电商用户价值分析(应用RFM模型)
有很多种分析电商用户价值的方式,今天来谈谈传统企业和电商用得较多的RFM模型。在众多的客户细分模型中,RFM模型是被广泛提到和使用的。
一、为什么分析
- 内部因素:增加用户的好感度,因为不同的活动会有不用的效果,并且用户的态度也不一样;
- 外部因素:增加业内竞争力,大部分公司意识到精准营销是获客盈利的重要法宝;
二、分析目的
根据用户对公司的贡献,把客户分为重点用户、潜力用户和流失用户三大类,挖掘出各用户群的需求点;
三、分析手段-RFM模型
3.1 名词解释
R、F、M分别代表三个单词:
- R(recency):最近一次消费日期,越近得分越高;
- F(frequency):消费频率,越大得分越高;
- M(monetary):消费金额,越大得分越高;
3.2 基本原理
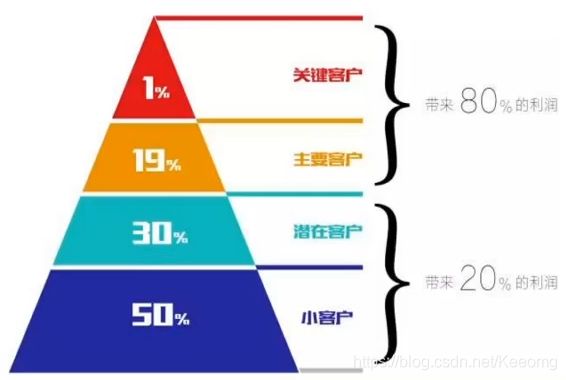
站在公司的角度,用户的等级也是符合”二八定律“,20%的客户带来80%的利润,而剩余80%的用户只带来20%的利润;
我们可以再往下细分,基于R、F、M值这三个维度,将每个维度分为高低两种情况,构建出了一个三维的坐标系,每个小正方形代表一类用户,也就是2^3=8类:
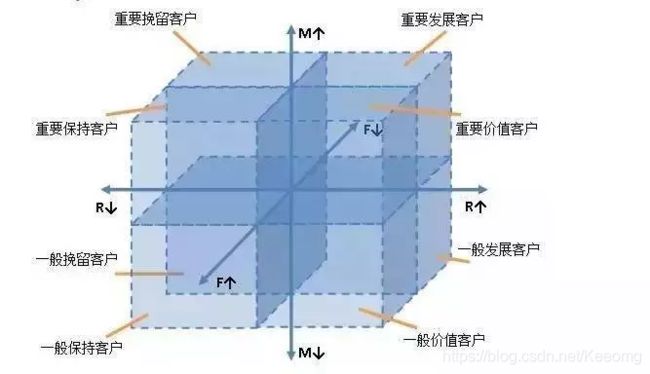
剩下的事情就是根据三维得分,将用户分类。
3.3 打分规则
如果只是按高低来分类,很容易把x-y面、x-z面和y-z面这三个面附近的用户归错类。为了达到更精准的分类,我们先把RFM三值量化成5个区间,再把5^3=25个用户群体压缩到8个,规则如下:
- R值得分规则:把距离最近交易日期的差值从小到大排序,划分为5层,依次给5,4,3,2,1分;
- F值得分规则:把用户的交易频率从大到小排序,划分为5层,依次给5,4,3,2,1分;
- M值得分规则:把用户的总交易金额从大到小排序,划分为5层,依次给5,4,3,2,1分;
- RFM总分:RFM值=0.2R + 0.3F + 0.5*M,从大到小排序,区间为
[5, 4.5); [4.5, 4); [4, 3.5);
[3.5, 3); [3, 2.5); [2.5, 2);
[2,1.5); [1.5, 1];
这里的0.2,0.3,0.5三个权重值不固定,在保证总和1前提下,根据具体业务自由分配
3.4 Python代码实现RFM模型
1.相关第三方数据分析库,其中datetime库是用于转换时间类型:
import pandas as pd
import numpy as np
import csv
import time
from datetime import datetime
#全部行都能输出
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
sale_data = pd.read_csv("D:/data/RFM_E_commerce/rfm_data.csv", encoding = 'gbk')
sale_data.head()

2. 查看字段类型、长度和有无缺失值,如有缺失值需要做缺失值填充;
sale_data.dtypes
len(sale_data)
sale_data.isnull().any()

