5、模块详情及import本质
5-1定义
模块用来从逻辑上组织python代码(变量,函数,类,逻辑。。。),本质就是.py结尾的Python文件。(文件名test.py,对应的模块名:test)
1、定义一个模块module_alex.py
module_alex.py在模块下,定义一变量和一个方
name="kaka"
def sayhi():
print("hello kaka")
2、调用模块
同级目录下建立main.py调用module_alex中的变量或者方法
import module_alex
print(module_alex.name)
module_alex.sayhi()
运行结果
kaka
hello kaka
5-2模块导入方法
方法1、导入一个模块
import module_name #导入一个模块
方法2、导入多个模块
import module1_name,module2_name,module3_name #导入多个模块
方法3、导入所有方法
另外一种方法
module_alex中包含若干个不同的方法,要导入怎么写呢?
from module_alex import * #导入所有方法
from module_alex import *
print(module_alex.name)
module_alex.sayhi()
方法4、方法重名
调用模块的方法名和本地文件的方法名重名了怎么办呢?
module_alex.py
def logger():
print("from module_alex logger")
main.py
from module_alex import *
def logger():
print("in the main")
logger()
运行结果会是什么呢?
in the main
当前文件方法生效
1、from import和import的区别
import ——> 模块名.方法名
import module_alex
module_alex.logger()
import * ——> 模块名.方法名——报错
from module_alex import *
module_alex.logger()
运行报错,说没有定义
Traceback (most recent call last):
File "D:/Python/s014/Day5/main.py", line 4, in
module_alex.logger()
NameError: name 'module_alex' is not defined
这样调用不行引入的是*,相当于把文件整个copy到当前文件中一份,那么要调用就只能通过,方法名的方式
import * ——> 方法名
from module_alex import *
logger()
运行结果
from module_alex logger
2、同名方法使用谁
导入文件中和本地文件使用同名方法,到底谁生效。
module_alex。py
def logger():
print("from module_alex logger") main.py
from module_alex import *
def logger():
print("in the main")
logger() 运行结果:
in the main ————本地生效
那么要导入的同名方法生效怎么办呢?
方法5、as起别名的方式导入
from import logger as logger_alex
from module_alex import logger as logger_alex
def logger():
print("in the main")
logger()
logger_alex()运行结果
in the main
from module_alex logger
方法6 、from import多个方法
from module_alex import m1,m2,m3
5-3 import的本质
1、导入模块的本质
什么是模块呢?本质就是python的.py文件,从逻辑上组件python代码。本质是实现一个功能。
import module_alex
#module_alex=allcode
import的本质是,将导入模块的所有代码编译了一下,赋值给了模块名的一个变量module_alex。如果要调用其中的变量或者方法,就要用模块名.变量名 module_alex.name,
模块名.方法名 module_alex.logger() 来实现。
如果导入多个模块,用逗号分隔。import moudle1,module2, module3
from module_alex import name
做了一件什么事?打开这个module_alex文件,只把文件中的name传过来,做了一次解释,拿到当前页面,执行一遍。
所以,调用的时候直接用变量名就可以了,不用把包名也写上。
那么还想调用Logger方法
from module_alex import name,logger
from module_alex import name,logger
print(name)
logger()
运行结果
kaka
from module_alex logger
2、导入包的本质
包:用来从逻辑上组织模块的。
本质就是一个目录(必须要带一个__init__.py文件)
模块可以导入,那么包可不可以导入呢?如何导入包呢?导入包的本质就是,解释这个包下面的__init__.py文件
做一个实验,新建package_test包__init__.py文件中写入如下代码
print("from package package_test")
运行同级目录下的p_test.py文件,会有什么结果?
运行结果
from package package_test
3、结论
所以,导入模块的本质,就是把python文件解释一遍
导入包的本质,就是执行包下的init文件。
以上的所有导入,都是在同一目录下操作的。
5-4 路径搜索
当前目录没有,就不能直接用import导入
import module_name---> module_name.py---> module_name.py路径----->sys.path
是文件就要有存放的路径,
import 就是找到这个文件的目录,找到了就成功,找不到就抛出异常。
找路径,到哪里去找,1、当前目录。2、环境变量
import sys
print(sys.path)
运行结果——环境变量列表输出
['D:\\Python\\s014\\Day5', 'D:\\Python\\s014', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python35\\python35.zip', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python35\\DLLs', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python35\\lib', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python35', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python35\\lib\\site-packages']
环境变量的一个列表输出
要导入的模块不在列表中。所以报错。
想办法把文件添加到列表中就可以了
import sys,os
#获取当前文件的绝对路径
print(os.path.abspath(__file__))
D:\Python\s014\Day5\p_test.py
我们要路径名,不要文件名
import sys,os
#获取当前文件的绝对路径
print(os.path.abspath(__file__))
#获取路径名
print(os.path.dirname(os.path.abspath(__file__)))
#再上一级目录
print(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
DIR_PATH=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
#添加到环境变量
sys.path.append(DIR_PATH)
print(sys.path)
如果怕有重复的模块路径包含相同名称的文件,在环境变量列表里,可以追加的路径放到最前面,第一位,找到了就不会向下寻找了,可以用insert方法代替append(append是加到列表的追后面,前面有重复的就不会执行)
再导入就不会报错
导入包的目的就是组织模块的。
导入包,包名调用方法名
p_test.py
import package_test #run __init__.py
package_test.test.my_test()
运行报错

为什么没有,导入包和导入模块是不一样的。虽然语法是一样,实际上做的事儿是不一样的。执行init文件,运行完init文件就说明这个包正常导入了,init和test1没有任何关系。所以说不可以这样调用,根本找不到。
所以我们要修改init文件,init文件和test在同级目录,可以导入
包 package_test 的init文件中加入import test
import test
print("from package package_test")
运行p_test.py还是报错
from package package_test
Traceback (most recent call last):
File "D:/Python/s014/Day5/p_test.py", line 7, in
package_test.test.my_test()
AttributeError: module 'test' has no attribute 'my_test'
以上调用好像不行,还是报错,换一种导入方式,试试。
from .当前目录,把test1所有代码拿到当前位置。执行一遍 ,再运行就可以找到。这个(.)点相当于init的相对路径。
from . import test
print("from package package_test")
运行p_test.py
运行结果
from package package_test
mytest fucn
5-5 导入优化
新建文件在test4的目录下建model_test和test两个文件。
model_test模块里做一些什么事情呢?定义一些函数。定义一个test文件来用model_test这个模块
model_test.py
def test():
print("from module_test test") test.py
import model_test
def logger():
model_test.test()
print("logger ...")
def search():
model_test.test()
print("search...") logger()search()运行结果
from module_test test
logger ...
from module_test test
search ...
如果module.test.test方法要调用几百次,第一次调用python会怎么去做 ?
先找到module.test模块,再找到test方法,第二次调用,找到module.test模块,再找到test方法,循环往复,找到了就执行,找不到就出错。都有一个找的过程。一遍一遍重复的找。重复劳动,效率就降低了。
是不是可以解决,优化呢?
重复在找,重复在哪里呢?查找module.test模块的过程
是否可以优化呢?
from model_test import test
def logger():
test()
print("logger ...")
def search():
test()
print("search ...")
logger()
search()
运行结果
from module_test test
logger ...
from module_test test
search ...
