Meta-LMTC:Meta learning for Large-Scale Multi-Label Text Classification论文笔记
Abstract
虽然目前的方法可以利用先验知识来处理这些少/零样本的标签(指有些标签对应的样本很少甚至没有),但它们忽略了数据集中包含的元知识,它可以指导模型用少量样本学习。
Intro:
LMTC任务:文本可能涵盖多个不同的标签也可能一个不属于其中任何一种。可将所有标签集合分为两个不相交的集合:CS(seen)为见过的标签集合(包含常见的标签CRS (frequent)和不常见的(few-shot)标签CFS ),CU为没见过(unseen)的标签集合(zero-shot)。
LMTC应用很广:organizing documents in Wikipedia articles;annotating medical records with diagnostic and procedure labels;assigning legislation with relevant legal concepts 。(注意区别于multi-class classification)
由于预设标签类很多以及有限的有注释的资源,LMTC 任务往往面临long-tailed label distribution(长尾分布)。许多标签有少量或没有样本。少量/零样本会给最终效果带来坏处:预测不够精准。
现在主流解决这些零/少量样本的方法,将文本与特征向量为每一个标签做匹配(prior knowledge label)。Rios Kavuluru利用标签文本描述符来生成一个特征 每个标签的向量 。它采用了两层GCN来利用(structured knowledge)来增强标签的表现。Lu发现 基于预先训练好的标签相似度图 单词的嵌入频率和共现频率也有益。
但是以上方法忽视了潜在的meta-knowledge,它能够让模型用少量样本就能学习。Meta-learning 被认为是一种有效的能获取到这种元知识的策略。为了获取meta-knowledge,meta-learning为少/零样本构建任务来希望能够达到用有限的样本就能够获得最大的效果。(下图为模拟了这个场景)
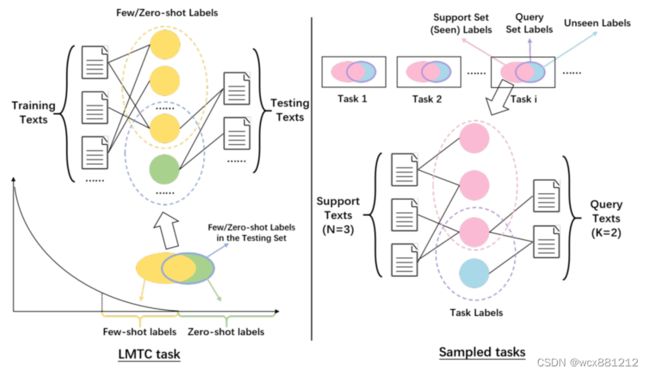
右图模拟了这样一个数据量很少的场景。右图中的每一个task只有3个训练数据(support text)2个测试数据(query text),训练数据集和测试数据集不相交即没有重复的样本。这里的N,K不是指的N way K shot,仅指每个task里训练数据和测试数据各自的数量。中间的四个圆圈代表四种标签。其中三个粉色的代表是见过的标签(即在训练样本中出现过的标签),绿色的代表是还没有见过的标签(即在训练样本时还未出现过的标签)。测试数据样本所对应的标签有可能已经在训练样本时已经见过了(如处于交集的粉红标签),也有可能还没见过(如绿色的)。meta-learning的思想是希望让所有task的效果都好,所以能够学习到如何处理few/zero-shot的问题。
然而大多数的meta-learning的算法都是为了multi-class classiffcation under the few-shot samples的场景下设计的。然后认为简单的把这些方法扩展到multi-label classification上不够好。原因(1、LMTC任务需要考虑零和少量数据的场景,现有方法只考虑到了少量样本的场景2、LMTC 任务面临long-tailed label distribution的挑战)。
解决这两个问题:我们提出了一个基于优化的meta-learning算法(感觉指的MAML):meta-LMTC(包括meta learning phase and fine-tuning phase)。以及一种抽样策略。
Contributions:从meta-learning角度提出LMTC;在LMTC的两个大难点上比其他模型好。也能增强BERTlike model。
Related work和序言:
介绍:LMTC任务、meta-learning、MAML
Meta-Learning for LMTC
meta-LMTC算法包含meta-learning phase and a fine tuning phase
meta-learning stage:
(感觉就是用的MAML,欢迎大佬们讨论)

