学习率预热(transformers.get_linear_schedule_with_warmup)
1. 什么是warmup
warmup是针对学习率learning rate优化的一种策略,主要过程是,在预热期间,学习率从0线性(也可非线性)增加到优化器中的初始预设lr,之后使其学习率从优化器中的初始lr线性降低到0,如下图所示:
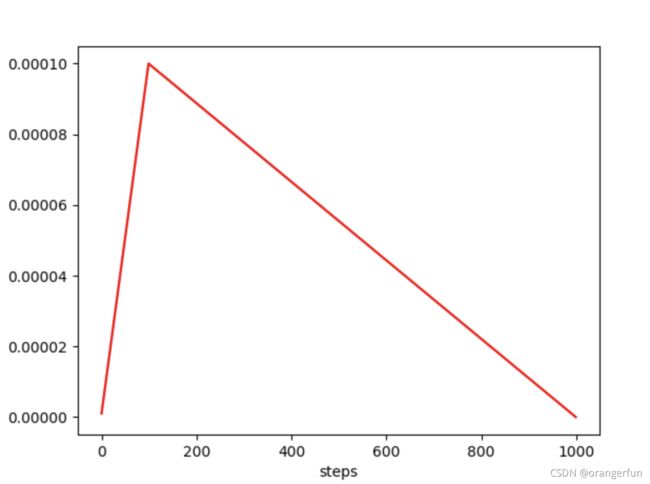
上图中初始learning rate设置为0.0001,设置warm up的步数为100步
2. warmup的作用
由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳
3. transformers.get_linear_schedule_with_warmup使用
from transformers import AdanW, get_linear_schedule_with_warmup
optimizer = AdamW(model.parameters(), lr=lr, eps=adam_epsilon)
len_dataset = 3821 # 可以根据pytorch中的len(Dataset)计算
epoch = 30
batch_size = 32
total_steps = (len_dataset // batch_size) * epoch if len_dataset % batch_size = 0 else (len_dataset // batch_size + 1) * epoch # 每一个epoch中有多少个step可以根据len(DataLoader)计算:total_steps = len(DataLoader) * epoch
warm_up_ratio = 0.1 # 定义要预热的step
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps = warm_up_ratio * total_steps, num_training_steps = total_steps)
......
optimizer.step()
scheduler.step()
optimizer.zero_grad()
get_linear_schedule_with_warmup参数说明:
optimizer: 优化器
num_warmup_steps:初始预热步数
num_training_steps:整个训练过程的总步数
get_linear_schedule_with_warmup是learning rate线性增加和线性衰减,也有非线性的,如下定义了不同类型的warmup策略:
def _get_scheduler(self, optimizer, scheduler: str, warmup_steps: int, t_total: int):
"""
Returns the correct learning rate scheduler
"""
scheduler = scheduler.lower()
if scheduler == 'constantlr':
return transformers.get_constant_schedule(optimizer)
elif scheduler == 'warmupconstant':
return transformers.get_constant_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps)
elif scheduler == 'warmuplinear':
return transformers.get_linear_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps, num_training_steps=t_total)
elif scheduler == 'warmupcosine':
return transformers.get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps, num_training_steps=t_total)
elif scheduler == 'warmupcosinewithhardrestarts':
return transformers.get_cosine_with_hard_restarts_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps, num_training_steps=t_total)
else:
raise ValueError("Unknown scheduler {}".format(scheduler))
注意:当num_warmup_steps参数设置为0时,learning rate没有预热的上升过程,只有从初始设定的learning rate 逐渐衰减到0的过程
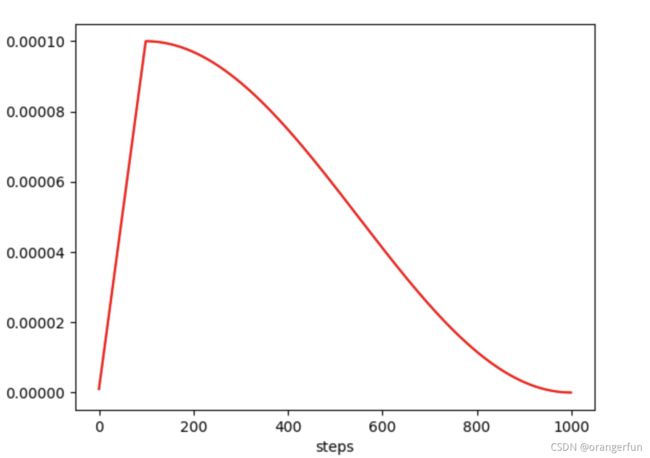
4. 实验
def train(trainset, evalset, model, tokenizer, model_dir, lr, epochs, device):
optimizer = AdamW(model.parameters(), lr=lr)
batch_size = 3
# 每一个epoch中有多少个step可以根据len(DataLoader)计算:total_steps = len(DataLoader) * epoch
total_steps = (len(trainset)) * epochs
scheduler = get_cosine_schedule_with_warmup(
optimizer, num_warmup_steps=100, num_training_steps=total_steps)
model, optimizer = amp.initialize(model, optimizer, opt_level="O1")
lr_record = []
for epoch in tqdm(range(epochs), desc="epoch"):
train_loss, steps = 0, 0
for batch in tqdm(trainset, desc="train"):
batch = tuple(input_tensor.to(device) for input_tensor in batch if isinstance(input_tensor, torch.Tensor))
input_ids, label, mc_ids = batch
steps += 1
model.train()
loss, logits = model(input_ids=input_ids, mc_token_ids=mc_ids, labels=label)
# loss.backward()
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
train_loss += loss.item()
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), 5)
# torch.nn.utils.clip_grad_norm_(model.parameters(), 5)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
lr_record.append(scheduler.get_lr()[0])
if steps % 500 == 0:
print("step:%d avg_loss:%.3f"%(steps, train_loss/steps))
plot(lr_record)
eval_res = evaluate(evalset, model, device)
os.makedirs(model_dir, exist_ok=True)
model_path = os.path.join(model_dir, "gpt2clsnews.model%d.ckpt"%epoch)
model.save_pretrained(model_path)
tokenizer.save_pretrained(os.path.join(model_dir,"gpt2clsnews.tokinizer"))
logging.info("checkpoint saved in %s"%model_dir)
5. 参考
Python transformers.get_linear_schedule_with_warmup() Examples
Warmup预热学习率
关于warm up(transformers.get_linear_schedule_with_warmup)