把代码拿到当前位置执行一遍,就可以直接调用了
让代码更快的小技巧之一。
5-6-1时间模块
在Python中,通常有这几种方式来表示时间:1)时间戳 2)格式化的时间字符串 3)元组(struct_time)共九个元素。由于Python的time模块实现主要调用C库,所以各个平台可能有所不同。
UTC(Coordinated Universal Time,世界协调时)亦即格林威治天文时间,世界标准时间。在中国为UTC+8。DST(Daylight Saving Time)即夏令时。
时间戳(timestamp)的方式:通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。返回时间戳方式的函数主要有time(),clock()等。
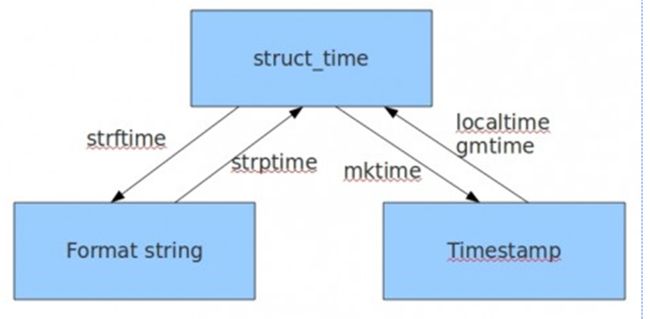
元组(struct_time)方式:struct_time元组共有9个元素,返回struct_time的函数主要有gmtime(),localtime(),strptime()。下面列出这种方式元组中的几个元素:
1、字符串的格式化表示
格式化的字符串表示
2017-07-29 21:32:33
2、时间戳格式
时间戳,本质就是秒数,输出一堆浮点数。
import time
print(time.time())结果
1501337673.6026378
显示的是秒数,从1970年1月1日到现在的秒数
3、元组
功能:返回本地时间的struct_time的格式的对象,也可以把时间戳转换成成struct_time的格式的对象
获得一个元组
import time
print(time.localtime())
time.struct_time(tm_year=2017, tm_mon=8, tm_mday=26, tm_hour=22, tm_min=28, tm_sec=50, tm_wday=5, tm_yday=238, tm_isdst=0)
isdst是否是夏令时
******中国比其他国家早8小时*******
5-6-2 方法详解
1、time.time()
功能:返回当前时间的时间戳(1970年纪元后经过的浮点秒数)
import time
print( time.time() )#返回当前时间的时间戳【运行结果】
1503757832.139651
import time
#跟localtime()结合起来返回当前时间对象
print( time.localtime(time.time()) )
# 给当前时间加上3个小时,注意了,localtime中只能介绍秒级别的,所以是3600*3表示3个小时
print( time.localtime(time.time() + 3600*3))
#跟asctime结合起来用 生成当前时间格式
print( time.asctime( time.localtime( time.time() ) ))
time.struct_time(tm_year=2017, tm_mon=8, tm_mday=26, tm_hour=22, tm_min=35, tm_sec=2, tm_wday=5, tm_yday=238, tm_isdst=0)
time.struct_time(tm_year=2017, tm_mon=8, tm_mday=27, tm_hour=1, tm_min=35, tm_sec=2, tm_wday=6, tm_yday=239, tm_isdst=0)
Sat Aug 26 22:35:02 2017
3、time.localtime()
功能:返回本地时间的struct_time的格式的对象,也可以把时间戳转换成成struct_time的格式的对象
import time
t = time.localtime() #返回本地时间的对象,通过对象获取对应的年月日等信息
print(t)
t.tm_hour # 获取小时数
print(t.tm_hour )
4.time.gmtime()
功能:返回当前utc时间(伦敦时间)
gmtime()括号中传入的是秒,就是时间戳,传完以后返回的结果是一个元祖,
如果不传入,依然可以,返回UTC时区的时间。即,标准时间。
import time
print(time.gmtime() ) #返回utc的时间struct time 格式
print(time.asctime(time.gmtime()) ) #伦敦时间
print(time.asctime(time.localtime()) )#北京时间,两者正好相差8个小时
print(time.localtime()) #返回本地时间的的一个元祖的形式。
time.struct_time(tm_year=2017, tm_mon=8, tm_mday=26, tm_hour=14, tm_min=43, tm_sec=42, tm_wday=5, tm_yday=238, tm_isdst=0)
Sat Aug 26 14:43:42 2017
Sat Aug 26 22:43:42 2017
time.struct_time(tm_year=2017, tm_mon=8, tm_mday=26, tm_hour=22, tm_min=43, tm_sec=42, tm_wday=5, tm_yday=238, tm_isdst=0)
5、time.mktime()
功能:把struct_time时间对象转成时间戳
import time
#生成struct_time时间对象
t = time.strptime("2017-03-30 17:30","%Y-%m-%d %H:%M")
print(t)
#时间对象转成时间戳
t2_stamp = time.mktime(t)
print(t2_stamp)
time.struct_time(tm_year=2017, tm_mon=3, tm_mday=30, tm_hour=17, tm_min=30, tm_sec=0, tm_wday=3, tm_yday=89, tm_isdst=-1)
1490866200.0
import time
#生成struct_time时间对象
t = time.localtime()
print(t)
print(t.tm_year)
time.struct_time(tm_year=2017, tm_mon=8, tm_mday=26, tm_hour=23, tm_min=3, tm_sec=44, tm_wday=5, tm_yday=238, tm_isdst=0)
2017
如果知道一个时间戳,想知道是过去时间的一些信息,
调用x的方法获取。各种属性值,
那当前时间和未来时间呢,一样都可以用
import time
#生成struct_time时间对象
t = time.localtime(123423553)
print(t)
print(t.tm_year)
print("this is 1973 day%d:"%t.tm_yday)
time.struct_time(tm_year=1973, tm_mon=11, tm_mday=29, tm_hour=20, tm_min=19, tm_sec=13, tm_wday=3, tm_yday=333, tm_isdst=0)
1973
this is 1073 day333:
6、time.strptime()
功能:把时间格式的字符串转成struct_time格式的时间对象
import time
# 后面的格式去前面字符串中挨个拽,对应到元祖里
print(time.strptime("2017-03-30 17:30","%Y-%m-%d %H:%M"))
#转换为struct_time格式的时间对象
time.struct_time(tm_year=2017, tm_mon=3, tm_mday=30, tm_hour=17, tm_min=30, tm_sec=0, tm_wday=3, tm_yday=89, tm_isdst=-1)
7、time.strftime()
功能:struct_time时间对象转换成时间字符串
import time
#生成struct_time时间对象
t = time.strptime("2017-03-30 17:30","%Y-%m-%d %H:%M")
#把时间对象转换成时间格式的字符串
m = time.strftime("%Y-%m-%d-%H-%M.log",t)
print(m)
#不传入时间对象,默认是当前时间
m = time.strftime("%Y-%m-%d-%H-%M.log")
print(m)
2017-03-30-17-30.log
2017-08-26-23-11.log
当然,中间如果需要用时间戳转换的话,你还可以这样,代码如下:
import time
#生成struct_time时间对象
t = time.strptime("2017-03-30 17:30","%Y-%m-%d %H:%M")
print(t)
#把时间对象转成时间戳
t2_stamp = time.mktime(t)
print(t2_stamp)
#再通过localtime函数把时间戳转成struct_time时间对象
t3 = time.localtime(t2_stamp)
print(t3)
#把时间对象转换成时间格式的字符串
m = time.strftime("%Y-%m-%d-%H-%M.log",t)
print(m)
time.struct_time(tm_year=2017, tm_mon=3, tm_mday=30, tm_hour=17, tm_min=30, tm_sec=0, tm_wday=3, tm_yday=89, tm_isdst=-1)
1490866200.0
time.struct_time(tm_year=2017, tm_mon=3, tm_mday=30, tm_hour=17, tm_min=30, tm_sec=0, tm_wday=3, tm_yday=89, tm_isdst=0)
2017-03-30-17-30.log
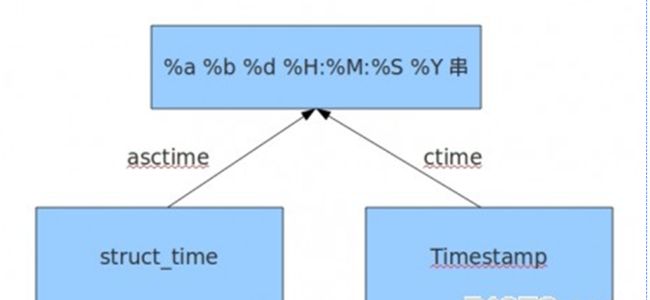
8、time.asctime()
功能:返回时间格式:'Thu Mar 30 16:47:39 2017'(星期月日时间 年)
import time
print(time.asctime())
Sat Aug 26 23:20:20 2017
格式参照
%a 本地(locale)简化星期名称
%A 本地完整星期名称
%b 本地简化月份名称
%B 本地完整月份名称
%c 本地相应的日期和时间表示
%d 一个月中的第几天(01 - 31)
%H 一天中的第几个小时(24小时制,00 - 23)
%I 第几个小时(12小时制,01 - 12)
%j 一年中的第几天(001 - 366)
%m 月份(01 - 12)
%M 分钟数(00 - 59)
%p 本地am或者pm的相应符 一
%S 秒(01 - 61) 二
%U 一年中的星期数。(00 - 53星期天是一个星期的开始。)第一个星期天之前的所有天数都放在第0周。 三
%w 一个星期中的第几天(0 - 6,0是星期天) 三
%W 和%U基本相同,不同的是%W以星期一为一个星期的开始。
%x 本地相应日期
%X 本地相应时间
%y 去掉世纪的年份(00 - 99)
%Y 完整的年份
%Z 时区的名字(如果不存在为空字符)
%% ‘%’字符
9、time.ctime()
功能:传入时间戳,返回string字符串
import time
print(time.ctime())
print(time.asctime())
Sat Aug 26 23:22:05 2017
Sat Aug 26 23:22:05 2017
两种运行结果一样,都是返回这种形式的字符串
区别是啥?传入的值不一样
time.ctime(时间戳)
time.asctime(元祖)
10总结
1、转换方式1
时间戳——>元祖的形式
方法两种,
gmtime()——UTC时间
localtime()——UTC时间+(时差)8小时
2、转换方式2
元祖的形式——>时间戳
striftime(“格式”,“元祖”)—>“格式化字符串”
striptime(“格式化字符串”,“格式”) —>“元祖”
3、转换方式3
