VIT Adapter【Vision Transformer Adapter for Dense Predictions】论文笔记
Vision Transformer Adapter for Dense Predictions
论文地址:2205.08534.pdf (arxiv.org)
代码地址:https://github.com/czczup/ViT-Adapter
目录
摘要
Introduce
Related work
Vision Transformer Adapter
Experiments
Conclusion
Appendix
摘要
本文研究了一种简单有效的vit的适配器。与最近在其架构中引入视觉特异性诱导偏差(vision-specific inductive biases)的vit不同,由于缺乏图像的先验信息,ViT在密集预测任务中取得了较差的性能。为了解决这一问题,我们提出了一种Vision Transformer Adapter (vit-Adapter),它可以弥补ViT的缺陷,并通过附加的架构引入诱导偏差,实现与视觉特定模型相当的性能。具体来说,我们的框架中的主干是一个普通的transformer,它可以用多模态数据(multi-modal data)进行预训练。当对下游任务进行微调时,使用特定于模式的adapter将数据和任务的先验信息引入到模型中,使其适合于这些任务。我们在多个下游任务中验证了vit-adapter的有效性,包括目标检测,实力分割,语义分割等。
Notably,when using HTC++, our ViT-Adapter-L yields 60.1 AP b and 52.1 AP m on COCO test-dev, surpassing Swin-L by 1.4 AP b and 1.0 AP。对语义分割,我们vit-adapter实现了sota,在ADE20K val上实现了60.5的miou。我们希望vit-adapter可以作为vit研究的替代方案,并促进未来的研究。
Introduce
最近,transformer在计算机视觉领域取得了巨大的成功。得益于注意力机制的动态特征提取能力和长期依赖性,vit及其变体很快在许多cv任务中崛起,如目标检测和语义分割,超越了CNN模型,达到了最先进的性能。
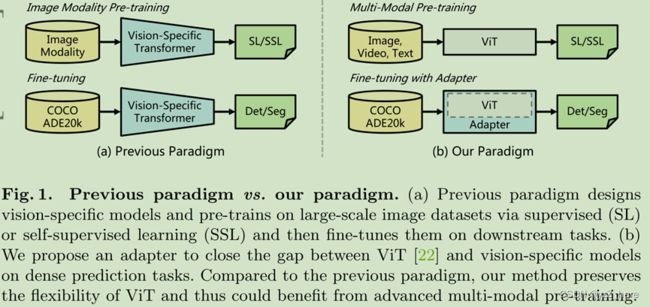
尽管目前最先进的视觉任务模型是transformer引入图像之前的变体,普通的transformer仍然有一些不可忽视的优势。源自NLP领域,transformer没有输入数据的假设。基于不同的嵌入层,如patch embedding、3D patch embedding、token embedding,ViT等普通的transformer可以处理图像、视频、文本等多模态数据。因此,ViT可以使用大规模的multi-model data 进行训练前预处理,这使得模型提取到的特征具有更丰富的语义信息。然而,与特定于任务的TF相比,ViT在下游任务中有明显的缺陷。以图像任务为例,缺乏图像的先验信息会导致收敛速度较慢,性能较低,因此在密集预测任务中,普通的transformer与专用transformer没有竞争优势。受到NLP领域的adapter的启发, 这项工作旨在开发一种适配器,以缩小ViT等普通TF与用于下游视觉任务的专用模型之间的差距。
为了这个目的,所以我们推出了VIT-Adapter,这是一个额外的网络,再不改变原有结构的基础上可以有效的适配VIT到下游的密集预测任务中。具体地说,为了将视觉特定的诱导偏差引入到普通转换器中,我们为vit- adapter设计了三个定制模块,包括:(1)一个用于捕获局部语义的空间先验模块(2)空间特征注入器用于将空间先验融合(3)多尺度特征提取器,用于重建密集预测任务所需的多尺度特征。如图1所示,与之前在大规模图像数据集(如ImageNet[20])上进行预训练并在不同任务上进行微调的范式相比,我们的范式更加灵活。在我们的框架中,骨干网是一个通用模型(例如,ViT),可以用多模态数据和任务进行预训练。将该模型应用于下游任务时,通过一个无需训练的特定的vit-adapter,将输入数据和任务的先验信息引入到通用骨干中,使该模型适合于下游任务。以这种方式,使用ViT作为主干,我们的框架实现了与Swin transformer[52]等专门为密集预测任务设计的transformers主干网络相当甚至更好的性能。
我们主要的贡献如下三点:
- 我们提出了一个密集预测任务适配器的ViT,可以弥合ViT与专用transformers之间的差距,如Swin transformers和PVTv2通过将图像先验引入到ViT骨干中对下游视觉任务,使其适合于密集预测任务。
