基于RFM模型与kmeans聚类的用户细分
前面主要是关于客户风险的分析,本文换一个角度,对客户价值做一点研究。
用户与商品(or服务)是企业最重要的资产,当用户数量增长到一个比较庞大的规模,如何有效地管理是需要关注的问题,而用户细分、差异化运营正是是一个可考虑的方向。将相似的用户归类,给每一个类别贴上“标贴”,然后针对各类的特征制定差异化策略。
核心流程主要包含以下模块:
- 用户分群,要求不重不漏,群内差异较小,群间差异较大;
- 对上一步得到的用户群进行特征分析、价值比较;
- 针对不同用户群制定差异化管理策略,实现个性化运营。
主要模型与方法:
- 特征选择(传统RFM模型,从R——最近购买,F——购买频次,M——平均消费金额)
- kmeans聚类(聚类分析常用方法:层次聚类与kmeans聚类,选第二种)
通过一个案例加以说明。
一、案例背景
以数据探索分析用到订单明细作为源数据,属于比较常见的零售数据类型。
![]()
以订单编号标识一条订单记录,商品编码标识订单内的一条明细,以YBM20190201083534100004为例,这条记录由id为106030的用户,在2019/2/1 8:35:35,通过重庆分公司的平台,购买三种商品Y010103201、Y010102635、Y010106332产生。
抽样保留25万+条,明细跨度为3个月,涉及不同用户1万+。
二、数据预处理
订单数据并不能直接建模,首先以RFM模型为基础进行特征选择和统计计算。

处理后的数据如下:
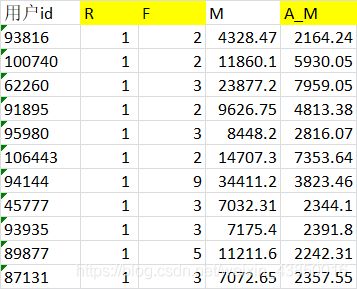
三个指标量纲差距非常大,需要进一步处理,两个思路任选:标准化(均值为0,方差为1);离散化。下面是聚类算法离散化后的结果:
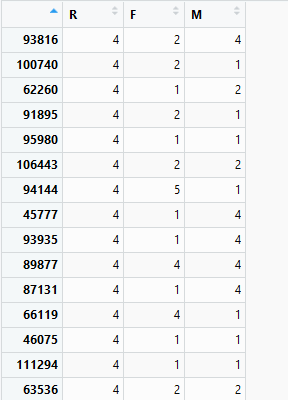