time.ctime(时间戳) —>“格式化字符串”
time.asctime(元祖) —>“格式化字符串”
5-6-4 datetime模块
1、datetime.datetime.now()
功能:返回当前时间,格式如:2017-07-30 12:47:03.941925
import datetime
print(datetime.datetime.now())
2017-08-26 23:24:49.9781052、datetime.date.fromtimestamp()
功能:时间戳转换为日期格式
import datetime,time
t = datetime.date.fromtimestamp(time.time())
print(t) #把当天日期的时间戳转换为当天日期
2017-08-263、datetime.timedelta()
功能:对某个时间的加减
import datetime
#当前时间加3天
t1 = datetime.datetime.now()+datetime.timedelta(days=3)
print(t1)
#当前时间减3天
t1 = datetime.datetime.now()-datetime.timedelta(days=3)
print(t1)
#当前时间减3天
t1 = datetime.datetime.now()+datetime.timedelta(days=-3)
print(t1)
#当前时间加3个小时
t1 = datetime.datetime.now()+datetime.timedelta(hours=3)
print(t1)
#当前时间加30分钟
t1 = datetime.datetime.now()+datetime.timedelta(minutes=30)
print(t1)
2017-08-29 23:28:52.482309
2017-08-23 23:28:52.482309
2017-08-23 23:28:52.482309
2017-08-27 02:28:52.482309
2017-08-26 23:58:52.4823094、时间替换
import datetime
c_time = datetime.datetime.now()
#当前时间输出
print(c_time)
#时间替换
update_c_time = c_time.replace(minute=3,hour=2)
#替换后的时间输出
print(update_c_time)
2017-08-26 23:30:45.210981
2017-08-26 02:03:45.210981
5-6-5 random模块
1、random.random()
功能:随机返回一个小数
import random
print(random.random()) #随机返回一个小数
0.80487035665312572、random.randint(a,b)
功能:随机返回a到b之间任意一个数,包括b
import random
print(random.randint(1,5))#可以返回5
print(random.randint(1,5))
3
5
3、random.randrange()
功能:随机返回start到stop,但是不包括stop值
import random
print(random.randrange(5)) #不能随机返回5
print(random.randrange(5)
1
1)
4、random.sample(population, k)
功能:从population中随机获取k个值,以列表的形式返回
import random
print(random.sample(range(10),3) ) #从0-9返回3个随机数
print(random.sample('abcdefghi',3) ) #从'abcdefghi'中返回3个字符
[4, 3, 2]
['e', 'i', 'c']
5生成随机数
5-1、用random和string模块生成随机数
import random,string
str_source = string.ascii_lowercase + string.digits
#大写字母字符和0-9数字字符串拼接
print(str_source)
print(random.sample(str_source,6) ) #取6个随机字符
print(''.join(random.sample(str_source,6)) ) #生成一个随机数字符串
abcdefghijklmnopqrstuvwxyz0123456789
['l', 'd', '2', 'n', 'v', 'p']
k6xor3
5-2、程序实现
import random
checkcode = ''
for i in range(4):
current = random.randrange(0,4)
if current != i:
#如果当前的loop i不等于随机数,就取出65-90中的随机字符
temp = chr(random.randint(65,90))
else:
temp = random.randint(0,9)
checkcode += str(temp)
print(checkcode)
1YC0
5-5-6 os模块
提供对操作系统进行调用的接口
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
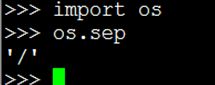
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
1、os.getcwd()
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径,相当于Linux的pwd
import os
print(os.getcwd())
D:\Python\s014\Day4\test4
2、os.chdir("dirname")
功能:切换路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
直接切换,是否能成功?
看不懂,但是和上面的cwd路径相比少了一个斜杠呢
解决方式1,
加转义字符斜杠。没有报错,打印一下路径,成功切换。
import os
print(os.getcwd())
os.chdir("D:\\test")
print(os.getcwd())
D:\Python\s014\Day4\test4
D:\test
解决方式2,(推荐使用此种方式)
加r去掉转义字符。
import os
print(os.getcwd())
os.chdir(r"D:\test")
print(os.getcwd())
D:\Python\s014\Day4\test4
D:\test
3、os.curdir
import os
print(os.curdir)
os.curdir 返回当前目录: ('.')
这是一个属性,不是一个方法。
4、os.pardir
os.pardir 获取当前目录的父目录字符串名:('..')
import os
print(os.pardir)
..5、os.makedirs
os.makedirs('dirname1/dirname2') 递归创建某个目录
什么叫递归的创建呢,就是创建的目录不存在,父级目录也不存在
C:\a\b\c\d,目的是创建d文件夹,但是\a\b\c都不存在
import os
os.makedirs(r"C:\a\b\c\d")查看是否创建成功

6、os.removedirs()
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
import os
os.removedirs(r"C:\a\b\c\d")
执行过后,\d被删除了,但是c,b,a都是空的文件夹,所以逐一返回上一层的时候删除了,所以,\a\b\c都没有了
7、os.mkdir
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
import osos.mkdir(r"C:\a")
os.mkdir(r"C:\a\b")
用此命令创建多级目录报错,创建单级目录成功。
先建a,再建b执行成功
8、os.rmdir()
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
import os
# os.mkdir(r"C:\a\b")
os.rmdir(r"C:\a\b")
a文件夹还在,只删掉了b
9、os.listdir('dirname')
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
import os
print(os.listdir("."))
['model_test.py', 'test.py', '__pycache__']指定一个具体的路径也可以
import os
print(os.listdir("d:\\test"))
['andashu2', 'catalina.out', 'catalina.sh', 'dang.sql', 'dangdang_dk', 'dangdang_dk.war', 'heapdump-HJ01.hprof', 'huojia.txt', 'ifcfg-eth0', 'index.jsp', 'nginx.conf', 'profile', 'startup.bat', 'startup.sh', 'startup.sh1', 'startup_j.sh', 'startup_jprofiler.sh', 'startup_jprofiler.sh 1', 'startup_jvisualvm.sh', 'test1.war', '替换文件']
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
10、os.stat
os.stat('path/filename') 获取文件/目录状态信息
import os
print(os.stat("."))
os.stat_result(st_mode=16895, st_ino=1970324837013096, st_dev=3460675811, st_nlink=1, st_uid=0, st_gid=0, st_size=4096, st_atime=1503798385, st_mtime=1503798385, st_ctime=1503744457)
11、各种分隔符
1、os.sep 路径分隔符
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
Windows
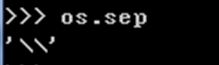
Linux
2、os.linesep 换行分隔符
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
3、os.pathsep 环境变量分隔符
os.pathsep 输出用于分割文件路径的字符串
Windows
;
Linux
:
12、其他
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
查看当前目录下都有什么内容
import os
print(os.system("dir"))
������ D �еľ��� �¼Ӿ�
�������� CE45-B8E3
D:\Python\s014\Day4\test4 ��Ŀ¼
2017/08/27 09:53 .
2017/08/27 09:53 ..
2017/08/26 22:17 76 model_test.py
2017/08/27 09:53 639 test.py
2017/08/26 22:19 __pycache__
2 ���ļ� 715 �ֽ�
3 ��Ŀ¼ 26,901,798,912 �����ֽ�
0
import os
print(os.system("ipconfig"))
os.path
os.path.abspath(path) 返回path规范化的绝对路径
import os
print(os.path.abspath("."))
