NNDL 实验六 卷积神经网络(5)使用预训练resnet18实现CIFAR-10分类
目录
5.5实践:基于ResNet18网络完成图像分类任务
5.5.1数据处理
5.5.1.1数据集介绍
5.5.1.2 数据读取
5.5.1.2 数据集划分
5.5.2模型构建
5.5.2.1使用Resnet18进行图像分类实验
5.2.2.2什么是“预训练模型”?什么是“迁移学习”?
5.5.2.3 比较“使用预训练模型”和“不使用预训练模型”的效果。
5.5.3模型训练
5.5.4模型评价
5.5.5模型预测
思考题
1.阅读《Deep Residual Learning for Image Recognition》,了解5种深度的ResNet(18,34,50,101和152),并简单谈谈自己的看法。(选做)
2.用自己的话简单评价:LeNet、AlexNet、VGG、GoogLeNet、ResNet(选做)
总结
5.5实践:基于ResNet18网络完成图像分类任务
在本实践中,我们实践一个更通用的图像分类任务。
图像分类(Image Classification)是计算机视觉中的一个基础任务,将图像的语义将不同图像划分到不同类别。很多任务也可以转换为图像分类任务。比如人脸检测就是判断一个区域内是否有人脸,可以看作一个二分类的图像分类任务。
这里,我们使用的计算机视觉领域的经典数据集:CIFAR-10数据集,网络为ResNet18模型,损失函数为交叉熵损失,优化器为Adam优化器,评价指标为准确率。
Adam优化算法
Adam 是一种可以替代传统随机梯度下降过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重。Adam 最开始是由 OpenAI 的 Diederik Kingma 和多伦多大学的 Jimmy Ba 在提交到 2015 年 ICLR 论文(Adam: A Method for Stochastic Optimization)中提出的。本文前后两部分都基于该论文的论述和解释。
首先该算法名为「Adam」,其并不是首字母缩写,也不是人名。它的名称来源于适应性矩估计(adaptive moment estimation)。
Adam优势(在非凸优化问题中)
- 实现简单,计算高效,对内存需求少
- 参数的更新不受梯度的伸缩变换影响
- 超参数具有很好的解释性,且通常无需调整或仅需很少的微调
- 更新的步长能够被限制在大致的范围内(初始学习率)
- 能自然地实现步长退火过程(自动调整学习率)
- 很适合应用于大规模的数据及参数的场景
- 适用于不稳定目标函数
- 适用于梯度稀疏或梯度存在很大噪声的问题
Adam 优化算法的基本机制
Adam 算法和传统的随机梯度下降不同。随机梯度下降保持单一的学习率(即 alpha)更新所有的权重,学习率在训练过程中并不会改变。而 Adam 通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。
以上内容参考: (十) 深度学习笔记 | 关于优化器Adam_Viviana-0的博客-CSDN博客_adam优化器
5.5.1数据处理
5.5.1.1数据集介绍
CIFAR-10数据集包含了10种不同的类别、共60,000张图像,其中每个类别的图像都是6000张,图像大小均为![]() 像素。CIFAR-10数据集的示例如 图5.15 所示。
像素。CIFAR-10数据集的示例如 图5.15 所示。

将数据集文件进行解压后:

5.5.1.2 数据读取
在本实验中,将原始训练集拆分成了train_set、dev_set两个部分,分别包括40 000条和10 000条样本。将data_batch_1到data_batch_4作为训练集,data_batch_5作为验证集,test_batch作为测试集。
最终的数据集构成为:
- 训练集:40 000条样本。
- 验证集:10 000条样本。
- 测试集:10 000条样本。
读取一个batch数据的代码如下所示:
import os
import pickle
import numpy as np
def load_cifar10_batch(folder_path, batch_id=1, mode='train'):
if mode == 'test':
file_path = os.path.join(folder_path, 'test_batch')
else:
file_path = os.path.join(folder_path, 'data_batch_' + str(batch_id))
# 加载数据集文件
with open(file_path, 'rb') as batch_file:
batch = pickle.load(batch_file, encoding='latin1')
imgs = batch['data'].reshape((len(batch['data']), 3, 32, 32)) / 255.