三、用户细分
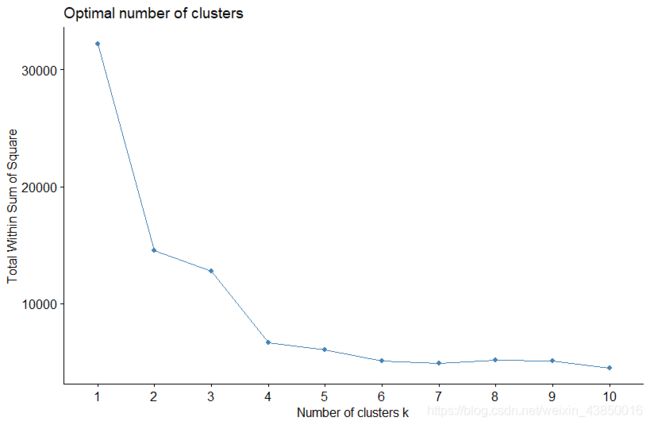
kmeans聚类的类别数需要提前给定,我们知道类别一定是分得越多效果越好,但代价一定也就更大,选择一个合适的类别是非常重要的
1.参考模型
以纵轴的群内方差作为分类效果的度量,模型可以帮我们找到一个群内差异较小,群间差异较小的类别,从4开始方差下降就不明显了,4、5、6都是可以考虑的类别数。
2.实际需求
如果公司有财有力,一对一管理都ok,那类别数自然可以放宽。
又或是公司有心无力,多一条差异化策略也没有,那多一个类别多一份负担。
3.模型结果
分类的要求不只是分开而已,更为重要的是提取各类别的特征,为决策服务。如果出现模型显著,但结果无法解释,或者特征明显,但是数量特别特别少,也是不行的。
四、特征提取
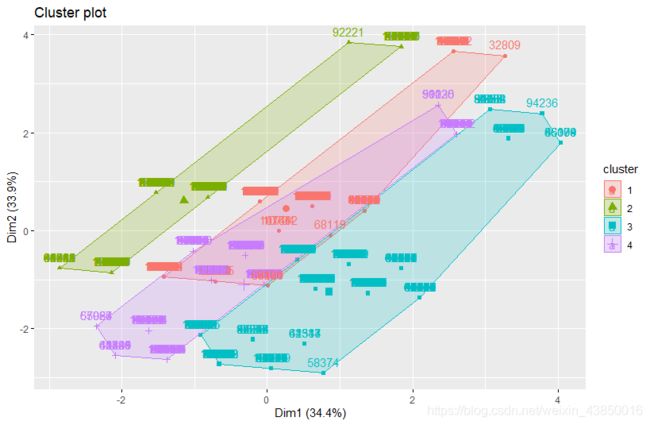
选取4个类别。
超平面上聚类效果,一个颜色代表一个类别所在的区域。整体聚类效果不错,但1和4有点难分。
四个类别分别在R、F、M三个指标上的表现,各类别特征还是非常明显的,注意R是唯一一个反向指标,越大约糟糕。
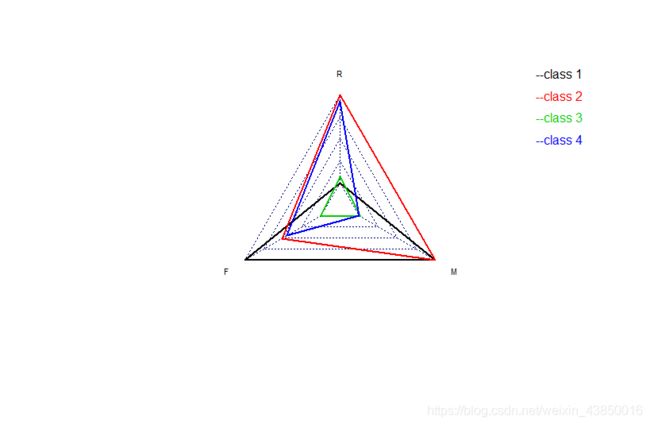
每位用户对应一个类别,各类别特征归纳如下,策略写得比较糙,大致方向是这样的。

五、结论与反思
基于RFM模型和kmeans聚类,可将这份订单数据里用户分为区分度较高的4个类别,针对这四组用户群体各自的特点,考虑制定不同的管理策略。
有两处地方值得注意:
输入指标选取,只选择R、F、M是因为源数据信息有限,条件允许可让更多指标参与建模;
类别数的确定,考虑实际需求以及模型结果的反馈作用。
部分参考代码:
#对R、F、M不做标准化而是离散化处理
#可辅助识别异常值
library(factoextra);library(ggplot2)
fviz_nbclust(as.data.frame(dd$R), kmeans, method = "wss") #5类
fviz_nbclust(as.data.frame(dd$F), kmeans, method = "wss") #5类
fviz_nbclust(as.data.frame(dd$A_M), kmeans, method = "wss")#5类
R<-kmeans(dd$R,5);F<-kmeans(dd$F,5);M<-kmeans(dd$A_M,5)
table(R$cluster);table(F$cluster);table(M$cluster)
newdata<-data.frame(R$cluster,F$cluster,M$cluster)
colnames(newdata)<-c('R','F','M');rownames(newdata)<-dd$用户id
#类别特别少的摘出去
spe<-newdata[which(newdata$F==5|newdata$M==5),]
remain<-newdata[-which(newdata$F==5|newdata$M==5),]
#knn聚类
fviz_nbclust(remain, kmeans, method = "wss") #4或者6
result <- kmeans(remain,4)
type <- result$cluster
table(type)
#可视化1;各维度上的表现
library(fmsb)
max <- apply(result$centers, 2, max)
min <- apply(result$centers, 2, min)
data.radar <- data.frame(rbind(max, min, result$centers))
radarchart(data.radar, pty = 32, plty = 1, plwd = 2, vlcex = 0.7)
# 加图例
L <- 1.2
for(i in 1:4){
text(2, L, labels = paste("--class", i), col = i)
L <- L - 0.2
}
#可视化2:聚类效果
fviz_cluster(result,remain)