D:\Python\s014\Day4\test4os.path.split(path) 将path分割成目录和文件名二元组返回
import os
print(os.path.split(r"D:\Python\s014\homework\ATM\userinfo\user3.dat"))
('D:\\Python\\s014\\homework\\ATM\\userinfo', 'user3.dat')
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
import os
print(os.path.dirname(r"D:\Python\s014\homework\ATM\userinfo\user3.dat"))
D:\Python\s014\homework\ATM\userinfo
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
import os
print(os.path.basename(r"D:\Python\s014\homework\ATM\userinfo\user3.dat"))
user3.dat
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
一定从某一个根开始。win有很多根,c:\, d:\,e:\都是根。linux的/开头的都是根。
Windows
import os
print(os.path.join("C:",r"\g\d\user3.dat"))
C:\g\d\user3.datlinux
import os
print(os.path.join("/","a","abc.txt"))
/a/abc.txt
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
import os
print(os.path.getatime("D:\Python\s014\homework\ATM\docs\README"))
1503130319.072348
import os
print(os.path.getmtime("D:\Python\s014\homework\ATM\docs\README"))
1503130319.0883489
5-5-7 sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径
把脚本后面的参数都加上了,读取参数用的
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout.write('please:')
val = sys.stdin.readline()[:-1]
5-5-8 string模块
1、string.ascii_letters
功能:返回大小写字母的字符串
import string
print(string.ascii_letters)
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
2、string.ascii_lowercase
功能:返回小写字母的字符串
import string
print(string.ascii_lowercase)
abcdefghijklmnopqrstuvwxyz
3、string.ascii_uppercase
功能:返回大写字母的字符串
import string
print(string.ascii_uppercase)
ABCDEFGHIJKLMNOPQRSTUVWXYZ
4、string.digits
功能:返回0-9数字的字符串
import string
print(string.digits)
01234567895、string.punctuation
功能:返回所有特殊字符,并以字符串形式返回
import string
print(string.punctuation)
!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
5-6-8 shutil 模块
1、shutil.copyfileobj()
功能:把一个文件的内容拷贝到另外一个文件中
import shutil
# “本节笔记”文件要存在,“目标文件”自动创建
f1=open("本节笔记",encoding="utf-8")
f2=open("目标文件","w",encoding="utf-8")
shutil.copyfileobj(f1,f2)
ps:要指定文件编码,不然报错
2、shutil.copyfile()
功能:拷贝文件,但是不拷贝所有权限
import shutil
shutil.copyfile("本节笔记","copy的笔记")
输入文件名,就自动copy,不用做前面的打开的操作,既可以完成。
copy的笔记不用创建,自动创建文件到当前目录下
3、shutil.copymode()
功能:拷贝文件的文件权限
只copy权限,内容,组,用户均不变。没有创建文件。
st_mode=33206就是权限,其他的信息使用新建文件自己的,内容,宿主
[root@whtest137 ~]# ll
total 8
-rwxr-xr-x 1 root root 0 Apr 1 16:05 kaka #有执行权限
-rw-r--r-- 1 whtest whtest 0 Apr 1 16:06 kaka_old #没有执行权限
>>> import os,shutil
>>> os.chdir("/root")
#拷贝"kaka_old"权限给"kaka"
>>> shutil.copymode("kaka_old","kaka")
[root@whtest137 ~]# ll
total 8
-rw-r--r-- 1 root root 0 Apr 1 16:05 kaka
# 获得跟"kaka_old"一样的文件权限
-rw-r--r-- 1 whtest whtest 0 Apr 1 16:06 kaka_old
4、shutil.copystat
功能:拷贝文件所有状态信息,如:mode bits, atime, mtime, flags
#两个文件的创建时间和用户权限都不同
[root@jenkins_sh temp]# ll
total 0
-rw-r--r-- 1 root root 0 Apr 1 17:31 kaka
-rwxr-xr-x 1 jenkins jenkins 0 Apr 1 16:26 kaka_old
#python操作
>>> import os,shutil
>>> os.chdir("/temp")
#kaka 这个文件状态
>>> os.stat("kaka")
posix.stat_result(st_mode=33188, st_ino=76808194, st_dev=2053L, st_nlink=1,
st_uid=0, st_gid=0, st_size=0, st_atime=1491039109, st_mtime=1491039109,
st_ctime=1491039109)
#kaka_old的文件状态
>>> os.stat("kaka_old")
posix.stat_result(st_mode=33261, st_ino=76808195, st_dev=2053L, st_nlink=1,
st_uid=101, st_gid=103, st_size=0, st_atime=1491035188, st_mtime=1491035188,
st_ctime=1491035242)
#拷贝kaka_old 文件状态给kaka 文件
>>> shutil.copystat("kaka_old","kaka")
# 拷贝后,kaka文件的文件状态
>>> os.stat("kaka")
posix.stat_result(st_mode=33261, st_ino=76808194, st_dev=2053L, st_nlink=1,
st_uid=0, st_gid=0, st_size=0, st_atime=1491035188, st_mtime=1491035188,
st_ctime=1491039237)
#操作后两个文件比较
[root@jenkins_sh temp]# ll
total 0
-rwxr-xr-x 1 root root 0 Apr 1 16:26 kaka
#状态包括文件权限,文件创建的时间等,不包括文件所属用户和用户组
-rwxr-xr-x 1 jenkins jenkins 0 Apr 1 16:26 kaka_old
5、shutil.copy()
功能:拷贝文件和文件的权限
#拷贝前
[root@jenkins_sh temp]# ll
total 0
-rwxr-xr-x 1 jenkins jenkins 0 Apr 1 16:26 kaka_old
#拷贝中
>>> import os,shutil
>>> os.chdir("/temp")
>>> shutil.copy("kaka_old","kaka")
#拷贝结果输出
[root@jenkins_sh temp]# ll
total 0
-rwxr-xr-x 1 root root 0 Apr 1 17:42 kaka
#拷贝了kaka_old文件和文件权限
-rwxr-xr-x 1 jenkins jenkins 0 Apr 1 16:26 kaka_old
6、shutil.copy2(src, dst)
功能:拷贝文件和文件的状态
#拷贝前
[root@jenkins_sh temp]# ll
total 0
-rwxr-xr-x 1 jenkins jenkins 0 Apr 1 16:26 kaka_old
#拷贝中
>>> import os,shutil
>>> os.chdir("/temp")
>>> shutil.copy2("kaka_old","kaka")
#拷贝后
[root@jenkins_sh temp]# ll
total 0
-rwxr-xr-x 1 root root 0 Apr 1 16:26 kaka #拷贝了kaka_old的文件和状态
-rwxr-xr-x 1 jenkins jenkins 0 Apr 1 16:26 kaka_old
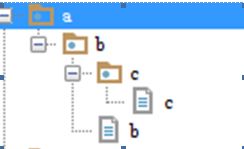
7、shutil.copytree(src, dst)
功能:递归的去拷贝文件,不存在的直接创建,相当于cp -r
import shutil
shutil.copytree("a","new_a")
a的目录结构如下
运行后生成new_a,完整的copy了一份目录
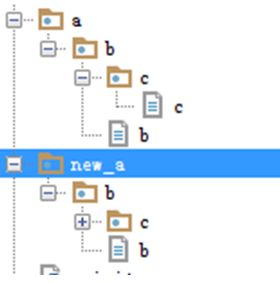
9、shutil.rmtree()
功能:递归的去删除文件,相当于:rm -fr
import shutil
shutil.rmtree("new_a")
删除目录操作,运行之后,确实new_a的目录没有了
10、shutil.move()
功能:递归的去移动文件 相当于:mv
#操作前
[root@jenkins_sh temp]# ll
total 4
drwxr-xr-x 2 root root 4096 Apr 1 18:07 jia
-rw-r--r-- 1 root root 0 Apr 1 18:07 kaka
#操作中
>>> import shutil
>>> shutil.move("/temp/kaka","/temp/jia")
#把文件移到目录中
#操作结果
[root@jenkins_sh jia]# ll
total 4
drwxr-xr-x 2 root root 4096 Apr 1 18:08 jia
[root@jenkins_sh temp]# cd jia/;ll
total 0
-rw-r--r-- 1 root root 0 Apr 1 18:07 kaka
5-6-9 压缩模块
1、shutil.make_archive()
功能:创建压缩包并且返回文件路径,例如:zip,tar
shutil.make_archive("文件名","压缩类型","压缩谁?路径")
#指定路径
>>> import shutil
#把/temp下的jia文件以zip压缩格式压缩,并且存放在/temp/kaka目录下,"/temp/kaka/jia" 中的jia是压缩名
>>> shutil.make_archive("/temp/kaka/jia",'zip',"/temp/jia")
'/temp/kaka/jia.zip' #压缩结果
#默认当前路径
shutil.make_archive("jia",'zip',"/temp/jia")
'/temp/jia.zip'
2、zipfile
功能:以zip的形式压缩文件,注意了这个只能压缩文件,不能压缩目录,如果压缩,也只能显示空目录。
import zipfile
# 压缩
z = zipfile.ZipFile('laxi.zip', 'w')
z.write('a.log') #写入一个文件
z.write('data.data') #写入一个文件
z.close() #关闭
# 解压
z = zipfile.ZipFile('laxi.zip', 'r')
z.extractall() #解压
z.close()
3、tarfile
功能:以tar的形式打包文件,这边能打包所以文件,包括目录
import tarfile
# 打包
tar = tarfile.open('your.tar','w')
#不加arcname打的是绝对路径,也就是/Users/wupeiqi/PycharmProjects/bbs2.zip,加这个表示你在your.tar中加什么文件就写什么文件名,也就是bbs2.zip
tar.add('/Users/wupeiqi/PycharmProjects/bbs2.zip', arcname='bbs2.zip')
tar.add('/Users/wupeiqi/PycharmProjects/cmdb.zip', arcname='cmdb.zip')
tar.close()
# 解压
tar = tarfile.open('your.tar','r')
tar.extractall() # 可设置解压地址
tar.close()
小结:
tar打包不会压缩文件,所以文件的大小没有变
zip才会压缩,所以压缩后的文件大小会变小
一般情况下是先打包再压缩
5-6-10 shelve模块
之前我们说不管是json也好,还是pickle也好,在python3中只能dump一次和load一次,不能dump多次,和load多次,但是我们真想要dump多次和load多次怎么办呢,并且能事项数据的持久化? shelve模块是对pickle更上一层的封装。
1、shelve概念
1-1、持久化
import shelve
import datetime
d=shelve.open("shelve_test")
dt=datetime.datetime.now()
info={"name":"kaka","age":18}
name=["aaa","bbb","ccc"]
d["name"]=name #持久化列表
d["info"]=info #持久化字典
d["date"]=dt
d.close()
代码执行结果:
自动生成三个文件,分别是:shelve_test.dir、shelve_test.dat、shelve_test.bak
存进去了,如何读取出来呢?