3. 考虑到用户黏贴度,其黏贴度越高越有价值,这里为了凸显他们的价值,于是做去重处理,当某个客户一天之内有下多个订单的情况我们只记录这个客户当天有下单(非必须项,请根据实际情况考虑是否需要这项处理)
sale_data.drop_duplicates(subset = ['buy_time', 'city_code', 'customer_code'], keep = 'first', inplace = True)
len(sale_data)
4.把buy_time字段转化为时间类型,并计算最后一次消费距离现在的时间间隔date_diff
def time_diff(x):
x=x[0]
day_diff=(pd.to_datetime('today')-x).days
return day_diff
sale_data['buy_time']=pd.to_datetime(sale_data['buy_time'])
sale_data['date_diff']=sale_data.apply(time_diff,axis=1)
sale_data.head()
5.计算’最后一次消费间隔’,‘消费次数’,'消费总额’三个字段实际大小
R_data = sale_data.groupby(['city_code', 'customer_code'])['date_diff']
F_data = sale_data.groupby(['city_code', 'customer_code'])['bill_code']
M_data = sale_data.groupby(['city_code', 'customer_code'])['sale_amt']
R_agg = R_data.agg([('最后一次消费间隔', 'min')])
F_agg = F_data.agg([('消费次数', 'count')])
M_agg = M_data.agg([('消费总额', 'sum')])
rfm = R_agg.join(F_agg).join(M_agg)
rfm

6.把’最后一次消费间隔’,‘消费次数’,'消费总额’三个字段按照五分位数,划分为5层,并给与对应得分;
rfm = rfm.reset_index(drop = False)
bins = rfm['最后一次消费间隔'].quantile(q=np.linspace(0,1,6), interpolation= 'nearest')
bins[0] = 0
labels = [5, 4, 3, 2, 1]
R1 = pd.cut(rfm['最后一次消费间隔'], bins, labels=labels)
bins = rfm['消费次数'].quantile(q=np.linspace(0,1,6), interpolation= 'nearest')
bins[0] = 0
labels = [1, 2, 3, 4, 5]
F1 = pd.cut(rfm['消费次数'], bins, labels=labels)
bins = rfm['消费总额'].quantile(q=np.linspace(0,1,6), interpolation= 'nearest')
bins[0] = 0
labels = [1, 2, 3, 4, 5]
M1 = pd.cut(rfm['消费总额'], bins, labels=labels)
rfm['R1']=R1
rfm['F1']=F1
rfm['M1']=M1
rfm.head()

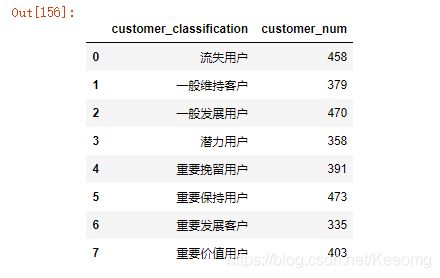
7.按照RFM得分公式,算出总分,划分对应用户等级,并统计出各等级的用户数量,了解总体分布情况。
rfm['RFM'] = 0.2*R1.astype(int) + 0.3*F1.astype(int) + 0.5*M1.astype(int)
bins = rfm['RFM'].quantile(q=np.linspace(0,1,9), interpolation= 'nearest')
bins[0] = 0
labels = ['流失用户', '一般维持客户', '一般发展用户', '潜力用户', '重要挽留用户', '重要保持用户', '重要发展客户', '重要价值用户']
rfm['用户分层'] = pd.cut(rfm['RFM'], bins, labels=labels)
rfm=rfm.rename(columns={'最后一次消费间隔':'last_sale_day','消费次数':'sale_frq','消费总额':'sale_amt','用户分层':'customer_classification',})
rfm_table = rfm.pivot_table(values = 'customer_code', index = 'customer_classification', aggfunc='count')
rfm_result = rfm_table.rename(columns={'customer_code':'customer_num'}).reset_index()
print(rfm_result)
四、分析应用
根据对应的用户类型实施合适的运营策略:

五、模型思考
- 该模型的优点有两个,第一,对于电商公司来说,轻而易举获取需要且准确的数据;第二,分层可解释性强,业务好理解。
- 模型的缺点在于不适用于大电器品类,比如空调、冰箱、电视等使用周期长的电器。
- 模型优化:
第一:阈值(三维权重)的调整,要随着最终划分的人群以及相关的运营效果、活动规律,调整阈值的设定,最终达到一个最合理的划分;
第二:对于高价值用户不公平,比如我是某平台购买力最高的用户,却和下面10%的享受一样的服务,竟然没享受到”皇帝“的待遇肯定不爽啊,应该另给到前10这批用户贵宾般服务作为运营补充。