读Hearing Lips:Improving Lip Reading by Distilling Speech Recognizers论文
论文:https://arxiv.org/pdf/1911.11502.pdf
代码:无
标题:听唇:通过蒸馏语音识别器改善唇读
关键词:多模态、语音唇读LIBS、CMLR中文数据集、Lip by Speech (LIBS)、CSSMCM、attention-based sequence-to-sequence model
[sos] => 句子起始标识符、[eos] => 句子结束标识符和 [pad] => 补全字符、
word embedding:通俗的翻译可以认为是单词嵌入,就是把X所属空间的单词映射为到Y空间的多维向量;就是找到一个映射或者函数,生成在一个新的空间上的表达。
alignment score function、alignment
Teacher Forcing 机制:RNN有两种训练模式:(1)free-running mode:上一个state的输出作为下一个state的输入;(2)teacher-forcing mode:使用给定的target即标签作为输入
Character Error Rate (CER):字错误率,中文语句中的最小单位是汉字,使用CER作为指标
Word Error Rate (WER):单词错误率,英文语句中最小单位是单词,使用WER作为指标
BLEU:(bilingual evaluation understudy),即:双语互译质量评估辅助工具。机器翻译结果越接近专业人工翻译的结果,则越好;BLUE去做判断:一句机器翻译的话与其相对应的几个参考翻译作比较,算出一个综合分数。这个分数越高说明机器翻译得越好。(注:BLEU算法是句子之间的比较,不是词组,也不是段落)
beam search:集束搜索,
grid search:Grid Search是一种调参的手段,即穷举,穷举所有的超参组合。以有两个参数的模型为例,参数a有3种可能,参数b有4种可能,把所有可能性列出来,可以表示成一个3*4的表格,其中每个cell就是一个网格,循环过程就像是在每个网格里遍历、搜索
摘要:
近年来,由于深度学习和大规模数据集的出现,唇读得到了无与伦比的发展。尽管取得了令人鼓舞的成果,但遗憾的是,由于唇部动作的模糊性,使得从唇部动作视频中提取判别特征具有挑战性,因此唇部阅读的性能仍然不如其对应的语音识别。在本文中,我们提出了一种新的方法,被称为 "语音唇读"(LIBS),其目的是通过学习语音识别器来加强唇语阅读。我们的方法背后的原理是,从语音识别器中提取的特征可以提供补充性和鉴别性的线索,这些线索很难从嘴唇的微妙运动中获得,因此有利于读唇器的训练。具体来说,这是通过从语音识别器中提炼出多模态知识给读唇器来实现的。为了进行这种跨模式的知识提炼,我们利用一种有效的对齐方案(指后文的帧级别的知识蒸馏)来处理音频和视频的长度不一致的问题,以及一种创新的过滤策略(指后文的LCS)来完善语音识别器的预测。所提出的方法在CMLR和LRS2数据集上实现了新的最先进的性能,在字符错误率方面分别比基准线高出了7.66%和2.75%。
贡献:提出音频视频对齐方案,使用新的过滤策略从不同层面进行知识蒸馏
介绍:
唇读,也称为视觉语音识别,旨在预测正在说出的句子,给定一个正在说话的人脸的静音视频。得益于最近深度学习的发展和用于训练的大数据的可用性,唇读取得了前所未有的进展,性能得到了很大提高(Assael et al. 2016; Chung et al. 2017; Zhao, Xu, and Song 2019)。
尽管取得了令人鼓舞的成就,但基于视频的唇读的性能仍然远低于其对应的基于音频的语音识别,基于音频的语音识别的目标也是解码口语文本,因此可以被视为与唇读共享相同底层分布的异类模态。给定相同数量的训练数据和模型架构,在语音识别和唇读的字符错误率方面,性能差异分别高达10.4%和39.5%(Chung et al . 2017)。这是由于嘴唇动作本质上的模糊性:几个看似相同的嘴唇动作可能产生不同的单词,使得从感兴趣的视频中提取鉴别特征并进一步可靠地预测文本输出非常具有挑战性。
在这篇论文中,我们提出了一个新颖的方案,通过语音唇读(LIBS),它利用语音识别,其性能在大多数情况下是令人满意的,以促进更具挑战性的唇读的训练。我们假设给定一个预先训练好的语音识别器,并尝试提取隐藏在语音识别器中的知识给待训练的目标唇读器。
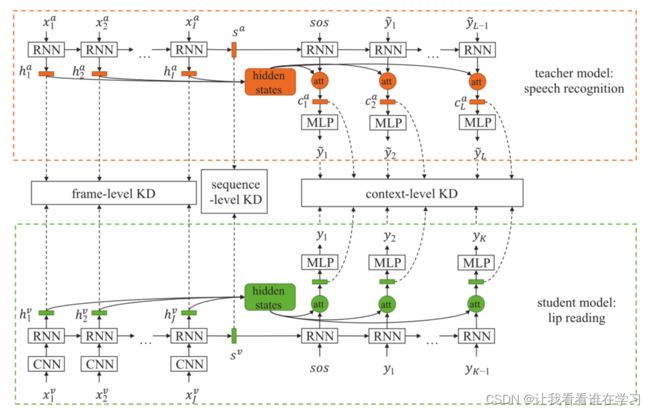
利用知识蒸馏(Hinton、Vinyals和Dean 2015)完成这项任务的基本原理在于,声音语音信号包含的信息与视觉信号的信息是互补的。例如,具有细微运动的话语很难在视觉上区分,但在大多数情况下,在听觉上很容易识别(Wolff et al. 1994)。通过模仿由语音识别器提取的声学语音特征,唇读器有望增强其提取判别视觉特征的能力。为此,LIBS被设计成在多个时间尺度上提取知识,包括序列级、上下文级和帧级,以便对来自输入序列的多粒度语义进行编码。