import shelve
import datetime
d=shelve.open("shelve_test")
print(d.get("name"))
print(d.get("info"))
print(d.get("date"))
d.close()
运行结果:
['aaa', 'bbb', 'ccc']
{'name': 'kaka', 'age': 18}
2017-08-09 22:44:38.425340
四、总结
shelve模块是一个简单的key,value将内存数据通过文件持久化的模块。
shelve模块可以持久化任何pickle可支持的python数据格式。
shelve就是pickle模块的一个封装。
shelve模块是可以多次dump和load。
5-5-11 XML模块
xml是实现不同语言或者程序之间进行数据交换的协议,跟json差不多,但是json使用起来更简单,不过,古时候,在json还没有诞生的黑暗年代,大家只能选择xml,到现在仍然有很多传统的公司,像金融行业的很多系统的接口还是xml。
1、xml的格式
说明:就是通过<>节点来区别数据结构的,格式如下:
2
2008
141100
5
2011
59900
69
2011
13600
2、查询xml文档内容
运行结果
打印了一段内存地址和根节点的名字
Import xml.etree.ElementTree as et
tree =et.parse("xmltest.xml")#要处理那个文件
root =tree.getroot() #获取根节点
print(root.tag) #打印节点名称
#遍历xml文档
forchild inroot:
print(child.tag,child.attrib) #分别打印子节点名称和子节点属性
#遍历子节点下的所有节点
for i in child:
print(i.tag,i.text) #打印子节点下节点的节点名和节点值
#只遍历year节点
fori in child.iter("year"):
print("\t",i.tag,i.attrib,i.text)
#只遍历year节点
for node in root.iter("year"):
print(node.tag,node.text) #打印year的节点名和节点值
- tag是返回节点名,attrib返回节点属性,text返回节点值
- 返回根节点用getroot()方法
- 只遍历某个节点,只需要用iter(节点名)方法
2、修改xml文档内容
importxml.etree.ElementTree as et
tree =et.parse("xmltest.xml")
root =tree.getroot()
#修改year节点的值
fornode inroot.iter("year"):
new_year =int(node.text) +1 #修改节点值
node.text =str(new_year) #修改后强制转换成字符串类型
node.tag ="myyear" #修改节点名
node.set("ksks",'handsome') #修改节点属性
tree.write("xmltest1.xml") #修改完成后,重新写入xml文件(可以是任何文件,包括原来的)
注:可以修改xml文件中的任何内容,包括本身的节点名,修改后一定要有写入xml文件的操作。
3、删除node节点
importxml.etree.ElementTree as et
tree =et.parse("xmltest.xml")
root =tree.getroot()
#删除
forcountry inroot.findall("country"): #找到第一层子节点
rank =int(country.find("rank").text)
#找到子节点下的'rank'节点的节点值
ifrank > 50:
root.remove(country) #删除子节点
tree.write("xmltest1.xml") #重新写入xml文件
- findall()从根节点只能根据第一层的子节点名查找,并且返回第一层子节点的内存地址
- find从根节点查找第一层子节点名,返回第一层子节点下的所有节点的内存地址
- 删除子节点用remove()方法
- 删除以后,一定要做重新写入新的xml文件操作
1、手动创建xml文件
importxml.etree.ElementTree as et
new_xml =et.Element("namelist") #创建根节点
#创建第一层子节点,后面参数依次是:父节点,子节点,子节点属性
name =et.SubElement(new_xml,"name",attrib={"ksks":"handsome"})
#创建第二层子节点
age =et.SubElement(name,"age",attrib={"check":"yes"})
#设置第二层节点值
age.text ='22'
sex =et.SubElement(name,"sex")
sex.text ="man"
#创建另外一个第一层子节点
name2 =et.SubElement(new_xml,"name",attrib={"ksks":"haoshuai"})
#创建其第二层子节点
age =et.SubElement(name2,"age")
age.text ='19'
ET =et.ElementTree(new_xml) #生成新的xml文档
ET.write("test.xml",encoding="utf-8",xml_declaration=True) #在新xml文件的开头自动添加:
et.dump(new_xml) #在屏幕上打印生成的格式
注:et.dump(new_xml)这个有什么作用呢?当你需要直接把字符串传过去,不需要串文件时,用这个就ok了。
5-6-12配置文件模块
1、配置文件格式
[DEFALUT]
compressionlevel = 9
serveraliveinterval = 45
compression = yes
forwardx11 = yes
[bitbucket.org]
user = hg
[topsecret.server.com]
host port = 50022
forwardx11 = no
2、创建配置文件
说明:其实有的时候我们很少创建,除非是用系统管理,一般直接修改就可以了,但是还是要掌握的。
代码如下:
import configparser #导入configparser模块
#创建一个对象
config = configparser.ConfigParser()
#配置默认全局配置组
config["DEFALUT"] = {"ServerAliveInterval":"45",
"Compression":"yes",
"CompressionLevel":"9"
}
#配置第一个其他组
config["bitbucket.org"] = {}
#没有没有赋给一个变量,直接赋值
config["bitbucket.org"]["User"] = 'hg'
#配置第二个其他组
config["topsecret.server.com"] = {}
#这边就赋给一个变量
topsecret = config["topsecret.server.com"]
#通过变量赋值
topsecret["Host Port"] = '50022'
topsecret["ForwardX11"] = 'no'
#给全局配置组赋值
config["DEFALUT"]["ForwardX11"] = "yes"
#操作完毕,把配置的内容写入一个配置文件中
with open("example.ini","w") as configfile:
config.write(configfile)
3、读取配置文件
1、读取配置组
>>> import configparser
>>> config = configparser.ConfigParser()
>>> config.sections() #不读取配置文件,组名列表为空
>>> config.read("example.ini")
#读取配置文件,返回配置文件名
['example.ini']
>>> config.sections() #返回除默认配置组的其他组名
['bitbucket.org', 'topsecret.server.com']
>>> config.defaults() #读取默认配置组,并返回有序字典
OrderedDict([('compressionlevel', '9'), ('serveraliveinterval', '45'), ('compression', 'yes'), ('forwardx11', 'yes')])
2、组名是否存在
>>> 'bitbucket.org' in config #组名存在
True
>>> 'ksks.org' in config #组名不存在
False
3、读取组内的值
>>> config["bitbucket.org"]["User"]
#读取"bitbucket.org"配置组中的值
'hg'
>>> config["DEFAULT"]["Compression"] #读取默认配置组中的值
'yes'
>>> topsecret = config['topsecret.server.com']
#把配置组赋给一个对象
>>> topsecret['ForwardX11'] #通过对象获取值
'no
4、 循环获取组内的key值
#循环打印bitbucket.org组下的key值
>>> for key in config["bitbucket.org"]:
... print(key)
...
