ResNet、ResNeXt详解以及代码实现
目录
ResNet网络结构详解
resnet的创新
残差块Residul Block
整体网络结构
ResNet代码实现
ResNeXt详解
组卷积
更新了Block
ResNeXt整体结构
ResNet网络结构详解
resnet的创新
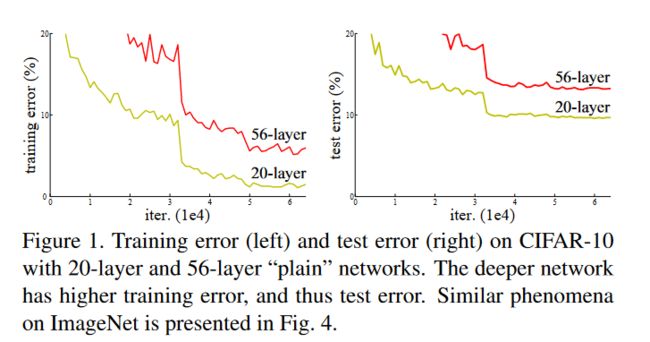
1.可以堆叠上千层
简单堆叠卷积层会造成梯度消失梯度爆炸,以及退化问题。退化问题说的是在训练集和验证集的精度都变差,不是在表达过拟合,而是堆叠过深后模型效果会变差。
从理论角度来说,浅层模型达到一定精度后,后面堆叠的更多的层全部学为identity,即可至少保证模型效果不会随着堆叠网络深度变差,但是SGD没办法求出这样的解
2.使用了BN来防止梯度消失/梯度爆炸,并加速训练
3.提出残差结构解决退化问题
残差块Residul Block
论文中定义了两种残差结构
resnet-18/34使用第一种残差结构(左)
resnet-50/101/152使用第二种残差结构(右)
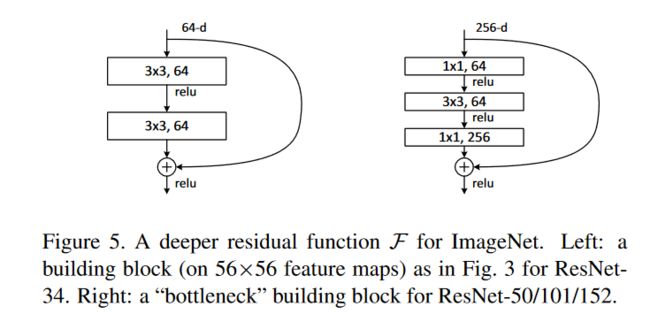
残差块除了计算卷积操作以外,增加了一个跳跃连接
将输入值与卷积后的值相加再传入激活函数
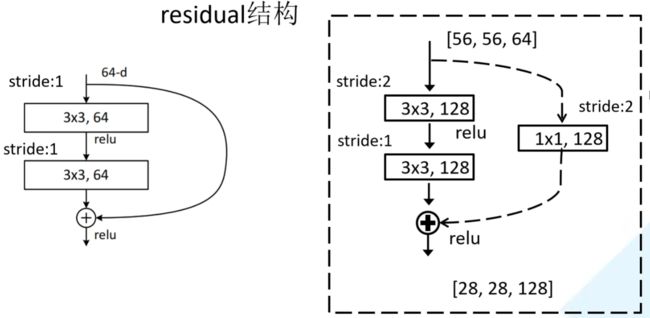
以下图resnet-34的前几层为例,除了第一个紫色模块以外,后面每一个模块的第一个残差结构都需要做一个下采样操作,也就是虚线部分。
实线部分表示的输入输大小是一样的,可以直接相加,而虚线部分的输入和输出大小不同,需要进行一个下采样操作再相加

下采样:通过一个1*1改变通道数,同时第一个3*3卷积的步距也从1变为2将输入w,h缩小一半
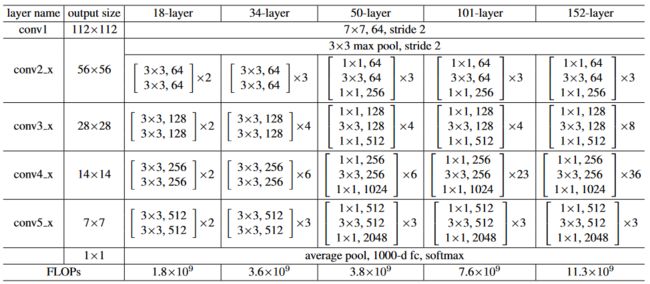
整体网络结构
中括号代表残差块,右边数字代表每个残差块重复几次
ResNeXt详解
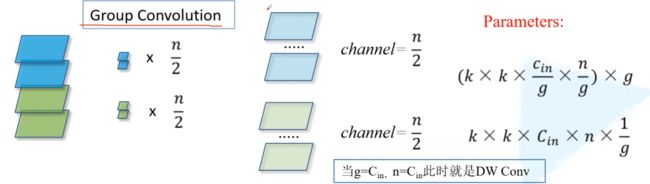
组卷积
普通卷积
参数个数:卷积核高*卷积核宽*输入维度*卷积核个数

组卷积
以g=2也就是分成两组为例
每一组的参数为: 卷积核高*宽*(输入维度/2)*(输出维度/2)
一共g组再乘个g就是所有参数
所以两组时乘个2约掉分母一个二后 参数=卷积核高*宽*输入维度*输出维度*(1/2)
将2换成g,就是参数量缩小为原来的g分之一
当g等于输入维度时,相当于每一个维度都分开计算,等价于逐通道卷积
更新了Block
左边为resnet残差块,先通过1*1卷积降维,再用3*3卷积提取特征,再1*1升维从而减少计算
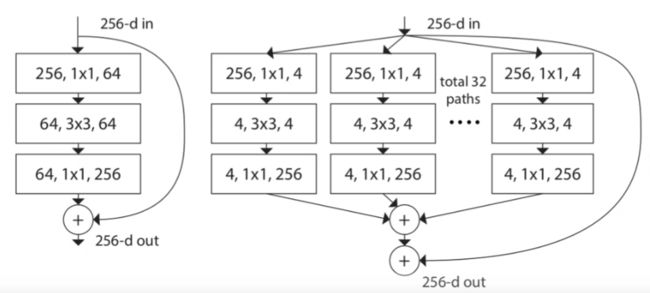
而ResNeXt提出了一个组卷积的概念
将输入通道为256的数据通过1*1卷积压缩成大小为4的32组,合起来也就是128通道
然后进行卷积操作后,再用1*1卷积扩充回32组256通道
将32组数据按对应位置相加合成一个256通道的输出
ResNeXt整体结构
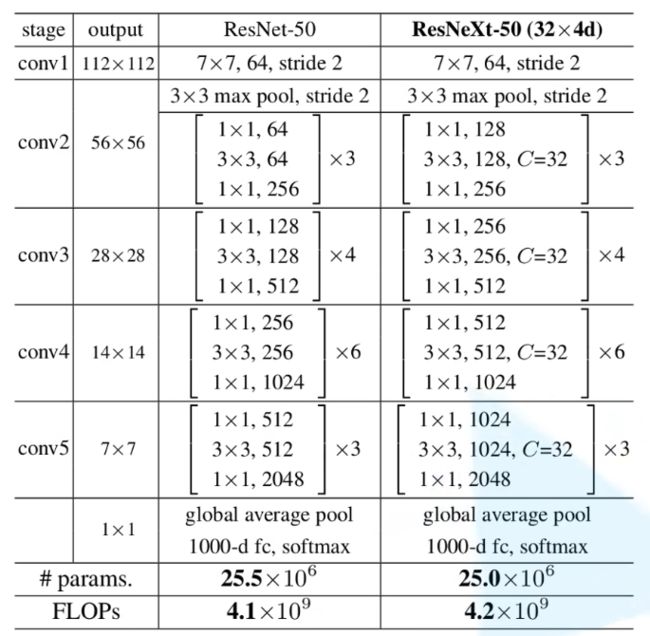
ResNet和ResNeXt代码实现
ResNeXt只增加了组的概念,相比resnet的block增加两个关于组卷积的参数groups,width_per_group就行
观察整体结构图
可以看到每种不同层数的resnet有很多相似的模块,但是每个模块的具体数值不同
所以将模块单独设计出来,吧不同的网络的不同数值设计为参数,调用那个网络就传入那组参数
编码时
对于18和34
1.padding:考虑到每个残差块需要使大小不变,k=3的情况下,(h-3+2p/1)+1,只需要p=1即可
padding除了conv1是3其余位置全为1