- 为了在不改变ViT结构的情况下融合图像先验,设计了空间先验模块和两个特征交互算子,可以补充ViT缺失的局部连续性信息,并为下游任务重组细粒度多尺度特征。
- We evaluate the proposed ViT-Adapter on multiple challenging benchmarks, including COCO [50] and ADE20K [84]. Compared to the prior arts,our models consistently achieve improved performance. As shown in Fig. 2, under comparable parameters and computation overhead, ViT-Adapter-B achieves 49.6 AP b on COCO mini-val, outperforming Swin-B by 1.0 points (49.6 vs.48.6). Benefiting from multi-modal pre-training [86], the performance of this model can be further boosted to 50.7 AP b . When adopting HTC++ [52], our ViT-Adapter-L yields 60.1 AP b and 52.1 AP m on COCO test-dev. For the semantic segmentation task, our ViT-Adapter-L establishes a new state-of-the-art of 60.5 mIoU on the ADE20K dataset, 0.6 points higher than SwinV2-G [51].We hope that this very simple and strong framework can serve as a baseline for vision-specific adapter for pure transformers.

Related work
Transformers:
近年来,变形金刚已经主导了多种形式的各种任务,如自然语言处理、计算机视觉和语音识别。普通的transformer最初是为机器翻译而提出的,今天仍然是用于NLP任务的最先进的架构。Vision Transformer是第一个将普通Transformer推广到图像分类任务而不做太多修改的工作。PVT[74]和Swin Transformer[52]通过结合cnn的金字塔结构引入了更多图像特异性的归纳偏差,在一定程度上牺牲了其他模态的广义化能力的同时,在分类和密集预测任务中取得了优异的性能。Conformer[59]提出了第一个将CNN与变压器相结合的双网络。最近,BEiT[4]和MAE[27]将ViT的范围扩展到带有蒙面图像建模的自我监督学习,展示了纯ViT架构的强大潜力。
Decoders for ViT
密集预测的架构通常遵循一种encoder-decoder模式,编码器生成丰富的特征,解码器聚合并将它们转换为最终的预测。近年来,在ViT的global receptive的启发下,许多工作采用它作为编码器和设计任务特定的解码器。SETR,Segmenter等,总之,这些工作通过设计模态和任务特定的解码器改善了ViT的密集预测性能,但仍然存在ViT单尺度、低分辨率表示的缺点。
Adapters
到目前为止,在自然语言处理领域中,适配器已经得到了广泛的应用。PALs和适配器在transformers encoder中引入新的模块,用于特定任务的微调,使预训练模型快速适应下游NLP的任务。在cv领域,一些adapter已经在增量学习和域适应领域提出。随着CLIP(Learning transferable visual models from natural language supervision)的出现,许多基于CLIP的适配器[24,69,81]被用于将预先训练的知识转移到zero-shot or few-shot的下游任务。最近,采用了上采样和下采样模块,使单尺度ViT适应于多尺度FPN,这种技术可以看作是ViT最简单的多尺度适配器。然而,它在密集预测中的性能仍然不如最近的transformers变体,后者很好地结合了图像先验信息。因此,如何设计一种功能强大的适配器来提高ViT的密集预测性能仍然是一个挑战。
Vision Transformer Adapter
3.1 Overall Architecture

如图三所示,我们的模型可以分为两部分。第一部分是骨干网络(即ViT[22]),它由一个补丁嵌入和L个transformer encoder层组成(如图3(a))。第二部分是所提出的viti - adapter,如图3(b)所示,该适配器包括:(1)空间先验模块从输入图像中获取空间特征,(2)空间特征注入器将空间先验注入ViT,(3)多尺度特征提取器从ViT中提取层次特征。