#输出,只打印默认组和bitbucket.org组的key值
user
compressionlevel
serveraliveinterval
compression
forwardx11
#循环打印topsecret.server.com组下的key值
>>> for key in config["topsecret.server.com"]:
... print(key)
#输出,只打印默认组和topsecret.server.com组的key值
host port
forwardx11
compressionlevel
serveraliveinterval
compression
注:默认组是全局的,所以循环遍历key值时,会遍历从默认组和需要遍历的组一起遍历出来。
4、configuration的增删改查
1、配置文件名i.cfg
[DEFAULT]
k1 = v1
k2 = v2
[section1]
k3 = v3
k4:v4
[section2]
k5 = 5
2、读i.cfg
import configparser
config = configparser.ConfigParser()
config.read("i.cfg")
sec = config.sections()
print(sec)
#输出
['section1', 'section2']
options = config.options("section2") #返回默认组和section2组的key值
print(options)
#输出
['k5', 'k1', 'k2']
item_list = config.items("section2") #返回默认组和section2组的key-value值
print(item_list)
#输出
[('k1', 'v1'), ('k2', 'v2'), ('k5', '5')]
#获取section2组中k1对应的值,是否可取是按照上面返回的列表
val1= config.get("section2","k1")
print(val1)
#输出
v1
#返回section2中k5的值,这个值返回的int类型的
val2= config.getint("section2","k5")
print(val2)
#输出
5
3、改写i.cfg
①删除section和option
import configparser
config = configparser.ConfigParser()
config.read("i.cfg")
config.remove_option("section1","k3") #删除section1组下的k3
config.remove_section("section2") #删除section2组
with open("i.cfg2","w") as f: #重新写入一个文件
config.write(f)
#输出,写入文件的内容
[DEFAULT]
k1 = v1
k2 = v2
[section1]
k4 = v4
②添加section
import configparser
config = configparser.ConfigParser()
config.read("i.cfg")
sec = config.has_option("section2","k5") #是否存在section2组内有k5
print(sec)
#输出
True
sec = config.has_section("ksks") #是否存在ksks组
print(sec)
#输出
False
config.add_section("ksks") #添加section组ksks
config.add_section("ksks") #重新写入到一个配置文件中
with open("i.cfg3","w") as f:
config.write(f)
③添加或者设置option
import configparser
config= configparser.ConfigParser()
config.read("i.cfg")
config.set("ksks","z","18") #设置或者添加ksks中option值
with open("i.cfg3","w") as f: #重新写入文件中
config.write(f)
5-6-13 加密模块:hashlib
我们写程序中,经常需要对字符串进行MD5加密,python中也支持这种加密,下面说说,这个加密模块:hashlib。
1、MD5加密
原则:只要你的输入是固定的,你的输出也一定是固定的。MD5是在hash上更改的,主要做文件的一致性
import hashlib
m = hashlib.md5() #创建一个MD5对象
m.update(b"huojia") #在python3中需要是2进制的值,所以字符串前加b
print(m.hexdigest()) #以16进制打印MD5值
m.update(b"i++")
print(m.hexdigest())
m2 = hashlib.md5() #创建MD5对象m2
m2.update(b"huojiai++")
print(m2.hexdigest())
31750638aaff38379f4938bc9a6a3100
26f80aee68926f2fdb9aacaadf3fab4c
26f80aee68926f2fdb9aacaadf3fab4c
注:由上面的代码可以看出,你读到最后一行的字符串的MD5值跟一下子读取所有内容的MD5值是一样的,这是为什么呢?其实这边update做了一个拼接功能,m.update(b"huojia")是返回的字符串"huojia"的MD5值,但是到了第二个m.update("i++")的值并不是"i++"的字符串的MD5值,它需要拼接前面的字符串,应该是m.update(b"huojiai++")的MD5值,所以相当于m.update(b"huojia"),m.update(b"i++") = m.update(b"huojia"+b"i++")。
2、sha1加密
要过时了,尽量别用
mport hashlib
hash = hashlib.sha1()
hash.update(b"zhangqigao")
print(hash.hexdigest())
a39bb9061bfa9617b3c19cb9d019106ab1b186ad2、sha256 加密
说明:sha256用的比较多,相比MD5要更加的安全
import hashlib
hash = hashlib.sha256()
hash.update(b"huojia")
print(hash.hexdigest())
f3c6367011f5476562159af59a0ed3192fcb7315cc475f458da816429a3265ef
3、sha384 加密
import hashlib
hash = hashlib.sha384()
hash.update(b"huojia")
print(hash.hexdigest())
0ab90a282cb5a09fe0e97471651e787d390c7945b42d7abc5997db237bb0731c4a75db583794b195315b357677eea46a
4、sha512 加密
import hashlib
hash = hashlib.sha512()
hash.update(b"huojia")
print(hash.hexdigest()
676948356126aaeff33a164c1717949878c533b0b39595322cd7f7cc29f644c0f4d2eca7273b1442fcd608ca7fdc5120ff91646c16f2c0dd73b690ad6aa02322
)
注意:
- 以上这几种,其实都是对MD5加密的不同算法
- 其中sha256用的最多,比MD5要安全的多
- 有些公司会用加盐方式加密,比如:把字符串"huojia",通过一定的算法变成"huo.jia",当然这种算法自己肯定要知道,然后MD5加密,当然每个公司的加盐方式是不一样的。
hmac加密
其实以上还不是最牛的,最牛的是下面这种,叫hmac加密,它内部是对我们创建key和内容进行处理再进行加密。
散列消息鉴别码,简称HMAC,是一种基于消息鉴别码MAC(Message Authentication Code)的鉴别机制。使用HMAC时,消息通讯的双方,通过验证消息中加入的鉴别密钥K来鉴别消息的真伪;
一般用于网络通信中消息加密,前提是双方先要约定好key,就像接头暗号一样,然后消息发送把用key把消息加密,接收方用key + 消息明文再加密,拿加密后的值 跟 发送者的相对比是否相等,这样就能验证消息的真实性,及发送者的合法性了。
代码如下:
import hmac #导入hmac模块
hash = hmac.new(b"iamkey",b"iamvalue")
print(hash.hexdigest())
6bbe6de2f25056b70288e76e78ab002e


可以存储中文,但是记得encode
import hmac #导入hmac模块
hash = hmac.new(b"12345","这里存的是value".encode(encoding="utf-8"))
print(hash.digest())
print(hash.hexdigest())
b'\x19x\x8b\x03S\xd1\xb3L\xaf\x91W\xb6cc\xe7B'
19788b0353d1b34caf9157b66363e742
logging模块
很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误,警告等信息输出,python的logging模块提供了标准的日志接口,你可以通过它存储各种格式的日志,logging的日志可以分为debug,info,warning,error和critical 5个级别,下面我们就来看看这个日志模块logging怎么用
1、简单用法
说明:日志级别有五个,分别是:debug,info,warning,error和critical,其中debug级别最低,critical级别最高,级别越低,打印的日志等级越多。
import logging
logging.debug("logging debug")
logging.info("logging info")
logging.warning("user [huojia] attempted wrong password more than 3 times")
logging.error("logging error")
logging.critical("logging critical")
WARNING:root:user [huojia] attempted wrong password more than 3 times
ERROR:root:logging error
CRITICAL:root:logging critical
注:从上面可以看出,一个模块默认的日志级别是warning
2、日志级别
看一下这几个日志级别分别代表什么意思,如表:
| Level |
When it’s used |
|---|---|
DEBUG |
Detailed information, typically of interest only when diagnosing problems. |
INFO |
Confirmation that things are working as expected. |
WARNING |
An indication that something unexpected happened, or indicative of some problem in the near future (e.g. ‘disk space low’). The software is still working as expected. |
ERROR |
Due to a more serious problem, the software has not been able to perform some function. |
CRITICAL |
A serious error, indicating that the program itself may be unable to continue running. |
3、日志写入文件
import logging
logging.basicConfig(filename="catalina.log",level=logging.INFO) #输入文件名,和日志级别
#---日志输出---
logging.debug("logging debug")
logging.info("logging info")
logging.warning("logging warning")
#输出到文件中的内容
INFO:root:logging info
WARNING:root:logging warning
注: 这句中的level=loggin.INFO意思是,把日志纪录级别设置为INFO,也就是说,只有比日志是INFO或比INFO级别更高的日志才会被纪录到文件里,所以debug日志没有记录,如果想记录,则级别设置成debug也就是level=loggin.DEBUG
import logging
logging.basicConfig(filename="catalina.log",level=logging.WARNING) #输入文件名,和日志级别
#---日志输出---
logging.debug("logging debug")
logging.info("logging info")
logging.warning("logging warning")
日志中的树出
INFO:root:logging info