2.stride:除去conv2_x这一层以外,后面每层的第一个残差块的第一层输入和输出维度都是不同的
需要进行下采样操作,所以下采样的地方s取2,其他地方s都取1
编码时stride默认值设为1,需要下采样的地方才传入stride=2参数
对于50/101/152
1.padding:p的取值思路一样,但是由于卷积核有1*1的,所以(h-1+2p/1)+1,p直接取默认值0即可
其他取值不变
2.但是每层结束后的最后一个1*1需要扩充维度,每次扩充4倍
由于conv2_x第一次进来是从channel=3变成64,后面每次进都是从256变64
恰好这一层是不需要下采样的
所以用①channel是否为4倍②s是否等于2两个条件来判断需不需要下采样
在后面_make_layer函数中实现
先实现两种不同的残差结构
上述的第一种残差结构,也就是对应18/34层的BasicBlock
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out上述的第二种残差结构,也就是对应更多层的Bottleneck
class Bottleneck(nn.Module):
"""
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。
但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,
这么做的好处是能够在top1上提升大概0.5%的准确率。
可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch
"""
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out使用时直接调用每种不同层的结构对应的残差块作为参数传入中即可
除了残差块不同以外,每个残差块重复的次数也不同,所以也作为参数
每个不同的模型只需往ResNet模型中穿入不同参数即可
def resnet34(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet34-333f7ec4.pth
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet50(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet50-19c8e357.pth
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
def resnext50_32x4d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth
groups = 32
width_per_group = 4
return ResNet(Bottleneck, [3, 4, 6, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
def resnext101_32x8d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth
groups = 32
width_per_group = 8
return ResNet(Bottleneck, [3, 4, 23, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
ResNet通用写法
根据上一个代码块中调用不同层的网络传入不同参数即可
