Pytorch学习笔记——Batch Norm方法
1.自定义BatchNorm类
import time
import torch
from torch import nn,optim
import torch.nn.functional as F
import torchvision
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def batch_norm(is_training,X,gamma,beta,moving_mean,moving_var,eps,momentum):
if not is_training:
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2,4)
if len(X.shape) == 2:
mean = X.mean(dim=0)
var = ((X-mean)**2).mean(dim=0)
else:
mean = X.mean(dim=0,keepdim=True).mean(dim=2,keepdim=True).mean(dim=3,keepdim=True)
var = ((X-mean)**2).mean(dim=0,keepdim=True).mean(dim=2,keepdim=True).mean(dim=3,keepdim=True)
X_hat = (X-mean) / torch.sqrt(var+eps)
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) *var
Y = gamma * X_hat + beta
return Y,moving_mean,moving_var
class BatchNorm(nn.Module):
def __init__(self,num_features,num_dims):
super(BatchNorm,self).__init__()
if num_dims == 2:
shape = (1,num_features)
else:
shape = (1,num_features,1,1)
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.zeros(shape)
def forward(self,X):
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
Y,self.moving_mean,self.moving_var = batch_norm(self.training,X,self.gamma,self.beta,self.moving_mean,self.moving_var,eps=1e-5,momentum=0.9)
return Y
class FlattenLayer(nn.Module):
def __init__(self):
super(FlattenLayer,self).__init__()
def forward(self,x):
return x.view(x.shape[0],-1)
net = nn.Sequential(nn.Conv2d(1,6,5),
BatchNorm(6,num_dims=4),
nn.Sigmoid(),
nn.MaxPool2d(2,2),
nn.Conv2d(6,16,5),
BatchNorm(16,num_dims=4),
nn.Sigmoid(),
nn.MaxPool2d(2,2),
FlattenLayer(),
nn.Linear(16*4*4,120),
BatchNorm(120,num_dims=2),
nn.Sigmoid(),
nn.Linear(120,84),
BatchNorm(84,num_dims=2),
nn.Sigmoid(),
nn.Linear(84,10))
def evaluate_accuracy(data_iter,net,device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')):
acc_sum,n = 0.0,0
with torch.no_grad():
for X,y in data_iter:
if isinstance(net,torch.nn.Module):
net.eval()
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train()
else:
if('is_training' in net.__code__.co_varnames):
acc_sum += (net(X,is_training=False).argmax(dim=1) == y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum/n
def load_data_fashion_mnist(batch_size,resize=None,root='~/Datasets/FashionMNIST'):
trans = []
if resize:
trans.append(torchvision.transforms.Resize(size=resize))
trans.append(torchvision.transforms.ToTensor())
transform = torchvision.transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root=root,train=True,download=True,transform=transform)
mnist_test = torchvision.datasets.FashionMNIST(root=root,train=False,download=True,transform=transform)
train_iter = torch.utils.data.DataLoader(mnist_train,batch_size=batch_size,shuffle=True,num_workers=4)
test_iter = torch.utils.data.DataLoader(mnist_test,batch_size=batch_size,shuffle=False,num_workers=4)
return train_iter,test_iter
def train_ch5(net,train_iter,test_iter,batch_size,optimizer,device,num_epochs):
net = net.to(device)
print("training on ",device)
loss = torch.nn.CrossEntropyLoss()
batch_count = 0
for epoch in range(num_epochs):
train_l_sum,train_acc_sum,n,start = 0.0,0.0,0,time.time()
for X,y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat,y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter,net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec' %(epoch+1,train_l_sum/batch_count,train_acc_sum/n,test_acc,time.time()-start))
batch_size = 256
train_iter,test_iter = load_data_fashion_mnist(batch_size=batch_size)
lr,num_epochs = 0.001,5
optimizer = torch.optim.Adam(net.parameters(),lr=lr)
train_ch5(net,train_iter,test_iter,batch_size,optimizer,device,num_epochs)
print(net[1].gamma.view((-1,)))