WARNING:root:logging warning
$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
WARNING:root:logging warning
4、加入日期格式
说明:感觉上面的日志格式忘记加上时间啦,日志不知道时间怎么行呢,下面就来加上
import logging
logging.basicConfig(filename="catalina.log",
level=logging.INFO,
format='%(asctime)s %(module)s:%(levelname)s %(message)s', #格式请见第5点内容
datefmt='%m/%d/%Y %H:%M:%S %p') #需要加上format和datefmt
#---日志输出---
logging.debug("logging debug")
logging.info("logging info")
logging.warning("logging warning")
运行后日志文件显示
08/27/2017 21:48:18 PM testlog:INFO logging info
08/27/2017 21:48:18 PM testlog:WARNING logging warning
5、 format的日志格式
| %(name)s |
Logger的名字 |
| %(levelno)s |
数字形式的日志级别 |
| %(levelname)s |
文本形式的日志级别 |
| %(pathname)s |
调用日志输出函数的模块的完整路径名,可能没有 |
| %(filename)s |
调用日志输出函数的模块的文件名 |
| %(module)s |
调用日志输出函数的模块名 |
| %(funcName)s |
调用日志输出函数的函数名 |
| %(lineno)d |
调用日志输出函数的语句所在的代码行 |
| %(created)f |
当前时间,用UNIX标准的表示时间的浮 点数表示 |
| %(relativeCreated)d |
输出日志信息时的,自Logger创建以 来的毫秒数 |
| %(asctime)s |
字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 |
| %(thread)d |
线程ID。可能没有 |
| %(threadName)s |
线程名。可能没有 |
| %(process)d |
进程ID。可能没有 |
| %(message)s |
用户输出的消息 |
6、复杂的日志输入格式
之前的写法感觉要么就输入在屏幕上,要么就是输入在日志里面,那我们有没有既可以输出在日志上,又输出在日志里面呢?很明显,当然可以。下面我们就来讨论一下,如何使用复杂的日志输出。
1、简介
python使用logging模块记录日志涉及的四个主要类:
①logger:提供了应用程序可以直接使用的接口。
②handler:将(logger创建的)日志记录发送到合适的目的输出。
③filter:提供了细度设备来决定输出哪条日志记录。
④formatter:决定日志记录的最终输出格式。
2、logger
①每个程序在输出信息之前都需要获得一个logger。logger通常对应了程序的模块名,比如聊天工具的图形界面模块可以这样获得它的logger:
logger = logging.getLogger("chat.gui")
核心模块可以这样写:
logger = logging.getLogger("chat.kernel")
②logger.setLevel(lel)
说明:指定最低的日志级别,低于lel的级别将被忽略(debug是最低的内置级别,critical为最高)
logger.setLevel(logging.DEBUG) #设置级别为debug级别
③Logger.addFilter(filt)、Logger.removeFilter(filt)
说明:添加或删除指定的filter
④logger.addHandler(hdlr)、logger.removeHandler(hdlr)
说明:增加或删除指定的handler
logger.addHandler(ch)#添加handler
logger.removeHandler(ch) #删除handler
⑤Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical()
说明:可以设置的日志级别
logger.debug('debug message')
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical('critical message')
④获取handler个数
handler_len = len(logger.handlers)
print(handler_len)
#输出
1
3、hander
handler对象负责发送相关的信息到指定目的地。Python的日志系统有多种Handler可以使用。有些Handler可以把信息输出到控制台,有些Logger可以把信息输出到文件,还有些 Handler可以把信息发送到网络上。如果觉得不够用,还可以编写自己的Handler。可以通过addHandler()方法添加多个多handler 。
①Handler.setLevel(lel)
说明:指定被处理的信息级别,低于lel级别的信息将被忽略。
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
②Handler.setFormatter()
说明:给这个handler选择一个格式
ch_formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s") #生成格式
ch.setFormatter(ch_formatter) #设置格式
③Handler.addFilter(filt)、Handler.removeFilter(filt)
说明:新增或删除一个filter对象
Handler详解
1、logging.StreamHandler
说明:使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息,也就是屏幕输出。
它的构造函数是:StreamHandler([strm]),其中strm参数是一个文件对象,默认是sys.stderr。
import logging
logger = logging.getLogger("TEST-LOG")
logger.setLevel(logging.DEBUG)
ch = logging.StreamHandler() #创建一个StreamHandler对象
ch.setLevel(logging.DEBUG) #设置输出StreamHandler日志级别
ch_formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
ch.setFormatter(ch_formatter) #设置时间格式
logger.addHandler(ch)
# 'application' code
logger.debug('debug message')
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical('critical message')
#输出
2017-04-11 16:42:49,764 - TEST-LOG - DEBUG - debug message
2017-04-11 16:42:49,764 - TEST-LOG - INFO - info message
2017-04-11 16:42:49,764 - TEST-LOG - WARNING - warn message
2017-04-11 16:42:49,765 - TEST-LOG - ERROR - error message
2017-04-11 16:42:49,765 - TEST-LOG - CRITICAL - critical message
2、logging.FileHandler
说明:和StreamHandler类似,用于向一个文件输出日志信息,不过FileHandler会帮你打开这个文件。
它的构造函数是:FileHandler(filename[,mode])。filename是文件名,必须指定一个文件名。mode是文件的打开方式。参见Python内置函数open()的用法。默认是’a',即添加到文件末尾。
import logging
#create logging
logger = logging.getLogger("TEST-LOG")
logger.setLevel(logging.DEBUG)
fh = logging.FileHandler("debug.log",encoding="utf-8") #日志输出到debug.log文件中
fh.setLevel(logging.INFO) #设置FileHandler日志级别
fh_formatter = logging.Formatter("%(asctime)s %(module)s:%(levelname)s %(message)s")
fh.setFormatter(fh_formatter)
logger.addHandler(fh)
# 'application' code
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical('critical message')
#输出到文件中
2017-04-11 17:09:50,035 logging_screen_output:INFO info message
2017-04-11 17:09:50,035 logging_screen_output:WARNING warn message
2017-04-11 17:09:50,035 logging_screen_output:ERROR error message
2017-04-11 17:09:50,035 logging_screen_output:CRITICAL critical message
3、logging.handlers.RotatingFileHandler
说明:这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建 一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。
它的构造函数是:RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]]),其中filename和mode两个参数和FileHandler一样。
maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。
backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。
import logging
from logging import handlers #需要导入handlers
logger = logging.getLogger(__name__)
log_file = "timelog.log"
#按文件大小来分割,10个字节,保留个数是3个
fh = handlers.RotatingFileHandler(filename=log_file,maxBytes=10,backupCount=3)
formatter = logging.Formatter('%(asctime)s %(module)s:%(lineno)d %(message)s')
fh.setFormatter(formatter)
logger.addHandler(fh)
logger.warning("test1")
logger.warning("test12")
logger.warning("test13")
logger.warning("test14")
4、logging.handlers.TimedRotatingFileHandler
说明:这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就 自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。
它的构造函数是:TimedRotatingFileHandler( filename [,when [,interval [,backupCount]]]),其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。
interval是时间间隔。when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:①S:秒②M:分③H:小时④D:天⑤W :每星期(interval==0时代表星期一)⑥midnight:每天凌晨
import logging
from logging import handlers
import time
logger = logging.getLogger(__name__)
log_file = "timelog.log"
#按时间来分割文件,按5秒一次分割,保留日志个数是3个
fh = handlers.TimedRotatingFileHandler(filename=log_file,when="S",interval=5,backupCount=3)
formatter = logging.Formatter('%(asctime)s %(module)s:%(lineno)d %(message)s')