对于ViT,首先将输入图像送入补丁嵌入,其中图像被分为16×16非重叠patchs。然后,这些patchs被展平并投影到d维embedding中。这里的特征分辨率降低到原始图像的1/16。最后,将嵌入的补丁和position embedding一起通过ViT的L编码器层。
对于vit-adapter,我们首先将image输入到空间先验模组中。收集3个目标分辨率(1/8、1/16、1/32)的d维空间特征。然后,将这些特征映射进行展平和拼接,作为特征交互的输入。具体来说,给定交互次数(interaction times)N,我们将ViT的变压器编码器平均分成N个块,每个block包含L/N个编码器层。对于第i个块,我们首先通过空间特征注入器向该块注入空间先验因子Fisp,然后通过多尺度特征提取器从该块的输出中提取层次特征。然后,N个特征交互,获得高质量的多尺度特征,然后将特征分割和重构为3个目标分辨率1/8、1/16和1/32。最后,我们对1/8比例的特征图进行2×2转置卷积上采样,构建1/4比例的特征图。通过这种方法,我们得到了一个与ResNet[30]分辨率相近的特征金字塔,可以用于各种密集预测任务。
3.2 Spatial Prior Module
PvtV2和segformer等工作展示了重叠滑动窗口的卷积可以帮助transformer更好地捕捉输入图像的局部连续性。受到这些工作的启发,我们在ViT中引入了一个基于卷积的空间先验模块(Spatial Prior Module),它通过一个ResNet(Deep residual learning for image recognition.cvpr)和三次卷积对H×W输入图像进行不同尺度的下采样。该模块与patch嵌入层并行建模图像的局部空间上下文,不改变ViT原有的架构。
如图3(c)所示,借用了ResNet的一个标准卷积块,它由三个卷积和一个最大池层组成。接下来,一个s=2的3×3卷积包含该模块的剩余部分,它使通道数量翻倍,并减少了feature map的大小。最后,我们采用了几个1×1卷积将特征映射投影到D维上。通过这种方法,我们得到了一个特征金字塔{f1 f2 f3},其中包括的分辨率为1/8, 1/16, 1/32。最后我们将这些feature map展平并拼接,作为后面特征注入器的输入。

3.3 Feature Interaction
由于ViT的柱状结构,其特征映射尺度单一,分辨率较低,导致其在密集预测任务中的性能不及金字塔结构。为了缓解这个问题,我们提出了两个特性交互模块,用于在adapter和ViT之间交流feature map。具体来说,这两个模块是基于cross-attention,叫做 Spatial Feature Injector 和 Multi-Scale Feature Extractor。如3.1节所述,我们将ViT的transformers encoder划分为N个相等的块,并在每个块的前后分别应用所提出的两个block。
Spatial Feature Injector:如图3d中所示,这个模块用来给vit中注入空间先验信息的。具体的对于第i个transformers block来说,我们将输入特征Fi(vit)作为Q(transformers中的KQV),将空间先验信息Fi(sp)看作K和V,我们使用multi-head cross-attention提取空间特征Fi(sp)并注入到Fi(vit),可以写成公式1:

Multi-Scale Feature Extractor:在注入了空间先验信息到第i个block之后,我们从Fi(vit)得到了输出Fi+1(vit)。之后我们将vit中的特征和空间特征的角色交换(Q和K,V交换)。将Fi(sp)看作是Q,将Fi+1(vit)看作是K和V,通过cross-attention模块将两者进行有一次的信息交流,可以定义为下面公式:

与空间特征注入器一样,我们在这里使用了变形注意(Deformable detr: Deformable transformers for end-to-end object detection)来减少计算成本. 此外,为了弥补fixed-size position embedding的缺陷,我们参考(CPVT和PVTv2)引入了CFFN在cross-attention之后。考虑到效率,我们参考(Delight:Deep and light-weight transformer),设置CFFN的比值为1/4。CFFN层通过zero-padding的深度卷积,增强了特征的局部连续性,可以表示为:
![]()
其中新的空间特征Fi+1(sp)将被用作下一个块的特征交互的输入。