但是如果是简单的把meta-learning 算法直接扩展到LMTC任务效果是不佳的,有如下两个问题:
(1)LMTC任务需要处理少/零样本的场景,而现有的方法只考虑少样本场景,从而提供不是很精确的的训练条件;
(2)LMTC任务的数据集通常呈现长尾分布。但是元学习算法并没有考虑到具体的数据分布。
所以需要一种好的任务抽样策略。
LMTC Task Sampling Strategy:
解决问题(1):named instance-based one:均匀采样,使zero-shot也能被学习到。 但是仍然没有解决long-tailed distribution。
解决问题(2):named label-based one:从CS集合中随机选择一个标签然后再任意选择带有这个注释的其中一个样本。重复N+K次构建一个任务Task i(support set ,query set)。这种策略相当于丢弃了zero-shot label 弱化了热频标签。但是过度关注于带有few-hot label的实例。
最后综合二者,在构建Task上使用概率p使用策略1抽样,使用1-p的概率使用策略2抽样。更精确更泛化。(p为超参数)
Experiment
分别使用两种数据集:a medical dataset MIMIC-III、a EU legislation dataset
评价指标:R@K,nDCG@K
Baseline:CNN、R-CNN、CAML、ZAGGRU、ZAGRU、AGRU-KAMG。
前三者不能处理没见过的标签。后三者可以。
ZAGGRU:将GCN用于层级标签。Its GCNs can obtain better representations for few/zero-shot labels benefit from the representations of frequent labels that are nearby in the label hierarchy.
ZAGRU:用两层MLP代替了GCN块。尽管这样后不能处理层级标签了,但是处理少见的标签表现不错。
AGRU-KAMG:the state-of the-art model of LMTC task, which can handle few and zero-shot labels。它利用了基于label embedding和label co-occurrence graph相似性的标签图谱,这能够获取标签之间的关系。
结果如下:

其中SIMPLE-EXT为直接把MAML算法扩展到以上算法上。
Analysis:
-
能够增强BERTlike模型
BERT-LWAN:不能处理zero-shot label。使用shared label encoder不现实(LMTC任务的标签量太大)。使用Distil-BERT(a smaller, faster and lighter model;retaining 97% of BERT’s language understanding capabilities. )作为shared label encoder并用LWAN和the gradient accumulation trick作为Z-DistilBERT。再将meta-LMTC扩展在此模型上。

-
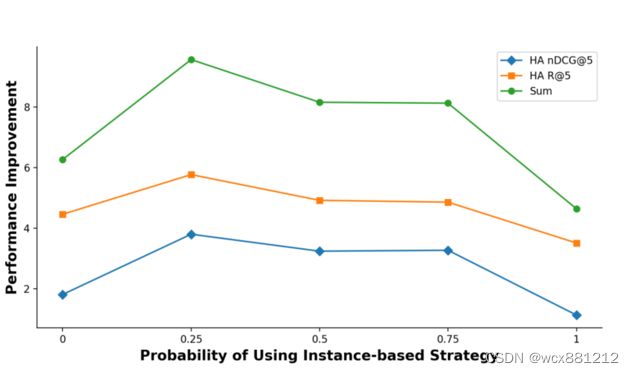
超参数p如何影响模型效果
-
使用Meta-LMTC后哪种标签分类测试的提升效果最大
在样本中出现次数为1~20次的标签提升效果最大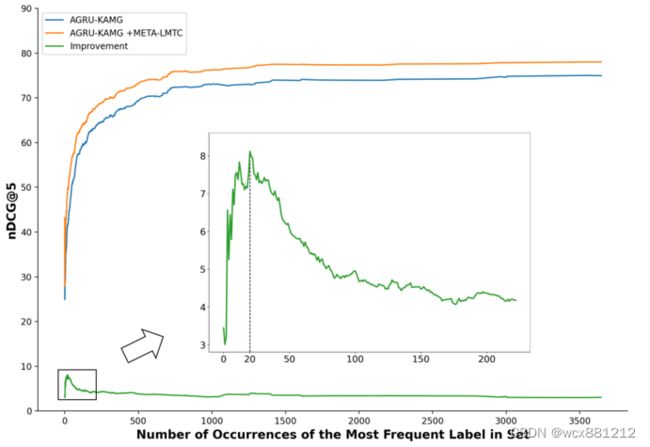
Contributions:
第一个从meta-learning角度解决LMTC任务;在LMTC的两个大难点上比其他模型好。也能增强BERTlike model。