然而,从一个异质的模态中提取知识,在这个例子中是音频序列,面临两个主要的挑战。第一个原因在于,这两种模态可能以不同的采样率为特征,因此是异步的,而第二个原因在于不完美的语音识别预测。为此,我们采用跨模态对齐策略,通过寻找音频和视频之间的对应关系来同步音频和视频数据,从而进行从音频特征到视觉特征的细粒度知识蒸馏。另一方面,为了增强语音预测,我们引入了一种过滤技术来细化蒸馏特征,以便可以过滤有用的特征来进行知识提取。
在CMLR (Zhao, Xu, and Song 2019) 和 LRS2 (Afouras et al. 2018)两个大规模唇读数据集上的实验结果表明,该方法优于现有技术。我们在数据集上实现了31.27%的字符错误率(CER)CMLR Benchmark (Lipreading) | Papers With Code,比基线提高了7.66%,在LRS2上实现了45.53%的字符错误率,比基线提高了2.75%。值得注意的是,当训练数据量减少时,所提出的方法往往会产生更大的性能增益。例如,当只使用了20%的训练样本时,在CMLR数据集上,相对于基线的性能提高了9.63%。
因此,我们的贡献是通过从语音识别器中提取多粒度知识,实现一种创新和有效的方法来增强唇读器的训练。据我们所知,这是沿着这条路线的第一次尝试,与现有的在卷积神经网络上工作的特征级知识提取方法不同(Romero et al. 2014; Gupta, Hoffman, and Malik 2016; Hou et al. 2019),我们的策略处理RNN。在几个数据集上的实验表明,所提出的方法产生新的SOTA。
相关工作:
唇读:
(Assael et al. 2016)提出了第一个基于深度学习的、端到端的句子级唇读模型。它应用了一个具有门控循环单元(GRU) (Cho et al. 2014)和连接主义时序分类(CTC)(Graves et al. 2006)的时空CNN。(Chung et al. 2017)介绍了利用新型双注意机制的WLAS网络,该机制可以仅在视觉输入、仅在音频输入或两者上操作。(Afouras et al. 2018)提出了一个seq2seq和一个基于自注意变压器模型的CTC架构,并在一个非公开可用的数据集上进行了预训练。(Shillingford et al. 2018)设计了一种唇读系统,该系统使用网络输出音素分布,并通过CTC损失进行训练,然后使用语言模型的有限状态转换器将音素分布转换为单词序列。在(Zhao, Xu, and Song 2019)中,提出了一种用于汉语普通话唇读的级联序列到序列架构(CSSMCM)。CSSMCM在预测字符时显式地模拟音调。
语音识别:
序列到序列模型在自动语音识别(ASR)社区中越来越受欢迎,因为它将传统ASR系统的独立组件合并到单个神经网络中。(Chorowski等人,2014年)将序列到序列与注意机制相结合,以决定使用哪些输入帧来生成下一个输出元素。(Chan et al. 2016)提出了编码器中的金字塔结构,它减少了注意力模型从中提取相关信息的时间步骤数
知识蒸馏:
知识蒸馏最初是为了让一个较小的学生网络通过从一个较大的教师网络学习来表现得更好(Hinton, Vinyals和Dean 2015)。教师网络之前已经进行了训练,学生网络的参数将被估计。在(Romero et al. 2014)中,将知识蒸馏的思想应用于图像分类中,学生网络需要学习教师网络的中间输出。在(Gupta、Hoffman 和 Malik 2016)中,知识蒸馏被用于指导新的 CNN 以获取新的图像模态(如深度图像),方法是教网络重现从标记良好的图像中学习到的中级语义表示模态。 (Kim and Rush 2016) 提出了一种序列级知识蒸馏方法,用于在输出级进行神经机器翻译。与这些工作不同,我们对RNN循环神经网络进行特征级知识蒸馏。
背景:
关于Seq2Seq和基于注意力的Seq2Seq可以看博客:seq2seq model和Attention-based seq2seq Model(动图展示)_nana-li的博客-CSDN博客
这里我们简单回顾一下基于注意力的序列对序列模型(Bahdanau,Cho和Bengio 2015)。设x = [x1,...,xI],y = [y1,...,yK]分别是长度为I和K的输入和目标序列。序列到序列模型用编码器神经网络和解码器神经网络来参数化概率p(y|x)。编码器变换输入序列x1,...,xI进入隐藏状态序列h1^x,...,hI^x,并产生固定维度的状态向量s^x,它包含输入序列的语义含义。在本文中我们也称s^x为序列向量。

