lstm结构图_带你深入了解TensorFlow框架下的LSTM时间序列预测
点击上方蓝字关注我们
![]()
前言
 重组病毒载体疫苗是什么 基本知识
重组病毒载体疫苗是什么 基本知识
所谓的时间序列预测是指在某些未来时间点预测数据的值的多少。时间序列预测主要基于连续性原理。在现实生活中,大多数事物的基本发展趋势将在未来继续,其产生的数据也将满足时间序列的连续性原则。所以在实际应用中,时间序列预测具有较强的实用性。预测效果与预测模型的选择密不可分。
TensorFlow简介TensorFlow是一种基于图的计算框架。正如TensorFlow本身所表示含义。Tensor表示张量,是TensorFlow的核心数据单位,其本质是一个任意维的数组。Flow(流)表示基于数据流图的计算,构建执行流图是TensorFlow开发过程中的重点。它表示的是张量从流图的一端流动到另一端计算过程,正是这种基于流的架构让它具有了更高的灵活性。TensorFlow系统架构如下图所示。
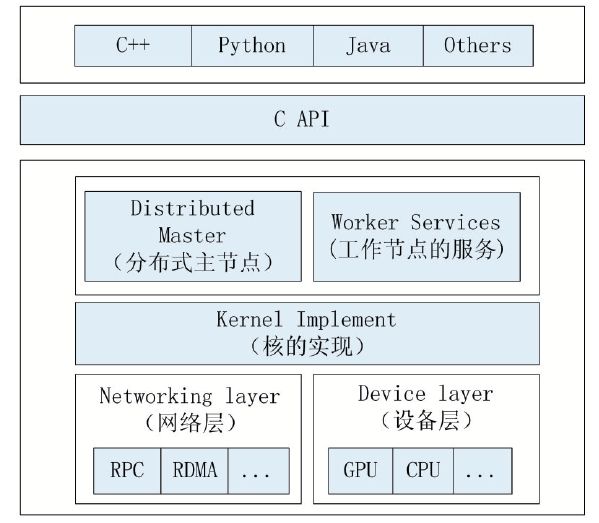
TensorFlow系统架构
LSTM网络LSTM(LongShort-Term Memory)是传统递归神经网络RNN(Recurrent Neural Networks)改良后的成果,是一款长短期记忆网络。它是由Ho⁃chreiter和Schmidhuber在1997年提出的。相较于普通的RNN,LSTM增加了一个记忆单元(cell)用于判断信息有用与否,解决了长序列训练过程中的梯度消失和梯度爆炸问题。这一改进使得其能在更长的序列中有更好的表现。
记忆单元的状态(cellstate)是LSTM的关键,为了保护和控制记忆单元的状态,一个记忆单元中被放置了三个控制门,分别叫做输入门、遗忘门和输出门。每个控制门由一个包含一个sigmoid函数的神经网络层和一个点乘操作组成。LSTM记忆单元的结构图如下图所示。图中从左方的输入![]() 到右方的输出
到右方的输出![]() 的一条贯穿示意图顶部的水平线即为记忆单元的状态。遗忘门、输入门、输出门的神经网络层均用
的一条贯穿示意图顶部的水平线即为记忆单元的状态。遗忘门、输入门、输出门的神经网络层均用![]() 层表示,其输出结果分别由
层表示,其输出结果分别由![]() 、
、![]() 、
、![]() 表示。图中的两个
表示。图中的两个![]() 层则分别对应记忆单元的输入与输出,其中第一个
层则分别对应记忆单元的输入与输出,其中第一个![]() 层生成了一个向量
层生成了一个向量![]() ,用来更新细胞状态。
,用来更新细胞状态。
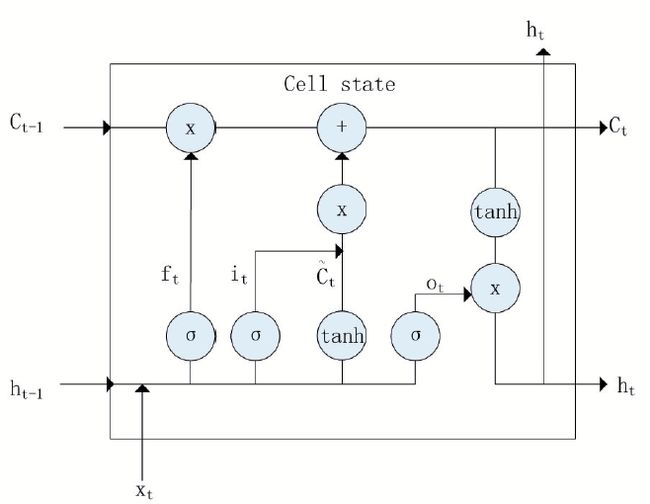
LSTM结构
关于输入门、遗忘门和输出门的详细介绍如下:1.遗忘门
一个信息进入LSTM的网络当中,只有符合算法认证的信息才可以不被遗忘。完成是否遗忘判断的是包含![]() 层的遗忘门,它通过将输入的
层的遗忘门,它通过将输入的![]() 和
和![]() 代入下式中得到
代入下式中得到![]() 来决定上一时刻的单元状态有多少可以被保留到当前时刻。
来决定上一时刻的单元状态有多少可以被保留到当前时刻。
![]()
2.输入门
输入门通过sigmoid来决定当前时刻网络的输入![]() 有多少保存到记忆单元状态
有多少保存到记忆单元状态![]() ,具体计算公式如下式所示,
,具体计算公式如下式所示,
![]()
其次,![]() 层会生成一个向量
层会生成一个向量![]() ,用来更新记忆单元状态,如下式所示
,用来更新记忆单元状态,如下式所示
![]()
然后将通过遗忘门和输入门得到的![]() 、
、![]() 、
、![]() 代入下式,这样即可将当前单元状态
代入下式,这样即可将当前单元状态![]() 和长期单元状态
和长期单元状态![]() 组合在一起,形成新的单元状态
组合在一起,形成新的单元状态![]() ,如下式。
,如下式。
![]()
3.输出门
输出门决定LSTM输出内容![]() 。它首先通过sigmoid层来得到一个初始输出
。它首先通过sigmoid层来得到一个初始输出![]() 如下式所示,
如下式所示,
![]()
然后再用![]() 层把单元状态
层把单元状态![]() 值推到-1和1之间。最终将sigmoid层和
值推到-1和1之间。最终将sigmoid层和![]() 层的输出相乘,以此实现对单元状态