class ResNet(nn.Module): def __init__(self, block, blocks_num, num_classes=1000, include_top=True, groups=1, width_per_group=64): super(ResNet, self).__init__() self.include_top = include_top self.in_channel = 64 self.groups = groups self.width_per_group = width_per_group self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2, padding=3, bias=False) self.bn1 = nn.BatchNorm2d(self.in_channel) self.relu = nn.ReLU(inplace=True) self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.layer1 = self._make_layer(block, 64, blocks_num[0]) self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2) self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2) self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2) if self.include_top: self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1) self.fc = nn.Linear(512 * block.expansion, num_classes) for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') def _make_layer(self, block, channel, block_num, stride=1): downsample = None if stride != 1 or self.in_channel != channel * block.expansion: downsample = nn.Sequential( nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(channel * block.expansion)) layers = [] layers.append(block(self.in_channel, channel, downsample=downsample, stride=stride, groups=self.groups, width_per_group=self.width_per_group)) self.in_channel = channel * block.expansion for _ in range(1, block_num): layers.append(block(self.in_channel, channel, groups=self.groups, width_per_group=self.width_per_group)) return nn.Sequential(*layers) def forward(self, x): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) if self.include_top: x = self.avgpool(x) x = torch.flatten(x, 1) x = self.fc(x) return x