解码器根据编码器的输出计算目标序列的概率。具体来说,给定输入序列和先前生成的目标序列 y
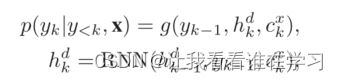
其中 g 是 softmax 函数,hk^d 是Decoder RNN 在时间步 k 处的隐藏状态,ck^x 是注意力机制计算的上下文向量。注意机制允许解码器在输出生成的每个步骤中关注输入序列的不同部分。
具体来说,Context vector上下文向量是通过根据相似度分布αk对每个编码器隐藏状态hi^x进行加权来计算的:

相似度分布 αk 表示 h(k−1)^d 和每个 hi^x 之间的近似度,计算公式为:
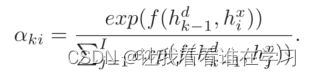
f 计算 h(k−1)^d 和 hi^x 之间的非归一化相似度,通常采用以下方式:
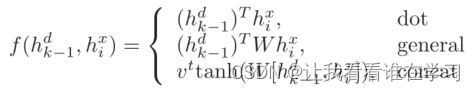
提出方法:
LIBS 的框架如图 1 所示。语音识别器和唇读器都基于基于注意力的序列到序列架构。对于输入视频,x^v = [x1^v, ..., xJ^v] 表示其视频帧序列,y = [y1, ..., yK] 是目标字符序列。对应的音频帧序列为 x^a = [x1^a, ..., xI^a ]。预训练的语音识别器读入音频帧序列 x^a,并输出预测的字符序列 y^~ = [ y1^~, ..., yL^∼]。需要注意的是,语音识别器预测的句子是不完善的,L可能不等于K。同时,编码器隐藏状态h^a = [h1^a, ..., hI^a ],序列向量s^a,上下文向量c^a = [c1^a, ..., cL^a] 也可以得到。它们用于指导唇读者的训练。基本唇读器被训练以最大化条件概率分布 p(y|x^v),这等于最小化损失函数:
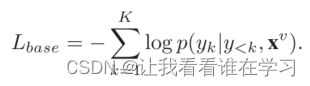
Encoder编码器的隐藏状态(hidden states)、序列向量(s)和上下文向量(c)分别表示为 h^v = [h1^v, ..., hJ^v], sv, 和 c^v = [c1^v, ..., cK^v]。所提出的方法LIBS旨在最小化损失函数:
![]()
其中 LKD1、LKD2 和 LKD3 构成多粒度知识蒸馏,分别工作在序列级、上下文级和帧级。 λ1、λ2 和 λ3 是相应的平衡权重。详情如下所述。
图 1:LIBS 的框架。学生网络处理唇读,教师处理语音识别。知识在序列、上下文和帧级别进行提炼,以使多粒度的特征能够从教师网络转移到学生。 KD是知识蒸馏的缩写
序列级知识蒸馏:
如前所述,序列向量 s^x 包含输入序列的语义信息。对于一个视频帧序列x^v及其对应的音频帧序列x^a,它们的序列向量s^a和s^v应该是相同的,因为它们是同一事物的不同表达。因此,序列级知识蒸馏表示为:
(等号右边表示二范数的平方,范数其实是一个函数,它把不能比较的向量转换成可以比较的实数;范数的本质是距离,存在的意义是为了实现比较,参考博客:范数对于数学的意义?1范数、2范数、无穷范数_yangpan011的博客-CSDN博客_无穷范数)

