注意力机制(attention)
目录
非参注意力
自注意力机制(self-attention)
多头自注意力机制(Multi-head Self-attention)
Position Encoding
非参注意力
给定一组数据( ,
,![]() ),i=1,2....n
),i=1,2....n
最简单的方式给每一组数据添加一样权重大小的注意力

更好的注意力方案:Nadataya-Watson核回归

用每一个x的距离函数除以所有的距离函数和得到一个该x的比重(类似softmax)作为注意力大小
再将获取的n组不同的注意力乘上对应的y值,得到注意力加权结果。
K为计算x和之间的‘距离’的核函数,例如取高斯分布:

那么带入原函数就可以化简为:
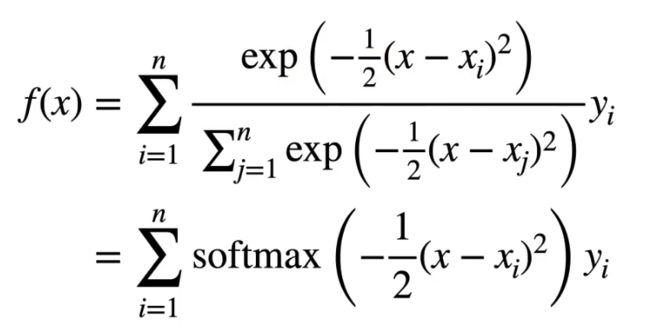
以上是从统计角度出发的,没有可学习参数。

在原来的基础上加上可学习的参数w通过训练,调整每组数据对应的权重大小。
自注意力机制(self-attention)
获取文字输入如果是独热向量的话,就默认了每一个词向量之间是独立的, 除去一个位置是1其他位全0,最好用词嵌入(word Embeading)获取词向量。
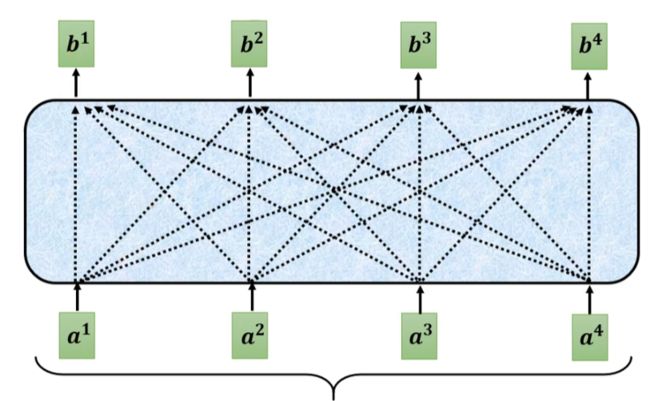
每一组输入向量a都需要考虑所有其他输入之后再输入b
如何计算出b1
中间具体的计算过程也就是添加注意力的方式有多种,例如:


后续都使用左边这个先利用两个权重矩阵乘输入获取q,k,再将q, k做点积获取α的方式
权重矩阵W是后续通过训练得来的。
将α作为两个输入的相关程度,α就是所谓的attention score
每一组输入都引入这种点积方式计算一个相关程度α

以计算a1的attention score为例,在计算时需要用自己的q去跟每一组向量的k计算一个α,包括a1自己的k(不计算自己的attention score在多数情况下都对结果有较大的影响)
再将得到的一组α做softmax获取一组![]() (此处可以尝试用Relu等等,看会不会有更好的结果)
(此处可以尝试用Relu等等,看会不会有更好的结果)

计算完![]() 后,利用输入向量a和一个新的权重矩阵计算v
后,利用输入向量a和一个新的权重矩阵计算v
将每一组α乘以v后相加获取b
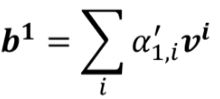
此时谁的attention score也就是α更大,谁的v就会在输出的b中占主要地位,最大程度影响b的值。
以上就是计算b1的全过程,b2,b3等等都是同理可得
于是便可以通过以上计算获取一个输出矩阵B
简化表达
把每个输入向量计算q的操作拼接到一起,用一个矩阵I来表示(input)
获得的q也拼接到一起形成矩阵Q,k和v也是同理拼成K V矩阵


在计算α时,q1需要访问每一个k,就可以将k拼起来
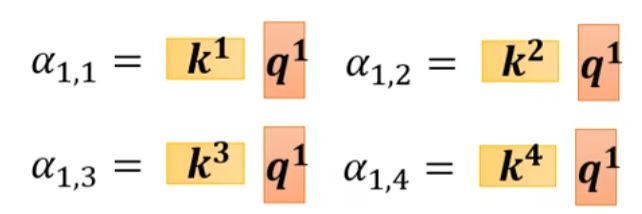
同时每个q都需要访问一次k1-kn

所以获取的α矩阵就简化为了![]() ×Q ,再将结果做softmax操作之后与v相加就可以得到b1-bn
×Q ,再将结果做softmax操作之后与v相加就可以得到b1-bn

多头自注意力机制(Multi-head Self-attention)
吧一组q视为一种类别的相关性,几个输入之间可能有多种不同方面的相关性,引入多组q使得网络能够提取到多种不同关注点。
以heads为2举例,再添加两个矩阵w与原来的q相乘获取两个不同的q。通过两个不同的w来的得到两个关注点不同的,从而达到Multi-head。

计算时 与每个
与每个![]() 相乘,
相乘, 与所有
与所有![]() 相乘
相乘
在计算![]() 的输入b时,有几个head就会输出几个
的输入b时,有几个head就会输出几个![]()

将 ![]() 计算出的所有b用一个矩阵拼起来
计算出的所有b用一个矩阵拼起来

Position Encoding
上述的每个a用多个head计算b的过程,都是可以独立进行的,不会影响彼此的输出结果。
所以这种做法可能忽略了一个很重要的问题:每个a的位置信息
每个a在句子的前或者后可能会直接影响语义,所以用Position Encoding来添加位置信息。

构造一个向量 加在a中
加在a中
具体的构造方式很多,目前还是一个尚待研究的问题
例如以Transformer中的正余弦编码方式
或者构造成一个可学习的向量由数据训练得出等等