labels = batch['labels']
return np.array(imgs, dtype='float32'), np.array(labels)
imgs_batch, labels_batch = load_cifar10_batch(
folder_path='cifar-10-batches-py',
batch_id=1, mode='train')
# 打印一下每个batch中X和y的维度
print("batch of imgs shape: ", imgs_batch.shape, "batch of labels shape: ", labels_batch.shape)运行结果:
![]()
可视化观察其中的一张样本图像和对应的标签,代码实现如下:
import matplotlib.pyplot as plt
image, label = imgs_batch[3], labels_batch[2]
print("The label in the picture is {}".format(label))
plt.figure(figsize=(2, 2))
plt.imshow(image.transpose(1, 2, 0))
plt.savefig('a.pdf')运行结果:
![]()

5.5.1.2 数据集划分
代码如下:
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as transforms
class CIFAR10Dataset(Dataset):
def __init__(self, folder_path='cifar-10-batches-py', mode='train'):
if mode == 'train':
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=1, mode='train')
for i in range(2, 5):
imgs_batch, labels_batch = load_cifar10_batch(folder_path=folder_path, batch_id=i, mode='train')
self.imgs, self.labels = np.concatenate([self.imgs, imgs_batch]), np.concatenate(
[self.labels, labels_batch])
elif mode == 'dev':
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=5, mode='dev')
elif mode == 'test':
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, mode='test')
self.transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
def __getitem__(self, idx):
img, label = self.imgs[idx], self.labels[idx]
img = img.transpose(1, 2, 0)
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
train_dataset = CIFAR10Dataset(folder_path='cifar-10-batches-py',
mode='train')
dev_dataset = CIFAR10Dataset(folder_path='cifar-10-batches-py', mode='dev')
test_dataset = CIFAR10Dataset(folder_path='cifar-10-batches-py', mode='test')5.5.2模型构建
5.5.2.1使用Resnet18进行图像分类实验
代码如下:
from torchvision.models import resnet18
resnet18_model = resnet18()理解ResNet原理:深入浅出读懂ResNet原理与实现_周健文的博客-CSDN博客
5.2.2.2什么是“预训练模型”?什么是“迁移学习”?
预训练模型
在一个原始任务上预先训练一个初始模型,然后在目标任务上使用该模型,针对目标任务的特性,对该初始模型进行精调,从而达到提高目标任务的目的。
在本质上,这是一种迁移学习的方法,在自己的目标任务上使用别人训练好的模型。
迁移学习
迁移学习(Transfer Learning)是机器学习中的一个名词,是指一种学习对另一种学习的影响,或习得的经验对完成其它活动的影响。迁移广泛存在于各种知识、技能与社会规范的学习中。
迁移学习专注于存储已有问题的解决模型,并将其利用在其他不同但相关问题上。比如说,用来辨识汽车的知识(或者是模型)也可以被用来提升识别卡车的能力。计算机领域的迁移学习和心理学常常提到的学习迁移在概念上有一定关系,但是两个领域在学术上的关系非常有限。
迁移学习 (Transfer Learning) - 知乎
什么是预训练模型_小白学编程11的博客-CSDN博客_预训练模型
5.5.2.3 比较“使用预训练模型”和“不使用预训练模型”的效果。
resnet = models.resnet18(pretrained=True)
resnet = models.resnet18(pretrained=False)5.5.3模型训练
RunnerV3类代码实现如下:
class RunnerV3(object):
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric
self.dev_scores = []
self.train_epoch_losses = []
self.train_step_losses = []
self.dev_losses = []
self.best_score = 0
def train(self, train_loader, dev_loader=None, **kwargs):
self.model.train()
num_epochs = kwargs.get("num_epochs", 0)
log_steps = kwargs.get("log_steps", 100)
eval_steps = kwargs.get("eval_steps", 0)
save_path = kwargs.get("save_path", "best_model.pdparams")
custom_print_log = kwargs.get("custom_print_log", None)
num_training_steps = num_epochs * len(train_loader)
if eval_steps:
if self.metric is None:
raise RuntimeError('Error: Metric can not be None!')