t 是一个简单的变换函数(例如线性或仿射函数),它将特征嵌入到具有相同维度的空间中。
上下文级知识蒸馏:
当解码器在某个时间步预测一个字符时,注意力机制使用上下文向量来总结与当前输出最相关的输入信息。因此,如果唇读器和语音识别器在第 j 个时间步预测相同的字符,则上下文向量 cj^v 和 cj^a 应该包含相同的信息。自然,上下文级别的知识蒸馏应该推动 cj^v 和 cj^a 相同。
然而,由于不完美的语音识别预测,yj^~ 和 yj 可能不一样。简单地使 cj^v 和 cj^a 相似会阻碍唇读器的性能。这需要从语音识别预测中选择正确的字符,并使用相应的上下文向量进行知识蒸馏。此外,在当前的注意力机制中,上下文向量是建立在 RNN 隐藏状态向量之上的,它作为输入句子前缀子串的表示,考虑到 RNN 计算的顺序性(Wu et al. 2018)。因此,即使预测句子中有相同的字符,它们对应的上下文向量也会因为位置不同而不同。
基于这些发现,提出了一种基于最长公共子序列 (LCS) 1 的过滤方法来细化提取的特征。 LCS 用于比较两个序列。找出两个序列中相同顺序的公共子序列,选择最长的序列。 LCS 最重要的方面是公共子序列不必是连续的,它保留了字符之间的相对位置信息。形式上,LCS 计算 y^~ = [y1^~, ..., yL^~] 和 y = [y1, ..., yK] 之间的公共子序列,并获得 y^~ 和 y 中对应字符的下标:

其中 I1^a , ..., IM^a 和 I1^v , ..., IM^v 分别是语音识别器预测的句子和真实 (ground truth) 句子中的下标。详情请参阅补充材料。值得注意的是,当句子是中文时,如果两个字符有相同的拼音,则定义为相同。拼音是汉字的音标,同音字占汉字的85%以上。
上下文级知识蒸馏仅计算这些常见字符:

帧级别知识蒸馏:
此外,我们希望语音识别器可以更精细、更明确地教唇读者。具体来说,知识在帧级别被提炼,以增强每个视频帧特征的可辨别性。
如果知道视频和音频的对应关系,那么直接将视频帧特征与对应的音频特征进行匹配就足够了。但是,由于采样率不同,视频序列和音频序列长度不一致。此外,由于数据的开头或结尾可能出现空白,因此无法保证视频和音频严格同步。因此,不可能人为地指定对应关系。这个问题是通过首先学习视频和音频的对应关系,然后进行帧级知识蒸馏来解决的。
由于 RNN 的隐藏状态提供更高级别的语义并且比原始输入特征更容易关联(Sterpu、Saam 和 Harte 2018),音频和视频之间的对齐是在音频编码器和视频编码器的隐藏状态上学习的,正式的说,对于每一个音频隐藏状态 hi^a ,最相似的视频帧特征是通过类似于注意力机制的方式计算出来的:
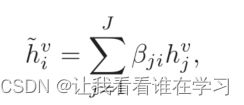
βji 是 hi^a 和视频编码器隐藏状态 hj^v 之间的归一化相似度:

由于hi^v~ 包含与音频特征hi^a 最相似的信息,并且声学语音信号包含与视觉信号互补的信息,因此使hi^v~ 和hi^a 相同可以增强唇读者提取判别视觉特征的能力。因此,帧级知识蒸馏定义为:
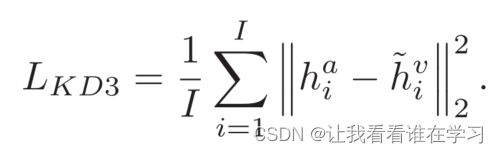
音频和视频模态可以有双向交互。然而,在初步实验中,我们发现视频参与音频会导致性能下降。因此,仅选择音频参与视频来执行帧级知识蒸馏。
实验:
数据集:
CMLR:
(Zhao, Xu, and Song 2019):它是目前最大的中文普通话唇读数据集。它包含来自中国网络电视网站的100,000多个自然句子,包括3,000多个汉字和20,000个短语。
LRS2:
(Afouras et al. 2018):它包含来自 BBC 电视台的 45,000 多个口语句子。 LRS2根据播出日期分为开发(train/val)和测试集。该数据集有一个“预训练”集,其中包含用每个单词的对齐边界注释的句子。我们在实验中遵循提供的数据集分区。
评价指标:
对于 LRS2 数据集的实验,我们报告了字错误率 (CER)、单词错误率 (WER) 和 BLEU (Papineni et al. 2002)。 CER 和 WER 定义为 ErrorRate = (S + D + I)/N,其中 S 是替换数,D 是删除数,I 是从对假设的引用中获得的插入数,N是参考文献中的字符(单词)数。BLEU 是 n-gram 精度的一种改进形式,用于将候选句子与一个或多个参考句子进行比较。在这里,使用一元 BLEU。对于 CMLR 数据集的实验,只报告了 CER 和 BLEU,因为中文句子呈现为连续的字符串,没有词边界的划分。
训练策略:
与 (Chung et al. 2017) 一样,课程学习(curriculum learning)用于加速训练并减少过度拟合。由于 CMLR 和 LRS2 的训练集没有标注词边界,因此句子根据长度分组为子集。我们开始训练短句,然后随着网络训练使序列长度增加。计划抽样 (Scheduled sampling)(Bengio et al. 2015) 用于消除训练和推理之间的差异。对于 CMLR 数据集,前一个输出的采样率从 0.7 到 1 选择,对于 LRS2 数据集从 0 到 0.25 选择。为了公平比较,解码是通过 CMLR 的宽度为 1 集束宽(beam width)和 LRS2 的宽度为 4 的集束搜索执行的,与 (Chan et al. 2016) 类似。
然而,初步实验结果表明,基于序列到序列的模型很难在 LRS2 数据集上取得合理的结果。这是因为即使是最短的英文句子也包含 14 个字符,解码器在训练开始时仍然难以从所有输入步骤中提取相关信息。因此,为 LRS2 数据集添加了预训练阶段,如 (Afouras et al. 2018)。在预训练时,CNN 对 MV-LRS (Chung and Zisserman 2017) 数据集的单词摘录进行预训练,用于提取预训练集的视觉特征。唇读者在这些冻结的视觉特征上进行训练。预训练从一个单词开始,然后逐渐增加到最大 16 个单词的长度。之后,模型在训练集上进行端到端训练。
实施细节:
唇语阅读器:
CMLR:输入图像的尺寸为 64 × 128。 VGG-M 模型(Chatfield et al. 2014)用于提取视觉特征。唇帧转化为灰度,VGG-M网络以每5个唇帧为输入,每个时间步移动2帧。我们使用2层双向 GRU (Cho et al. 2014),编码器单元大小为 256,解码器单元大小为 512 的2层单向 GRU。对于字符词汇,保留出现超过 20 次的字符。 [sos] => 句子起始标识符、[eos] => 句子结束标识符和 [pad] => 补全字符 也包括在内。最终词汇量为 1779。初始学习率为 0.0003,每次训练误差在 4 个 epoch 内没有改善时,学习率下降 50%。模型预热(He et al. 2016)(即以一个很小的学习率逐步上升到设定的学习率,这样做会使模型的最终收敛效果更好。)用于防止过度拟合。
表 1:CMLR 和 LRS2 数据集中使用的平衡权重。

