SFEW [6]是一个从电影中选择的静态面部表情数据集,包括958张图像用于训练,436张图像用于验证,372张图像用于测试。SFEW中的图像用6个基本表达式和RAF-DB中的中性面进行了标注。由于在测试集中没有公共标签,我们比较了在验证集上的性能。AffectNet [22]是目前最大的真实面部表情数据集,由约42万张带有8个表情标签的人工人工标记图像组成。为了进行公平的比较,我们使用了28万张训练图像和4000张验证图像(每类500张图像)。扩展的Cohn-Kanade(CK+)[20]包括来自123个受试者的593个视频序列。我们选择每个序列的第一帧和最后一帧作为中性面孔和目标表达,其中包括636张带有7个表达标签的图像。
性能指标。为了评估模型的性能,我们使用总体测试精度作为所有算法的性能指标。此外,我们遵循标准的SSL(半监督学习)评价方案,使用不同的随机种子进行了5次实验,以获得平均精度及其标准差。
实施细节。在接下来的实验中,我们使用MTCNN [41]来检测和调整大小为224×224的面部表情。我们提出的方法是在两个NVIDIA Tesla V100 gpu上使用PyTorch工具箱实现的。对于主干CNN,我们默认使用在MS-Celeb-1M人脸识别数据集上预先训练的ResNet18 [9]。我们还用WideResNet-28-2在MarginMix [7] 中用于公平比较进行实验.我们采用与DFER相关的弱增强策略,包括RandomCrop和RandomHorizontalFlip。此外,RandAugment [5] 被用作 [28] 之后的强增强方案。RAF-DB中的训练数据作为其他未标记数据添加到SFEW中。
为了进行公平的比较,我们对所有实验使用初始学习率为5 × 10 − 4的Adam优化器 [13]。训练时期的总数设置为20。除AffectNet外,带标签和未带标签的数据的小批量大小为16。对于所有用于公平比较的算法,这些设置都是相同的。初始阈值集根据经验设置为T0 = {0.8}C。在等式中。(10),超参数 λ1、 λ2和 λ3分别设置为0.5、1和0.1。
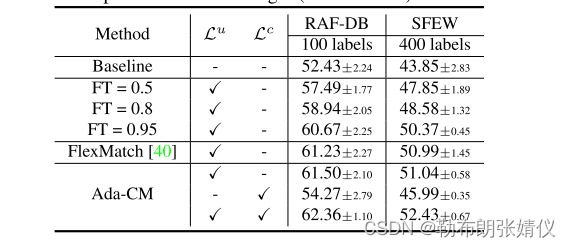
表1。对RAF-DB和SFEW上的Ada-CM中固定阈值和不同成分的消融研究(以%,平均±标准差)。基线表示该模型仅由标记数据有限的Ls CE进行训练。这也适用于以下各表。请注意,Lu表示获得具有高置信度分数的数据的不同阈值,例如,固定的(第2行到第4行)、动态的(第5行)和我们的自适应置信度(第6行和第8行)。
4.2消融研究
在本节中,我们分析了方法中每个组件的贡献。为了方便起见,我们在以下实验中使用 ‘FT’; 来引用具有不同固定阈值的FixMatch [28]。
Ada-CM中各组件的有效性。为了评估所提出的自适应置信度的重要性,我们进行了消融研究,对100个标签的RAF-DB和400个标签的SFEW进行了高置信度得分的样本和Lc的Lu调查。此外,还可以验证第3.3节中的关系。
如表1所示,一些观察结果可以总结如下。首先,与基线方案相比,其他方法(第2~8行)利用了未标记的样本,显著提高了两种评价方案的基线性能。在所有情况下,我们最终的Ada-CM(第8行)都实现了最好的性能改进。此外,不同的固定阈值会影响伪标签的质量,这与FixMatch [28]中的效果一致。
其次,对比目标(第7行)的效果超过了基线,但并不令人满意(只有Lc损失)。这可能是因为对比目标侧重于同一数据的不同视图之间的特征级相似性,而区分类间样本的能力有限。然而,该操作可以确保利用所有未标记的样本来更新模型,并与Lu实现协同作用,以提高性能。
此外,对于阈值的影响,我们比较了三个固定的阈值,FlexMatch(第5行)和我们的自适应置信裕度(第6行)。从结果,我们的自适应置信度显示了更大的性能改进。这些结果验证了我们的方法的两个贡献: 1)与基于固定阈值的方法相比,我们的方法在伪标记未标记的面部表情方面是非常有效的。2)我们的Ada-CM和FlexMatch [40]在具有高置信度分数的样本上都取得了相似的性能。然而,我们的方法的贡献是,在FlexMatch中只能选择所有未标记的样本,相比之下,Ada-CM只能选择部分样本。事实上,结合自适应置信度和对比目标,我们的方法(第8行)取得了最好的结果,这表明在所有未标记数据的帮助下,熵最小化和对比学习可以共同指导模型提取更有区别的特征。
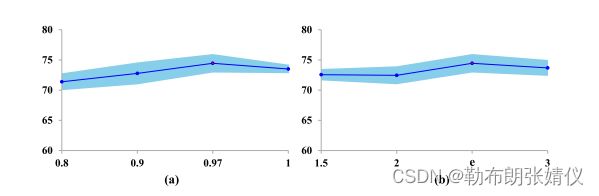
图3。Ada-CM的消融研究图。(a)改变控制参数B。(b)测量γ的效果。具有默认设置的性能将用红色标记
评价 B. 由于参数B用于控制每个时期的置信裕度峰值,所以我们在等式(5)中进行了实验来探索不同的B。图3 (a)反映了不同的模型性能 B. 我们发现默认设置B = 0.97达到了最好的结果。当B太小时,我们的方法就很难得到保证伪标签的质量。原因是带有错误伪标签的数据量增加了。
不同的影响γ. γ提供了逐步修改当前置信裕度的能力。图3 (b)显示了不同γ∈{1.5、2、e、3}的影响。我们可以得到,我们的方法在一定范围内对γ不敏感,但当γ设置为e时,我们获得了最高的性能。
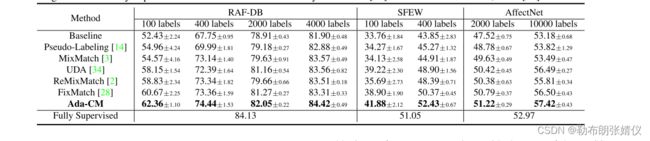
表2。使用ResNet-18在RAF-DB、SFEW和AffectNet上与最先进的SSL方法进行性能比较(以%,平均±标准差)。完全监督表示所有标记的训练数据都用于训练DFER模型。这也适用于以下各表。完全监督的基线结果由RAF-DB上的DLP-CNN [16]和SFEW,AffectNet上的RAN [32]获得。