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
global_step = 0
for epoch in range(num_epochs):
total_loss = 0
for step, data in enumerate(train_loader):
X, y = data
X = X.cuda()
logits = self.model(X).cuda()
y = y.to(dtype=torch.int64)
y = y.cuda()
loss = self.loss_fn(logits, y)
total_loss += loss
self.train_step_losses.append((global_step, loss.item()))
if log_steps and global_step % log_steps == 0:
print(
f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}")
loss.backward()
if custom_print_log:
custom_print_log(self)
self.optimizer.step()
optimizer.zero_grad()
if eval_steps > 0 and global_step > 0 and \
(global_step % eval_steps == 0 or global_step == (num_training_steps - 1)):
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}")
self.model.train()
if dev_score > self.best_score:
self.save_model(save_path)
print(
f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}")
self.best_score = dev_score
global_step += 1
trn_loss = (total_loss / len(train_loader)).item()
self.train_epoch_losses.append(trn_loss)
print("[Train] Training done!")
import torch
@torch.no_grad()
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
self.model.eval()
global_step = kwargs.get("global_step", -1)
total_loss = 0
self.metric.reset()
for batch_id, data in enumerate(dev_loader):
X, y = data
y = y.to(torch.int64)
X = X.cuda()
y = y.cuda()
logits = self.model(X).cuda()
loss = self.loss_fn(logits, y).item()
total_loss += loss
self.metric.update(logits, y)
dev_loss = (total_loss / len(dev_loader))
dev_score = self.metric.accumulate()
if global_step != -1:
self.dev_losses.append((global_step, dev_loss))
self.dev_scores.append(dev_score)
return dev_score, dev_loss
@torch.no_grad()
def predict(self, x, **kwargs):
self.model.eval()
logits = self.model(x)
return logits
def save_model(self, save_path):
torch.save(self.model.state_dict(), save_path)
def load_model(self, model_path):
state_dict = torch.load(model_path)
self.model.load_state_dict(state_dict)训练代码如下:
import torch.nn.functional as F
import torch.optim as opt
device = torch.device("cuda:0" )
print(device)
# 学习率大小
lr = 0.01
# 批次大小
batch_size = 64
# 加载数据
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
# 定义网络
model = resnet18_model
model.to(device)
# 定义优化器,这里使用Adam优化器以及l2正则化策略,相关内容在7.3.3.2和7.6.2中会进行详细介绍
optimizer = opt.SGD(model.parameters(),lr=lr, momentum=0.9)
# 定义损失函数
loss_fn = F.cross_entropy
# 定义评价指标
metric = Accuracy()
# 实例化RunnerV3
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 启动训练
log_steps = 3000
eval_steps = 3000
runner.train(train_loader, dev_loader, num_epochs=30, log_steps=log_steps,
eval_steps=eval_steps, save_path="best_model.pdparams")运行结果:
cuda:0
[Train] epoch: 0/30, step: 0/18750, loss: 7.38624
[Train] epoch: 4/30, step: 3000/18750, loss: 0.60103
[Evaluate] dev score: 0.69640, dev loss: 0.91229
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.69640
[Train] epoch: 9/30, step: 6000/18750, loss: 0.17661
[Evaluate] dev score: 0.70880, dev loss: 1.17403
[Evaluate] best accuracy performence has been updated: 0.69640 --> 0.70880
[Train] epoch: 14/30, step: 9000/18750, loss: 0.08402
[Evaluate] dev score: 0.71670, dev loss: 1.45985
[Evaluate] best accuracy performence has been updated: 0.70880 --> 0.71670
[Train] epoch: 19/30, step: 12000/18750, loss: 0.00731
[Evaluate] dev score: 0.73200, dev loss: 1.46413
[Evaluate] best accuracy performence has been updated: 0.71670 --> 0.73200
[Train] epoch: 24/30, step: 15000/18750, loss: 0.00303
[Evaluate] dev score: 0.72700, dev loss: 1.61839
[Evaluate]best accuracy performence has been updated: 0.73652 --> 0.71544
[Train] epoch: 28/30, step: 18000/18750, loss: 0.00662
[Evaluate] dev score: 0.73940, dev loss: 1.66308
[Evaluate] best accuracy performence has been updated: 0.73200 --> 0.73940
[Evaluate] dev score: 0.73320, dev loss: 1.69225
[Train] Training done!