LRS2:输入图像为 112 × 112 像素,覆盖嘴巴周围区域。用于提取视觉特征的 CNN 基于 (Stafylakis and Tzimiropoulos 2017),在 3D 卷积中具有 5 帧的卷积核宽度。编码器包含 3 层双向 LSTM (Hochreiter and Schmidhuber 1997),单元大小为 256,解码器包含 3 层单向 LSTM,单元大小为 512。唇读器的输出大小为 29,包含 [sos]、[eos]、[pad] 的 26 个字母和标记。预训练的初始学习率为 0.0008,训练的初始学习率为 0.0001,每次训练误差在 3 个 epoch 内没有改善时,初始学习率下降 50%。
两个数据集中使用的平衡权重如表 1 所示。这些值是通过进行grid search(网格搜索)(穷举所有的超参组合)获得的。
语音识别器:
用于训练语音识别器的数据集是 CMLR 和 LRS2 数据集的音频,以及其他语音数据:用于 CMLR 的 aishell (Bu et al. 2017) 和用于 LRS2 的 LibriSpeech (Panayotov et al. 2015)。使用 240 维 fbank(基于滤波器组的特征 Filter bank:语音特征提取算法之一,Fbank保留了更多的原始语音数据) 特征作为语音特征,以 16kHz 采样并计算超过 25ms 的窗口,步长为 10ms。对于 LRS2 数据集,语音识别器和唇读器具有相同的架构。对于 CMLR 数据集,具体来说,考虑了三种不同的语音识别器架构来验证 LIBS 的泛化性。
老师 1:它包含 2 层用于encoder的双向 GRU,单元大小为 256,2 层用于decoder的单向 GRU,单元大小为 512。换句话说,它与唇读器具有相同的架构。
老师 2:encoder 和 decoder 的 单元 大小都是 512。其他与1老师相同。
老师 3:encoder包含 3 层金字塔双向 GRU (Chan et al. 2016)。其他与1老师相同。
值得注意的是,Teacher 2 和 Lip reader 的特征维度不同,Teacher 3 将音频时间分辨率降低了 8 倍。
实验结果:
不同教师模型的有效性:
为了评估所提出的多粒度知识蒸馏方法的泛化性,我们比较了不同教师模型下 LIBS 对 CMLR 数据集的影响。由于 WAS(Watch, Attend and Spell) (Chung et al. 2017) 和基线唇读器(未经知识蒸馏训练)具有相同的Seq2Seq架构, WAS 使用与 LIBS 相同的训练策略进行训练,并在论文中与基线互换使用.从表 2 可以看出,LIBS 在不同的教师模型结构下大大超过了基线。值得注意的是,虽然教师 2 的表现优于教师 1,但对应的学生网络却不然。这是因为 Teacher 2 语音识别器和唇读器的特征维度不同。这意味着直接在相同维度的特征空间中提取知识可以获得更好的结果。在接下来的实验中,我们分析了在 CMLR 数据集上从教师 1 学习的唇读器。
表 2:在 CMLR 数据集上使用不同教师模型时 LIBS 的性能。

多粒度知识蒸馏的效果:
表 3 显示了多粒度知识蒸馏对 CMLR 和 LRS2 数据集的影响。比较 WAS、WAS +LKD1、WAS +LKD1 + LKD2 和 LIBS,所有指标都随着知识蒸馏粒度的增加而增加。越来越多的结果表明,知识蒸馏的每个粒度都能够促进 LIBS 的性能。但是,增加的幅度越来越小,并不表示序列级知识蒸馏比框架级知识蒸馏的影响更大。当只添加一个粒度的知识蒸馏时,WAS+LKD2表现出最好的性能。这是由于上下文级知识蒸馏直接作用于预测字符的特征上。
在 CMLR 数据集上,LIBS 在 CER 中超过 W AS 7.66%。但是,在LRS2 数据集上差距并没有那么大,只有 2.75%。这可能是由于训练策略的差异造成的。在 LRS2 数据集上,CNN 首先在 MV-LRS 数据集上进行预训练。预训练给 CNN 一个很好的初始值,以便在训练过程中提取更好的视频帧特征。为了验证这一点,我们比较了没有预训练阶段的 WAS 和 LIBS。 WAS 和 LIBS 的 CER 分别为 67.64% 和 62.91%,较大的差值为 4.73%。这证实了 LIBS 可以帮助提取更有效的视觉特征的假设。
表 3:多粒度知识蒸馏的效果。