print(net[1].beta.view((-1,)))
2.结果
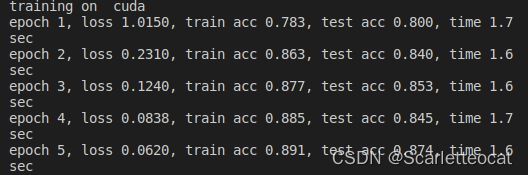 3.Pytorch自带类
3.Pytorch自带类
import time
import torch
from torch import nn,optim
import torch.nn.functional as F
import torchvision
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def batch_norm(is_training,X,gamma,beta,moving_mean,moving_var,eps,momentum):
if not is_training:
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2,4)
if len(X.shape) == 2:
mean = X.mean(dim=0)
var = ((X-mean)**2).mean(dim=0)
else:
mean = X.mean(dim=0,keepdim=True).mean(dim=2,keepdim=True).mean(dim=3,keepdim=True)
var = ((X-mean)**2).mean(dim=0,keepdim=True).mean(dim=2,keepdim=True).mean(dim=3,keepdim=True)
X_hat = (X-mean) / torch.sqrt(var+eps)
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) *var
Y = gamma * X_hat + beta
return Y,moving_mean,moving_var
class BatchNorm(nn.Module):
def __init__(self,num_features,num_dims):
super(BatchNorm,self).__init__()
if num_dims == 2:
shape = (1,num_features)
else:
shape = (1,num_features,1,1)
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.zeros(shape)
def forward(self,X):
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
Y,self.moving_mean,self.moving_var = batch_norm(self.training,X,self.gamma,self.beta,self.moving_mean,self.moving_var,eps=1e-5,momentum=0.9)
return Y
class FlattenLayer(nn.Module):
def __init__(self):
super(FlattenLayer,self).__init__()
def forward(self,x):
return x.view(x.shape[0],-1)
def evaluate_accuracy(data_iter,net,device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')):
acc_sum,n = 0.0,0
with torch.no_grad():
for X,y in data_iter:
if isinstance(net,torch.nn.Module):
net.eval()
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train()
else:
if('is_training' in net.__code__.co_varnames):
acc_sum += (net(X,is_training=False).argmax(dim=1) == y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum/n
def load_data_fashion_mnist(batch_size,resize=None,root='~/Datasets/FashionMNIST'):
trans = []
if resize:
trans.append(torchvision.transforms.Resize(size=resize))
trans.append(torchvision.transforms.ToTensor())
transform = torchvision.transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root=root,train=True,download=True,transform=transform)
mnist_test = torchvision.datasets.FashionMNIST(root=root,train=False,download=True,transform=transform)
train_iter = torch.utils.data.DataLoader(mnist_train,batch_size=batch_size,shuffle=True,num_workers=4)
test_iter = torch.utils.data.DataLoader(mnist_test,batch_size=batch_size,shuffle=False,num_workers=4)
return train_iter,test_iter
def train_ch5(net,train_iter,test_iter,batch_size,optimizer,device,num_epochs):
net = net.to(device)
print("training on ",device)
loss = torch.nn.CrossEntropyLoss()
batch_count = 0
for epoch in range(num_epochs):
train_l_sum,train_acc_sum,n,start = 0.0,0.0,0,time.time()
for X,y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat,y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter,net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec' %(epoch+1,train_l_sum/batch_count,train_acc_sum/n,test_acc,time.time()-start))
net = nn.Sequential(nn.Conv2d(1,6,5),
nn.BatchNorm2d(6),
nn.Sigmoid(),
nn.MaxPool2d(2,2),
nn.Conv2d(6,16,5),
nn.BatchNorm2d(16),
nn.Sigmoid(),
nn.MaxPool2d(2,2),
FlattenLayer(),
nn.Linear(16*4*4,120),
nn.BatchNorm1d(120),
nn.Sigmoid(),
nn.Linear(120,84),
nn.BatchNorm1d(84),
nn.Sigmoid(),
nn.Linear(84,10))
batch_size = 256
train_iter,test_iter = load_data_fashion_mnist(batch_size=batch_size)
lr,num_epochs = 0.001,5
optimizer = torch.optim.Adam(net.parameters(),lr=lr)
train_ch5(net,train_iter,test_iter,batch_size,optimizer,device,num_epochs)
4.结果(训练速度更快)