层的输出相乘,以此实现对单元状态![]() 的过滤从而得到模型输出如下式。
的过滤从而得到模型输出如下式。
![]()
案例分析1:单变量时间序列预测
下面首先从简单的案例来进行分析,这里只考虑单变量时间序列预测。注意,下面代码并非完整代码展示,主要是对程序主要步骤进行详细说明。完整代码请见文末。此外,这里默认大家都已经搭建和配置好了Python环境下TensorFlow。
第一步,模拟时间序列数据的生成
利用函数加随机噪声的方法生成一个较为复杂的实验用时间序列数据。x对应时间序列的“观察的时间点”,y对应时间序列的“观察到的值”。然后将入x和y合并成data(Python中的字典)完成数据读入。再使用NumpyReader使之转换为Tensor形式,接着用tf.contrib.timeseries.RandomWindowInputFn将其变为batch训练数据。这是一个有4个随机序列的训练数据batch,且每个序列长度为100。具体实现代码如下:
x= np.array(range(1000))
noise= np.random.uniform(-0.2, 0.2, 1000) #随机噪声
y= np.sin(np.pi * x / 50 ) + np.cos(np.pi * x / 50) + np.sin(np.pi * x/ 25) + noise
data= {
tf.contrib.timeseries.TrainEvalFeatures.TIMES:x, #TFTS 读入x
tf.contrib.timeseries.TrainEvalFeatures.VALUES:y, #TFTS 读入y
}
reader= NumpyReader(data)
train_input_fn= tf.contrib.timeseries.RandomWindowInputFn(
reader, batch_size=4,window_size=100)
第二步,定义LSTM模型
利用TFTS提供的LSTM模型,其中由于是单变量时间序列,每个观测点只对应一个数值所以需要令num_features=1。num_units=128表示使用隐层为128大小的LSTM模型。在优化器的选择上,选用了实现了Adam算法的优化器tf.train.AdamOptimizer,能基于训练数据迭代地更新神经网络权重。
estimator= ts_estimators.TimeSeriesRegressor(model=_LSTMModel(num_features=1,num_units=128),
optimizer=tf.train.AdamOptimizer(0.001))
第三步,训练、验证和预测
Estimator是一种可极大地简化机器学习编程的高阶TensorFlowAPI,借助预创建的Estimator可以快速实现训练集的训练、评估和预测。实现代码如下:
estimator.train(input_fn=train_input_fn,steps=2000) #训练
evaluation_input_fn= tf.contrib.timeseries.WholeDatasetInputFn(reader)
evaluation= estimator.evaluate(input_fn=evaluation_input_fn, steps=1) #评估
(predictions,)= tuple(estimator.predict(
input_fn=tf.contrib.timeseries.predict_continuation_input_fn(
evaluation,steps=200)))
第四步结果保存为图片
定义变量分别记录实验生成的时间序列数据,预测的时间序列数据以及向后预测的实验数据并绘图保存。实现代码如下:
observed_times= evaluation["times"][0] #记录实验用时间序列数据的时间
observed= evaluation["observed"][0, :, :] #记录实验用时间序列数据的值
evaluated_times= evaluation["times"][0] #记录预测值对应的时间
evaluated= evaluation["mean"][0] #记录预测值