3.4 Architecture Configurations
创建了不同规格的VIT-adapter,如下表所示,
在我们的实验中,ViT的patch size固定为16。交互次数N设置为4,这意味着我们将ViT的编码器层分成4个相等的块,用于特征交互。我们的两种特征交互算子都采用了变形注意(Deformable detr: Deformable transformers for end-to-end object detection),采样点数固定为4,注意头的数量分别设置为6、6、12、16。在最后的交互中,我们将三个多尺度特征提取器进行叠加。此外,我们将CFFN的比例设置为1/4,以减少计算开销,即CFFN的隐藏大小为48、96、192、256分别对应4中不同的vit变体。
Experiments
为了验证我们方法的有效性,我们在两个不同的密集预测任务上进行了大量的实验,包括COCO[50]对象检测和实例分割,以及ADE20K[84]语义分割。然后,我们进行了消融研究,分析了我们的vitc适配器的几种重要设计。
4.1 Object Detection and Instance Segmentation
Settings:我们的对象检测和实例分割实验是在COCO[50]基准上进行的,我们的代码主要基于MMDetection[10]。我们在5种主流检测器上评估了我们的方法,包括掩膜RCNN[29],级联掩膜R-CNN [8],ATSS [82],GFL[41]和稀疏R-CNN[68]。在训练阶段,我们对vit-T/S/B使用DeiT发布的权重,对vit-L使用(How to train your vit? data, augmentation, and regularization in vision transformers)的权重。我们的适配器新添加的模块是随机初始化的,没有预先训练的权重被加载。为了节省时间和内存,我们引用[43]( Benchmarking detection transfer learning with vision transformers)和修改ViT在大多数层使用14×14窗口注意。遵循惯例我们采用1×或3×训练计划(即12或36 个 epoch)来训练检测器,bs=16,lr=1*10e-4, 权重衰减0.05的AdamW优化器。
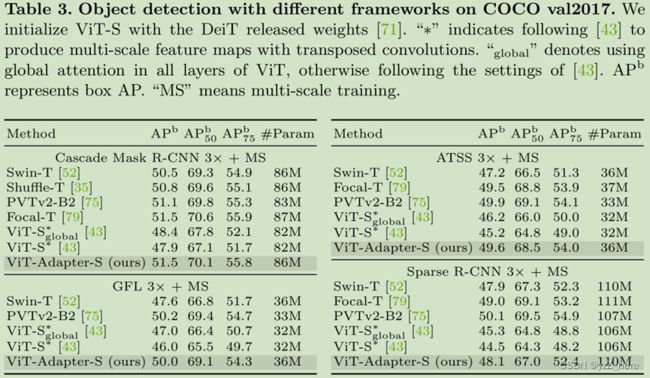
Results:如表2所示,略去,详细可看原文。
4.2 Semantic Segmentation
Settings:我们评估我们的vit-adapter在语义分割ADE20K[84]和MMSegmentation。为了进行完整的比较,我们使用了Semantic FPN[39]和UperNet[77]作为基本框架。对语义FPN,我们遵循PVT的设置,并训练模型为80 k迭代。对于UperNet,我们按照Swin[52]的设置来训练它并设置160 k迭代。此外,我们用DeiT发布的权重初始化vit-T/S/B,用来自(How to train your vit? data, augmentation, and regularization in vision transformers.)的ImageNet-22K权重初始化vit-L。
Result:如表5所示,我们分别报告了单尺度和多尺度mIoU的语义分割结果。我们首先考虑了semantic FPN[39],它是一个简单、轻量级的分割框架,没有复杂的设计。在可比较的模型尺寸下,我们的方法明显超过了以前的代表性方法。例如,vit-adapter-t超过了PVT-Tiny5.1 mIoU,参数减少近30%。 略。
4.3 Ablation Study
Settings:我们对COCO[50]数据集进行消融研究,除非明确说明,否则ViT使用DeiT发布的权重[71]。所有模型均使用Mask R-CNN[29]进行1× schedule训练,不进行多尺度训练。其他设置与4.1章节相同。
Ablation for Components: 为了研究每个关键设计的贡献,我们逐渐将vit-s∗基线[43]扩展到vit-adapter-s。如表6左侧所示,我们的空间先验模块和多尺度特征提取器比baseline提高了3.2 AP b和1.6 AP m。从变种2的结果中,我们发现空间特征注入器带来0.8 AP b和AP m提升。结果表明,局部连续性信息可以提高ViT在密集预测任务上的性能,且其提取过程可以与ViT体系结构解耦。此外,我们使用CFFN引入额外的位置信息,带来0.5 AP b和0.4 AP m增益,缓解了ViT中固定尺寸位置嵌入的缺点。

Interaction Times:在表6的右侧,我们研究了交互作用时间N的影响,具体来说,我们为vits配备了不同交互作用时间的适配器。当交互作用次数N增大时,模型精度达到饱和状态,并且应用更多的交互作用并不能单调地提高性能。因此,我们根据经验将N默认设置为4。
