实时数仓架构那些事儿
最近几个月对数仓架构做了一次升级,很累但很有意义。早就想借这次数仓架构的升级,梳理下最近几年做数仓架构的一些事情,只是没想到今天才下定决心开启梳理历程。作为一个IT码农,从Java研发工程师一步步做到大数据架构师,不是说我有多厉害,只是想说,我的文字水平很差,建议大家从一个技术宅男的角度看我写的文字。最重要的是,希望和大家一起讨论大数据实时数仓架构,不是说我的架构水平多厉害,只是想说,做技术架构是我的爱好。
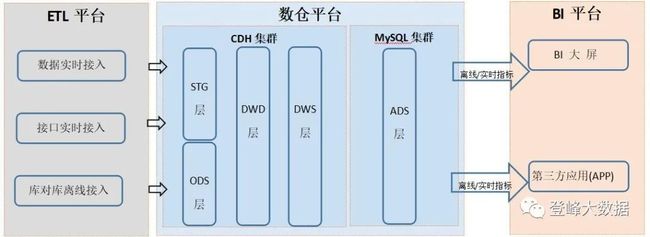
架构师要做的事情很多,不同的项目,不同的公司体量,不同的人员数量都会有不同的技术选型,进而形成不同的架构。在这里,我只想聊流批一体的实时数仓架构,不聊离线数仓架构,不聊Java架构 OR 微服务架构;聊更多的是架构思路,而不是某个技术的详细培训。本文中的架构用于电商供应链项目,日增量在千万数据量级别,总数据存储在TB级别,实时性只能达到秒级(我会说明原因)。所以,本文是否对您有参考价值,应该已经有了判断。
架构背景
背景很简单,公司要求:数仓架构要达到实时指标的秒级响应(数据实时计算),要能够接入各种数据来源(数据实时采集、接入),能够为第三方提供算力支撑(数据实时输出)。最关键的一点是,要省钱(即要用开源技术,不会买商业版软件)。那我们就从数据实时采集、实时接入、实时分析和实时输出这几个方面聊吧。
本系列文章要聊的整体架构图(简化版)
数据实时采集
要做实时采集,必然要用到CDC(变更数据捕获)数据,采集CDC数据的工具有商业版的,也有开源的,我们这次用开源的(Debezium)替换了商业版的(省钱!)。
什么是CDC
CDC是Change Data Capture(变更数据捕获)的简称。主要用途是:检测并捕获数据库的记录变动(记录的增删改)和DDL变动,并将这些变动按发生的顺序完整记录,写入到消息中间件供使用。CDC主要分为基于查询和基于Binlog两种方式,
基于查询的CDC 基于Binlog的CDC 概念 每次捕获变更时,都会发起select查询进行全表扫描,过滤出上次查询之后发生变更的数据。 读取数据存储系统的binlog,获取数据变更。例如MySQL里面的binlog持续监控。 开源产品 Sqoop、Kettle、Kafka JDBC Source Canal、Maxwell、Debezium、Flink CDC 执行模式 Batch Streaming 捕获所有数据的变化 否 是 低延迟、不增加数据库的负载 否 是 不侵入业务(LastUpdated字段) 否 是 捕获删除事件和旧记录的状态 否 是 从中可以看出,基于Binlog的CDC,有很多优势,使用范围也很广。常用于实时数仓场景。
要解决的问题
CDC采集要考虑哪些问题:
-
全量数据如何同步(CDC一般用于增量数据同步)?
-
源头数据库类型有哪些(本文聊Mysql和SqlServer两种)?
-
时间格式和浮点数(decimal)的处理(不是所有工具都能很好处理的,信不?)
-
如果源表添加字段,如何处理(至少要监控到,最好能实时添加到目标表)
-
如果源表有批量操作(批量修改,批量删除会导致CDC数据量猛增),如何处理?