predicted_times= predictions['times'] #记录向后预测的预测值对应的时间
predicted= predictions["mean"] #记录向后预测的预测值
plt.figure(figsize=(15,5)) #定义图片
plt.axvline(999,linestyle="dotted", linewidth=4, color='r') #画竖直分割线
observed_lines= plt.plot(observed_times, observed, label="observation",color="k") #定义线条
evaluated_lines= plt.plot(evaluated_times, evaluated, label="evaluation",color="g")
predicted_lines= plt.plot(predicted_times, predicted, label="prediction",color="r")
plt.legend(handles=[observed_lines[0],evaluated_lines[0], predicted_lines[0]],
loc="upperleft") #添加图例
plt.savefig('predict_result.jpg') #保存图片
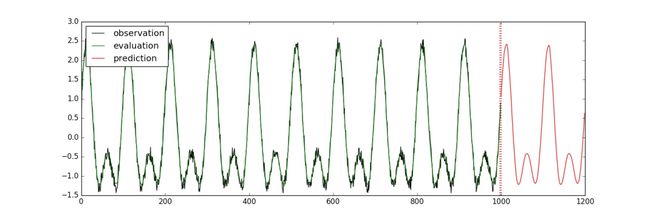
运行后,画出的图像会保存成“predict_result.jpg”文件。可以得到如下图结果:
案例分析2:多变量时间序列预测
案例1中只是针对单一变量时间序列进行了预测,这里我们通过改变变量数来进行多变量时间序列预测。依然要注意,下面的代码并非完整代码展示,主要是对程序主要步骤进行详细说明。完整代码请见文末。
第一步使用TFTS读入CSV文件
所谓多变量时间序列,就是指在每个时间点上的观测量有多个值。多变量时间序列预测与单变量时间序列预测的不同之处在于单变量预测每个时间点上的观测值只有一个,而多变量预测则有多个。与生成实验用时间序列数据不同,使用TFTS读入CSV文件首先需要引入文件并且需要通过column_names参数告诉TFTS文件中那些是时间,那些是观测量。具体实现代码如下:
csv_file_name= path.join("./data/multivariate_periods.csv")
reader =tf.contrib.timeseries.CSVReader(
csv_file_name,
column_names=((tf.contrib.timeseries.TrainEvalFeatures.TIMES,) #观测时间
+(tf.contrib.timeseries.TrainEvalFeatures.VALUES,) * 5)) #观测量
train_input_fn= tf.contrib.timeseries.RandomWindowInputFn(
reader, batch_size=4,window_size=32)
第二步定义LSTM 模型
唯一区别于单变量时间序列预测的在于,由于每个观测时间对应的观测量有5个,num_features=5。
estimator= ts_estimators.TimeSeriesRegressor(
model=_LSTMModel(num_features=5,num_units=128),
optimizer=tf.train.AdamOptimizer(0.001))
第三步训练、验证、预测以及绘图
与单变量原理及代码相同,这里就不再重复。同样,最后的运行结果会保存成“predict_result.jpg”文件,如下图所示:
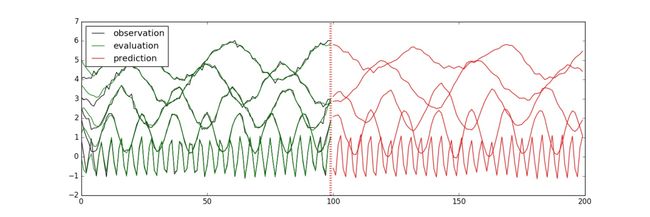
通过上述两个案例分析可以发现,在TensorFlow框架下引入LSTM模型会很好的对单变量时间序列和多变量时间序列进行预测,预测线条与实际线条接近重合,预测效果非常直观,见上面图中运行结果。
总结本文首先介绍了TensorFlow深度学习框架和LSTM网络的基本概念。通过单变量时间序列预测和多变量时间序列预测两个案例,详细地用实例代码介绍了TensorFlow引入的LSTM模型。从两次预测结果可以发现,预测均取得了较好的效果。该模型可用于解决实际工作中的一些时间序列预测问题,具有一定的实际意义。