Attention Type:在我们的适配器中,注意机制是可替换的。为了验证这一点,我们以vit -adapter-s为基本模型,研究了4种不同的注意机制,包括global attention(Attention is all you need), window attention(Attention is all you need),linear SRA(Pvtv2: Improved baselines with pyramid vision transformer), and deformable attention (Deformable detr: Deformable transformers for end-to-end object detection)。为了支持处理多尺度特征,我们略微修改了窗口关注和线性SRA。对于窗口注意,我们将三种不同比例的窗口大小分别设置为28、14和7。对于线性SRA,在进行注意操作之前,我们使用平均池化的方法将每个尺度的空间维度降低到一个固定的大小(即7×7)。
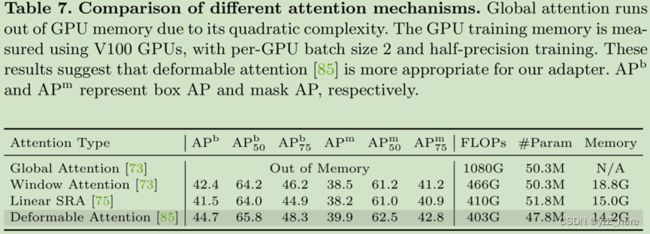
结果如表7所示,在我们的适配器中采用global attention时,由于二次元复杂度会耗尽GPU内存(32G)。Windows attention和linear SRA可以显著降低计算成本,但它们分别仅限于捕获局部和全局依赖项,导致建模能力相对较弱。我们的方法利用deformable attention避免了这一问题。具体来说,我们的方法在COCO val2017上获得了44.7 AP b和39.9 AP m的良好性能,在更少的FLOPs、参数和GPU内存的情况下,大大超过了其他具有Windows attention和linear SRA的变体。这些结果表明,由于deformable attention在处理多尺度特征方面的灵活性,它更适合于我们的适配器。
Pre-trained Weights:在这个实验中,我们研究各种预训练权重的影响。为了进行公平的比较,我们在不进行多尺度训练的情况下,对1×schedule使用不同的初始化来训练vit-adapter-B,如表8所示。我们的方法可以很容易地从更先进的预训练中受益。例如,简单地用MAE权重[27]替换DeiT权重[71],我们可以获得0.8 AP b和0.5 AP m的额外增益。更重要的是,当使用Uni-Perceiver [86]的多模态预训练时,我们的准确率进一步提高到48.4 AP b、43.1 AP m。这些结果表明,保留ViT的原始架构使我们的框架比专门设计的transformer更灵活,并且可以从现有的先进的训练前方法中获得显著的好处,而不需要额外的训练前成本。

Feature Visualization:在图4中,我们可视化了由vit-b *[43]和vit-adapter-b分别生成的多尺度特征图。由于特征分辨率的真正损失,vt - b∗的层次特征是模糊和粗糙的(见图4(a))。相反,我们的vit-adapter通过特征交互从ViT的单尺度特征重构细粒度的多尺度特征(见图4(b)),这提高了定位质量,减少了漏检。

TIDE Error Type Analysis: TIDE [5] is a toolbox for analyzing the sources
of error in object detection and instance segmentation algorithms. Following [43], we show the error type analysis generated by the TIDE in Fig. 5. These results reveal more detailed information about where our method improves overall AP brelative to the baseline [43]. For example, we observe that our ViT-Adapter slightly reduces missed errors compared to the baseline. Moreover, we see that our method has a more substantial effect on fixing localization errors. This phenomenon indicates that the fine-grained hierarchical features generated by our adapter contribute to better localization quality.