注意,到这一步,我并没有说使用哪个工具采集CDC数据,作为架构师,在这一步,要先想到解决的问题,然后再找能够解决问题的工具,即技术选型。避免犯错:手里有个锤子,看到什么都是钉子。
技术选型
别急,我不会立即告诉你我选择了Debezium这个工具,我想先聊下如何做技术选型,技术选型能力是架构师的一项很重要的能力,一旦选错,会给开发人员带来无尽的痛苦,也就是说,如果开发人员使用你选择的技术,开发效率很高,基本不用加班,恭喜你,你的选择是对的,你的年终评分会很高。
那么,怎么做技术选型呢?
-
首先,和架构师的技术积累、技术广度有关系,每个架构师都有自己的工具箱。试想,如果你只知道有OGG和canal两种CDC采集工具,那你必然会选择OGG处理Oracle数据库的CDC,canal处理Mysql数据库的CDC,如果这样,开发人员要同时会使用/运维这两种工具。这一定是问题吗?不一定,如果你们小组正好有这样的开发人员呢。
-
其次,架构师要了解开发人员的技术栈,他们擅长什么技术,使用过哪些技术。这和上一点是相辅相成的。
-
再次,架构师要有赋能的能力。有时做技术选型,并不能仅仅局限于现有开发人员的技术栈,还要结合工具是否开源?社区是否活跃?文档是否丰富?技术是否成熟?等等等等。这是一个权衡的过程!与其说是一种技术,不如说是一种艺术。如果选择的工具,开发人员都没用过,架构师也不熟悉(极端情况),此时架构师要负责技术调研,制作DEMO,培训文档,进行赋能。
-
最后,所选工具能否解决多少要解决的问题?
下面的表格,是我做技术选型过程中使用的,可以用Excel工具做,也可以在纸张上画出,能达到目的即可。
表1 CDC数据采集技术选型表
| 技术类型 | 易用性 | 技术栈匹配度 | 技术活跃度 | 解决问题的数量 | 备注 |
|---|---|---|---|---|---|
| SDC | 高。有UI界面用于配置。无代码编程。 | 高。Java技术栈。 | 低。高版本闭源了。 | 支持Mysql和SqlServer CDC采集。但无法监控到DDL的变化。只支持增量。 | SDC即Streamsets,此次升级就是要替换它。 |
| Flink CDC | 中。无UI界面,需代码开发,不易运维。 | 低。Flink没有引入架构中,与Spark相比,Flink开发人员不易招聘。 | 高。 | 支持Mysql和SqlServer CDC采集和监控DDL的变化(Stream API)。支持增量和全量。 | 支持的数据库种类多于Debezium。底层使用了Debezium。 |
| Canal、OGG类 | 中。无UI界面。 | 低。 | 中。 | 支持Mysql和SqlServer CDC采集和监控DDL的变化(Stream API)。 | |
| Debezium | 中。有UI界面(简陋)。 | 高。Java技术栈。 | 中。 | 支持Mysql和SqlServer CDC采集和监控DDL的变化(Stream API)。支持增量和全量。 |
有很多ETL工具(注:ETL工具后面详说),自带CDC数据采集组件,比如CDC,但这样就把CDC采集和ETL调度耦合在一起了,我个人不倾向这种形式,这也是我从SDC升级到Debezium的原因。
Debezium
这里我详细说下Debezium,对于SDC的使用,可以看我录制的一套视频《构建实时数仓的流批一体ETL工具-Streamsets》,对于其他CDC采集工具,各自学习吧。Debezium这部分我会录制配套视频。
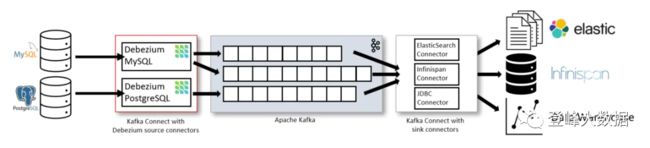
Debezium是一个基于Apache Kafka的CDC开源平台,是一组分布式服务,主要用途是在事务日志中记录提交到每个源数据库表的所有行级更改,以便应用程序可以查看并响应这些更改。Debezium记录提交给每个数据库表的所有行级更改。应用程序可以读取感兴趣的事务日志,以按照操作发生的顺序查看所有操作。Debezium的目标是构建一个连接器库,该连接器库捕获来自各种数据库管理系统的更改,并产生具有非常相似结构的事件,使应用程序更容易使用和响应事件,而不管这些更改来自何处。从本质上说,Debezium是一个连接器集合。
目前有以下连接器:
-
MongoDB
-
MySQL
-
PostgreSQL
-
SQL Server
-
Oracle
-
Db2
Debezium依赖Kafka Connect,Kafka Connect依赖Kafka Broker,Kafka Broker依赖于Zookeeper。实际上,Debezium只是一个kafka connector jar包而已。