fh.setFormatter(formatter)
logger.addHandler(fh)
logger.warning("test1")
time.sleep(2)
logger.warning("test12")
time.sleep(2)
logger.warning("test13")
time.sleep(2)
logger.warning("test14")
logger.warning("test15")
需要什么样的输出,只需要添加相应的handler就ok了。
控制台和文件日志共同输出
1、逻辑图
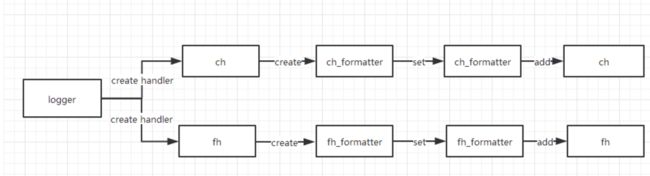
2、代码如下
需要什么样的输出,只需要添加相应的handler就ok了。
import logging
#create logging
logger = logging.getLogger("TEST-LOG")
logger.setLevel(logging.DEBUG)
#屏幕handler
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
#文件handler
fh = logging.FileHandler("debug.log",encoding="utf-8")
fh.setLevel(logging.INFO)
#分别创建输出日志格式
ch_formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
fh_formatter = logging.Formatter("%(asctime)s %(module)s:%(levelname)s %(message)s")
#设置handler的输出格式
ch.setFormatter(ch_formatter)
fh.setFormatter(fh_formatter)
#添加handler
logger.addHandler(ch)
logger.addHandler(fh)
# 'application' code
logger.debug('debug message')
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical('critical message')
re模块
正则表达式(或 RE)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现。你可以为想要匹配的相应字符串集指定规则;该字符串集可能包含英文语句、e-mail地址、TeX命令或任何你想搞定的东西。然后你可以问诸如“这个字符串匹配该模式吗?”或“在这个字符串中是否有部分匹配该模式呢?”。你也可以使用 RE 以各种方式来修改或分割字符串。所以今天就来讲讲这个模块:re模块。
1、常用的正在表达式符号
'.' 匹配除\n之外的任意一个字符,
'^' 匹配字符开头,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以
'*' 匹配*号前的字符0次或多次(允许匹配不到),re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次
'{m}' 匹配前一个字符m次
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c
'\' 转义
[a-z] 匹配[a-z]
[A-Z] 匹配[A-Z]
[0-9] 匹配数字0-9
'\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的
'\Z' 匹配字符结尾,同$
'\d' 匹配数字0-9
'\D' 匹配非数字
'\w' 匹配[A-Za-z0-9]
'\W' 匹配非[A-Za-z0-9]
's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group()
结果 '\t''(?P
re.search("(?P
结果:{'province': '3714', 'city': '81', 'birthday': '1993'}
【例子】
1、"." 匹配所有字符,"\w"就是匹配字符,但是不匹配特殊字符,"."匹配特殊字符
2、".+" 匹配任意字符,1次或多次,"+"前面的规则重复多次
3、"\w"匹配字母和数字,不能匹配特殊字符。
'+' 匹配不到会报错,没匹配到就返回None,
4、"\w"匹配字母和数字,不能匹配特殊字符。
'*' 匹配*号前的字符0次或多次(允许匹配不到),匹配不到,返回空
5、"\w?" 匹配字符1次或者0次,不能多。加上?允许匹配不到。
6、"\w{3}" 规则重复3次
7、"\w{5,8}" 重复5-8次,遇到空格就报错了,字符不包括空格,
8、改成"."就不报错了
9、匹配到|左边,或者右边都可以。
10、没匹配到、匹配到了
11、groups
按照规则groups分组显示
2、常用的匹配方法
1、re.match(pattern, string, flags=0)
说明:在string的开始处匹配模式
re.match(规则, string, flags=0) #目前是写死的规则,可以写成动态的规则
>>> import re
>>> a = re.match('in',"inet addr:10.161.146.134") #从头开始匹配in字符
>>> a.group() #查看匹配到了哪些
'in'
>>> a = re.match('addr',"inet addr:10.161.146.134") #开头匹配不到,所以返回none
>>> print(a)
None
2、re.search(pattern, string, flags=0)
说明:在string中寻找模式
>>> import re
>>> a = re.search('addr',"inet addr:10.161.146.134") #在字符串中寻找
>>> a.group()
'addr'
3、re.findall(pattern, string, flags=0)
说明:把匹配到的字符以列表的形式返回
>>> import re
>>> re.findall('[0-9]{1,3}',"inet addri:10.161.146.134")
['10', '161', '146', '134'] #符合条件的以列表的形式返回
4、re.split(pattern, string, maxsplit=0, flags=0)
说明:匹配到的字符被当做列表分割符
>>> import re
>>> re.split('\.',"inet addri:10.161.146.134")
['inet addri:10', '161', '146', '134']
5、re.sub(pattern, repl, string, count=0, flags=0)
说明:匹配字符并替换
>>> import re
>>> re.sub('\.','-',"inet addri:10.161.146.134")
'inet addri:10-161-146-134' #默认全部替换
>>> re.sub('\.','-',"inet addri:10.161.146.134",count=2)
'inet addri:10-161-146.134' #用count控制替换次数
6、finditer(pattern, string)
说明:返回迭代器
>>> import re
>>> re.finditer('addr',"inet addr:10.161.146.134")
3、常用方法
1、group([group1, ...])
说明:获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
>>> import re
>>> a = re.search('addr',"inet addr:10.161.146.134")
>>> a.group()
'addr'
>>> a.group(0)
'addr'
2、groups(default=None)
说明:以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。这个要跟分组匹配结合起来使用'(...)'
>>> import re
>>> a = re.search("(\d{2})(\d{2})(\d{2})(\d{4})","320922199508083319") #一个小括号表示一个组,有4个括号,就是4个组
>>> a.groups()
('32', '09', '22', '1995')
3、groupdict(default=None)
说明:返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。这个是跟另外一个分组匹配结合起来用的,即:'(?P
>>> import re
>>> a = re.search("(?P
#以下两种情况获取的值都是一样的
>>> a.groupdict()
{'birthday': '1993', 'city': '81', 'province': '3714'}
>>> a.groupdict("city")
{'birthday': '1993', 'city': '81', 'province': '3714'}
4、span([group])
说明:返回(start(group), end(group))
>>> import re
>>> a = re.search('addr',"inet addr:10.161.146.134")
>>> a.group()
'addr'
>>> a.span() #获取'addr'在字符串中的开始位置和结束位置
(5, 9)
5、start([group])
说明:返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引),group默认值为0。
>>> import re
>>> a = re.search('addr',"inet addr:10.161.146.134")
>>> a.group()
'addr'
>>> a.span()
(5, 9)
>>> a.start() #获取字符串的起始索引
5
5、end([group])
说明:返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1),group默认值为0。
>>> import re
>>> a = re.search('addr',"inet addr:10.161.146.134")
>>> a.group()
'addr'
>>> a.span()
(5, 9)
>>> a.end() #获取string中的结束索引
9
6、compile(pattern[, flags])
说明:根据包含正则表达式的字符串创建模式对象
>>> import re
>>> m = re.compile("addr") #创建正则模式对象
>>> n = m.search("inet addr:10.161.146.134") #通过模式对象去匹配
>>> n.group()
'addr'
4、反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
>>> import re
>>> a = re.split("\\\\","C:\ \kaka\yhd_settings")
>>> a
['C:', ' ', 'kaka', 'yhd_settings']
>>> re.findall('\\','abc\com')
Traceback (most recent call last)
>>> re.findall('\\\\','abc\com')
['\\']
>>> re.findall(r'\\','abc\com')
['\\']
六、其他匹配模式
1、re.I(re.IGNORECASE)
说明:忽略大小写(括号内是完整的写法,下同)
>>> import re
>>> a = re.search('addr',"inet Addr:10.161.146.134",flags=re.I)
>>> a.group()
'Addr' #忽略大小写
2、re.M(MULTILINE)
说明:多行模式,改变'^'和'$'的行为,详细请见第2点
>>> import re
>>> a = re.search('^a',"inet\naddr:10.161.146.134",flags=re.M)
>>> a.group()
'a'
3、re.S(DOTALL)
说明:点任意匹配模式,改变'.'的行为
>>> import re
>>> a = re.search('.+',"inet\naddr:10.161.146.134",flags=re.S)
>>> a.group()
'inet\naddr:10.161.146.134'
注意:上面这三种匹配模式,知道就行。
5、总结
1、用r''的方式表示的字符串叫做raw字符串,用于抑制转义。
2、正则表达式使用反斜杆(\)来转义特殊字符,使其可以匹配字符本身,而不是指定其他特殊的含义。
3、这可能会和python字面意义上的字符串转义相冲突,这也许有些令人费解,比如,要匹配一个反斜杆本身,你也许要用'\\\\'来做为正则表达式的字符串,因为正则表达式要是\\,而字符串里,每个反斜杆都要写成\\。
4、你也可以在字符串前加上 r 这个前缀来避免部分疑惑,因为 r 开头的python字符串是 raw 字符串,所以里面的所有字符都不会被转义,比如r'\n'这个字符串就是一个反斜杆加上一字母n,而'\n'我们知道这是个换行符。因此,上面的'\\\\'你也可以写成r'\\',这样,应该就好理解很多了。
r"\([^()]+\)"