Vision Transformer (ViT)初识:原理详解及代码
Vision Transformer (ViT)初识:原理详解及代码
- 参考资源
- 前言
- 1. 整体架构
-
- 1.1 Embedding层
-
- class token
- Position Embedding
- 1.2 Transformer Encoder层
- 1.3 MLP head 分类层
参考资源
论文:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
代码:https://github.com/google-research/vision_transformer(原论文对应源码)
代码:https://github.com/lucidrains/vit-pytorch
知乎:Vision Transformer
知乎:ViT(Vision Transformer)解析
CSDN:Vision Transformer详解
前言
Transformer最初提出是针对NLP领域的。
Vision Transformer将CV和NLP领域知识结合起来,对原始图片进行分块,展平成序列,输入进原始Transformer模型的编码器Encoder部分,最后接入一个全连接层对图片进行分类。
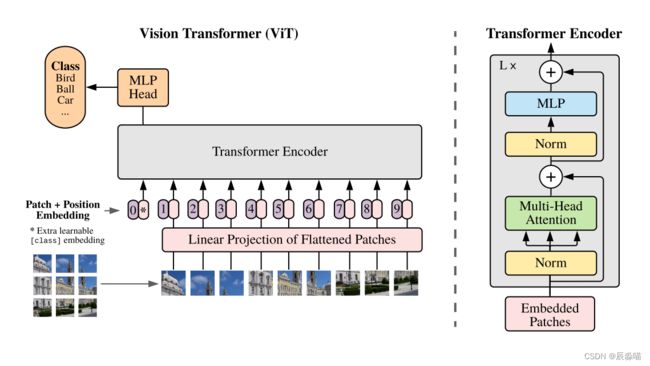
1. 整体架构
原论文中 Vision Transformer(ViT) 的模型框架。由三个模块组成:
- Linear Projection of Flattened Patches(Embedding层)
- Transformer Encoder(图右侧更加详细结构)
- MLP Head(最终用于分类的层)
1.1 Embedding层
Transformer模块的输入:token(向量)序列,即二维矩阵[num_token, token_dim]
对于图像数据:将 [H, W, C] 三维矩阵通过一个Embedding层进行变换。
先对图片作分块,再进行展平
首先将一张图片按给定大小分成一堆Patches,分块的数目为:
N = H ∗ W / ( P ∗ P ) N=H*W/(P*P) N=H∗W/(P∗P)
对每个图片块展平成一维向量,每个向量大小为
P ∗ P ∗ C P*P*C P∗P∗C
以ViT-B/16为例:
将输入图片(224x224)按照16x16大小的Patch进行划分,会得到196个Patches.
N = ( 224 / 16 ) 2 = 196 N=(224/16)^2=196 N=(224/16)2=196
接着通过线性映射将每个Patch映射到一维向量中,每个Patche数据shape为 [16, 16, 3] 通过映射得到一个长度为 768 的向量(后面都直接称为 token)。
16 ∗ 16 ∗ 3 = 768 16*16*3=768 16∗16∗3=768
在代码实现中,通过一个卷积层来实现。 以ViT-B/16为例,使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,正是Transformer想要的。
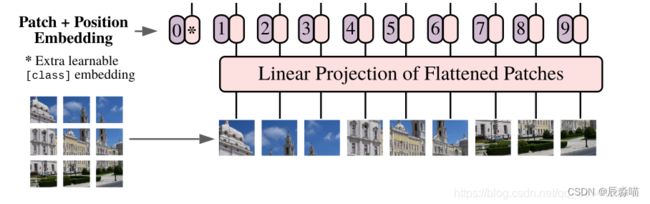
在输入Transformer Encoder之前注意需要加上 [class]token 以及Position Embedding。 其中:
class token
假设我们按照论文切成了9块,但是在输入的时候变成了10个向量。这是人为增加的一个向量。
因为传统的Transformer采取的是类似seq2seq编解码的结构 而ViT只用到了Encoder编码器结构,缺少了解码的过程,假设你9个向量经过编码器之后,你该选择哪一个向量进入到最后的分类头呢?因此这里作者给了额外的一个用于分类的向量,与输入进行拼接。
[class]token是一个可训练的参数,数据格式和其他token一样都是一个向量
以ViT-B/16为例,就是: 一个长度为768的向量,与之前从图片中生成的tokens拼接在一起,
Cat([1, 768], [196, 768]) -> [197, 768]
Position Embedding
Position Embedding采用的是一个可训练的参数(1D Pos. Emb.),是直接叠加在tokens上的(add),所以shape要一样。
以ViT-B/16为例,刚刚拼接[class]token后shape是[197, 768],那么这里的Position Embedding的shape也是[197, 768]。
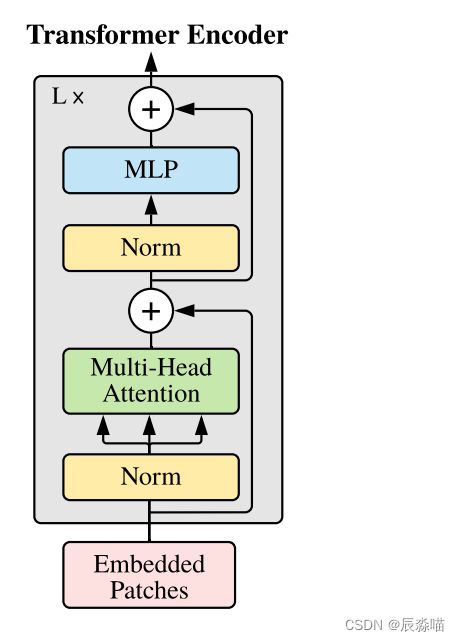
1.2 Transformer Encoder层
重复堆叠 Encoder Block L次,Encoder Block组成:
- Layer Norm
主要是针对NLP领域提出的,是对每个token进行Norm处理 - Multi-Head Attention
多头注意力,可以参考上篇 - Dropout/DropPath
在原论文的代码中是直接使用的Dropout层,在但rwightman实现的代码中使用的是DropPath(stochastic depth),可能后者会更好一点。 - MLP Block
全连接+GELU激活函数+Dropout
需要注意的是第一个全连接层会把输入节点个数翻4倍[197, 768] -> [197, 3072],第二个全连接层会还原回原节点个数[197, 3072] -> [197, 768]
1.3 MLP head 分类层
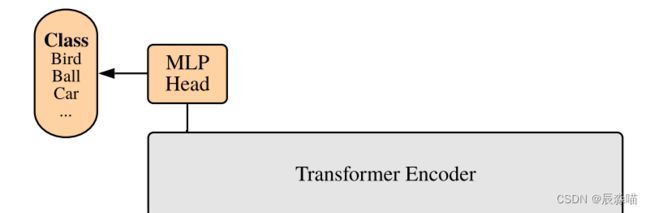
由LayerNorm和两层全连接层实现,采用的是GELU激活函数。

self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, mlp_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(mlp_dim, num_classes)
)
代码中,取token的第一个,也就是用于分类的token,输入到分类头里,得到最后的分类结果
即[197, 768]中抽取出[class]token对应的[1, 768]。