Conclusion
这项工作介绍了vit适配器,以弥补在密集预测任务中ViT和视觉特定transformer之间的性能差距。在不改变ViT结构的情况下,我们将图像先验注入到ViT中,通过空间先验模块和两个特征交互算子提取多尺度特征。在对象检测、实例分割和语义分割基准上的大量实验证实,我们的模型在相同数量的参数下,可以达到与精心设计的视觉专用transformer相当甚至更好的性能。
Appendix
A Comparison with Previous State-of-the-Art
为了进一步探索我们方法的潜力,在本节中,我们研究了先进的预训练是否能够使vit-adapter-l达到系统级的最先进性能。由于Uni-Perceiver[86]只提供预先训练的vit-b权值,这里我们采用ImageNet-22K预先训练的BEiT-L[4]来初始化我们的vita-adapter-l。BEiT[4]是针对ViT[22]设计的一种自监督学习方法,提出了一种学习高质量视觉表示的掩膜图像建模任务。它在语义分割等下游任务上实现了强大的微调结果,在ADE20K[84]数据集(57.0多尺度mIoU)上产生了最先进的结果。根据BEiT的官方知识库1,我们还采用了layer scale [72]和layer-wise learning rate decay来训练我们的模型。所有实验的学习速率衰减速率和随机深度速率[32]分别固定为0.9和0.3。
A 1 object detection and instance segmentation
略
A 2 semantic segmentation
For semantic segmentation, we employ an AdamW [55] optimizer with an initial
learning rate of 2×10-5, a batch size of 16, and a weight decay of 0.05.

ADE20K:
如上表所示,当使用upernet[77]进行160k迭代训练时,我们的ViT-adapter-L产生58.4多尺度mIoU,在仅10M额外参数的情况下,比BEiT-L[4]的结果高出1.4点。
此外,我们采用了更先进的Mask2Former[12]作为分割框架。由于SwinV2-G[51]是使用私人收集的预训练ImageNet-22K-ext-70M数据集包含7000万张图像,我们另外使用COCO-Stuff-164K[7]数据集进行80k次的训练前迭代。同样,我们将裁剪大小调整为896×896像素。值得注意的是,我们的ViT-adapter-L在这些设置下产生了60.5多尺度mIoU的新最先进的精度,这比之前最好的模型高出0.6个点,SwinV2-G[51],而我们方法的参数数要小得多。
Cityscapes:
在本实验中,我们使用Mask2Former[12]作为分割框架,并设置裁剪大小为896×896像素。按照这两个惯例(Hierarchical multi-scale attention for semantic segmentation和Segformer),我们首先在Mapillary vista[58]预训练,然后在cityscape上迭代了80K的iter进行fine-tune。如表11所示,我们的vit-adapter-l在测试集上实现了85.2个多尺度mIoU,略优于使用额外粗注释数据的HRNetV2+OCR+HMS[70]。