不同数量训练数据的影响:
与唇视频数据相比,语音数据更容易收集。我们评估了 LIBS 在 CMLR 数据集上唇部视频数据有限的情况下的效果。如前所述,句子根据长度分组为子集,只使用第一个子集来训练唇读。第一个子集大约是全训练集的 20%,包含 27262 个句子,每个句子的字符数不超过 11 个。从表 4 可以看出,当训练数据有限时,LIBS 倾向于产生更大的性能增益:CER 的改进从 7.66% 增加到 9.63%,BLEU 的改进从 5.86 增加到 7.96。
表 4:在 CMLR 数据集上使用不同数量的训练数据进行训练时 LIBS 的性能。

与SOTA方法比较:
表 5 显示了与其他框架比较的实验结果:WAS (Chung et al. 2017)、CSSMCM (Zhao, Xu, and Song 2019)、TM-seq2seq(transformer sequence to sequence) (Afouras et al. 2018) 和 CTC/attention (Petridis et al. . 2018). TM-seq2seq 在 LRS2 数据集上实现了最低的 WER,因为它的transformer自注意力架构(V aswani et al. 2017)。由于 LIBS 是为序列到序列架构设计的,因此可以通过将 RNN 替换为transformer 自注意力块。请注意,尽管专为汉语普通话唇读设计的 CSSMCM 具有出色的性能,但 LIBS 在 CER 方面仍以 1.21% 的优势超过它。
表 5:在 CMLR 和 LRS2 数据集上与其他现有框架的性能比较。

可视化:
注意力可视化:
注意机制在输入视频帧和生成的字符输出之间生成显式对齐。由于输入视频帧和生成的字符输出之间的对应在时间上是单调的,是否对齐有对角线趋势是模型性能的反映(Wang et al. 2017)。图 2 在 LRS2 数据集的测试集上可视化了视频帧的对齐方式和具有不同知识蒸馏粒度的相应输出。比较图 2(a) 和图 2(b),添加序列级知识蒸馏提高了生成句子结尾部分的质量。这表明唇读器增强了对整个句子语义信息的理解。添加上下文级知识蒸馏(图 2(c))允许每个解码器步骤的注意力集中在相应的视频帧周围,减少对不相关帧的关注。这也使得预测的字符更加准确。最后,帧级知识蒸馏(图2(d))进一步提高了视频帧特征的可辨别性,使注意力更加集中。生成的句子的质量和可理解性随着知识蒸馏的不同程度的增加而提高。
图 2:视频帧和预测字符之间的对齐,具有不同级别的所提出的多粒度知识蒸馏。纵轴代表视频帧,横轴代表预测字符。基本事实判决是由政府设立的。

Saliency Maps:(用来做模型的解释,哪些变量对于模型是重要的)
显着性可视化技术用于验证 LIBS 通过显示模型在预测时最集中的视频帧区域来增强唇读器提取判别视觉特征的能力。图 3 分别显示了基线模型和 LIBS 的显着性可视化,基于 (Smilkov et al. 2017)。基线模型和 LIBS 都可以正确聚焦在嘴周围的区域,但基线模型的显着区域比 LIBS 更分散。
图 3:WAS 和 LIBS 的显着性图。唇读者学会参加的地方以红色突出显示。

结论:
在这篇文章中,我们提出了LIBS,一种创新的和有效的方法来训练唇读从一个预先训练的语音识别器学习。LIBS从序列级、上下文级和帧级提取多种粒度的语音识别知识,以指导唇读程序的学习。具体来说,这是通过引入一种新的过滤策略来改进语音识别器的特征,并通过采用一种基于跨模态对齐的方法进行帧级知识提取来解决两个序列之间的采样率不一致的问题。实验结果表明,与现有技术相比,所提出的LIBS产生了相当大的改进,尤其是当训练样本有限时。在我们未来的工作中,我们期待着对其他通道对,如语音和手语,采用相同的框架。