表3.使用WideResNet-28-2在RAF-DB上与最先进的SSDFER方法的性能比较(以%,平均±标准差)。
4.3.与最先进的方法的比较
为了验证我们的Ada-CM的有效性,我们提供了在RAF-DB、SFEW和AffectNet数据集上的实验结果,并在两个方面与最先进的方法进行了比较,包括与RAF-DB上的SS-DFER方法[7]的比较,以及与SSL方法的比较。表2比较了我们的方法与使用ResNet-18作为骨干网络的SSL方法。从这个表中可以清楚地看出,我们提出的Ada-CM取得了最好的性能,并以很大的优势超过了最先进的FixMatch [28]。这表明,我们的方法可以更好地利用未标记的数据来进一步提高SSL的性能。与完全监督的结果[16,32]相比,我们的方法仍然可以获得较大的增益,即在1/3、1/2和1/28标记数据比的情况下,RAF-DB为0.29%,SFEW为1.38%,AffectNet为4.45%。这些结果验证了我们的方法的有效性和处理现实世界中有限的标记情况的能力。
此外,所提出的Ada-CM在每种情况下都能优于MarginMix [7]。据我们所知,MarginMix可以是第一次尝试基于MixMatch [3]来解决SS-DFER问题。如表3所示,我们的Ada-CM显著超过了13.28%、1.91%和5.3%,分别有400、1000和4000个标记样品。显著的结果表明了我们提出的Ada-CM在处理SS-DFER方面的有效性。在补充材料中可以找到更多的结果。

表4。使用WideResNet(WRN)-28-2 [38]和ResNet-18[9](平均±标准差)对实验室CK+进行跨数据集评估。所有模型都在RAF-DB上进行训练,并在CK+数据集上进行测试。

图4。通过不同方法获得的面部表情特征的2D t-SNE可视化[30],包括(a)基线、(b) FixMatch、(c)我们的Ada-CM(没有对比目标)和(d)整个Ada-CM。所有的模型都是在带有4000个标签的RAF-DB上进行训练的。这些特征从CK+数据集中提取出来。
4.4.用于跨数据集评估的SSL
为了进一步验证该方法的泛化能力,我们采用了跨数据集评估方案(RAF-DB到CK+数据集),该方案广泛应用于跨数据集DFER。表4显示了与以WideResNet-28-2和ResNet-18为骨干的最新方法的比较。显然,我们的方法在所有情况下都比现有的方法具有更好的性能。与完全监督结果[18]相比,使用ResNet-18的4000个标记样本的Ada-CM获得了3.6%的更大增益。这表明,我们的方法侧重于大量的未标记数据,而不受原始标签的影响,这有利于泛化。此外,我们的方法可以在1/3标记数据和更少的模型参数下获得优越的性能。具体来说,在[18]中使用的主干是带有通道级注意力的ResNet-50,而我们使用更轻量级的ResNet-18。
4.5.可视化
为了进一步评估我们的方法中重要的自适应置信裕度的有效性,我们使用了t-SNE[30],分别可视化由基线、FixMatch、我们提出的Ada-CM(没有对比目标)和整个Ada-CM在二维空间上提取的面部表情特征分布。
如图4所示,我们可以观察到,通过基线和FixMatch获得的面部表达特征对于某些类别没有足够的区别性,例如,红色虚线中的悲伤。相比之下,我们的Ada-CM(没有对比目标)可以在悲伤和其他类别之间达到一个明确的界限。特别是在结合对比目标后,类内相似性和类间差异更加明显。
5.结论
在本文中,我们提出了一种新的半监督自适应置信裕度(Ada-CM)用于深度面部表情识别,它自适应地利用所有未标记样本(即置信度高的子集I样本和低置信度高的子集II样本)来训练模型。所提出的Ada-CM从两个方面显著提高了性能。一方面,对置信度分数超过学习置信度的未标记样本直接进行伪标记,以匹配强增强版本的预测。另一方面,应用对比目标来学习子集II中样本间的面部表情特征。在四个流行数据集上的实验表明,我们的方法在执行SS-DFER任务方面的优越性。