Kafka Connect是一个框架,它作为一个独立的服务与Kafka broker一起运行。用于Apache Kafka和其他系统之间的数据同步。
当前架构中使用了CDH,里面有kafka组件,正好匹配
Debezium依赖Kafka Connect,Kafka Connect依赖Kafka Broker这一点。
Debezium在数仓环境中的使用方式
Debezium_Mysql
前置条件
1.mysql数据库
"hostname":"ip",
"port":"3306",2.创建账户并授权
CREATE USER 'debezium'@'localhost' IDENTIFIED BY 'password';
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'debezium' IDENTIFIED BY 'password';3.启用binlog日志
binlog_format = ROW
binlog_row_image = FULL4.验证前置条件是否满足
#检查用户权限是否满足
SHOW GRANTS FOR 'user_name'@'%';
#检查数据库配置是否满足
show variables like 'binlog_%'; 下载并解压jar包
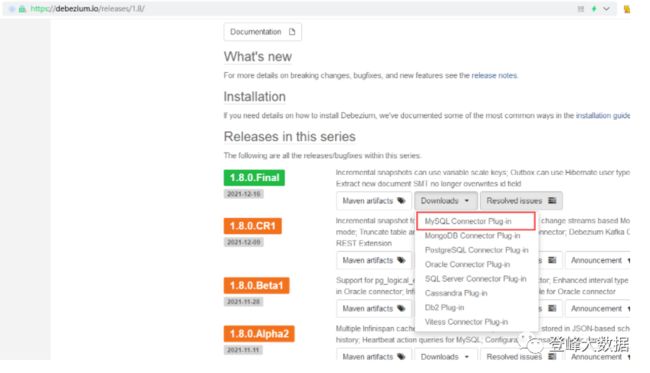
访问Debezium官网下载debezium-connector-mysql-1.8.0.Final-plugin.tar.gz,并解压到服务器上的一个目录中(本例中是:/mnt/lib_conn)
配置connector jar路径
编辑$KAFKA_HOME/config/connect-standalone.properties文件,配置plugin.path值为jar解压目录(/mnt/lib_conn)
bootstrap.servers=localhost:9092
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10000
plugin.path=/mnt/lib_conn启动kafka connect
nohup ./connect-standalone.sh ../config/connect-standalone.properties重启,可以查看进程号,使用kill -9停止kafka connect,然后再次启动即可:
[root@df01 bin]# jps
1351 Jps
808 ConnectStandalone #kafka connect的进程号和进程名称
10762 QuorumPeerMain
14557 Kafka
[root@df01 bin]# kill -9 808
[root@df01 bin]# nohup ./connect-standalone.sh ../config/connect-standalone.properties ../config/connect-file-source.properties &Debezium MySQL Connector配置
{
"name":"mysql-test2-connector",
"config":{
"connector.class":"io.debezium.connector.mysql.MySqlConnector",
"tasks.max":"1",
"database.hostname":"ip",
"database.port":"3306",
"database.user":"debezium",
"database.password":"******",
"database.server.id":"627065325",
"database.server.name":"dbserver1",
"database.include.list":"test2",
"database.history.kafka.bootstrap.servers": "localhost:9092",
"database.history.kafka.topic": "schema-changes.test2"
}
}生产环境中的connector
上面步骤,相当于运行了一个Hello World例子,要用于生产环境,但有几个问题要解决:
-
Debezium运行机制是什么样的
-
全量增量如何处理
-
消息体需优化
-
默认情况,一个表一个topic,用于接收CDC数据。用路由技术路由到一个topic
-
时间格式和Decimal处理
-
DDL日志路由
完整内容,关注公众号 登峰大数据