5.5.4模型评价
代码如下:
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(test_loader)
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))运行结果:
[Test] accuracy/loss: 0.7271/1.70735.5.5模型预测
代码如下:
# 获取测试集中的一个batch的数据
X, label = next(test_loader())
logits = runner.predict(X)
# 多分类,使用softmax计算预测概率
pred = F.softmax(logits)
# 获取概率最大的类别
pred_class = paddle.argmax(pred[2]).numpy()
label = label[2][0].numpy()
# 输出真实类别与预测类别
print("The true category is {} and the predicted category is {}".format(label[0], pred_class[0]))
# 可视化图片
X=np.array(X)
plt.imshow(X.transpose(1, 2, 0))
plt.show()运行结果:
The true category is 8 and the predicted category is 8思考题
1.阅读《Deep Residual Learning for Image Recognition》,了解5种深度的ResNet(18,34,50,101和152),并简单谈谈自己的看法。(选做)

以上是18层、34层、50层、101层以及152层网络所对应的残差块。
在第四列(34)中,每一行的大概解释如下:
- 第二行表示,从18层到152层的conv1都使用了64个7*7的卷积核
- 第三行表示的是从18层到152层的conv2_x第一步也都使用了3*3的卷积核进行池化
- 第四行表示con2_x的第二步执行了 3个残差块,每个残差块包含两步操作:使用64个3*3的卷积核,进行卷积,执行两次。而最终的结果shape为[56*56*64]
- 同样的,第五行(conv3_x)表示的是4个残差块,每个残差快包含两次相同的卷积:使用128个大小为3*3的卷积核进行卷积
- 第八行为均值池化,从而得到一个1000d的结果,在经过全连接层以及softmax激活函数得到 1*1的输出
经典网络的缺陷用以下图来解释:
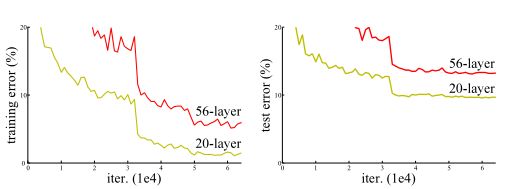
由上图不难看出,此模型56层的训练错误率和测试错误率都要高于20层的模型。由此可见,当模型的深度达到一定程度时会出现退化问题,即深模型的效果比浅模型的效果变差。
ResNet网络通过在网络架构多加入一条恒等映射,经过一次卷积,如果效果变差,则保持权重参数不变,相当于并没有做此次卷积。这样的话,就保证了神经网络不会随着网络层数的增加反而效果变差,也就阻止了模型退化的问题。对不同深度的深度残差网络的效果比较如下图所示:
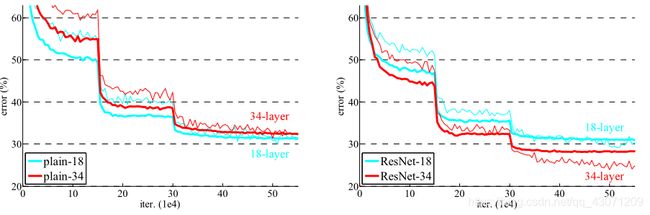
上图为不同深度的ResNet网络和普通网络的训练效果的对比图,图中细曲线代表训练误差,粗曲线代表验证误差,由上图可知,对于普通的网络来说存在着较浅网络的训练效果比较深网络好的情况,但对于ResNet网络来说,不存在这一情况。问题由此解决。
ref:
ResNet网络结构_世界最菜的博客-CSDN博客_resnet网络结构 Resnet网络结构图和对应参数表的简单理解_卡伊德的博客-CSDN博客_resnet网络结构图
2.用自己的话简单评价:LeNet、AlexNet、VGG、GoogLeNet、ResNet(选做)

LeNet:
卷积神经网络的开端
主要特征是将卷积层和下采样层相结合作为网络的基本机构
三个卷积层,两个池化层,两个全连接层。
AlexNet:
使用修正线性函数ReLu提高了训练速度
梯度消失现象出现较弱,有助于训练更深层的网络
VGG:
相较于AlexNet,使用更小的卷积核(层数加深,参数减少)
避免过多的计算量以及过于复杂的结构
GoogLeNet:
不同深度处增加了两个loss来保证梯度回传消失的现象
两个最重要的创新点分别是解决了深度和宽度受限
ResNet:
引入跨层链接,构造残差模块
解决网络退化问题
但训练时间长
总结